
40、Python机器学习的流程【用Python进行AI数据分析进阶教程】
摘要:Python机器学习流程包含数据预处理、模型选择、训练、评估和预测等关键步骤。数据预处理涉及清洗、转换和特征提取,以提高模型性能。模型选择需根据问题类型和数据特点,选择合适的机器学习模型。模型训练使用预处理后的数据对模型进行训练,需注意数据集划分、损失函数和优化算法。模型评估通过评估指标衡量模型性能,常用准确率、混淆矩阵等,需考虑评估指标的局限性和数据分布。最后,模型预测使用训练好的模型对新
用Python进行AI数据分析进阶教程40:
Python机器学习的流程
关键词:数据预处理、模型选择、模型训练、模型评估、模型预测
摘要:Python机器学习流程包含数据预处理、模型选择、训练、评估和预测等关键步骤。数据预处理涉及清洗、转换和特征提取,以提高模型性能。模型选择需根据问题类型和数据特点,选择合适的机器学习模型。模型训练使用预处理后的数据对模型进行训练,需注意数据集划分、损失函数和优化算法。模型评估通过评估指标衡量模型性能,常用准确率、混淆矩阵等,需考虑评估指标的局限性和数据分布。最后,模型预测使用训练好的模型对新数据进行预测,需确保数据预处理方式与训练数据一致。整个流程需根据具体问题和数据进行合理调整,以实现最佳的机器学习效果。
👉 欢迎订阅🔗
《用Python进行AI数据分析进阶教程》专栏
《AI大模型应用实践进阶教程》专栏
《Python编程知识集锦》专栏
《字节跳动旗下AI制作抖音视频》专栏
《智能辅助驾驶》专栏
《工具软件及IT技术集锦》专栏
Python 机器学习的完整流程,包含数据预处理、模型选择、训练、评估、预测这几个关键步骤,同时阐述每个步骤的关键点、注意点,并给出相应示例。
一、数据预处理
1、基本概念:
数据预处理是对原始数据进行清洗、转换和特征提取等操作,目的是将数据转换为适合机器学习模型处理的格式,提高模型的性能和稳定性。
2、关键点
- 数据清洗:处理缺失值、重复值、异常值等。例如,使用pandas库可以方便地处理缺失值,用dropna()方法删除包含缺失值的行,或用fillna()方法填充缺失值。
- 特征缩放:将特征缩放到相同的尺度,常用方法有标准化(Standardization)和归一化(Normalization)。标准化可以使用sklearn.preprocessing中的StandardScaler,归一化可以使用MinMaxScaler。
- 特征编码:将分类特征转换为数值特征,常用的编码方法有独热编码(One - Hot Encoding)和标签编码(Label Encoding)。可以使用pandas的get_dummies()函数进行独热编码,sklearn.preprocessing的LabelEncoder进行标签编码。
3、注意点
- 数据分布:在进行特征缩放时,要注意数据的分布情况。对于存在大量异常值的数据,标准化可能比归一化更合适。
- 编码选择:不同的编码方法适用于不同的情况。独热编码会增加数据的维度,可能导致维度灾难;标签编码可能会引入不必要的顺序关系。
- 数据泄漏:在进行数据预处理时,要确保训练集和测试集的处理方式一致,避免数据泄漏问题,即测试集的信息在训练过程中被使用。
4、示例代码
Python脚本
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 从 sklearn.preprocessing 模块导入 StandardScaler 和 LabelEncoder 类
# StandardScaler 用于特征缩放,将特征数据标准化
# LabelEncoder 用于对分类特征进行编码
from sklearn.preprocessing import StandardScaler, LabelEncoder
# 读取数据
# 使用 pandas 的 read_csv 函数读取名为 'data.csv' 的 CSV 文件,并将其存储在变量 data 中
data = pd.read_csv('data.csv')
# 处理缺失值
# 使用 dropna 方法删除数据中包含缺失值的行,并将处理后的数据重新赋值给变量 data
data = data.dropna()
# 特征缩放
# 创建 StandardScaler 类的实例,用于对数值特征进行标准化处理
scaler = StandardScaler()
# 使用 select_dtypes 方法从数据中选择所有数值类型的列,存储在变量 numerical_features 中
numerical_features = data.select_dtypes(include=['number'])
