
如何将SwanLab集成到Unsloth与TRL?
Unsloth是最近AI圈特别火的Python库,起因是DeepSeek R1带火了用GRPO(一种强化学习方法)来训练大模型,HuggingFace的TRL框架也在第一时间更新了GRPOTrainer。但在大家兴冲冲地启动训练时却发现,这显存占用也太高了,一般的显卡完全finetune不动呀!这个时候,Unsloth进入了大家的视野。它能够将Llama 3.3、Mistral、Phi-4、Qwe
Unsloth是最近AI圈特别火的Python库,起因是DeepSeek R1带火了用GRPO(一种强化学习方法)来训练大模型,HuggingFace的TRL框架也在第一时间更新了GRPOTrainer。但在大家兴冲冲地启动训练时却发现,这显存占用也太高了,一般的显卡完全finetune不动呀!
这个时候,Unsloth进入了大家的视野。它能够将Llama 3.3、Mistral、Phi-4、Qwen 2.5和Gemma的微调速度提高2倍,同时内存减少80%,足以在一张单卡进行GRPO训练。
下面的教程我会讲述如何使用unsloth和trl结合进行GRPO训练,同时来演示这两个框架如何集成SwanLab来进行全过程的实验跟踪与可视化。
文章目录
1. SwanLab和TRL的集成
TRL (Transformers Reinforcement Learning,用强化学习训练Transformers模型) 是HuggingFace推出的一个Python库,旨在通过监督微调(SFT)、近端策略优化(PPO)和直接偏好优化(DPO)等先进技术,对基础模型进行训练后优化。TRL 建立在 Transformers 生态系统之上,支持多种模型架构和模态,并且能够在各种硬件配置上进行扩展。

由于TRL是对Transformers的上层封装,所以SwanLab和Transformers的集成可以直接使用!使用方法是:
1. 引入1个SwanLabCallback
from swanlab.integration.transformers import SwanLabCallback
SwanLabCallback可以填很多参数,包括project、experiment_name、config、description、mode这些和swanlab.init直接映射的参数:
swanlab_callback = SwanLabCallback(
project="trl_integration",
experiment_name="qwen2.5-sft",
description="测试swanlab和trl的集成",
config={"framework": " TRL"},
mode="cloud",
)
这些参数会在trl启动训练后,用来创建SwanLab实验。
2. 传入Trainer
接下来的事情非常简单,你只需要找到trl的Trainer(比如SFTTrainer、PPOTrainer、GRPOTrainer等),然后把swanlab_callback实例传入到callbacks参数中即可:
from swanlab.integration.transformers import SwanLabCallback
from trl import SFTConfig, SFTTrainer
...
# 实例化SwanLabCallback
swanlab_callback = SwanLabCallback(
project="trl_integration",
experiment_name="qwen2.5-sft",
description="测试swanlab和trl的集成",
config={"framework": " TRL"},
)
trainer = SFTTrainer(
...
# 传入callbacks参数
callbacks=[swanlab_callback],
)
trainer.train()
启动trainer.train()以后,就可以在SwanLab中查看你跟踪的训练啦:
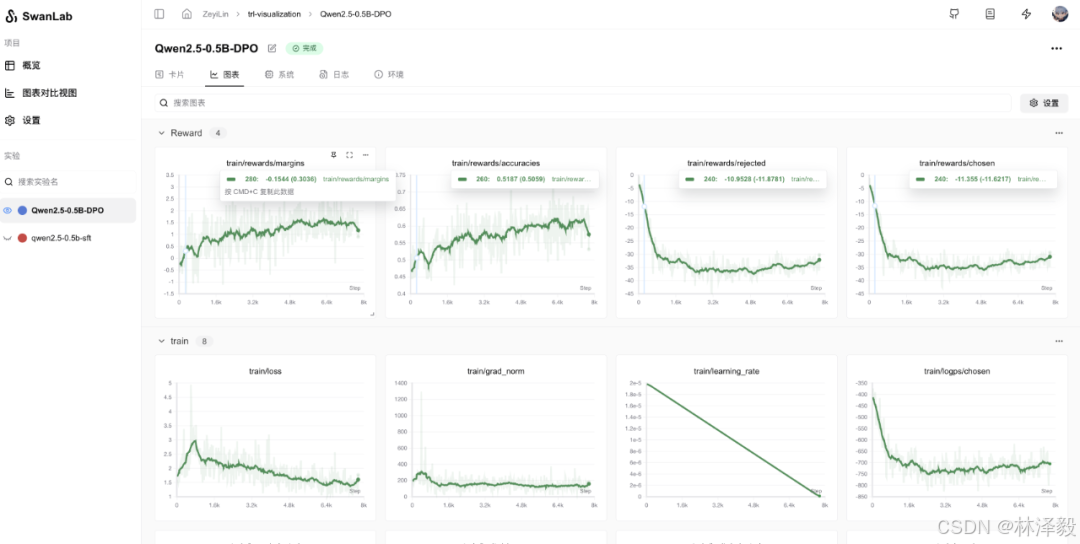
2. Unsloth + TRL + SwanLab

