
DeepSeek R1 训练思路在法律垂类上的实践
背景随着DeepSeek-R1的发布,强化学习(RL)算法在推理任务中展现出巨大的潜力。DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在法律领域,DeepSeek-R1的应用前景广阔。例如,WhyHow.AI团队基于DeepSeek-R1模型进行了精细微调,开发了开源医疗法律模型PatientSeek。此外,通达海公司已将DeepS
背景
随着DeepSeek-R1的发布,强化学习(RL)算法在推理任务中展现出巨大的潜力。DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。
在法律领域,DeepSeek-R1的应用前景广阔。例如,WhyHow.AI团队基于DeepSeek-R1模型进行了精细微调,开发了开源医疗法律模型PatientSeek。 此外,通达海公司已将DeepSeek-R1接入其法律大模型,并在部分法院客户现场进行测试,以进一步优化和提升模型性能。
为了验证purl-rl是否真的在完全不需要做sft微调的情况下,能够在法律领域上面也带来提升,我们这里的实验完全是基于base model 并且和R1区别的是,为了更进一步保持rl算法的纯洁度,我们并没有使用监督数据来做cold start部分。直接跳过了cold start部分,直接在法律任务上面进行pure rl 训练。
GRPO
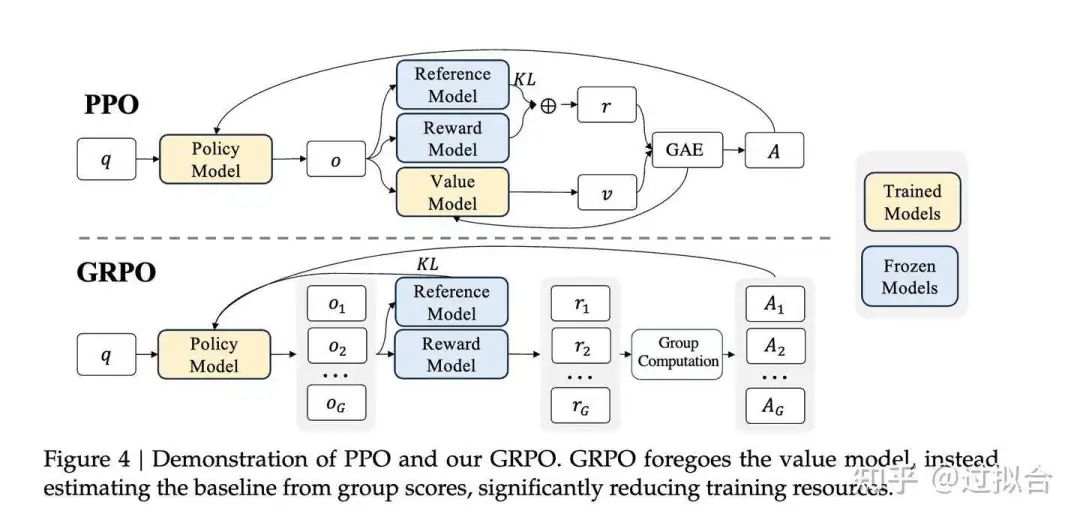
在强化学习(RL)中,Proximal Policy Optimization(PPO)算法通常需要训练一个与策略模型规模相当的价值函数模型,在RL训练过程中,价值函数被用作基线,以计算优势函数并减少方差。但是这会导致显著的内存和计算开销
然而,在大语言模型(LLM)的应用场景中,奖励模型通常只对最终生成的Token赋予奖励分数,这使得在每个Token上训练精确的价值函数变得复杂。
为了解决这一问题,deepseek提出了组相对策略优化(Group Relative Policy Optimization,GRPO)方法。与PPO不同,GRPO无需额外训练价值函数模型,而是通过对同一问题生成的多个采样输出的平均奖励进行基线化处理。
对于每个问题,GRPO从旧策略中采样一组输出,然后通过最大化以下目标来优化策略模型:
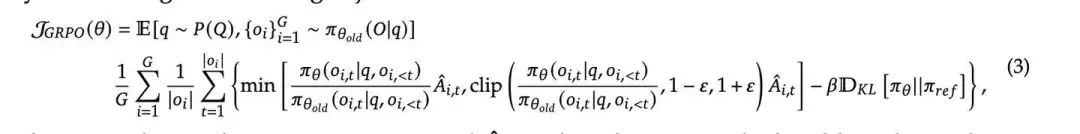
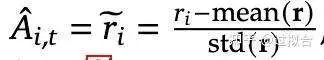
数据集介绍
数据来自中国裁判文书网发布的刑事案件法律文书。每份文书包含案件的事实描述和详细信息。每个案件还包括相关条款、被告的指控和刑期。
该数据集包含10000份刑事和民事法律文书,涵盖了202个指控、183个条款,刑期从0年到25年不等,包括终身监禁和死刑。
我们主要参考了cail2018的任务,cail2018是由中国电科团委、中国司法大数据研究院和中国中文信息学会共同主办的首届“中国法研杯”司法人工智能挑战赛。cail 2018主要是罪名预测,相关法条预测 ,刑期预测。在cail2018三个任务的基础上面,新增了对完整判决结果的评估。 总共以下四个任务:
任务1(指控预测):根据法律文书中的事实描述预测指控内容;
任务2(相关条款预测):根据法律文书中的事实描述预测相关条款;
任务3(刑期预测):根据法律文书中的事实描述预测刑期。
任务4(判决结果评价):根据法律文书中的事实描述预测完整的判决结果
数据集构建:我们对法律文书里面的裁决部署进行遮盖,只保留陈述事实的部分。 利用规则的方法再从判决部分提取罪名、相关法条、以及完整的判决结果作为客观答案。 构建了4k条训练测试集,1k条测试集。
