
ICLR 2025 | 天大×腾讯开源COME方案,5行代码让模型告别“过度自信”,实现TTA鲁棒性飞跃!
机器学习模型必须不断自我调整,以适应开放世界中新颖的数据分布。作为主要原则,熵最小化(EM)已被证明是现有测试时适应(TTA)方法中简单而有效的基础。然而,其致命的局限性(即过度自信)往往会导致模型崩溃。针对这一问题,研究人员提出保守最小化熵(COME),这是一种简单的、可直接替代传统EM的方法,能够很好地解决上述局限性。本质上,COME在TTA过程中通过对模型预测的狄利克雷先验分布进行表征,显式
1. 【导读】

-
标题:COME: TEST-TIME ADAPTION BY CONSERVATIVELY MINIMIZING ENTROPY
-
论文链接:https://arxiv.org/abs/2410.10894
-
收录会议:ICLR 2025
-
作者:Qingyang Zhang、Yatao Bian、Xinke Kong、Peilin Zhao、Changqing Zhang
-
作者机构:天津大学智能与计算学部、腾讯AI实验室
-
论文链接:https://github.com/BlueWhaleLab/COME
更多优质内容需要的同学看文末!
2. 【摘要】
机器学习模型必须不断自我调整,以适应开放世界中新颖的数据分布。作为主要原则,熵最小化(EM)已被证明是现有测试时适应(TTA)方法中简单而有效的基础。然而,其致命的局限性(即过度自信)往往会导致模型崩溃。
针对这一问题,研究人员提出保守最小化熵(COME),这是一种简单的、可直接替代传统EM的方法,能够很好地解决上述局限性。本质上,COME在TTA过程中通过对模型预测的狄利克雷先验分布进行表征,显式地对不确定性进行建模。通过这样做,COME自然地对模型进行正则化,使其在不可靠样本上倾向于保守的置信度。从理论上,研究人员进行了初步分析,揭示了COME通过引入数据自适应的熵下界来增强优化稳定性的能力。在实证方面,该方法在常用基准测试中取得了最先进的性能,在各种设置下,包括标准、终身和开放世界TTA,在分类准确性和不确定性估计方面都有显著改进,例如在准确率上提升高达34.5%,在误报率上降低15.1%。
提供的代码可在:https://github.com/BlueWhaleLab/COME获取。
3. 【研究背景】
在机器学习领域,模型在图像识别、自然语言处理和自动驾驶等诸多方面成果显著。但许多机器学习算法依赖训练数据和测试数据分布相似这一假设,在现实中,由于环境变化、传感器差异或数据采集条件不同,测试数据分布常与训练数据差异显著,致使模型性能降低。
为应对该问题,测试时适应方法(TTA)应运而生,其目的是在测试阶段调整模型,以减轻数据分布差异带来的负面影响。熵最小化(EM)作为现有TTA方法的重要基石,被广泛应用于众多现有方法中,通过迭代增加分配给最可能类别的概率来适应分类器。
然而,传统的EM方法存在严重缺陷。一方面,存在过度自信问题,它强制模型对所有测试样本输出低熵预测,使得模型对错误分类或异常样本的置信度过高。另一方面,模型有崩溃风险,在不可靠样本上持续优化熵,可能会让模型参数漂移到无效解,造成性能急剧下降 。
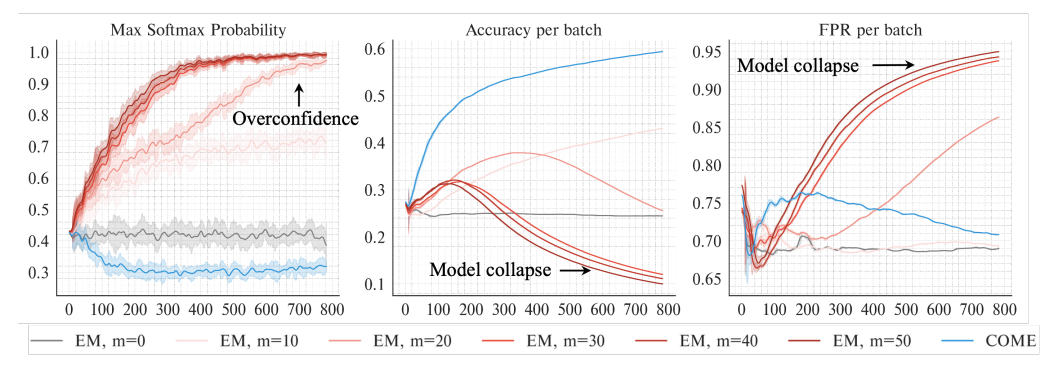
Empirical observations of Entropy Minimization when equipped to Tent (Wang et al., 2021). Along the TTA process, the uncertainty of models tuned with EM quickly drops, and the false positive rate decreases temporarily for a very short time horizon before quickly increasing.
