
[DA-CLIP]中图像复原IR-SDE模型创建和定义代码
整理DA-CLIP关于IR-SDE的处理过程
IR-SDE

DA-CLIP中IR-SDE与原始IR-SDE不同在于model.feed_data包含degra_context和image_context
DA-CLIP: model.feed_data(noisy_tensor, LQ_tensor, text_context=degra_context, image_context=image_context)原始ir-sde: model.feed_data(noisy_tensor, LQ_tensor)
app.py中模型定义
sde = util.IRSDE(max_sigma=opt["sde"]["max_sigma"], T=opt["sde"]["T"], schedule=opt["sde"]["schedule"],
eps=opt["sde"]["eps"], device=device)
sde.set_model(model.model)
# 调用sde_utils.py的IRSDE()方法test.yml中的相关参数设置
sde:
max_sigma: 50
T: 100
schedule: cosine # linear, cosine
eps: 0.005IR-SDE类
class IRSDE(SDE):
'''
Let timestep t start from 1 to T, state t=0 is never used
'''
def __init__(self, max_sigma, T=100, sample_T=-1, schedule='cosine', eps=0.01, device=None):
super().__init__(T, device)
self.max_sigma = max_sigma / 255 if max_sigma >= 1 else max_sigma
self.sample_T = self.T if sample_T < 0 else sample_T
self.sample_scale = self.T / self.sample_T
self._initialize(self.max_sigma, self.sample_T, schedule, eps)代码很长,先放初始化方法和总的概况,再介绍里面比较重要的地方
IRSDE类继承自SDE类,并实现了一个随机微分方程(Stochastic Differential Equation, SDE)的求解器,IRSDE类主要用于在图像生成任务中模拟从噪声到清晰图像的逆向过程。类的主要功能和特点包括:
初始化:构造函数
__init__初始化了 IRSDE 类的实例,设置了最大噪声标准差max_sigma、总时间步T、采样时间步sample_T、sample_scale、时间步调度策略schedule、精度eps以及设备device。时间步调度策略:
_initialize方法根据schedule参数的值来确定时间步的调度策略,可以是常数(constant)、线性(linear)或余弦(cosine)。初始化mu = 0,model = None核心方法:类提供了一系列方法来处理 SDE 的不同方面,包括设置
mu(均值)和model(用于生成噪声的模型)、计算drift(漂移项)、sde_reverse_drift(SDE 逆向漂移项)、ode_reverse_drift(ODE 逆向漂移项)、dispersion(分散项)、get_score_from_noise(从噪声中获取得分函数)、score_fn(得分函数)、noise_fn(噪声函数)等。逆向过程:
reverse_optimum_step方法用于计算逆向过程中的最优点,reverse_sde和reverse_ode方法分别用于执行 SDE 和 ODE 的逆向模拟过程。正向过程:
forward方法用于执行从初始状态x0到最终时间T的正向模拟过程。噪声和得分生成:
generate_random_states方法用于生成随机状态,noise_state方法用于在给定张量上添加噪声。权重计算:
weights方法用于计算在给定时间步的权重。
forward ()
与SDE类相比多了save_dir参数和保存状态的相关代码
# 定义前向模拟过程,从初始状态 x0 演化到最终时间 T 的状态
def forward(self, x0, T=-1, save_dir='forward_state'):
# 如果传入的 T 为负数,则使用类实例的 T 属性作为模拟的总时间
T = self.T if T < 0 else T
# 从输入的初始状态 x0 创建一个副本,用于在模拟过程中更新状态
x = x0.clone()
# 使用 tqdm 库创建一个进度条,显示模拟进度
for t in tqdm(range(1, T + 1)):
# 在每个时间步执行前向模拟步骤,更新状态 x
x = self.forward_step(x, t)
# 如果保存目录不存在,则创建它,如果已存在则不抛出错误
os.makedirs(save_dir, exist_ok=True)
# 将当前状态 x 沿第一个维度分成两部分,可能是为了分别保存不同的状态分量
x_L, x_R = x.chunk(2, dim=1)
# 将两部分状态沿维度0拼接,然后调用 tvutils 库的 save_image 函数保存为图像文件
# 文件名包含时间步信息,用于后续的可视化和分析
tvutils.save_image(torch.cat([x_L, x_R], dim=0).data, f'{save_dir}/state_{t}.png', normalize=False)
# 模拟结束后,返回最终的状态 x
return xreverse_sde()
与SDE一样添加了保存中间过程的代码。根据save_states决定是否保存逆扩散过程状态
# 定义逆向SDE过程,从最终状态 xt 逆向模拟回到初始状态
def reverse_sde(self, xt, T=-1, save_states=False, save_dir='sde_state', **kwargs):