judge-model based reward
我们知道GRPO里面的reward model是 rule based reward ,只需要判断模型预测的结果和标准答案是否一致即可以及 format reward 格式奖励 两条规则。但是在实际的法律任务上面,由于输出和表达方式的多样化,很难通过完全匹配的方式来确定,以及对于法条和判决结果这些任务会存在部分正确,以及判决结果的完全表述只能通过语义内容来判断,所以我们这里引入了judge model 来对答案进行评价。
judge 模型这里用的qwen2.5-7b-instruct模型,输入部分为标准答案和预测结果,输出评价结果。
prompt如下:
`if '刑期' not in answer: records = [ {"prompt": f"根据答案和预测结果判断预测结果是否正确(不考虑格式),如果完全正确返回2,部分正确返回1,错误返回0: 答案:{answer},模型预测结果:{predict}"}, ] else: records = [ {"prompt": f"根据答案和预测结果判断预测结果是否正确(不考虑格式),直接返回误差,比如’误差:6个月‘: 答案:{answer},模型预测结果:{predict}"}, ] `
奖励规则设计如下:
`### 格式奖励 格式错误 -1 分 ,格式正确 不扣分 ### 法律任务奖励 if'刑期' not in answer: # 非刑期预测任务 if'0'in output: # 回答全错 -2分 return -2 elif'1'in output: # 回答部分正确 +1分 return 1 elif'2'in output : # 回答完全正确 +1分 return 2 else: # 其它异常 不加分 return 0 else: # 刑期预测任务 if'个月' not in answer: # 如果答案里面没有包含具体刑期异常情况 ,不加分 return 0 else: # 正则表达式来提取数字 pattern = r"(\d+)(?=\s*(个月|年))" # 使用re.search找到匹配 match = re.search(pattern, output) # 如果匹配成功,输出数字 if match: number = match.group(1) # 对从judge model输出的误差月/240 进行负奖励 number = int(number) return -number/240 return -2 `
训练方法与设置
base model : Qwen2.5-7B-base
强化学习框架: verl [[https://github.com/volcengine/verl](https://github.com/volcengine/verl)]
参考开源项目:logit-rl [[https://github.com/Unakar/Logic-RL](https://github.com/Unakar/Logic-RL)]
超参数设置,train_batch_size 是7,Rollout.n 是16,actor lr 是3e-6。
算法:GRPO
实验结果与分析
经过400 step 的强化学习训练,模型从一开始的输出格式总是容易出错,慢慢学习到后来的输出格式完全正确, 在测试集上面的reward也是随着学习持续上升基本符合预期。
在罪名预测任务上面准确率从20% 上升到90%以上。
在刑期预测任务上面平均误差从11.5个月降低到2.4个月
在完整判罚结果上面reward socre作为评价指标,得分从-2.02 提升到 -0.96 score.
