
[论文阅读]MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
最近的 GPT-4 展示了非凡的多模态能力,例如直接从手写文本生成网站和识别图像中的幽默元素。这些特征在以前的视觉语言模型中很少观察到。但是,GPT-4 背后的技术细节仍未披露。我们认为,GPT-4 增强的多模态生成能力源于对复杂大型语言模型的使用(LLM)。为了研究这种现象,我们提出了 MiniGPT-4,它使用一个投影层将冻结的视觉编码器与冻结的高级 LLM, Vicuna对齐。我们的工作首次
https://arxiv.org/abs/2304.10592
MiniGPT-4:使用高级大型语言模型增强视觉语言理解
摘要
最近的 GPT-4 展示了非凡的多模态能力,例如直接从手写文本生成网站和识别图像中的幽默元素。这些特征在以前的视觉语言模型中很少观察到。但是,GPT-4 背后的技术细节仍未披露。我们认为,GPT-4 增强的多模态生成能力源于对复杂大型语言模型的使用 (LLM)。为了研究这种现象,我们提出了 MiniGPT-4,它使用一个投影层将冻结的视觉编码器与冻结的高级 LLM, Vicuna对齐。我们的工作首次发现,将视觉特征与高级大型语言模型正确对齐可以拥有 GPT-4 演示的许多高级多模态能力,例如生成详细的图像描述和从手绘草稿创建网站。此外,我们还观察到 MiniGPT-4 中的其他新兴功能,包括受给定图像启发编写故事和诗歌、教用户如何根据食物照片烹饪等等。在我们的实验中,我们发现在短图像标题对上训练的模型可能会产生不自然的语言输出(例如,重复和碎片化)。为了解决这个问题,我们在第二阶段策划了一个详细的图像描述数据集来微调模型,从而提高模型的生成可靠性和整体可用性。我们的代码、预训练模型和收集的数据集可在 Minigpt-4 获取。
主要贡献:
- 我们的研究以令人信服的证据表明,通过将视觉特征与 Vicuna 等先进的大型语言模型保持一致,MiniGPT-4 可以实现与 GPT-4 演示中展示的功能相媲美的高级视觉语言能力。
- 我们的研究结果表明,仅训练一个投影层就可以有效地将预训练的视觉编码器与大型语言模型对齐。我们的 MiniGPT-4 只需要在 4 个 A100 GPU 上训练大约 10 小时。
- 我们发现,简单地使用短图像标题对将视觉特征与大型语言模型对齐不足以开发性能良好的模型,并且会导致不自然的语言生成。使用小而详细的图像描述对进行进一步微调可以解决此限制并显著提高其可用性。
方法介绍
使用Vicuna作为语言解码器,使用与BLIP-2相同的视觉编码器(该视觉编码器是与Q-Former结合的ViT骨架)
目标:使用线性投影层弥合视觉编码器和LLM
