
Python基础部分
_*_ coding : utf-8 _*_ # @Time : 2022/10/24 17:37 # @Auther : 孙向阳 # @File : 函数 # @Project : python基础 def f1() : print("99") print("777") print("887") f1()
·
文章目录
- 一、pip指令
- 二、注释
- 三、变量类型
- 四、列表,字典,元组
- 五、查看数据类型
- 六、变量命名规范
- 七、数据类型转换
- 八、运算符
- 九、输入输出(格式化输出%s,%d)
- 十、if...else...语句
- 十一、for循环
- 十二、字符串的高级方法(len,find,startwith,endwith,count,replace,split,upper,lower,strip,join)
- 十三、列表的高级方法(增、删、改、查)
- 十四、元组的高级方法(注意:元组的元素是不能被修改的!)(好像只有查找的操作可以)
- 十五、字符串、列表、元组的切片操作
- 十六、字典的高级方法(增、删、改、查、遍历)
- 十七、函数
- 十八、文件
一、pip指令
win+R打开命令窗口
pip install 安装某个包
pip uninstall 卸载某个包
pip install 某个包 -i http://douban.com/simple 用镜像下载更快
二、注释
单行注释
多行注释
‘’’
‘’’
三、变量类型
int
long
float
complex
布尔类型
String
List(列表)
Tuple(元组)
Dictionary(字典)
四、列表,字典,元组
# 列表
name_list=['周杰伦','科比']
print(name_list)
# 元组
age_tuple=(18,19,20,21)
print(age_tuple)
# 字典
# 非常重要,scrapy框架的使用
# 格式
# 变量的名字={key:value,key1:value1}
person={'name':'阿斯顿','age':18}
print(person)
五、查看数据类型
a=1
print(type(a))
六、变量命名规范
标识符由字母,下划线和数字组成,且数字不能开头
严格区分大小写
不能使用关键字
七、数据类型转换
1、转换为int类型
a='123'
b=int(a)
print(type(b))
b=1.23
c=int(b)
print(type(c))
a=True
print(int(a))
a='123'
b=int(a)
print(b)
2、转换为浮点数
# 爬虫的时候大部分获取的都是字符串
a='12.34'#转换不了int类型
print(type(a))
b=float(a)
print(b)
c=999
print(float(c))
3、转换为字符串
a=80
print(type(a))
b=str(a)
print(b)
print(type(b))
a=1.2
print(type(a))
b=str(a)
print(b)
print(type(b))
a=True
print(type(a))
b=str(a)
print(b)
print(type(b))
输出结果
<class 'int'>
80
<class 'str'>
<class 'float'>
1.2
<class 'str'>
<class 'bool'>
True
<class 'str'>
4、转换为布尔型
#非零即1
a=1
print(bool(a))
a=2
print(bool(a))
a=-1
print(bool(a))
a=0
print(bool(a))
a=0.0
print(bool(a))
print("-------------------")
#字符串中有内容,转换完了之后都是True
a='萨达'
print(bool(a))
a=''
print(bool(a))
print("-------------------")
#只要列表有数据,就是True
a=['阿斯顿','啊撒旦']
print(bool(a))
a=[]
print(bool(a))
print("-------------------")
#只要元组有数据,就是True
a=('asd','asd')
print(bool(a))
a=()
print(bool(a))
print("-------------------")
#只要字典有数据,就是True
a={'name':'asdas'}
print(bool(a))
a={}
print(bool(a))
a={'':''}
print(bool(a))
输出结果
True
True
True
False
False
-------------------
True
False
-------------------
True
False
-------------------
True
False
-------------------
True
False
True
八、运算符

1、赋值运算符
python所特有写法