输出格式的变化
在开始的时候模型学习xxx<\think>xxx<\answer>的格式总是容易出错
忘记了结尾的<\answer>

出现了多次
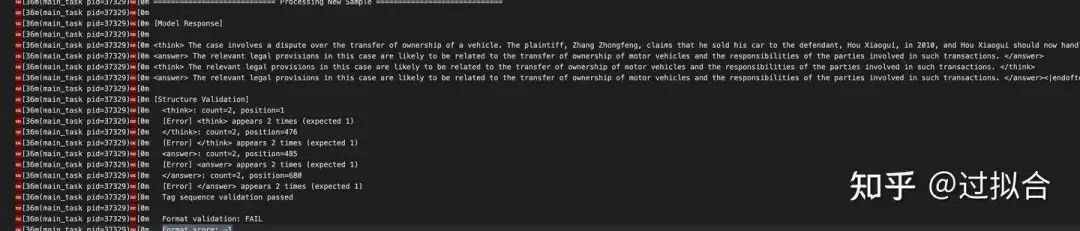
多次多次
基本在100 step以后,格式基本都完全正确了
思维链变化
是否出现了自我验证?
有,但是比较在数学以及逻辑题这些任务上面,出现的频率较低。

是否出现了迟疑,自我怀疑?
有,但是同样的出现次数很少。。。

观察到了一定的全面思考与总结的可能
很严谨且具有一定想象力的推理过程,有点夏洛克福尔摩斯的感觉了||
思考与回答的语种的变化
在刚开始的时候 think 和answer过程基本都是用英文回复,但是随着训练的加深,中文思考和回复的比例在增大。
输出长度的变化
最小长度变化
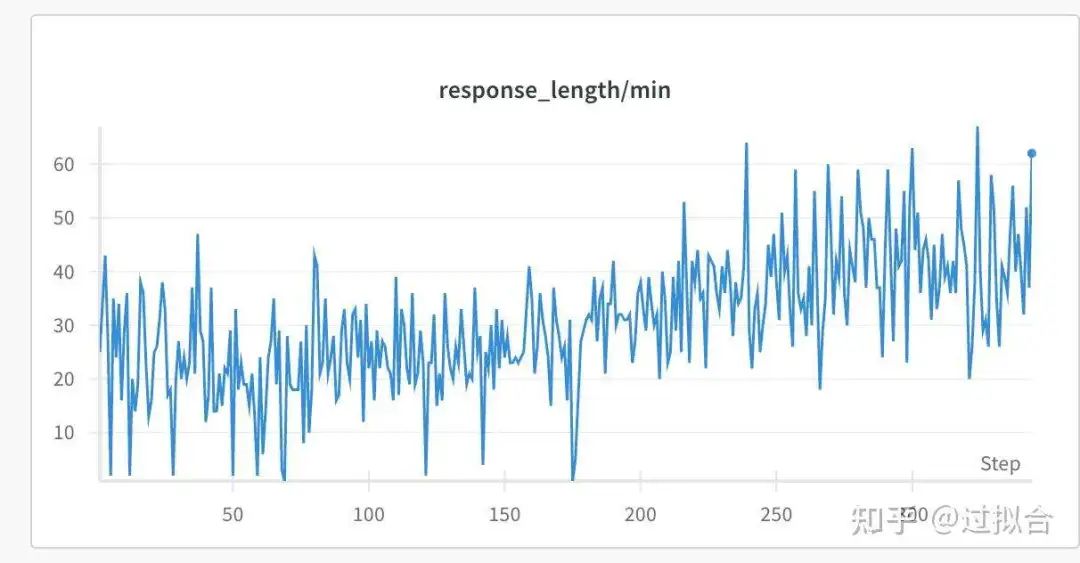
最小长持续上升的趋势,从20左右的均值上升到50左右波动。
