
机器学习入门9--集成学习方法1
本系列博客基于温州大学黄海广博士的机器学习课程的笔记,小伙伴们想更详细学习黄博士课程请移步到黄博士的Github、或者机器学习初学者公众号,现在在中国慕课也是可以学习的,内容包括机器学习、深度学习及Python编程,matplotlib、numpy、pandas、sklearn等,资料很详细,要系统学习请移步哦!笔者的博客只是笔记,内容不会十分详细,甚至会有些少错误!1.集成学习方法概述1.1 B
·
本系列博客基于温州大学黄海广博士的机器学习课程的笔记,小伙伴们想更详细学习黄博士课程请移步到黄博士的Github、或者机器学习初学者公众号,现在在中国慕课也是可以学习的,内容包括机器学习、深度学习及Python编程,matplotlib、numpy、pandas、sklearn等,资料很详细,要系统学习请移步哦!笔者的博客只是笔记,内容不会十分详细,甚至会有些少错误!
1.集成学习方法概述
1.1 Bagging
- 从训练集中进行子抽样组成每个基模型所需要的子训练集,多所有基模型预测的结果进行综合产生最终的预测结果,如下:
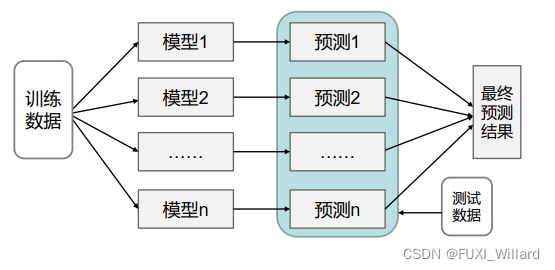
1.2 Boosting
- 训练过程为阶梯状,基模型按次序一一进行训练,基模型的训练集按照某种策略每次进行一定的转化,对所有基模型预测的结果进行线性综合产生最终的预测结果,如下:
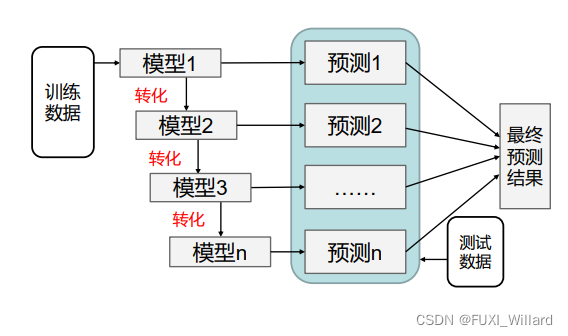
1.3 Stacking
- 将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练;同理,预测的过程要先经过所有基模型的预测形成新的测试集,最后对测试集进行预测;
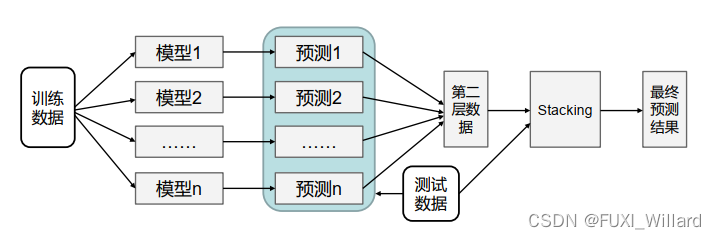
2.随机森林
2.1 随机森林(Random Forest)
-
用随机的方式建立一个森林,随机森林算法由很多决策树组成,每一棵决策树之间没有关联;建立完森林后,当有新样本进入时,每棵决策树都会分别进行判断,然后基于投票法给出分类结果;
-
优点:
- 在数据集上表现良好,相对于其他算法有较大的优势;
- 易于并行化,在大数据集上有很大的优势;
- 能够处理高维度数据,不用做特征选择;
-
