
太牛逼了,一个国产AI开源项目,遥遥领先 !
为了能让大家更好的体验到agent,一句话总结:你只需要用自然语言描述任务,它就会自动调用大模型生成Python代码并执行,会写代码、还能自动操作浏览器、操作所有的应用程序等,全程不需要自己动手,它就把活儿干了。通过上面这个简单的任务需求,我们大致了解了Aipy这个开源工具有多么的牛逼,还有很多的应用场景就不详细介绍了,强烈建议大家去试试,你一定会很快爱上这个AI工具的!AiPy是通过写Pytho
大家还记得Manus这个Agent产品吗?当时这个产品火到全球,一码难求,现在虽然说比较好注册了,不过现在使用需要消耗太多会员积分,随便一个问题,价格贵到离谱 。为了能让大家更好的体验到agent,今天给大家介绍一款国产AI开源项目:AiPy,可以本地化部署,使用起来很简单,无脑下载安装包,然后点击运行就可以使用。下面跟着小猿来看看这个AiPy到底有多牛逼?
1
AiPy简介
AiPy 是一个结合 Python 与大语言模型(LLM)的开源工具。它的特别之处在于,用户不需要熟悉编程,直接用自然语言描述需求,AiPy 就能自动生成并执行 Python 代码完成任务。轻松实现数据分析、清洗和可视化等操作,简直就是程序员的贴心小助手,同时也让零基础用户迈入编程的世界。
一句话总结:你只需要用自然语言描述任务,它就会自动调用大模型生成Python代码并执行,会写代码、还能自动操作浏览器、操作所有的应用程序等,全程不需要自己动手,它就把活儿干了。
开源项目:https://github.com/knownsec/aipyapp
2
AiPy详解
1、AiPy如何安装使用 ?
我们首先打开AiPy的官网:https://www.aipyaipy.com ,如下图所示,根据你自己的电脑系统,选择合适的安装包下载安装 。
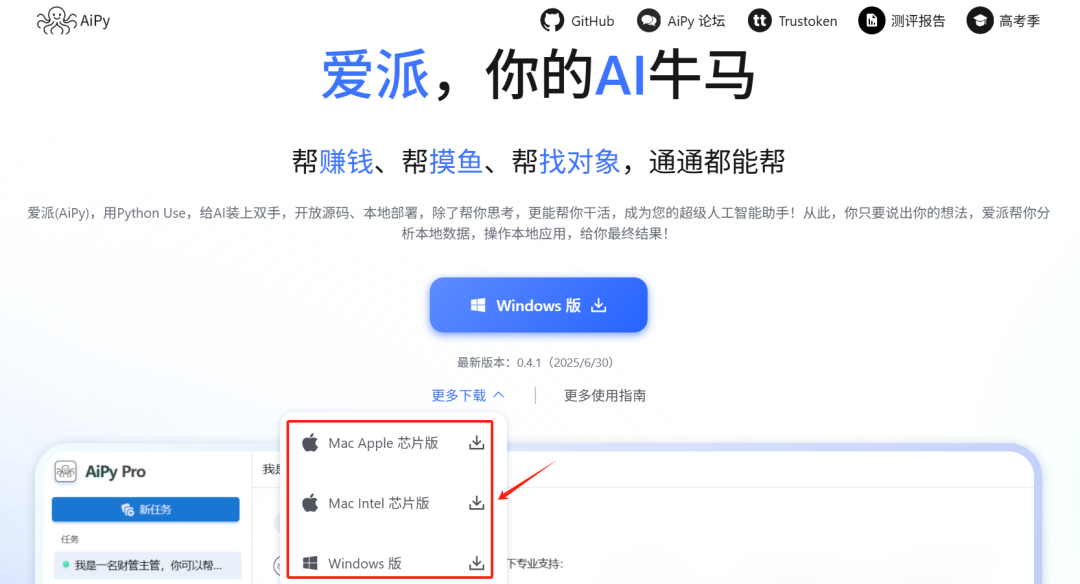
下载安装后,我们直接运行AiPy程序,会看到一个让我们选择模型提供商,这里官方比较推荐 Trustoken 网站,这个网站集成了很多AI模型。
https://www.trustoken.cn

大家注册好Trustoken网站的账号,根据我下图演示的创建api,复制key填入AiPy软件中即可 。
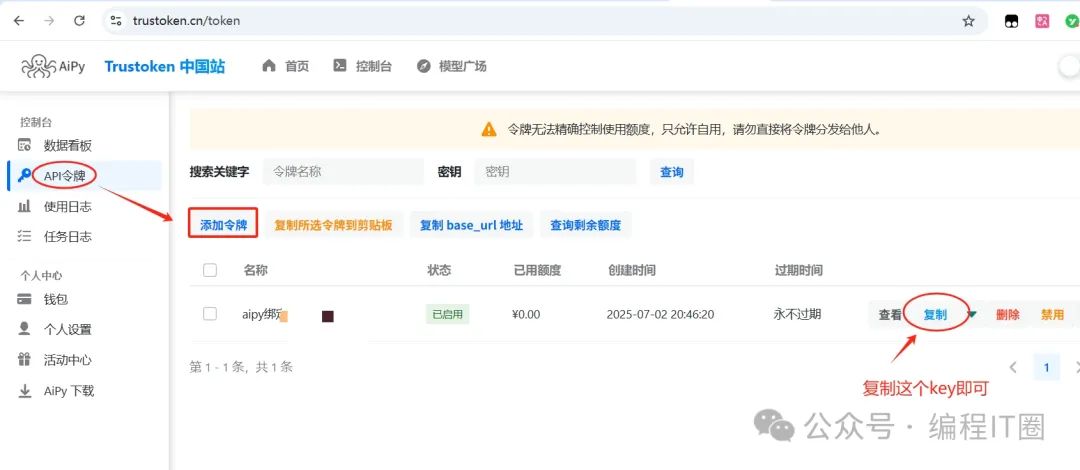
如果看到这个页面,恭喜你,代表成功了,可以正常使用了 。
2、AiPy的真实评测
我来给AiPy安排一个比较复杂的问题:从乘联会官网查询2025年新能源汽车品牌销售数据,然后做成一张品牌柱状图图表,然后打开,并以图片格式保存到本地。通过这个问题让我们一起来看看他的表现具体如何 。
首先这个问题抛给AiPy后,这个工具就开始分析用户的问题了。需要从乘联会官网获取2025年新能源汽车品牌销售数据,通过数据可视化生成柱状图并保存为图片文件。这是一个典型的数据获取→处理→可视化流程,需要处理网络请求、数据解析和图表生成等环节。
AiPy还给出了具体执行的4个步骤:
-
获取乘联会官网2025年新能源汽车品牌销售数据
-
解析并清洗销售数据
-
生成品牌销售数据柱状图
-
保存图表为图片文件并显示
AiPy是通过写Python代码去执行的,说实在的,这个代码交给程序员,估计要写个半天,现在Aipy,不到一分钟就写好了,太牛逼了。代码如下:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import sys
from datetime import datetime