d,f,r=0,2,3
print(d)
print(f)
print(r)
2、比较运算符
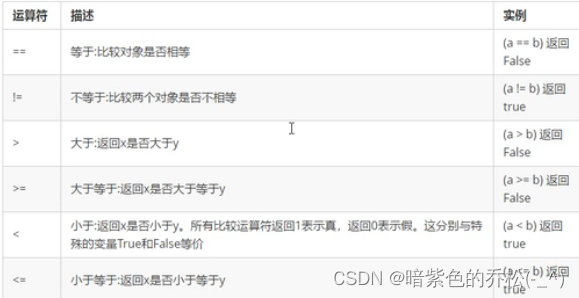
3、逻辑运算符

4、逻辑运算符性能优化
# and的性能优化,当and前面的结果是false的情况下,那么后面的代码就不会执行了
a=36
a>10 and print("hello")
# or的性能优化,只要一方为true,那么结果就是true,当前面为true,后面就不执行了
b=38
b>39 or print("world")
九、输入输出(格式化输出%s,%d)
# and的性能优化,当and前面的结果是false的情况下,那么后面的代码就不会执行了
a=36
a>10 and print("hello")
# or的性能优化,只要一方为true,那么结果就是true,当前面为true,后面就不执行了
b=38
b>39 or print("world")
password=input("请输入你的密码:")
print("我的密码是:%s"%password)
十、if…else…语句
age=19
if age>18:
print("你好")
gender=True
if gender==True:
print("你是男性")
#input返回的是字符串类型
age=input("请输入你的年龄:")
if int(age)>18:
print("您已成年!")
score=int(input("请输入分数"))
if score>=90:
print("优秀")
elif score>=80:
print("良好")
else:
print("不及格")
十一、for循环
# i是字符串中一个又一个字符的变量
# s是代表的要遍历的数据
s="china"
for i in s:
print(i)
# range方法的结果是一个可以遍历的对象
# range(5)方法的结果,左闭右开区间1-4
for i in range(1,6):
print(i)
for i in range(1,10,3):#间隔3个输出
print(i)
# 应用场景,会爬取一个列表给我们
# 循环一个列表
a_list=['asd','as','asds']
for i in a_list:
print(i)
#遍历列表中的下标
for i in range(len(a_list)):
print(i)
十二、字符串的高级方法(len,find,startwith,endwith,count,replace,split,upper,lower,strip,join)

s="china"
print(len(s))
print("--------------------")
s1="china"
print(s.find("c"))#返回字符串中第一次出现的位置
print("--------------------")
#是以特定字符出现在开头结尾吗
s2="china"
print(s2.startswith("c"))
print(s2.endswith("a"))
print("--------------------")
#统计字符出现的个数
s3="aaabb"
print(s3.count("a"))
print("--------------------")
#替换字符串
s4="cccdd"
print(s4.replace("c","d"))#将c替换成d
print("--------------------")
#字符串分割
s5="1#2#3#4#5"
print(s5.split('#'))
print("--------------------")
#转换成大小写
s6='china'
print(s6.upper())
s7='CHINA'
print(s7.lower())
print("--------------------")
#去空格
s8=" a "
print(len(s8))
print(len(s8.strip()))
print("--------------------")
#拼接,将这个字母一个个的都插入到字符的后面
s9='h'
print(s9.join('hello'))
输出结果
5
--------------------
0
--------------------
True
True
--------------------
3
--------------------
ddddd
--------------------
['1', '2', '3', '4', '5']
--------------------
CHINA
china
--------------------
10
1
--------------------
hhehlhlho
十三、列表的高级方法(增、删、改、查)
1、增加数据(append,insert,extend)
# 在列表的最后添加数据append
food_list=['q','r']
food_list.append("蘑菇")
print(food_list)
# insert,第一个参数是要插入的下标
char_list=['a','b','c','d']