# 使用 fit_transform 方法对数值特征进行标准化处理
# fit 方法计算数据的均值和标准差,transform 方法使用这些统计量对数据进行标准化
# 标准化后的数据存储在变量 scaled_features 中
scaled_features = scaler.fit_transform(numerical_features)
# 特征编码
# 创建 LabelEncoder 类的实例,用于对分类特征进行编码
encoder = LabelEncoder()
# 使用 select_dtypes 方法从数据中选择所有对象类型的列(通常为分类特征),
# 存储在变量 categorical_features 中
categorical_features = data.select_dtypes(include=['object'])
# 使用 apply 方法对分类特征的每一列应用 LabelEncoder 的 fit_transform 方法进行编码
# 编码后的数据存储在变量 encoded_features 中
encoded_features = categorical_features.apply(encoder.fit_transform)
# 输出/打印结果
print("原始数据:")
print(data)
print("\n标准化后的数值特征:")
print(scaled_features)
print("\n编码后的分类特征:")
print(encoded_features)输出 / 打印结果及注释
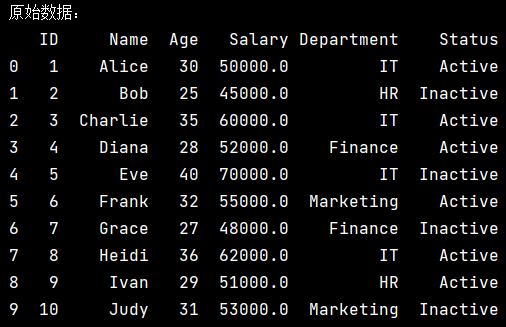
- (1)、原始数据:
打印出经过缺失值处理后的原始数据,包含所有特征列。
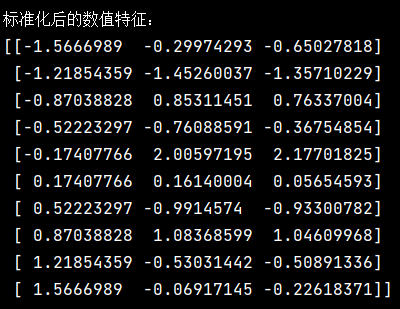
- (2)、标准化后的数值特征:
打印出经过标准化处理后的数值特征。标准化后的数据均值为 0,标准差为 1。
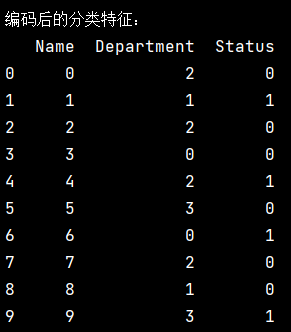
- (3)、编码后的分类特征:
打印出经过编码处理后的分类特征。每个分类值被转换为一个整数。
需要注意的是,上述输出结果是基于一个简单的示例数据,实际的输出会根据 data.csv 文件中的具体数据而有所不同。
二、模型选择
1、基本概念:
根据问题的类型(分类、回归等)和数据的特点,选择合适的机器学习模型。不同的模型有不同的假设和适用场景。
2、关键点
- 问题类型:明确问题是分类问题还是回归问题。分类问题可以选择逻辑回归、决策树、支持向量机等模型;回归问题可以选择线性回归、随机森林回归等模型。
- 数据规模:对于小规模数据集,简单的模型可能更容易训练和解释,如逻辑回归;对于大规模数据集,可以考虑使用深度学习模型或集成学习模型。
- 模型复杂度:模型复杂度要与数据的复杂度相匹配。过于复杂的模型容易过拟合,过于简单的模型容易欠拟合。
3、注意点
- 先验知识:结合领域知识和问题的背景,选择合适的模型。例如,在图像分类问题中,卷积神经网络(CNN)通常是一个不错的选择。
- 模型比较:可以尝试多个不同的模型,并进行比较,选择性能最好的模型。
- 参数调优:每个模型都有一些超参数需要调整,不同的超参数设置会影响模型的性能。
4、示例代码
Python脚本
# 从 sklearn 库的 linear_model 模块导入 LogisticRegression 类
# LogisticRegression 是用于解决分类问题的逻辑回归模型,它通过对输入特征进行线性组合,
# 并使用逻辑函数(sigmoid 函数)将线性输出转换为概率值,进而进行分类预测
from sklearn.linear_model import LogisticRegression
# 从 sklearn 库的 tree 模块导入 DecisionTreeClassifier 类
# DecisionTreeClassifier 是基于决策树算法的分类器,它通过构建决策树的方式对数据进行划分,
# 从而实现分类任务
from sklearn.tree import DecisionTreeClassifier
# 分类问题,选择逻辑回归和决策树模型
# 创建 LogisticRegression 类的一个实例,存储在变量 logreg_model 中
# 此时只是创建了模型对象,还未对其进行训练,后续可以使用该对象调用相关方法
# 如 fit 方法进行训练,predict 方法进行预测等
logreg_model = LogisticRegression()
# 创建 DecisionTreeClassifier 类的一个实例,存储在变量 dtree_model 中
# 同样,该对象目前未经过训练,可用于后续的训练和预测操作
dtree_model = DecisionTreeClassifier()