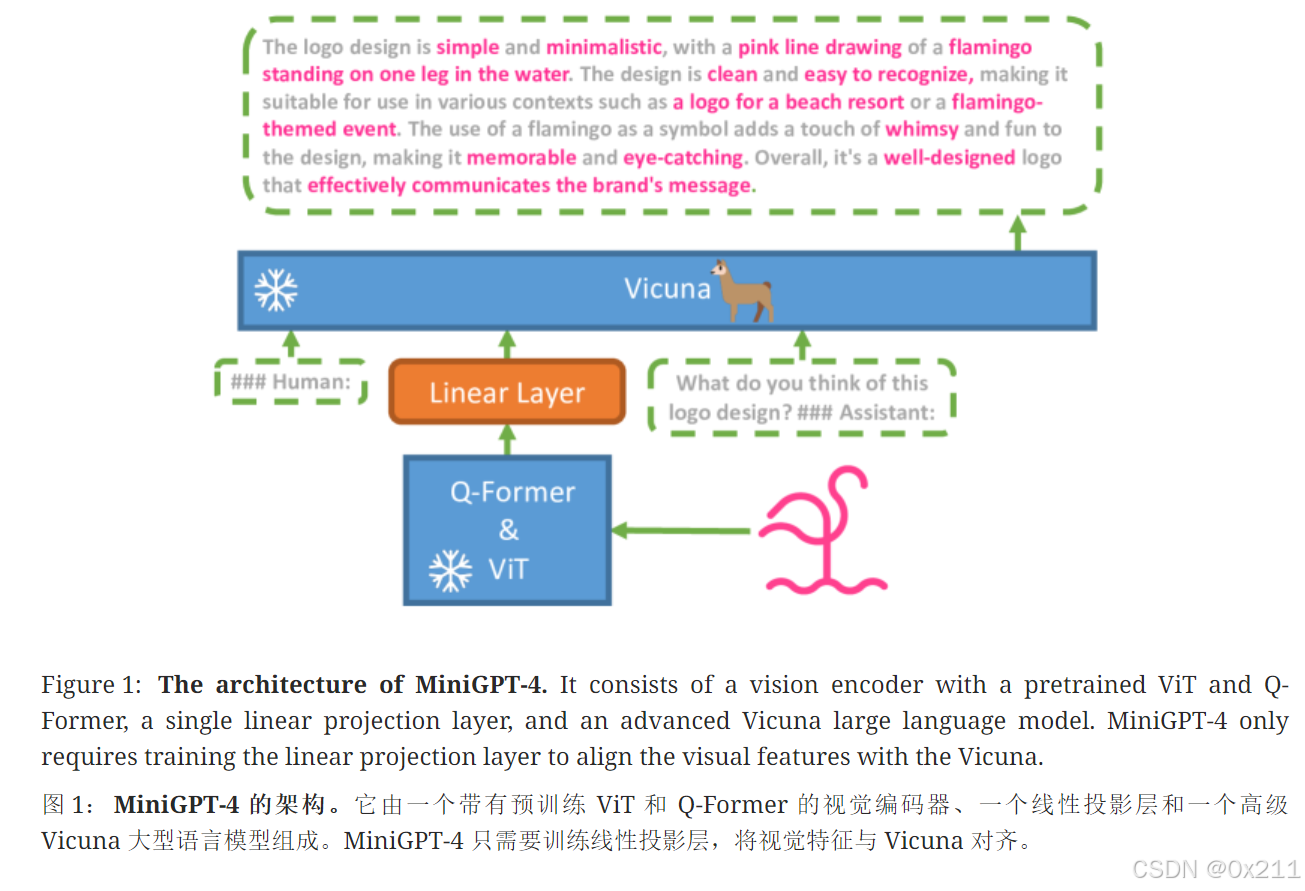
训练-阶段1
在大量对齐的图像-文本对上预训练模型,以获得视觉-语言知识
我们将注入投影层的输出视为对 LLM 的软提示,促使它生成相应的ground-truth文本。
整个预训练过程中,预训练的视觉编码器和 LLM 都保持冻结状态,只有线性投影层被预训练。我们使用概念标题的组合数据集、SBU 和 LAION 来训练我们的模型。我们的模型经历了 20000 个训练步骤,批量大小为 256,涵盖大约 500 万个图像-文本对。整个过程大约需要 10 小时才能完成,使用 4 个 A100 (80GB) GPU。
第一阶段训练后,MINI-GPT4展示了拥有丰富知识并对人类询问提供合理回应的能力。但是,我们观察到它会产生不连贯的语言输出,例如重复的单词或句子、碎片化的句子或不相关的内容。这些问题阻碍了 MiniGPT-4 与人类进行流畅的视觉对话的能力。
GPT-3中实际上也遇到了这些问题。GPT-3 难以生成与用户意图准确一致的语言输出。通过指令微调和来自人类反馈的强化学习过程,GPT-3 演变成 GPT-3.5,并能够产生更人性化的输出。这种现象与 MiniGPT-4 在初始预训练阶段之后的当前状态相似。因此,我们的模型在这个阶段可能难以生成流畅和自然的人类语言输出也就不足为奇了。
然后设计提示词让经过上一步训练的模型对图像进行详细的描述,如果生成的文本较少(少于80个token),则添加提示词”继续“,让模型继续生成相应文本。
上面提到了模型输出的不连贯性,因此把描述结果给Chat GPT,让Chat GPT对上面图像的描述进行一个信息精炼:”修复给定段落中的错误。删除任何重复的句子、无意义的字符、而不是英语句子等。删除不必要的重复。重写任何不完整的句子。直接返回结果,不作解释。如果输入段落已经正确,则直接返回该段落,而无需解释。“
手动过滤后,只有3500个满足要求的高质量图像-文本对,用于阶段2的训练
训练-阶段2
使用更小但高质量的图像文本数据集和设计的对话模板来微调预训练模型,以提高生成的可靠性和可用性。
微调过程非常高效,只需要 400 个训练步骤,批量大小为 12,使用单个 A100 GPU 大约需要 7 分钟。
总结
实验结果表明,MINIGPT-4可以比较有效地学习了GPT-4中的多模态功能,在meme解释、写诗、解释图像等多种图像-文本领域表现出了较好的输出结果。但是不可避免的是还是会存在幻觉问题。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 27
27 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)