如图所示,研究人员研究了熵最小化(Entropy Minimization, EM)在TTA场景下对两种代表性方法的影响,即Tent(Wang et al., 2021)和SAR(Niu et al., 2023)。
从左图可以观察到,在逐个epoch的TTA过程中,Tent方法和SAR方法均会持续增强预测的信心,max softmax probability值不断升高,呈现出模型过度自信预测的现象。
从中图能够发现,从第200个epoch起,在模型过度自信预测的同时,模型的预测准确率出现大幅下降的情况,研究人员将这种现象称为模型崩溃;而从右图假阳性率的走势也能看出,在模型过度自信预测时,其几乎丧失了分类预测的能力。
4.【主要贡献】
论文提出了一种名为COME(Conservatively Minimizing Entropy)的学习原则,用于改进现有测试时适应(TTA)方法,其主要贡献如下:
-
提出创新策略:研究人员提出了一种有别于传统熵最小化的驱动策略——保守最小化熵(COME)。该策略是一种简单且有效的模型无关学习原则,通过探索和利用不确定性来改进先前的TTA方法,可作为熵最小化的替代方案,在不改变原模型架构和训练策略的基础上,解决传统熵最小化方法存在的问题。
-
提供理论分析:对COME进行了理论分析,证明其模型置信度具有数据自适应的上界。这一特性使得TTA方法能够聚焦于可靠样本,并以保守的方式处理异常测试样本,与传统的熵最小化方法形成对比,凸显了COME在优化稳定性方面的优势,为TTA方法的设计提供了理论依据。
-
实验性能卓越:在多种设置下,包括标准、开放世界和终身TTA,研究人员进行了大量实验。结果表明,COME在分类准确性和不确定性量化方面均取得了优异的性能。在常用基准测试中,该方法相较于先前基于EM的TTA方法有显著提升,最高可实现准确率提升34.5%,误报率降低15.1% ,充分验证了COME的有效性和优越性。
5.【研究方法与基本原理】

Pseudo code of COME in a PyTorch-like style.
5.1基于主观逻辑建模不确定性(解决过度自信):
研究人员采用主观逻辑来量化不确定性。在 K 分类任务中,传统用 softmax 概率衡量预测置信度的方法易导致过度自信,而主观逻辑 (SL)将模型输出视为证据 e,构建狄利克雷分布来表示所有可能的概率分配。具体公式为:
其中,是由参数表征的狄利克雷分布,由证据加 1 得到,证据通过对模型输出 (即logits) 先应用 ReLU 函数再用指数输出函数获得,即,。在此基础上,计算每个类别的置信质量和整体不确定性质量 且, 其中为狄利克雷强度,代表收集到的总证据,为总类别数,且满足 。这样得到的主观意见不仅能描述对每个类别的置信度,还能显式地对不确定性进行建模。
5.2.通过锐化意见进行模型自适应:
传统 EM 方法最小化预测类分布的 softmax 熵,易使模型对某一类别分配过高概率。而 COME 提出最小化意见的熵这一学习原则:
相比传统方法,该原则为模型提供了更多选择,当总证据不足时,模型可通过将所有置信质量分配给不确定性,表达“不确定”的预测意见。此外,还可引入超参数来权衡最后一项, 即,以调整对测试样本是否适应的置信度 。
5.3. 无监督方式正则化不确定性(解决模型崩溃+高效正则化):
由于预训练模型存在过度自信问题,在TTA中直接最小化意见熵可能仍有问题。研究人员提出约束适应模型预测的不确定性质量,使其与预训练模型的差异不要过大,即:
subject to
其中 和 分别表示适应模型和预训练模型, 是根据前面公式估计的不确定性, 是防止模型不确定性过于极端的阈值。为将该约束转化为无约束形式,研究人员引入引理:
该引理表明主观意见的不确定性质量 受模型输出总证据的范数约束。因此,可通过约束模型输出 logits 的 p - 范数来间接约束 。最终,COME 的最小化目标为:
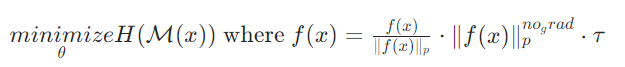
其中 是 的 p - 范数且梯度为零,可通过深度学习工具包中的 detach 操作实现, 是控制恢复 logits 大小的超参数。
6.【实验结果】
研究人员在Imagenet-C(level 5)数据集上开展了对比试验,以探究COME方法相较于传统方法的性能表现,具体结果如下:
-
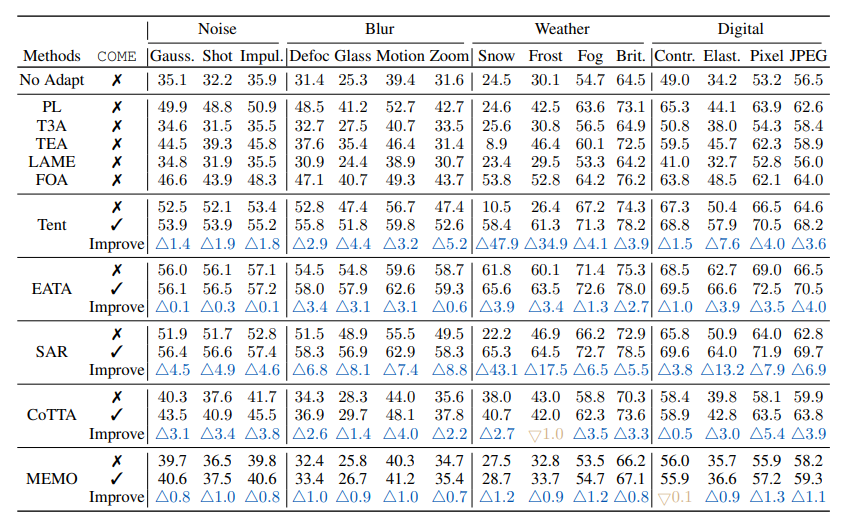
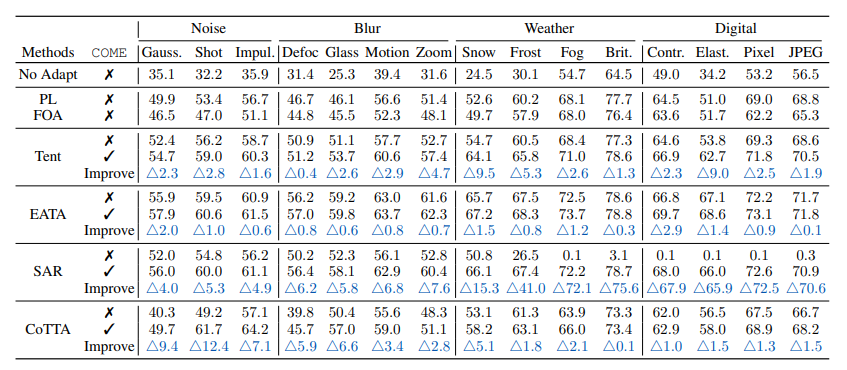
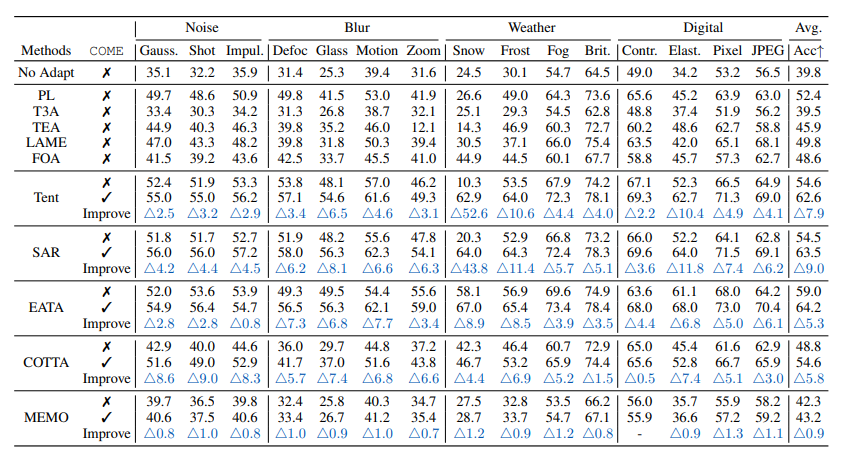
标准TTA(ImageNet-C):COME作为对熵最小化的改进,可直接应用于基于熵最小化的方法,显著提升模型预测能力。在Snow噪声(Level 5)下,Tent+COME对比Tent,分类准确率提升47.9%;在15类混合损坏数据上,SAR+COME对比SAR,平均准确率提升9.0%。
-
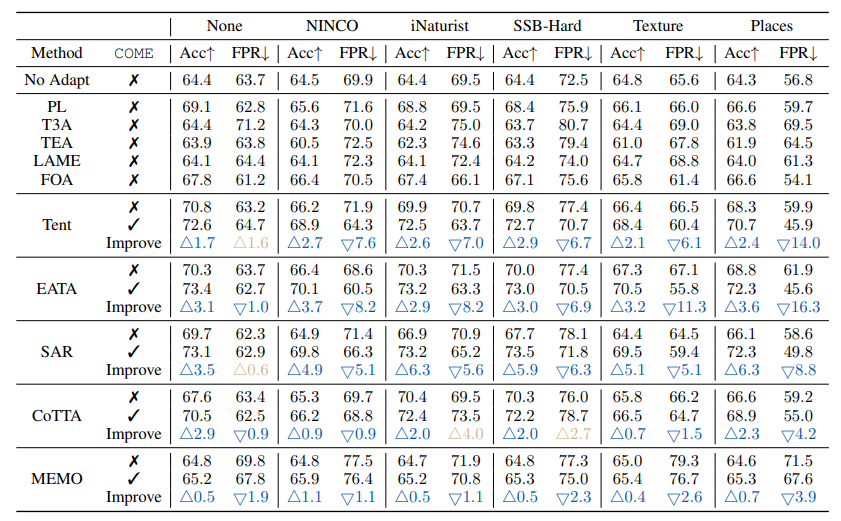
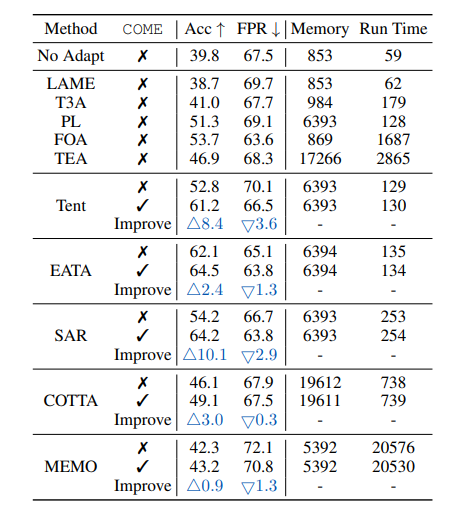
开放世界TTA(含异常样本):在开放世界实验设定下,模型会遇到outliers数据,COME能显著提升原方法性能。以NINCO数据集为例,使用COME后假阳性率(FPR)降低14.5%,有效减少对离群样本的误判。
-
终身学习TTA(持续分布变化):在动态数据流中,COME能够保持稳定性能,适应不断变化的测试数据分布。
-
计算效率:与不使用COME的原方法相比,COME仅增加<1%的推理耗时,适合实时部署,在提升模型性能的同时,不会对推理速度产生较大负面影响。
7.【论文总结展望】
总结
-
提出新学习原则:论文提出了一种名为COME的新型学习原则,用于改进现有测试时适应(TTA)方法。该原则基于证据理论显式地对不可靠测试样本的不确定性进行建模,并在推理时对模型进行正则化,使其倾向于保守的预测置信度。
-
