
Python爬虫实战 女神礼物特别篇,三秒搜索最受欢迎的礼物_爬特效礼物教程
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。网上学习资料一大堆,但如果学到的知识不成
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
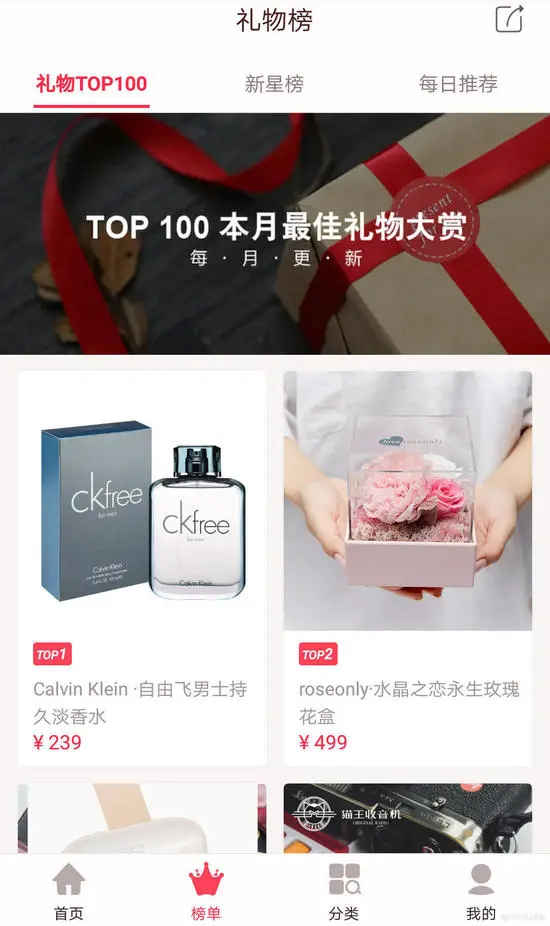
过女神节应该什么礼物好呢,爬取礼物说App,来告诉你选什么礼物好
App分析
爬取礼物TOP100榜单的信息
image
通过手机抓包软件「Charles」查找请求信息
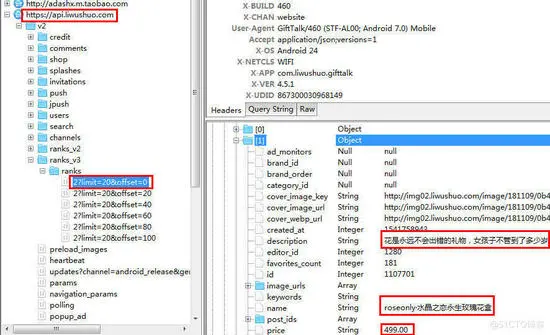
成功发现请求信息
获取信息
代码实现
from copyheaders import headers_raw_to_dict
import requests
import json
import time
headers = b"""
Accept:text![]()ml,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,\*/\*;q=0.8
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9
Cache-Control:max-age=0
Connection:keep-alive
Cookie:Hm\_lvt\_8a996f7888dea2ea6d5611cd24318338=1551961719; Hm\_lpvt\_8a996f7888dea2ea6d5611cd24318338=1551961719; session=c93470ef-86a2-43cc-abe3-36f98442bb8a
Host:api.liwushuo.com
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
"""
# 将请求头字符串转化为字典
headers = headers_raw_to_dict(headers)
num = 0
for i in range(0, 100, 20):
time.sleep(5)
# 请求网址
url = 'https://api.liwushuo.com/v2/ranks\_v3/ranks/2?limit=20&offset=' + str(i)
response = requests.get(url=url, headers=headers)
html = response.text
# 将字符串转为json格式
result = json.loads(html)
# 礼物列表
items = result['data']['items']
for item in items:
# 名称
name = item['name']
print(name)
# 价格
price = item['price']
print(price)\
# 礼物在礼物说里的地址
url = item['url']
print(url)
# 礼物图片
image = item['cover\_image\_url']
print(image)
# 礼物描述
description = item['description'].replace(',', ',').replace('\n', '').strip()
print(description)
# 礼物淘宝购买地址
purchase_url = item['purchase\_url']
print(purchase_url)
# 礼物排行
num += 1
rank = 'TOP' + str(num)
print(rank)
print('\n')
with open('gift.csv', 'a+') as f:
f.write(name + ',' + price + ',' + url + ',' + image + ',' + description + ',' + purchase_url + ',' + rank + '\n')
f.close()
成功获取礼物信息
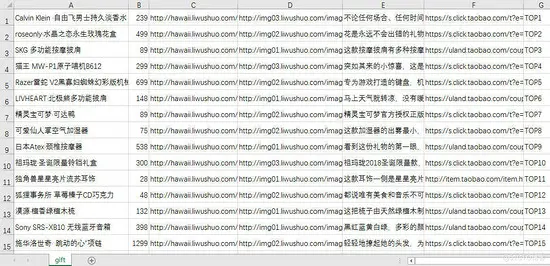
礼物的名称、价格、图片链接、礼物说链接、介绍、淘宝链接以及排行信息
图片生成
1. 生成礼物图片
有了图片的链接,一会就下载下来了。
具体代码
import pandas as pd
import requests
import os
df = pd.read\_csv('gift.csv', header=None, names=['name', 'price', 'url', 'image', 'description', 'purchase\_url', 'rank'], encoding='gbk')
folder_path = "gift\_image/"
os.makedirs(folder_path)
for j in range(100):
url = df['image'][j]
print(url)
r = requests.get(url)
picture_name = str(j+1) + '.jpg'
with open('gift\_image\\' + picture_name, 'wb') as f:
f.write(r.content)
成功获取了礼物图片

做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 19
19 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)