# 如果传入的 T 为负数,则使用类实例的 sample_T 属性作为逆向模拟的总时间
T = self.sample_T if T < 0 else T
# 从输入的最终状态 xt 创建一个副本,用于在逆向模拟过程中更新状态
x = xt.clone()
# 使用 tqdm 库创建一个进度条,显示逆向模拟进度
for t in tqdm(reversed(range(1, T + 1))):
# 调用 score_fn 方法计算给定状态和时间的评分函数(也称为概率密度函数的梯度)
score = self.score_fn(x, t, self.sample_scale, **kwargs)
# 执行逆向SDE步骤,使用评分函数更新状态 x
x = self.reverse_sde_step(x, score, t)
# x = self.reverse_sde_step_mean(x, score, t) # 这行代码被注释掉了,可能表示一个备用的逆向模拟步骤
# 如果 save_states 为 True,则保存逆向模拟过程中的状态
if save_states:
# 计算保存状态的间隔,这里假设只保存100个图像
interval = self.T // 100
# 如果当前时间步是保存间隔的整数倍,则保存状态
if t % interval == 0:
# 计算当前状态的索引
idx = t // interval
# 如果保存目录不存在,则创建它
os.makedirs(save_dir, exist_ok=True)
# 将当前状态 x 沿第一个维度分成两部分
x_L, x_R = x.chunk(2, dim=1)
# 将两部分状态沿维度3拼接,并保存为图像文件
tvutils.save_image(torch.cat([x_L, x_R], dim=3).data, f'{save_dir}/state_{idx}.png', normalize=False)
# 逆向模拟结束后,返回最终的状态 x
return xapp.py中调用该类初始化方法:
sde = util.IRSDE(max_sigma=opt["sde"]["max_sigma"], T=opt["sde"]["T"], schedule=opt["sde"]["schedule"],eps=opt["sde"]["eps"], device=device)
总的来说读取相关参数并初始化了一个IRSDE模型
sde.set_model(model.model)
set_model()
# set score model for reverse process
def set_model(self, model):
self.model = modelmodel
model = create_model(opt)
这个create_model不是open_clip里factory的,而是model文件夹下的 。
根据输入的字典进行相关判断创建模型
def create_model(opt):
model = opt["model"]
# YAML中默认model参数为denoising
if model == "denoising":
from .denoising_model import DenoisingModel as M
else:
raise NotImplementedError("Model [{:s}] not recognized.".format( model))
m = M(opt)
# 这个类提供了一个模型完整的训练和测试流程,包括数据准备、模型优化、评估、日志记录和模型保存。
# 它使用 PyTorch 框架,并且考虑了分布式训练的情况。通过 opt 配置字典,用户可以灵活地配置模型的各种参数。
logger.info("Model [{:s}] is created.".format(m.__class__.__name__))
return m
模型DenosingModel类和方法定义
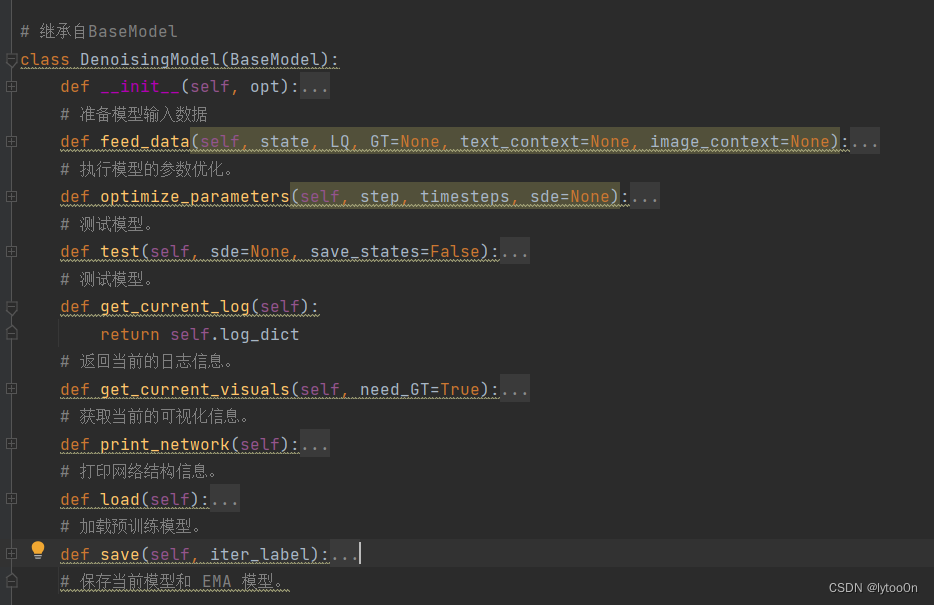
在初始化方法中调用了load方法,而load方法调用BaseModel的 load_network方法,根据地址pretrain_model_G加载了IRSDE预训练模型。
def load(self):
load_path_G = self.opt["path"]["pretrain_model_G"]
# 加载yml路径下的模型预训练权重
if load_path_G is not None:
logger.info("Loading model for G [{:s}] ...".format(load_path_G))
self.load_network(load_path_G, self.model, self.opt["path"]["strict_load"])在BaseModel类中定义device等属性、包含了与学习率调度、网络保存和加载、训练状态保存和恢复相关各方法
class BaseModel:
def __init__(self, opt):
# 构造函数接收一个配置字典 opt,并初始化一些基本属性。
self.opt = opt
# self.opt 存储传入的配置字典。
self.device = torch.device("cuda" if opt["gpu_ids"] is not None else "cpu")
# self.device 根据配置中的 gpu_ids 决定使用 CUDA 设备还是 CPU。
self.is_train = opt["is_train"]
self.schedulers = []
self.optimizers = []
# self.schedulers 和 self.optimizers 分别用于存储学习率调度器和优化器的列表。
#其他类方法省略该参数在option/test.yml设置了
model: denoising
这个DenosingModel模型和权重被加载到IRSDE的实例sde中

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)