
时间序列再获顶会最高分,多种全新SOTA带你猪突猛进,实力涨分!
时间序列分析在深度学习领域的重要性日益凸显,它通过深入挖掘和理解时间顺序数据的内在规律,极大地增强了模型在预测和模式识别任务中的性能。这一技术已经在金融、气象、健康监测等多个关键领域展现了其强大的应用潜力,成为当前研究的热点之一。为了促进大家对时间序列分析技术的深入理解和创新应用,我们精心筛选了近两年内发表在顶级会议和期刊上的20篇时间序列分析相关的重要研究。这些论文不仅涵盖了最新的研究成果,还提
时间序列分析在深度学习领域的重要性日益凸显,它通过深入挖掘和理解时间顺序数据的内在规律,极大地增强了模型在预测和模式识别任务中的性能。这一技术已经在金融、气象、健康监测等多个关键领域展现了其强大的应用潜力,成为当前研究的热点之一。
为了促进大家对时间序列分析技术的深入理解和创新应用,我们精心筛选了近两年内发表在顶级会议和期刊上的20篇时间序列分析相关的重要研究。这些论文不仅涵盖了最新的研究成果,还提供了相应的源代码,以供研究者参考和实践。
三篇论文详述
1、Masked Jigsaw Puzzle: A Versatile Position Embedding for Vision Transformers
方法
本论文提出了一种名为Masked Jigsaw Puzzle (MJP) 的位置嵌入方法,用于改进视觉变换器(Vision Transformers, ViTs)的性能和隐私保护能力。MJP方法包含以下几个核心步骤:
-
块状随机拼图洗牌算法:首先,通过这种算法随机选择一部分输入序列的图像块(patches),并对它们进行顺序的洗牌。
-
遮挡位置嵌入:对于被随机洗牌的图像块,使用一个共享的未知位置嵌入(Eunk)来代替它们原来的PEs,以减少位置信息的泄露。
-
强化非遮挡块的空间关系:对于未被洗牌的图像块,通过密集的绝对位置回归(Dense Absolute Localization, DAL)来加强它们的空间关系,以保持位置信息。
-
自监督学习:在训练过程中,通过自监督的方式学习DAL,以增强模型对未洗牌图像块的空间关系的感知。
创新点
-
位置嵌入的隐私保护:MJP通过遮挡和洗牌部分位置嵌入,减少了模型对输入图像块空间信息的依赖,从而降低了模型在梯度反转攻击下的隐私泄露风险。
-
性能与隐私的平衡:在保持ViTs的准确性的同时,MJP通过引入未知位置嵌入和强化空间关系的策略,提高了模型对图像块顺序变化的鲁棒性,增强了隐私保护能力。
-
自监督的空间关系强化:通过自监督的方式强化未被洗牌图像块的空间关系,MJP不仅提高了模型对图像的理解和分类能力,还提升了模型对图像变换的一致性。