最大长度变化
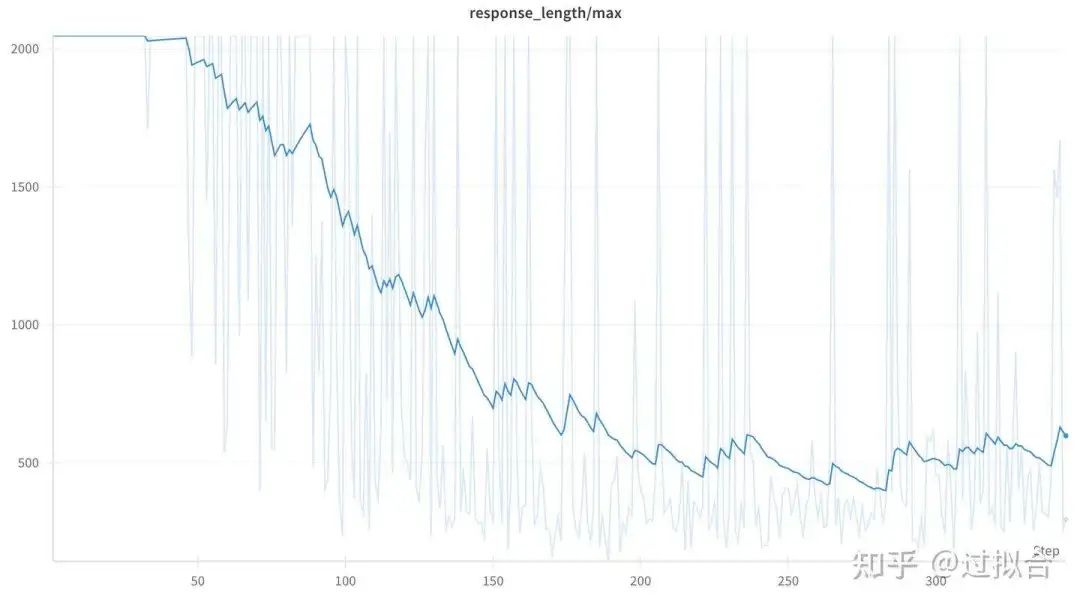
最大长度呈现下降的趋势, 从2000的均值下降到500左右。
平均长度变化
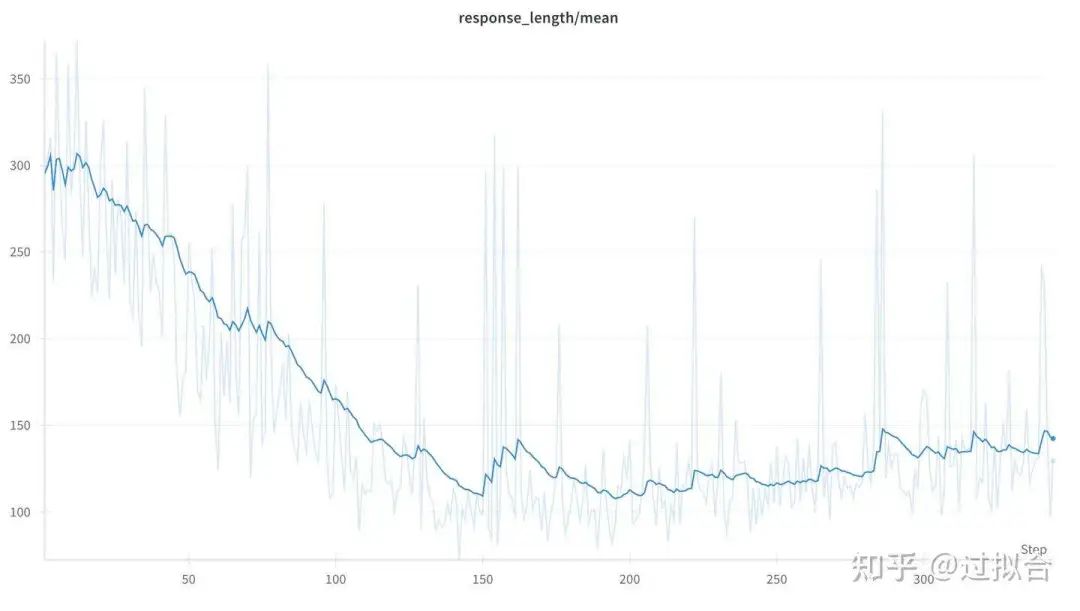
平均长度呈现先降低 从300降低到100左右,然后有震荡上升到150 左右到长度。
reward score变化
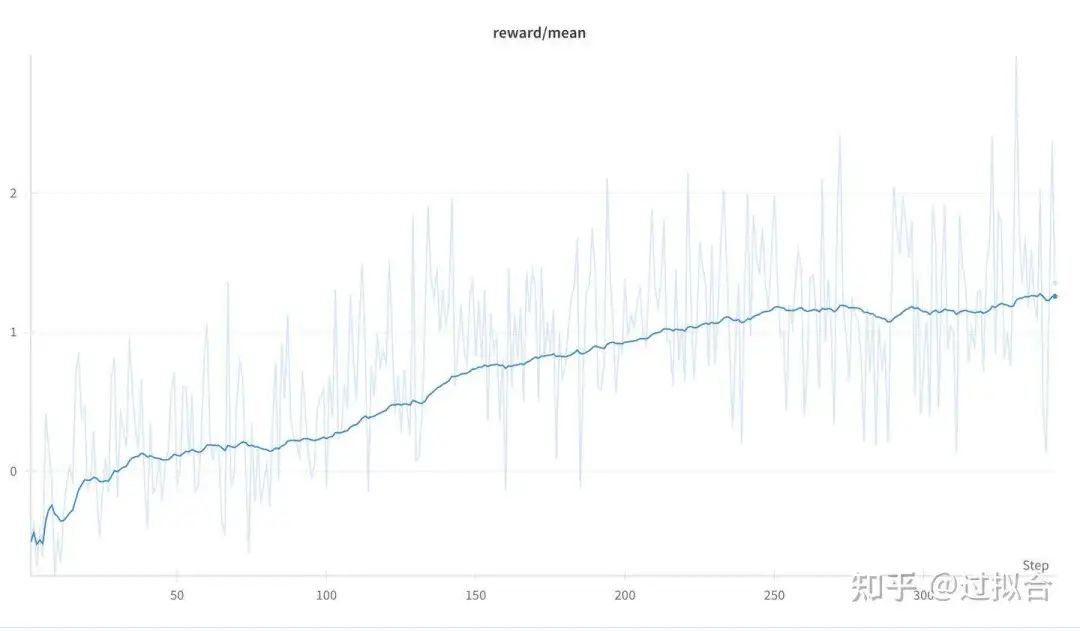
reward 随着 stgep 持续上升,从-0.5均值上升到1.4左右的均值波动。
loss变化
pg_loss
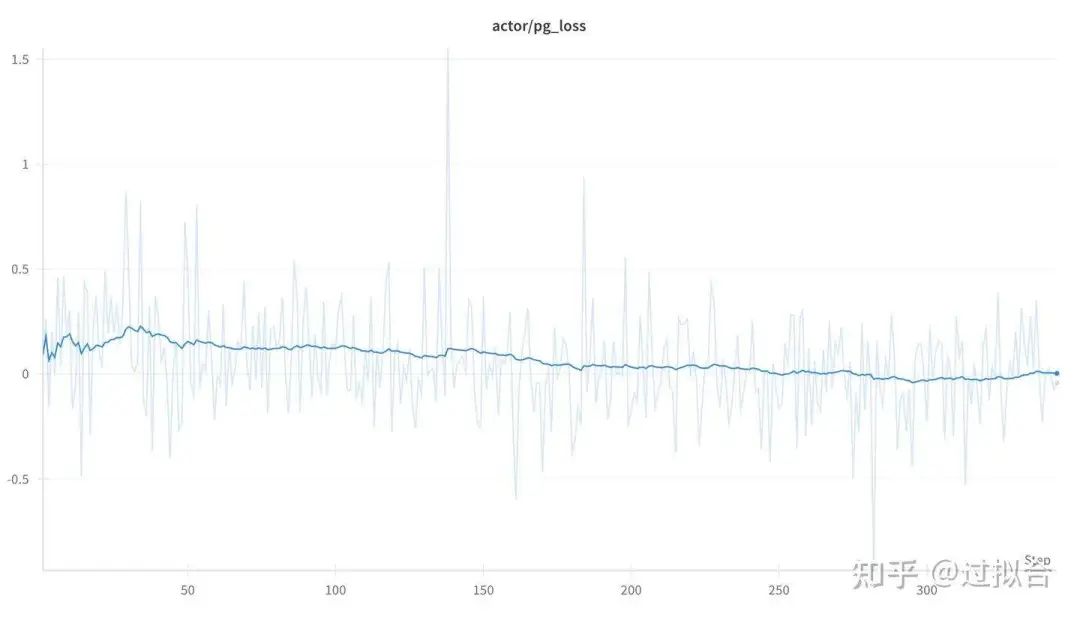
actor的pg_loss部分整体呈现缓慢下降的趋势
kl_loss
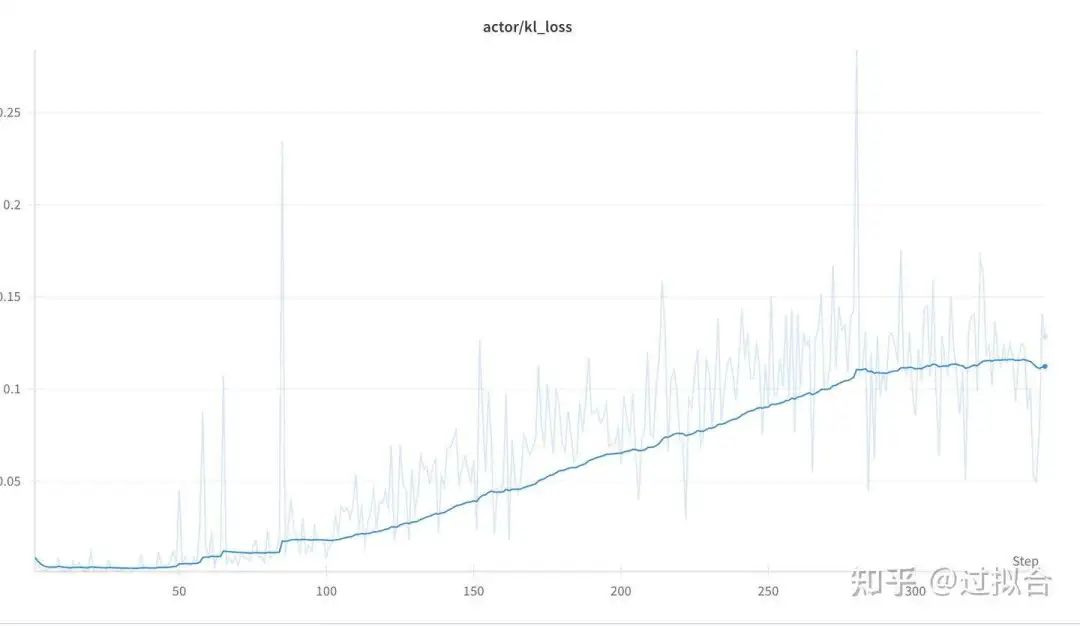
kl_loss随着训练的持续进行,loss不断变大,说明rl训练,actor模型与ref模型差异在拉大