理论与实验验证优势:该方法受贝叶斯框架启发,在理论上,其模型置信度具有数据自适应的上界,这为TTA方法处理不同可靠性的测试样本提供了理论依据;在实践中,通过大量实验验证,在常用基准测试中,它始终优于先前基于熵最小化(EM)的TTA方法,在分类准确性和不确定性估计方面都有显著改进。
-
明确方法优缺点:该方法的优势在于不确定性正则化简单且易于部署,符合TTA的效率要求;局限性在于当预训练模型也存在过度自信问题时,这种正则化的效果可能会减弱。
展望
-
探索更有效正则化技术:为了在TTA的实际需求和准确的不确定性估计之间实现更好的平衡,研究人员计划探索更有效的正则化技术,以克服当前方法的局限性。这将有助于进一步提高模型在复杂场景下的性能和可靠性。
-
研究适用于先进模型的TTA技术:随着视觉基础模型如DINOv2的发展,其学习到的特征表示比论文中使用的ImageNet预训练的ResNet和ViT模型更强大。因此,研究适用于这些更先进视觉基础模型的TTA技术是一个有前途的研究方向,有望进一步提升模型在各种任务中的表现。
-
深入研究不确定性学习与TTA的关系:许多最先进的TTA方法都采用了熵最小化学习原则,但该优化目标的潜在缺陷尚未完全理解。研究人员将进一步探索不确定性学习与可靠TTA过程之间的联系,这可能会为设计替代熵最小化的新型学习原则提供指导。
-
理论分析过度自信与模型崩溃的关系:研究人员还将从理论上进一步探究过度自信问题与模型崩溃之间的关系,以更好地理解模型在TTA过程中的行为,为改进模型性能提供更深入的理论支持。
8.【代码文件中文指南】
这是在ICLR 2025会议上发表的论文“COME:通过保守最小化熵实现测试时自适应”的官方代码实现。我们提出保守最小化熵(COME)方法,这是一种对熵最小化的简单改进,用于测试时自适应。
安装要求
要开始使用本代码库,你需要按照以下步骤进行安装:
pip install -r requirements.txt
数据准备
我们参照Robustness bench和OpenOOD的方式来准备数据集。以下是各数据集的下载链接:
-
ImageNet-C:从https://zenodo.org/record/2235448#.YpCSLxNBxAc下载。
- 以下数据集仅用于开放世界测试时自适应(TTA)设置:
-
iNaturalist:从https://ml-inat-competition-datasets.s3.amazonaws.com/2017/train_val_images.tar.gz下载。
-
NINCO、SSB_Hard、Texture、Open-ImageNet:从https://drive.google.com/drive/folders/1IFb4pPWTHsvWV6ezzbmGkIR64_VnOdSh?usp=drive_link下载。
-
使用示例
COME只需将先前TTA算法(如Tent、EATA和SAR)的损失函数从softmax熵替换为意见熵,即可轻松实现。
import torch