-
通用性和实用性:MJP方法不仅适用于标准的ViTs,还适用于其他变体,如Swin Transformer,显示出良好的通用性和实用性。

IMG_256
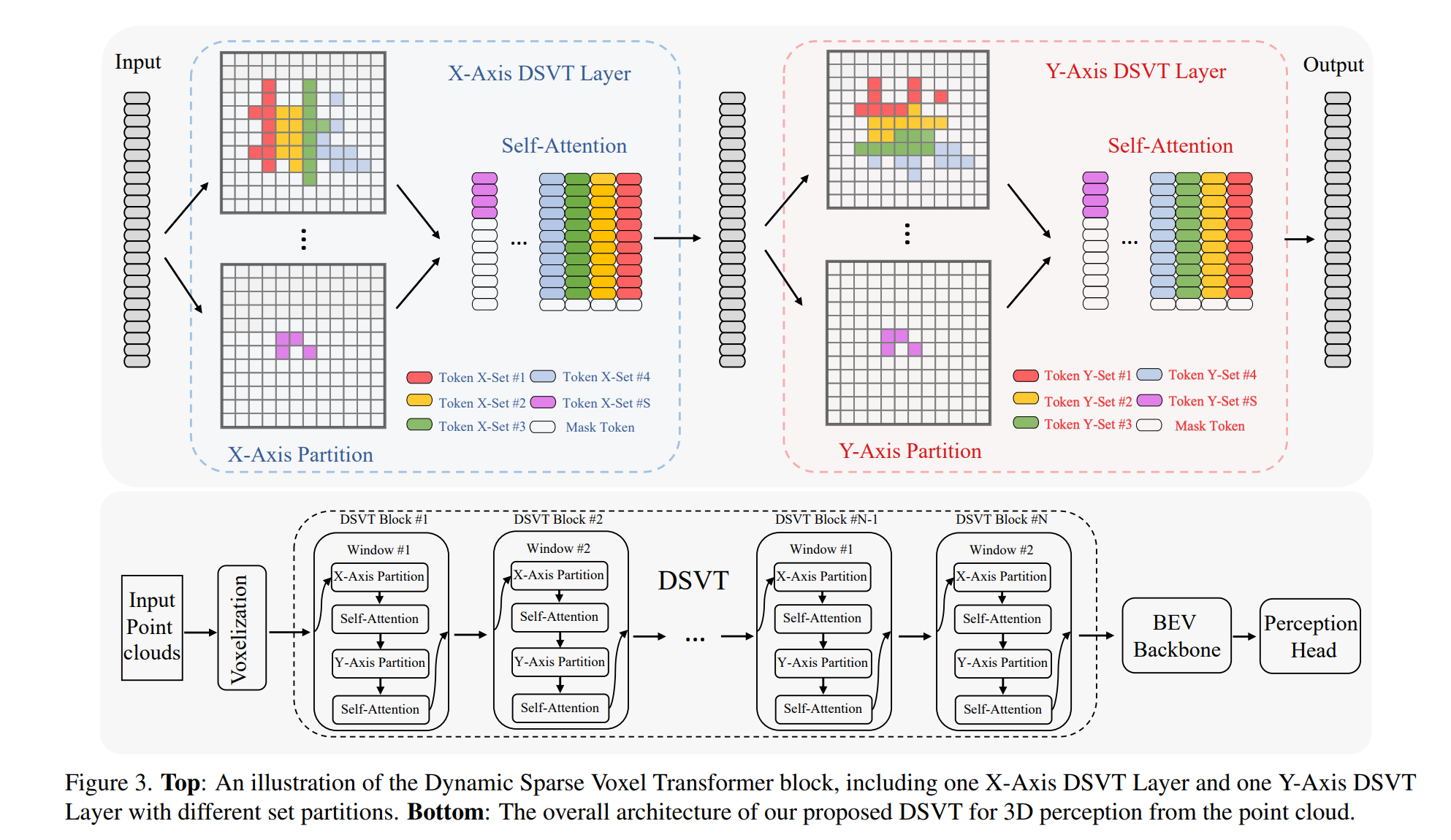
2、DSVT: Dynamic Sparse Voxel Transformer with Rotated Sets
方法
本论文提出了Dynamic Sparse Voxel Transformer (DSVT),这是一个用于户外3D感知的基于窗口的体素Transformer骨干网络。DSVT旨在高效处理稀疏点云数据,具体方法包括:
-
动态稀疏窗口注意力(Dynamic Sparse Window Attention):通过将每个窗口内的稀疏体素划分为一系列局部区域,并根据每个区域的稀疏性进行分区,然后以完全并行的方式计算所有区域的特征。
-
旋转集分区策略(Rotated Set Partitioning Strategy):为了允许跨集连接,设计了一种在连续自注意力层之间交替两种分区配置的策略。
-
注意力风格的3D池化模块(Attention-style 3D Pooling Module):为了有效下采样并更好地编码几何信息,提出了一种无需定制CUDA操作的强大且易于部署的3D池化操作。
-
单步长网络设计:采用单步长网络设计,不减少特征图在X/Y轴的尺度,以更好地进行户外3D目标检测。
-
基于注意力的3D骨干网络:整个网络完全基于注意力机制,无需任何自定义CUDA操作,易于在现代GPU上加速。
创新点
-
动态稀疏窗口注意力:提出了一种新颖的窗口基础注意力策略,可以高效并行处理稀疏3D体素,且完全基于深度学习框架中的优化操作,无需自定义CUDA代码。
-
旋转集分区策略:通过在连续的自注意力层之间改变分区轴(X轴和Y轴),增强了模型内部窗口融合的能力,提高了模型的表示能力。
-
注意力风格的3D池化操作:提出了一种新的3D池化操作,它在不牺牲性能的情况下减少了计算成本,并且可以自动聚合局部空间特征,提高了几何信息的编码效果。
-
易于部署的3D Transformer骨干网络:DSVT能够在不使用自定义CUDA操作的情况下实现高效的3D感知任务,并且可以轻松地通过NVIDIA TensorRT加速,达到实时推理速度。
-
在多个3D感知任务上达到最先进性能:DSVT在大规模Waymo和nuScenes数据集上的各种3D感知任务中均取得了优异的性能,超越了以往的最先进方法。
IMG_257
