
面试题:prefix LM 和 causal LM、encoder-decoder 区别及各自有什么优缺点?
Prefix LM,即前缀语言模型,是一种在给定一个文本前缀的情况下,模型能够基于这个前缀生成接下来的文本内容。
面试题:prefix LM 和 causal LM、encoder-decoder 区别及各自有什么优缺点?
原创 Alex 算法狗 2024年11月22日 15:53 浙江
各模型的atttion计算逻辑如下
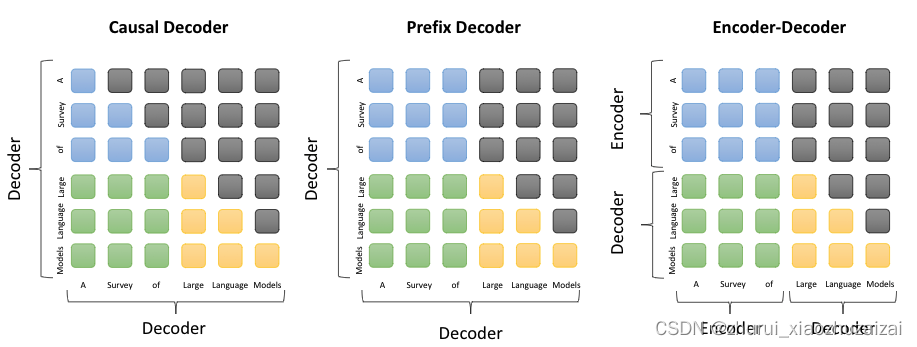
-
Prefix LM(前缀语言模型)
定义:Prefix LM,即前缀语言模型,是一种在给定一个文本前缀的情况下,模型能够基于这个前缀生成接下来的文本内容。注意力机制:在这种模型中,解码器(Decoder)可以访问整个输入序列(包括前缀和之前生成的输出),从而更好地理解上下文,生成连贯的文本。
应用场景:适合于需要基于已有文本继续生成文本的任务,例如文本补全、续写故事等。
优势:能够利用完整的上下文信息来生成文本,有助于生成更加准确和连贯的内容。
代表模型:T5、UniLM等,这些模型通过共享编码器(Encoder)和解码器(Decoder)的参数,实现对前缀的理解和文本生成。
优点:是可以减少对预训练模型参数的修改,降低过拟合风险;缺点:可能受到前缀表示长度的限制,无法充分捕捉任务相关的信息。 -
Causal LM(因果语言模型)
定义:Causal LM是一种自回归模型,它在生成文本时只能依赖于之前已经生成的文本,而不能利用未来信息。
注意力机制:这种模型使用一种掩码(masking),确保在生成每个词时,只能考虑它之前(包括当前)的词,而不能“看”到未来的词。
应用场景:广泛用于需要生成新文本的任务,例如文本摘要、聊天机器人、语言生成等。
优势:由于其自回归的特性,Causal LM在生成文本时可以逐步构建上下文,适用于长文本生成和需要逐步推理的场景。
代表模型:GPT系列模型,这些模型通过逐步生成文本的方式,实现了对语言的深入理解和生成。
优点:可以生成灵 活的文本,适应各种生成任务;
缺点:无法访问未来的信息,可能生成不一致或有误的内容。 -
Encoder-Decoder
定义:Encoder-Decoder包括一个编码器(Encoder)和一个解码器(Decoder)。编码器使用双向注意力,每个输入元素都可以关注到序列中的其他所有元素。解码器使用单向注意力,确保生成的每个词只能依赖于之前生成的词。
特点:Encoder-Decoder结构能够将输入数据编码成一个固定维度的向量,然后通过解码器将这个向量解码成目标输出。这种结构能够有效地处理变长序列的转换问题,并且具有较强的通用性和灵活性。
代表模型:Transformer、Flan-T5、BART等。
优点:可以处理输入和输出序列不同长度的任务,如机器翻译;
缺点:模型结构较为复杂,训练和推理计算量较大。
往期请看
面试题:LLama1, LLama2和LLama3的区别有哪些?
各厂家开源的Base,Chat,Instruction之间有什么区别?
P-tuning、Prompt-tuning和Prefix-tuning区别是什么?
Transformer中FFN的作用是什么?不以RLHF这种方式进行post-traing对齐,还有啥方法?
Prefix LM和Causal LM的区别是啥?一句话说明白?
备战AI岗位面试?这63个大模型深度学习问题你必须会答(14-27)
备战AI岗位面试?这63个大模型深度学习问题你必须会答(12-14)

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)