def fetch_cpca_new_energy_sales_data():
"""
从乘联会官网获取2025年新能源汽车品牌销售数据
"""
try:
# 乘联会官网地址
url = "http://www.cpcaauto.com/"
# 发送请求获取页面内容
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
print("正在访问乘联会官网...", file=sys.stderr)
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # 检查请求是否成功
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找包含新能源汽车销售数据的部分
# 由于不确定具体页面结构,这里使用多种可能的选择器尝试查找
possible_selectors = [
"div.new_energy_sales", # 新能源销售数据div
"table#sales_table", # 销售数据表
"div.data_list", # 数据列表
"div.statistics" # 统计数据区域
]
data_section = None
for selector in possible_selectors:
data_section = soup.select_one(selector)
if data_section:
print(f"找到数据区域: {selector}", file=sys.stderr)
break
ifnot data_section:
print("未找到新能源汽车销售数据区域", file=sys.stderr)
# 保存页面内容用于调试
with open("cpca_page.html", "w", encoding="utf-8") as f:
f.write(response.text)
print("页面内容已保存至cpca_page.html", file=sys.stderr)
set_result(status="error", message="未找到新能源汽车销售数据区域")
returnNone
# 尝试提取表格数据
table = data_section.find('table')
if table:
# 使用pandas读取表格数据
df = pd.read_html(str(table))[0]
print(f"成功提取表格数据,共{len(df)}行", file=sys.stderr)
# 保存原始数据
df.to_csv("raw_sales_data.csv", index=False, encoding="utf-8")
set_persistent_state(raw_data=df.to_dict('records'))
set_result(status="success", message="成功获取原始销售数据", data_length=len(df))
return df
else:
# 如果没有表格,尝试提取列表数据
print("页面中未找到表格,尝试提取列表数据", file=sys.stderr)
data_items = data_section.find_all('div', class_='data_item')
if data_items:
brands = []
sales = []
for item in data_items:
brand_name = item.find('span', class_='brand').text.strip() if item.find('span', class_='brand') elseNone
sales_num = item.find('span', class_='sales').text.strip() if item.find('span', class_='sales') elseNone
if brand_name and sales_num:
brands.append(brand_name)
sales.append(sales_num)
if brands and sales:
df = pd.DataFrame({"品牌": brands, "销量": sales})
df.to_csv("raw_sales_data.csv", index=False, encoding="utf-8")
set_persistent_state(raw_data=df.to_dict('records'))
set_result(status="success", message="成功获取列表形式销售数据", data_length=len(df))
return df
else:
print("无法从列表中提取有效数据", file=sys.stderr)
set_result(status="error", message="无法从列表中提取有效数据")
returnNone
else:
print("数据区域中未找到表格或列表", file=sys.stderr)
set_result(status="error", message="数据区域中未找到表格或列表")
returnNone
except requests.exceptions.RequestException as e:
print(f"网络请求错误: {str(e)}", file=sys.stderr)
set_result(status="error", message=f"网络请求错误: {str(e)}")
returnNone
except Exception as e:
print(f"数据获取过程中发生错误: {str(e)}", file=sys.stderr)
set_result(status="error", message=f"数据获取过程中发生错误: {str(e)}")
returnNone
# 执行数据获取
df = fetch_cpca_new_energy_sales_data()AiPy执行完成后,会告诉你任务圆满完成了,并且给出了用户想要的答案并且还分析总结了数据 ,不错,很牛逼 !

2025年新能源汽车品牌销售数据,并且用柱状图显示给用户,数据一目了然,是我想要的效果,非常满意 !
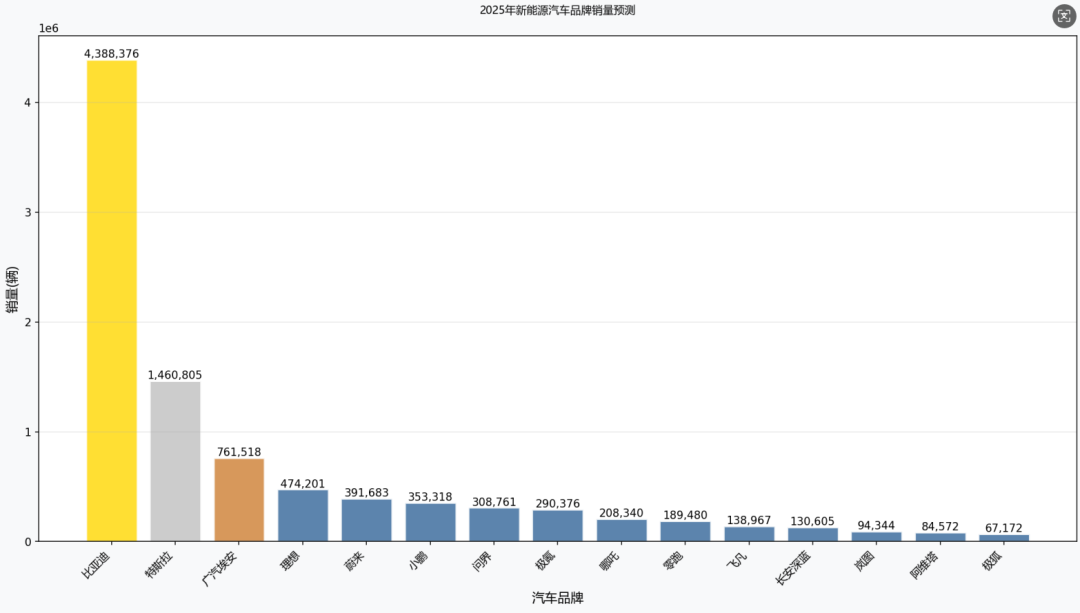
通过上面这个简单的任务需求,我们大致了解了Aipy这个开源工具有多么的牛逼,还有很多的应用场景就不详细介绍了,强烈建议大家去试试,你一定会很快爱上这个AI工具的 !
感兴趣的朋友还可以从它的官网:https://www.aipyaipy.com/
或者去github开源项目:https://github.com/knownsec/aipyapp
AiPy官方微信群已经建好了,方便大家交流提问。 免费扫码加入,还有最后50个位置,扫码先到先得 !群位置少量供应,能加进去的是幸运 !

↓↓↓ 戳 “阅读原文” 跳转AiPy官网

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)