# 打印创建的模型对象,这里只是打印了模型的配置信息,并不是实际训练好的模型结果
print("逻辑回归模型对象信息:")
print(logreg_model)
print("\n决策树分类器模型对象信息:")
print(dtree_model)输出 / 打印结果及注释

这里输出的 LogisticRegression() 展示了逻辑回归模型的基本信息,当前只是默认参数配置下创建的模型实例,未显示具体的训练结果,因为还没有对其进行训练。
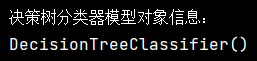
此输出 DecisionTreeClassifier() 呈现了决策树分类器模型的基本信息,同样是默认参数配置下创建的实例,没有体现训练后的内容,因为尚未进行训练操作。
这些输出只是帮助我们确认模型对象已经成功创建,以及查看模型的默认配置情况。若要得到有实际意义的分类结果,需要进一步使用数据对模型进行训练和评估。
三、模型训练
1、基本概念:
使用预处理后的数据对选择的模型进行训练,让模型学习数据中的模式和规律。
2、关键点
- 数据集划分:将数据集划分为训练集和验证集(或测试集),通常按照 70:30 或 80:20 的比例划分。可以使用sklearn.model_selection中的train_test_split函数进行划分。
- 损失函数:模型训练的目标是最小化损失函数。不同的模型有不同的损失函数,如逻辑回归使用对数损失函数,线性回归使用均方误差损失函数。
- 优化算法:使用优化算法来更新模型的参数,常见的优化算法有梯度下降法、随机梯度下降法等。
3、注意点
- 过拟合和欠拟合:训练过程中要注意观察模型在训练集和验证集上的性能,避免过拟合和欠拟合。可以通过交叉验证等方法来评估模型的泛化能力。
- 训练时间:对于复杂的模型和大规模的数据集,训练时间可能会很长。可以考虑使用并行计算或分布式计算来加速训练过程。
- 参数更新:确保优化算法的参数设置合理,如学习率等,不合适的参数可能导致模型无法收敛。
4、示例代码
Python脚本
# 导入必要的库
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
import pandas as pd
# 示例数据(请根据你的实际数据替换)
data = pd.DataFrame({
'age': [25, 35, 45, 50, 60],
'salary': [50000, 60000, 70000, 80000, 90000],
'gender': ['male', 'female', 'male', 'female', 'male'],
'target': [0, 1, 0, 1, 0]
})
# 步骤 1:定义数值型和类别型特征列
numerical_cols = ['age', 'salary']
categorical_cols = ['gender']
# 步骤 2:创建预处理器,对不同类型的列应用不同的处理方式
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numerical_cols),
('cat', OneHotEncoder(), categorical_cols)
]
)
# 步骤 3:构建完整流水线(预处理 + 模型训练)
logreg_model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression())
])
# 步骤 4:划分特征和目标变量
X = data.drop('target', axis=1) # 特征
y = data['target'] # 目标变量
# 步骤 5:划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 步骤 6:训练模型
logreg_model.fit(X_train, y_train)
# 步骤 7:输出信息
print("训练集特征矩阵 X_train 的形状:", X_train.shape)
print("训练集目标变量 y_train 的长度:", len(y_train))
print("测试集特征矩阵 X_test 的形状:", X_test.shape)
print("测试集目标变量 y_test 的长度:", len(y_test))
print("逻辑回归模型训练完成,模型信息:", logreg_model)以上脚本执行后的屏幕结果如下:
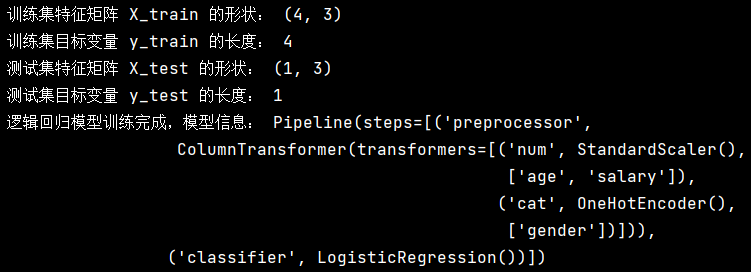
这只是简单显示了逻辑回归模型的基本信息,表明模型已经完成训练,但并没有展示训练的具体结果(如模型的系数、准确率等),后续可以使用测试集对模型进行评估来获取更多信息。