char_list.insert(2,'p');
print(char_list)
# extend,将列表整个的插入到后面
num_list=[1,2,3]
num1_list=[4,5,6]
num_list.extend(num1_list)
print(num_list)
['q', 'r', '蘑菇']
['a', 'b', 'p', 'c', 'd']
[1, 2, 3, 4, 5, 6]
2、删除数据
# 删除 del
#爬取的数据中,有我们不想要的可以删除掉
a_list=[1,2,3,3]
print(a_list)
del a_list[2]
print(a_list)
print("-----------------")
# pop()删除最后一个元素
b_list=[5,6,7,8]
print(b_list)
b_list.pop()
print(b_list)
print("-----------------")
# remove()删除指定的元素,好像只能删除第一次出现的额位置
c_list=[1,2,3,3]
print(c_list)
c_list.remove(3)
print(c_list)
[1, 2, 3, 3]
[1, 2, 3]
-----------------
[5, 6, 7, 8]
[5, 6, 7]
-----------------
[1, 2, 3, 3]
[1, 2, 3]
3、修改数据
#通过下标来修改
city_list=['1','2','3','4','5']
city_list[4]=0
print(city_list)
['1', '2', '3', '4', 0]
4、查找数据
num_list=['5','9','23','5']
num=input("请输入数字:")
if num in num_list:
print("存在")
else:
print("不在")
ball_list=['篮球','排球']
ball=input("请输入球类:")
if ball not in ball:
print("不在")
else:
print("在")
请输入数字:6
不在
请输入球类:排球
在
十四、元组的高级方法(注意:元组的元素是不能被修改的!)(好像只有查找的操作可以)
a_tuple=(1,2,3)
print(a_tuple)
print(a_tuple[2])
# 元组的元素是不能被修改的!
# 如果定义只包含一个元素的元组,需要在后边加一个逗号
b_tuple=(1,)
print(b_tuple)
(1, 2, 3)
3
(1,)
十五、字符串、列表、元组的切片操作
s="hello,world"
# 字符串的第四个元素
print(s[4])
#左闭右开
print(s[0:5])
#从起始开始,一直到最后
print(s[1:])
#从下标为0的索引开始,一直到第二个参数为止,左闭右开区间
print(s[:4])
#hello,world,从下标为0的位置开始,到下标为7的位置结束,每次增长2个长度,左闭右开
print(s[0:7:2])
o
hello
ello,world
hell
hlow
十六、字典的高级方法(增、删、改、查、遍历)
1、增加数据
person={'name':'老马'}
print(person)
#给字典添加一个新的key和value
person['age']='18'
print(person)
{'name': '老马'}
{'name': '李四', 'age': '18'}
2、删除数据
# del:删除指定的元素
person={'name':'张三','age':18}
print(person)
del person['age']
print(person)
# del也可以删除整个字典,但是不能输出了,会报错
del person
# clear:清空字典,但是保留字典对象,可以输出,保留了字典结构
person2={'name':'李四','age':99}
person2.clear()
print(person2)
{'name': '张三', 'age': 18}
{'name': '张三'}
{}
3、修改数据
person={'name':'张三','age':19}
# 修改之前
print(person)
#修改name为李四
person['name']='李四'
print(person)
{'name': '张三', 'age': 19}
{'name': '李四', 'age': 19}
4、查找数据
person={'name':'啊撒旦','age':21}
print(person['name'])
print(person['age'])
# print(person['sex'])#访问不存在的key也是会报错的
# print(person.name)#这样写是会报错的
print(person.get('name'))
print(person.get('age'))
print(person.get('sex'))#访问不存在的key的时候,会返回None值