Unsloth在GRPO训练中起到了加速训练和降低显存消耗的作用,可以和TRL结合使用,用法大概如下:
1. 引入FastLanguageModel和PatchFastRL
from unsloth import FastLanguageModel, PatchFastRL
2. 给trl的GRPO打上加速补丁
PatchFastRL("GRPO", FastLanguageModel) # 对 TRL 进行补丁处理
from trl import GRPOConfig, GRPOTrainer, ModelConfig, TrlParser
注意,要先打上补丁,然后在再导入trl的GRPO工具。
3. 给模型和Tokenizer打上加速补丁
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="Qwen/Qwen2.5-3B-Instruct", # 模型名称或路径
fast_inference=True, # 启用 vLLM 快速推理
load_in_4bit=True, # 是否以 4 位加载模型,False 表示使用 LoRA 16 位
max_lora_rank=64, # 设置 LoRA 的最大秩
max_seq_length=1024, # 设置最大序列长度
gpu_memory_utilization=0.4, # GPU 内存利用率,若内存不足可减少
attn_implementation="flash_attention_2", # 设置注意力实现方式 flash attention
)
# PEFT 模型
model = FastLanguageModel.get_peft_model(
model,
r=64, # 选择任意大于 0 的数字!建议使用 8, 16, 32, 64, 128
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
], # 如果内存不足,可以移除 QKVO
lora_alpha=32, # 设置 LoRA 的 alpha 值
use_gradient_checkpointing="unsloth", # 启用长上下文微调
random_state=42, # 设置随机种子
)
到这里Unsloth就已经完成了加速工作啦,接下来就是和trl的训练流程一样,定义trainer,然后执行训练。
所以unsloth+trl+swanlab的大致代码框架如下:
from swanlab.integration.transformers import SwanLabCallback
from unsloth import FastLanguageModel, PatchFastRL
PatchFastRL("GRPO", FastLanguageModel) # 对 TRL 进行补丁处理
from trl import GRPOConfig, GRPOTrainer, ModelConfig, TrlParser
...
model, tokenizer = FastLanguageModel.from_pretrained(
...
)
# PEFT 模型
model = FastLanguageModel.get_peft_model(
...
)
# 实例化SwanLabCallback
swanlab_callback = SwanLabCallback(
project="trl_integration",
experiment_name="qwen2.5-sft",
description="测试swanlab和trl的集成",
config={"framework": " TRL"},
)
# 定义GRPOTrainer
trainer = GRPOTrainer(
...,
# 传入callbacks参数
callbacks=[swanlab_callback],
)
# 开启训练!
trainer.train()
SwanLab跟踪的结果示意如下:
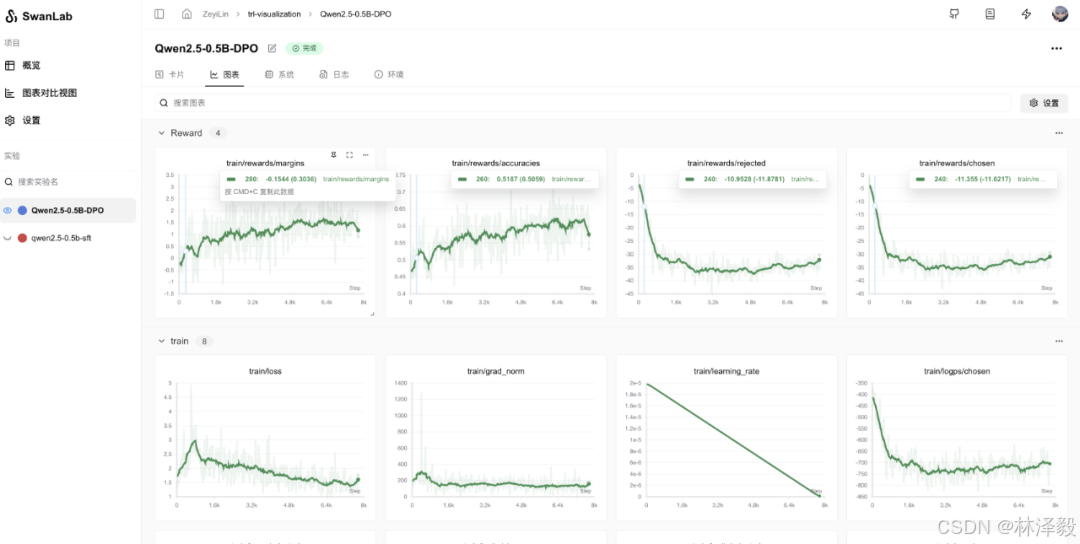
如果你想体验完整的unsloth+trl+swanlab训练R1 Zero的代码,欢迎使用DataWhale骆师傅和邓恺俊写的unlock-deepseek仓库中的 train_Datawhale-R1_unsloth.py 脚本!
Github仓库:https://github.com/datawhalechina/unlock-deepseek
更多资料
- swanlab集成trl官方文档:https://docs.swanlab.cn/guide_cloud/integration/integration-huggingface-trl.html
- swanlab集成transformers官方文档:https://docs.swanlab.cn/guide_cloud/integration/integration-huggingface-transformers.html
- unsloth开源仓库:https://github.com/unslothai/unsloth
- trl开源仓库:https://github.com/huggingface/

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)