
深入解析 RAG:结合检索与大模型的智能问答技术
在人工智能驱动的智能问答系统中,大语言模型(LLM)如 GPT-4 和 Claude 3 在许多任务上表现出色。然而,LLM 的一个核心局限在于其知识是静态的,无法随时更新,对于专业领域的知识掌握也存在不足。为了解决这一问题,检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生。RAG 结合了外部知识库和大模型,能够提升生成内容的准确性、相关性和可追溯
前言
在人工智能驱动的智能问答系统中,大语言模型(LLM)如 GPT-4 和 Claude 3 在许多任务上表现出色。然而,LLM 的一个核心局限在于其知识是静态的,无法随时更新,对于专业领域的知识掌握也存在不足。为了解决这一问题,检索增强生成(Retrieval-Augmented Generation, RAG)技术应运而生。RAG 结合了外部知识库和大模型,能够提升生成内容的准确性、相关性和可追溯性。
本文将详细解析 RAG 技术的核心流程,并探讨如何构建高效的 RAG 系统,以提高智能问答系统的性能。
1. RAG 技术概览
RAG 技术的核心思想是通过检索外部知识来增强大模型的回答能力。首先,需要构建知识库,将领域文档、结构化数据或互联网信息转化为可检索的内容。接着,使用嵌入模型对文本进行编码,使其能够在向量数据库中进行高效存储和检索。当用户输入查询时,系统会将问题转换为向量,并在知识库中查找相关内容。最后,大模型结合检索到的信息生成最终回答。
2. 知识库构建
知识库的质量直接影响 RAG 生成的准确性。数据收集可以来自学术论文、政府报告、企业文档、数据库、新闻、博客等多个渠道。为了提高检索效果,所有数据都需要经过预处理,包括去除噪声、去重、格式标准化等步骤。
此外,文本需要进行分块处理,以便检索时能够更精确地返回相关内容。例如,在构建医疗问答系统时,可以按疾病类别整理医学文献,并标注数据的发布时间,以便检索时过滤过时信息。
3. 嵌入模型(Embedding Model)
嵌入模型的主要作用是将文本转化为高维向量表示,使其能够在向量空间中进行相似性检索。通用模型如 Sentence-BERT(SBERT)、OpenAI 的 Text-Embedding-3-small,适用于一般任务,而 BioBERT、FinBERT 这样的领域特定模型则适合医学和金融等专业场景。
在实践中,文本向量化可以通过如下方式完成:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
vector = model.encode("糖尿病治疗方法")
嵌入模型的选择与优化直接影响检索效果,合理微调可以进一步提升匹配精准度。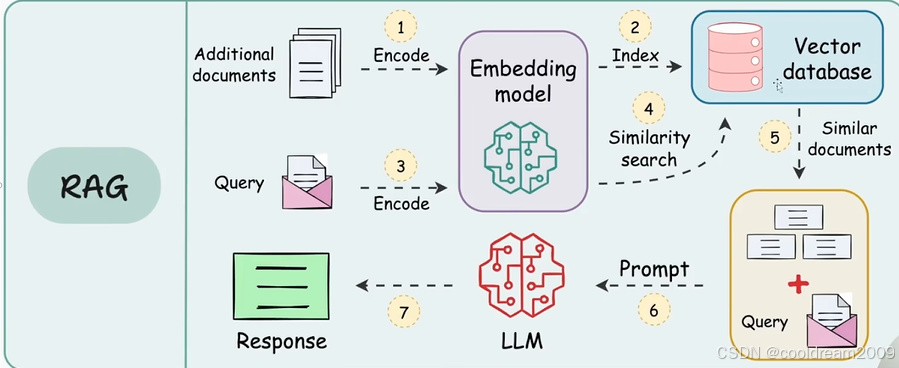
4. 向量数据库(Vector Database)
向量数据库用于高效存储和检索文本向量,支持近似最近邻搜索(ANN),以快速找到最相关的内容。主流的向量数据库包括本地部署方案(如 FAISS、Chroma)和云端方案(如 Pinecone、Milvus),适用于不同规模的应用场景。
向量数据库的索引构建包括三个主要步骤。首先,对所有文本块进行嵌入,并存入数据库。其次,选择合适的索引结构,如 HNSW(Hierarchical Navigable Small World)或 IVF-PQ(Inverted File with Product Quantization),以提高检索效率。最后,在检索时可以通过条件过滤来提升精准度,如按时间、类别等筛选结果。
5. 用户查询处理
当用户提出问题后,系统首先使用嵌入模型将问题转换为向量,并在向量数据库中进行搜索。检索到的结果会按照相关性排序,并作为上下文信息输入给大模型,以辅助回答生成。
例如,以下代码展示了如何进行查询向量化和检索:
query_vector = model.encode("糖尿病的最新治疗方法?")
results = vector_db.query(query_vector, top_k=5, filter={"year": ">=2020"})
为了优化检索效果,可以引入查询扩展技术,让 LLM 生成多个查询变体,以提高覆盖率。此外,混合检索方法结合传统关键词搜索(如 BM25)和向量搜索,可以进一步提升精准度。
6. 大模型生成(LLM)
在检索到的内容基础上,大模型会进行最终的回答生成。通常,输入格式包括问题本身以及检索到的文本。例如:
你是一位医疗助手,请根据以下信息回答问题:
[检索结果1]: 2023年 WHO 指南建议...
[检索结果2]: 临床试验显示药物 X...
---
问题:糖尿病的最新治疗方法?
生成质量的优化可以通过调整温度参数来控制创造性。例如,降低温度值(如 0.2)可以让模型更依赖检索内容,而不是凭空生成答案。此外,要求模型在回答中明确列出信息来源,有助于提高回答的可信度。例如:
“根据 2023 年 WHO 指南(来源:文档 A),推荐结合 SGLT2 抑制剂与生活方式调整…(更多细节参考文档 B)”
7. RAG 的优势与挑战
RAG 技术具有诸多优势。首先,它突破了 LLM 预训练知识的限制,使 AI 能够利用最新信息,提高回答的准确性。其次,由于检索到的信息可追溯,RAG 可以减少 LLM 生成的“幻觉”(Hallucination)问题。最后,相较于直接微调 LLM,RAG 降低了训练成本,使知识更新更加灵活。
然而,RAG 也存在一定的挑战。检索质量依赖于知识库的覆盖范围,如果知识库中的信息不全,模型仍可能无法生成高质量的答案。此外,在长文本处理过程中,如何筛选和组织上下文信息是一个重要问题。另一方面,知识库的维护需要不断更新数据,并重新嵌入和索引,增加了系统的管理成本。
结语
RAG 技术在智能问答和知识增强任务中展现了巨大潜力,使 AI 能够结合检索和生成,提高回答的质量和可信度。随着向量检索技术和大模型能力的不断优化,RAG 在医疗、法律、金融等行业的应用前景十分广阔。未来,如何进一步优化检索策略、提高实时性,将是 RAG 发展的重要方向。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 17
17 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)