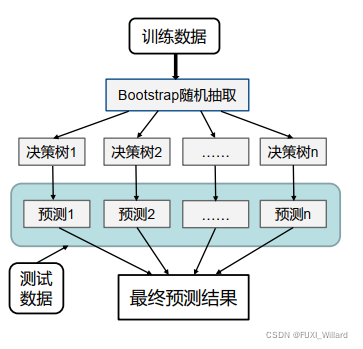
随机森林包括:
- 随机选择样本(放回抽样);
- 随机选择特征;
- 构建决策树;
- 随机森林投票(平均);
-
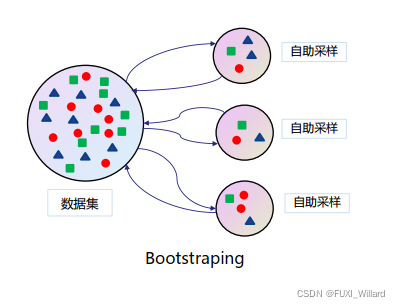
随机选择样本:采用Bootstraping自助采样法;
-
随机选择特征:在每个节点在分裂过程中都是随机选择特征的;
3.AdaBoost和GBDT算法
3.1 AdaBoost算法
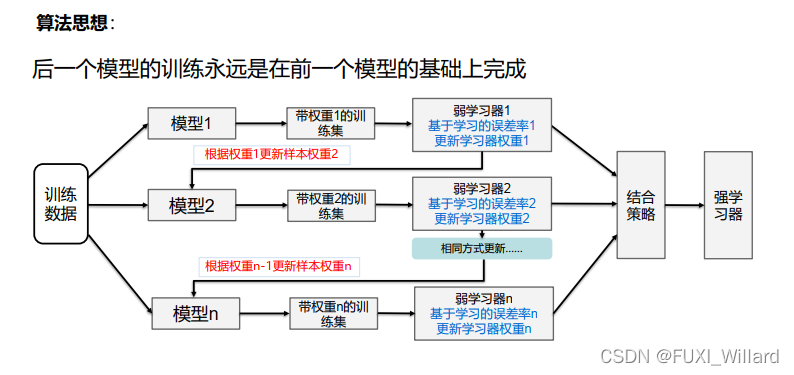
- AdaBoost(Adaptive Boosting,自适应增强):前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器;同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数;
3.2 算法思想
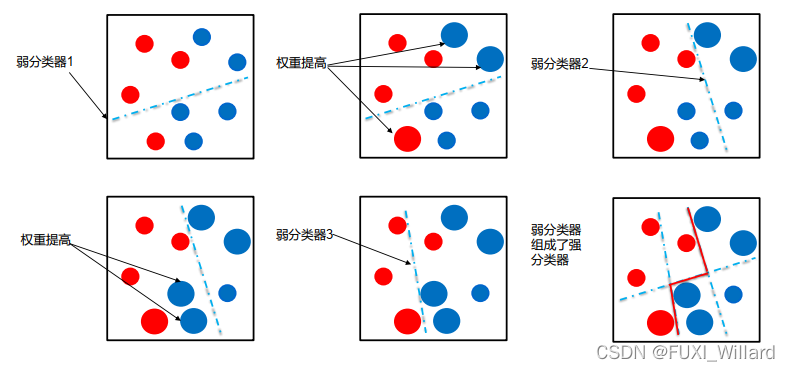
- 初始化训练样本的权值分布,每个样本具有相同权值;
- 训练弱分类器,如果样本分类正确,则在构造下一个训练集中,它的权值会被降低;反之提高;用更新过的样本集去训练下一个分类器;
- 将所有弱分类组合成强分类器,各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,降低分类误差率大的弱分类器的权重;
3.3 GBDT算法
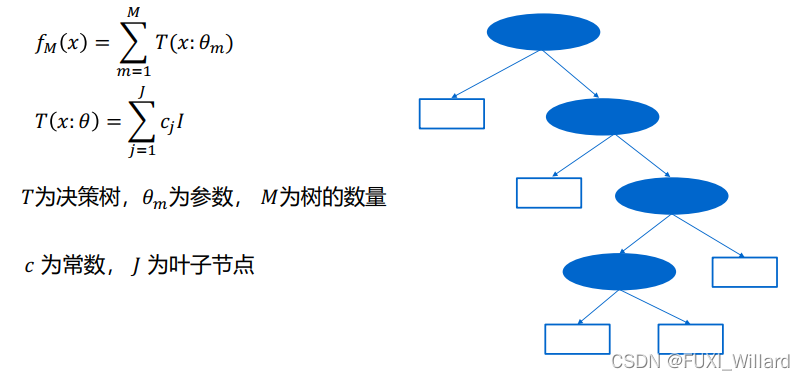
- GBDT(Gradient Boosting Decision Tree):一种迭代的决策树算法,该算法由多棵决策树组成;
- GBDT核心:在于累加所有树的结果作为最终结果,因此,GBDT的树是回归树,不是分类树;
- GBDT组成:Regression Decision Tree–DT;Gradient Boosting–GB;Shrinkage–缩减;
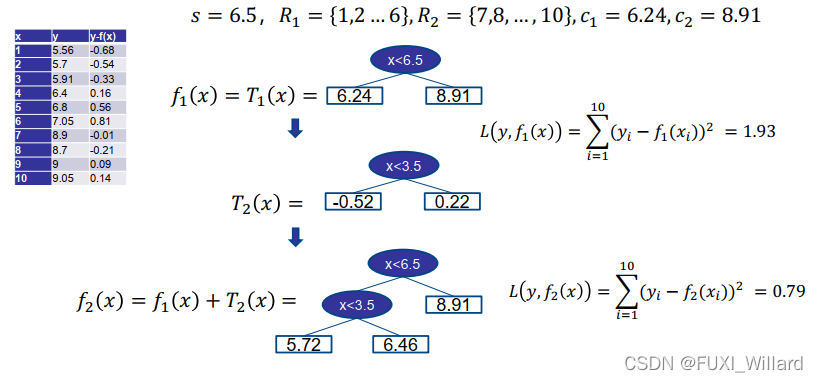
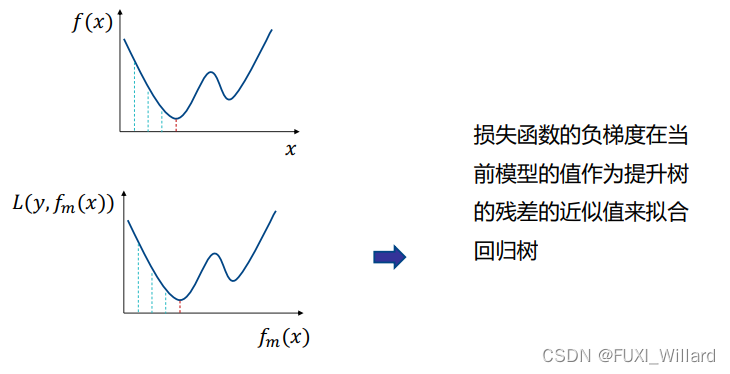
3.4 GBDT算法流程








GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)