
树莓派智能语音助手之首次RASA模型训练
终于在树莓派上安装了rasa(见《树莓派智能语音助手之聊天机器人-RASA》https://blog.csdn.net/hydekong/article/details/141285925),接下来就要学习怎么训练模型,逐步实现真正的语音助手。这就是我训练的第一个中文模型。可以看到,根据user输入的“你好”,chatbot最终判断消息意图是greet,于是chatbot会回复“你好呀”。个人理解
终于在树莓派上安装了rasa(见《树莓派智能语音助手之聊天机器人-RASA》),接下来就要学习怎么训练模型,逐步实现真正的语音助手。
第一次训练模型,主要是大概了解下各个组成模块。在我的rasa1.4.0版本生成的工程文件夹下有如下这几个文件:
actions.py # 自定义执行动作的代码
config.yml # 对NLU和Core模型的配置
domain.yml # 领域配置
credentials.yml # 证书配置,用于调用语音通道的接口
endpoints.yml # 端点配置,如:机器人要使用的模型、动作、存储服务等
data/nlu.yml # NLU训练数据
data/stories.yml # 故事编写文件
models/.tar.g # 初始化模型
模仿CSDN上的文章ubuntu安装rasa_unbuntu20.04安装rasa-CSDN博客,开始第一次rasa train。
config.yml
# Configuration for Rasa NLU.
# https://rasa.com/docs/rasa/nlu/components/
language: zh
pipeline: supervised_embeddings
# Configuration for Rasa Core.
# https://rasa.com/docs/rasa/core/policies/
policies:
- name: MemoizationPolicy
- name: KerasPolicy
- name: MappingPolicy
基本上就是rasa init成功后的那份。在没有完全理解各项定以前,不要随便复制网上的参考文档,这会影响到后续训练的成功与否。
credentials.yml
就直接在末尾添加:
rasa:
url: "http://localhost:5005/api"
endpoints.yml
文档里就有下面内容,打开后确认下是否存在,若没有就把它加上去。
action_endpoint:
url: http://localhost:5055/webhook
domain.yml
个人理解,这个文档就是定义chatbot的行为:Intent定义的是对话场景下的意图;actions定义的是基于该意图chatbot能采取的动作;templates则是对应动作所反馈的对话内容。
intents:
- greet
- goodbye
- mood_great
- mood_unhappy
actions:
- utter_greet
- utter_happy
- utter_goodbye
- utter_unhappy
templates:
utter_greet:
- text: "你好呀"
utter_happy:
- text: "太棒了,加油"
utter_unhappy:
- text: "可以告诉我发生了什么事"
utter_goodbye:
- text: "再见"
session_config:
session_expiration_time: 60
carry_over_slots_to_new_session: true
nlu.md
个人理解,nlu收录的是user的可能会话,在整个对话过程,chatbot会根据这个文件来预测user消息的意图。
## intent:greet
- 嗨
- 你好
- 今天顺利吗
- 你吃了吗
## intent:goodbye
- 再见
- 明天见
- 一会儿见
## intent:mood_great
- 我很好
- 真神奇
- 很棒
- 太好了
## intent:mood_unhappy
- 难过
- 我不开心
- 真糟糕
- 太恐怖了
stories.md
个人理解stories定义的是互动关系(即user说了什么,chatbot会怎么反应)。
## greet_happy
* greet
- utter_greet
* mood_great
- utter_happy
## greet_unhappy
* greet
- utter_greet
* mood_unhappy
- utter_unhappy
## user leaves
* goodbye
- utter_goodbye
修改完上述文档,执行rasa train,开始训练模型。训练过程中若报错了,需要根据报错信息修改对应文件内容。训练完成会告知在model文件夹下生成了一个新的模型。
重新执行rasa shell,这时候会自动调取最新的模型来用。我执行输入了 rasa shell nlu,看一下 nlu 输出的结构化数据。
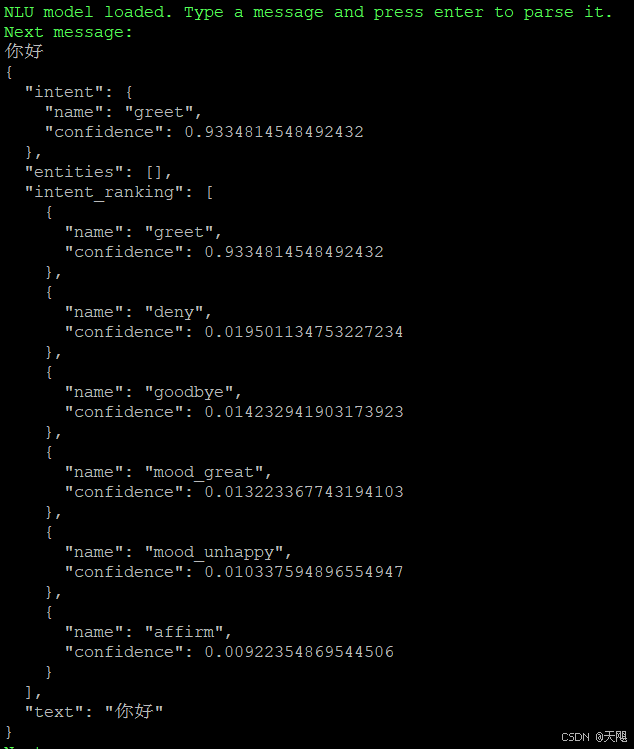
可以看到,根据user输入的“你好”,chatbot最终判断消息意图是greet,于是chatbot会回复“你好呀”。
这就是我训练的第一个中文模型。这就是个极简模型,只能按照定义的文本一问一答,超出了“天就聊不下去了”。要真正用好rasa还有很长的路要走啊!

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)