def entropy_of_opinion(x: torch.Tensor): # COME的关键组件
x = x / torch.norm(x, p=2, dim=-1, keepdim=True) * torch.norm(x, p=2, dim=-1, keepdim=True).detach()
brief = torch.exp(x) / (torch.sum(torch.exp(x), dim=1, keepdim=True) + 1000)
uncertainty = K / (torch.sum(torch.exp(x), dim=1, keepdim=True) + 1000)
probability = torch.cat([brief, uncertainty], dim=1) + 1e-7
entropy = -(probability * torch.log(probability)).sum(1)
return entropy
def forward_and_adapt(x, model, optimizer, args):
"""对一批数据进行前向传播并自适应调整模型。
计算模型预测的熵,计算梯度,并更新参数。
"""
outputs = model(x)
# COME:用entropy_of_opinion替换softmax_entropy
loss = entropy_of_opinion(outputs)
loss = loss.mean(0)
loss.backward()
optimizer.step()
optimizer.zero_grad()
return outputs
复现结果
基线
-
no_adapt (source):未经任何自适应调整的原始模型。
-
Tent、EATA、SAR:先前使用熵最小化的TTA方法。
-
Tent_COME、EATA_COME、SAR_COME:增强后的COME版本。
运行代码
要运行实验,请执行脚本start.sh。
结果
ImageNet-C(Level 5)上的分类准确率对比。相较于基线有显著(≥ 0.5)提升的结果用“+”标记。
结果
ImageNet-C(第5级)上的分类准确率对比。相较于基线有显著(≥0.5)提升的结果用“+”标记。
| 方法 | 是否使用COME | 高斯噪声 | 散粒噪声 | 脉冲噪声 | 散焦模糊 | 玻璃模糊 | 运动模糊 | 缩放模糊 | 雪噪声 | 霜噪声 | 雾噪声 | 亮度 | 对比度 | 弹性变换 | 像素化 | JPEG压缩 | 平均准确率提升 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 无自适应调整(原始模型) | ✗ | 35.1 | 32.2 | 35.9 | 31.4 | 25.3 | 39.4 | 31.6 | 24.5 | 30.1 | 54.7 | 64.5 | 49.0 | 34.2 | 53.2 | 56.5 | 39.8 |