总结与思考
关于长度
不同于r1或logic-rl等在数学和逻辑题上面的实验结果,整体来说在法律任务上面回复长度的均值整体来说是先降低再上升的趋势,这一定和数学以及逻辑题任务上面出现持续上升的趋势存在差异。这里个人推测在法律文书上面的四个任务整体来说便监督,另一方面实验的模型是基于qwen2.5-7b-base模型,也有可能是7B的模型随着长度的增长并没有方法获得reward持续上升。
关于judge model
在实验过程中发现基于qwen2.5-7b-instruct模型的裁判,这一些case下面判断的并不准确,尽管告诉了它标准答案的内容,依然在一些复杂的情况下,出现错判的情况。可能需要专门训练一个高准确同时具备很好泛化能力的裁判模型。由于裁判模型是一个生成模型所以需要保证裁判模型不能太大,否则会导致裁判过程时间太慢,整体训练效率下降
关于reward改进思路
目前来看rule based reward 只设置了格式奖励以及正确奖励,虽然给了actor模型更大自主学习的空间,但是同时也导致reward 更稀疏,训练效率更慢。另一方面在法律任务上面学习出来的漂亮的思维链占比明显少于数学任务和逻辑题任务,将设我们在reward 上面引入一些漂亮思维链特征的奖励应该会增加思维链进化的效率。
关于业务落地
目前来看,在外呼实时润色场景,r1平均思维链在600左右的长度,即使通过1.5B的模型蒸馏,也无法满足实时性的要求(外呼场景要求实时润色模型完整延迟<400ms,否则工程链路颜色会超过2s才能回复)。从这个场景来看对思维链进行压缩是有必要的,这种情况下我们只能通过rl算法引入长度惩罚的权重去学习更精简的思维链才有可能在润色场景落地。所以蒸馏的方法并不是一种很好方法。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 12
12 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)