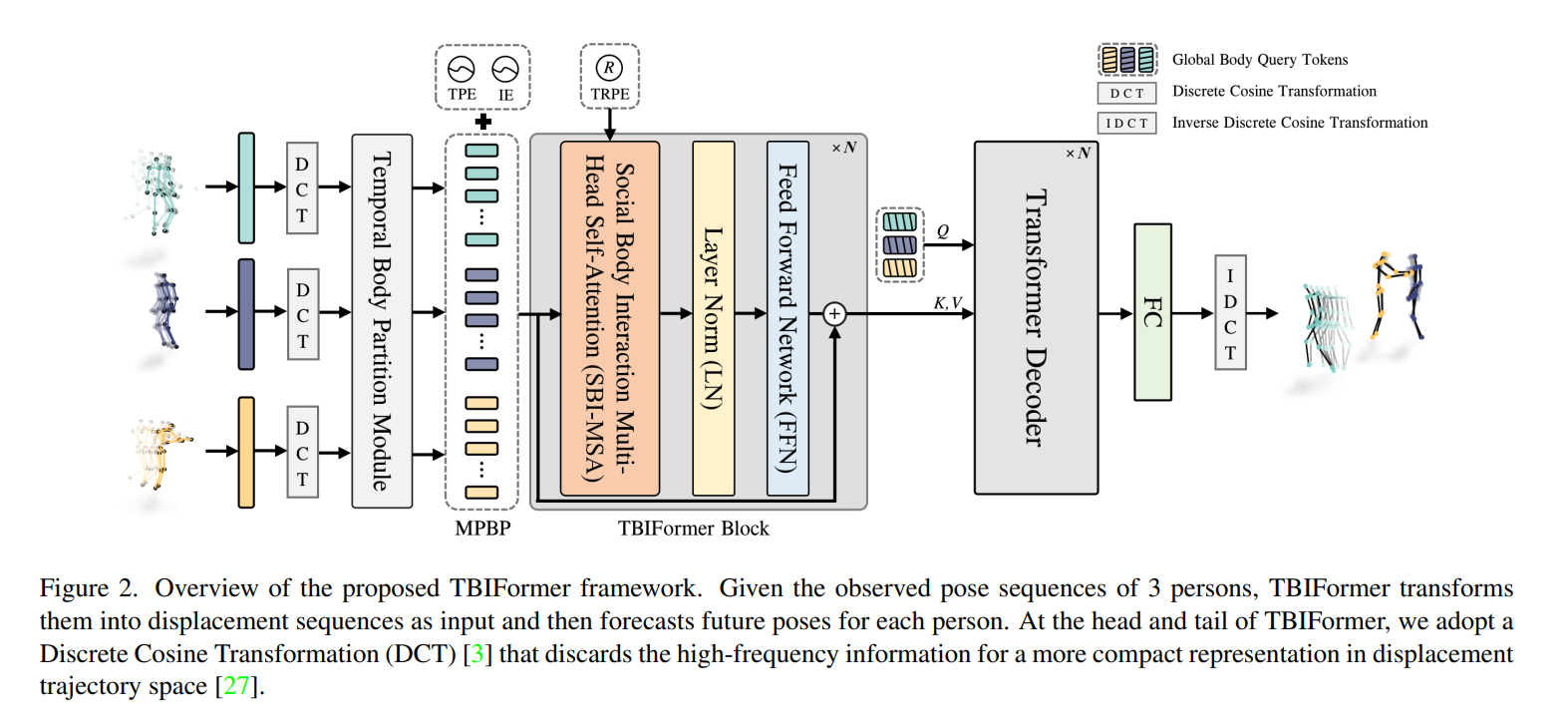
3、Trajectory-Aware Body Interaction Transformer for Multi-Person Pose Forecasting
方法
本论文提出了一种名为Trajectory-Aware Body Interaction Transformer (TBIFormer) 的模型,用于多人姿态预测。该模型通过有效建模身体部位间的交互来提高预测的准确性。具体方法包括:
-
Temporal Body Partition Module (TBPM):将每个人的姿势序列转换为包含身体部位的短时间周期序列,以保留空间和时间信息。
-
Social Body Interaction Multi-Head Self-Attention (SBI-MSA):利用转换后的序列学习个体间和个体内身体部位的动态。
-
Trajectory-Aware Relative Position Encoding:提出了一种新颖的相对位置编码方式,通过测量运动轨迹的相似性来提供区分性的空间信息和额外的交互线索。
-
Transformer Decoder:使用标准的Transformer解码器进一步考虑个体身体部位之间的当前和历史关系的预测,以生成每个人未来的运动轨迹。
创新点
-
TBPM模块:通过将原始姿势序列转换为多人身体部位序列,增强了网络对交互身体部位的建模能力。
-
SBI-MSA模块:通过测量身体部位的运动相似性而不是整个身体的相似性,学习跨个体的身体部位动态,有效捕获复杂人群中的细粒度身体交互依赖性。
-
Trajectory-Aware Relative Position Encoding:提出了一种基于轨迹的相对位置编码方法,通过动态时间弯曲(DTW)算法的变体Soft-DTW来测量轨迹相似性,提供了比基于欧几里得距离的空间编码更鲁棒和准确的空间信息。
-
在多个多人运动数据集上的实验:证明了所提出的方法在短期和长期预测方面均显著优于现有最先进方法,实现了预测精度的大幅提升。
-
考虑了个体间的全局位置变化和交互:与以往仅关注个体局部姿势动态预测的方法不同,TBIFormer同时考虑了全局身体轨迹和个体间的交互,这对于理解复杂3D环境中的人类行为至关重要。
IMG_258

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 23
23 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)