啊撒旦
21
啊撒旦
21
None
5、字典的遍历(很重要)
person={'name':'李四','age':87,'sex':'男'}
# 1、第一种方法,遍历字典的key.# keys()可以获取字典所有key的值
for key in person.keys():
print(key)
print('------------')
# 2、第二种方法,遍历字典的value.# values()可以获取字典所有的value值
for value in person.values():
print(value)
print('------------')
# 3、遍历字典的key和value
for key,value in person.items():
print(key,value)
print('------------')
# 4、遍历字典的项/元素
for item in person.items():
print(item)
name
age
sex
------------
李四
87
男
------------
name 李四
age 87
sex 男
------------
('name', '李四')
('age', 87)
('sex', '男')
十七、函数
1、函数的定义和调用
def f1():
print("99")
print("777")
print("887")
f1()
2、函数的参数
def sum(a,b):
c=a+b
print(c)
# 位置参数
sum(1,2)
#关键字传参
sum(b=98,a=97)
3、函数的返回值
def buyIceCream():
return '冰激凌'
print(buyIceCream())
def sum(a,b):
c=a+b
return c
print(sum(123,456))
十八、文件

1、文件的打开和关闭
# open(文件的路径,模式)
# open函数可以打开一个已经存在的文件
# 模式: w 可写 r 可读
# 文件的打开
fp = open('test.txt', 'w')
fp.write("helllo")
f=open('demo/text.txt','w')
f.write('asdsadsadsa')
#文件的关闭
f.close()
fp.close()
2、文件的读写
#如果文件存在,会先清空原来的数据,然后再写
fp=open("test.txt",'w')
fp.write('hello\n'*5)
fp.close()
#如果模式变为了a,会执行追加的操作
fp=open("test.txt",'a')
fp.write('hello\n'*5)
fp.close()
#读数据
fp=open('test.txt','r')
#默认情况下是一字节一字节的读
content=fp.read()
print(content)
fp.close()
print('------------------')
#一行一行的读取,但是只能读取一行
fp=open('test.txt','r')
content2=fp.readline()
print(content2)
fp.close()
fp=open('test.txt','r')
content2=fp.readlines()#返回的是一个链表
print(content2)
fp.close()
3、文件的序列化和反序列化

#序列化
#必须导入json文件!!!
import json
#默认情况下,对象是无法写入到文件中,如果想写入到文件中,必须使用序列化的操作
# 序列化的两种方式
#一、dumps()
fp=open('test.txt','w')
name=['zs','ls']
name=json.dumps(name)#将python对象转换为json字符串
fp.write(name)
fp.close()
#二、dump
fp=open('test.txt','w')
name=['zs','ls']
# dump相当于把下面这两步合并了
# name=json.dumps(name)
# fp.write(name)
json.dump(name,fp)
fp.close()
# 反序列化,两种方法
# loads
fp=open('test.txt','r')
content2=fp.read()
result=json.loads(content2)
print(result)
print(type(result))
# load
fp=open('test.txt','r')
result=json.load(fp)
print(result)
print(type(result))
4、文件的异常处理(try…except)
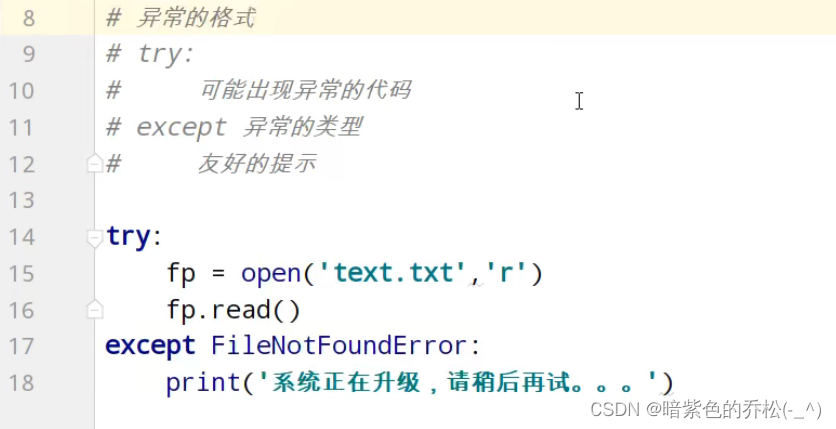
try:
fp=open('uuu,txt','r')
fp.read()
except FileNotFoundError:
print("文件不存在")

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)