| Tent | ✗ | 52.4 | 51.8 | 53.3 | 53.0 | 47.6 | 56.8 | 47.6 | 10.6 | 28.0 | 67.5 | 74.2 | 67.4 | 50.2 | 66.7 | 64.6 | 52.8 |
| Tent(使用COME) | ✓ | 53.8 | 53.7 | 55.3 | 55.7 | 51.7 | 59.7 | 52.7 | 59.0 | 61.7 | 71.3 | 78.2 | 68.7 | 57.7 | 70.5 | 68.2 | 61.2 |
| 提升幅度 | - | +1.4 | +1.9 | +1.9 | +2.7 | +4.1 | +2.9 | +5.0 | +48.4 | +33.6 | +3.9 | +4.0 | +1.3 | +7.5 | +3.8 | +3.6 | +8.4 |
| EATA | ✗ | 55.9 | 56.5 | 57.1 | 54.1 | 53.3 | 61.9 | 58.7 | 62.1 | 60.2 | 71.3 | 75.4 | 68.5 | 62.8 | 69.3 | 66.6 | 62.2 |
| EATA(使用COME) | ✓ | 56.2 | 56.6 | 57.2 | 58.1 | 57.6 | 62.5 | 59.5 | 65.5 | 63.9 | 72.5 | 78.1 | 69.7 | 66.5 | 72.4 | 70.7 | 64.5 |
| 提升幅度 | - | +0.3 | +0.2 | +0.1 | +4.1 | +4.3 | +0.6 | +0.7 | +3.5 | +3.7 | +1.2 | +2.7 | +1.2 | +3.7 | +3.1 | +4.0 | +2.2 |
| SAR | ✗ | 52.7 | 52.1 | 53.6 | 53.5 | 48.9 | 56.7 | 48.8 | 22.5 | 51.9 | 67.5 | 73.4 | 66.8 | 52.7 | 66.3 | 64.5 | 55.5 |
| SAR(使用COME) | ✓ | 56.2 | 56.5 | 57.5 | 58.3 | 56.7 | 62.9 | 58.2 | 65.3 | 64.8 | 72.6 | 78.5 | 69.3 | 64.4 | 71.9 | 69.5 | 64.2 |
| 提升幅度 | - | +3.5 | +4.4 | +3.8 | +4.8 | +7.7 | +6.2 | +9.5 | +42.9 | +12.8 | +5.0 | +5.1 | +2.5 | +11.6 | +5.6 | +5.0 | +8.7 |
关注下方《AI前沿速递》🚀🚀🚀
获取更多优质AI前沿内容
码字不易,欢迎大家点赞评论收藏

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 11
11 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)