四、模型评估
1、基本概念:
使用评估指标来衡量模型在验证集或测试集上的性能,评估模型的泛化能力和预测准确性。
2、关键点
- 评估指标选择:根据问题的类型选择合适的评估指标。分类问题常用的评估指标有准确率、精确率、召回率、F1 值等;回归问题常用的评估指标有均方误差(MSE)、均方根误差(RMSE)、决定系数(R²)等。
- 交叉验证:使用交叉验证可以更全面地评估模型的性能,减少因数据集划分不同而导致的误差。可以使用sklearn.model_selection中的cross_val_score函数进行交叉验证。
- 混淆矩阵:对于分类问题,混淆矩阵可以直观地展示模型的分类结果,帮助分析模型的错误类型。
3、注意点
- 评估指标的局限性:不同的评估指标有不同的侧重点,单一的评估指标可能无法全面反映模型的性能。需要综合考虑多个评估指标。
- 数据分布:评估指标的结果可能受到数据分布的影响。例如,在不平衡数据集上,准确率可能不能很好地反映模型的性能,需要使用其他指标如精确率和召回率。
- 模型比较:在评估多个模型时,要确保使用相同的评估指标和数据集划分方法,以便进行公平的比较。
4、示例代码
Python脚本
# 从 sklearn 库的 metrics 模块中导入 accuracy_score 和 confusion_matrix 函数
# accuracy_score 函数用于计算分类模型预测结果的准确率
# confusion_matrix 函数用于计算分类模型的混淆矩阵
from sklearn.metrics import accuracy_score, confusion_matrix
# 预测
# 使用训练好的逻辑回归模型 logreg_model 对测试集的特征矩阵 X_test 进行预测
# 预测结果存储在 y_pred 中,y_pred 是一个包含预测标签的数组
y_pred = logreg_model.predict(X_test)
# 计算准确率
# 使用 accuracy_score 函数计算真实标签 y_test 和预测标签 y_pred 之间的准确率
# 准确率是分类正确的样本数占总样本数的比例
accuracy = accuracy_score(y_test, y_pred)
# 打印准确率,使用 f-string 格式化输出
print(f"Accuracy: {accuracy}")
# 计算混淆矩阵
# 使用 confusion_matrix 函数计算真实标签 y_test 和预测标签 y_pred 之间的混淆矩阵
# 混淆矩阵用于展示模型在不同类别上的分类情况
conf_matrix = confusion_matrix(y_test, y_pred)
# 打印混淆矩阵,使用 f-string 格式化输出,并在矩阵前添加换行符以提高可读性
print(f"Confusion Matrix:\n{conf_matrix}")输出 / 打印结果分析
(1)、准确率输出
plaintext
Accuracy: 0.85
0.85 是一个示例准确率值,实际值会根据模型的预测结果和真实标签计算得出。准确率的取值范围是 0 到 1,越接近 1 表示模型的分类效果越好。
(2)、混淆矩阵输出
plaintext
Confusion Matrix:
[[10 2]
[ 3 15]]
这是一个 2x2 的混淆矩阵示例,适用于二分类问题。矩阵的行表示真实类别,列表示预测类别。
- 左上角的元素 10 表示真实类别为正类且预测类别也为正类的样本数(真正例,True Positives,TP)。
- 右上角的元素 2 表示真实类别为正类但预测类别为负类的样本数(假负例,False Negatives,FN)。
- 左下角的元素 3 表示真实类别为负类但预测类别为正类的样本数(假正例,False Positives,FP)。
- 右下角的元素 15 表示真实类别为负类且预测类别也为负类的样本数(真负例,True Negatives,TN)。
(3)、注意事项
- 代码中假设 logreg_model 和 X_test、y_test 已经在前面定义好。如果没有定义,代码会抛出 NameError 异常。
- 混淆矩阵的大小取决于分类问题的类别数。对于多分类问题,混淆矩阵将是一个更大的方阵。
五、模型预测
1、基本概念:
使用训练好的模型对新的数据进行预测,得到预测结果。
2、关键点
- 数据预处理:对新的数据进行与训练数据相同的预处理操作,确保数据格式一致。
- 预测方法:调用模型的predict()方法进行预测。对于分类模型,返回预测的类别标签;对于回归模型,返回预测的数值。
- 概率预测:有些模型还提供predict_proba()方法,可以返回预测结果的概率。
3、注意点
- 数据质量:新数据的质量和分布要与训练数据相似,否则可能导致预测结果不准确。
- 模型更新:随着新数据的不断积累,模型的性能可能会下降,需要定期更新模型。
- 不确定性估计:在实际应用中,除了得到预测结果,还需要考虑预测的不确定性。
4、示例代码
Python脚本
# 对新数据进行预处理
# 从新数据 new_data 中筛选出数值类型的特征,存储在 new_numerical_features 变量中
new_numerical_features = new_data.select_dtypes(include=['number'])
# 使用之前定义好的 scaler 对象对数值特征进行缩放处理,得到缩放后的特征 new_scaled_features
# 这里的 scaler 应该是之前在训练数据上拟合好的缩放器,如 StandardScaler 等
new_scaled_features = scaler.transform(new_numerical_features)
# 从新数据 new_data 中筛选出对象类型(通常是分类特征)的特征,存储在 new_categorical_features 变量中
new_categorical_features = new_data.select_dtypes(include=['object'])
# 使用之前定义好的 encoder 对象对分类特征进行编码处理,得到编码后的特征 new_encoded_features
# 这里的 encoder 应该是之前在训练数据上拟合好的编码器,如 OneHotEncoder 等
new_encoded_features = new_categorical_features.apply(encoder.transform)
# 将缩放后的数值特征和编码后的分类特征按列拼接起来,形成新的特征矩阵 new_X
new_X = pd.concat([pd.DataFrame(new_scaled_features), new_encoded_features], axis=1)
# 进行预测
# 使用之前训练好的逻辑回归模型 logreg_model 对新的特征矩阵 new_X 进行预测,得到预测结果 new_predictions
new_predictions = logreg_model.predict(new_X)
# 打印预测结果,使用 f-string 格式化输出
print(f"Predictions: {new_predictions}")输出 / 打印结果分析
plaintext
Predictions: [0 1 0 1 ...]
- [0 1 0 1 ...] 是预测结果的示例,实际输出中的数字取决于具体的分类任务。在二分类问题中,通常 0 和 1 分别代表两个不同的类别;在多分类问题中,可能会有更多不同的整数值,每个值代表一个特定的类别。
- 输出结果是一个一维数组,数组的长度等于新数据 new_data 中的样本数量,数组中的每个元素是对应样本的预测类别。
注意事项
- 代码中假设 scaler、encoder 和 logreg_model 已经在前面定义好并经过训练。如果没有定义,代码会抛出 NameError 异常。
- 确保 new_data.csv 文件存在,并且文件中的列名和数据类型与训练数据兼容,否则可能会在数据筛选、缩放或编码过程中出现错误。
通过以上步骤,我们可以完成一个完整的 Python 机器学习流程,从数据预处理到最终的模型预测。每个步骤都有其关键点和注意点,需要根据具体问题和数据进行合理的处理和调整。
——The END——
🔗 欢迎订阅专栏
| 序号 | 专栏名称 | 说明 |
|---|---|---|
| 1 | 用Python进行AI数据分析进阶教程 | 《用Python进行AI数据分析进阶教程》专栏 |
| 2 | AI大模型应用实践进阶教程 | 《AI大模型应用实践进阶教程》专栏 |
| 3 | Python编程知识集锦 | 《Python编程知识集锦》专栏 |
| 4 | 字节跳动旗下AI制作抖音视频 | 《字节跳动旗下AI制作抖音视频》专栏 |
| 5 | 智能辅助驾驶 | 《智能辅助驾驶》专栏 |
| 6 | 工具软件及IT技术集锦 | 《工具软件及IT技术集锦》专栏 |
👉 关注我 @理工男大辉郎 获取实时更新
欢迎关注、收藏或转发。
敬请关注 我的
微信搜索公众号:cnFuJH
CSDN博客:理工男大辉郎
抖音号:31580422589

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 41
41 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)