
CDA数据分析师一级学习笔记(20000字知识点整理)
CDA数据分析师一级知识体系,作者是CDA持证人任添辉,本笔记涵盖8大核心模块:1)数据分析概述与职业道德(6%),强调GDPR合规与数据安全;2)数据结构(12%),解析表格/表结构数据处理技术;3)数据库应用(17%),详解SQL操作与查询优化;4)描述性统计(10%),涵盖集中趋势、离散度等分析方法;5)多维数据透视(10%),介绍星型模型等OLAP技术;6)业务分析(25%),包含RFM模
作者:CDA数据分析师一级持证人 任添辉
目录
PART 5 多维数据透视分析与趋势分析法(10%) 17
PART 7 业务分析报告与数据可视化报表(15%) 23
考试内容涵盖
-
PART 1 数据分析概述与职业操守(占比 6%)
数据分析概念、方法论、角色(占比 1%)
-
-
EDIT数字化模型:Exploration探索(指标体系)、Diagnosis诊断(性质分析法,数量分析法)、Instruction指导(知识库,策略库,流程模板)、 Tool工具(数据模型,算法模型,优化模型)
-
业务描述性分析流程:
-
业务理解:抓问题核心、定位决策者角色、设计报表框架
-
数据获取:系统数据采集、人工维护数据、外部数据支持
-
数据处理:字段标准统一、异常数据处理、多表数据关联
-
数据分析:数据探索、运用分析方法论、结合高效工具
-
结果展示:选择合适图表、撰写分析报告
-
CRISP-DM方法论(跨行业数据挖掘标准流程):业务理解、数据理解、数据准备、建模、模型评估、模型发布
-
SEMMA方法论(数据挖掘,搭建统计模型):数据抽样、数据探索、数据调整、模式化、评估与评价
-
数据分析师职业道德与行为准则(占比 1%)
-
-
保护数据资产安全性;遵循数据真实性;全面理解业务背景、痛点与需求;根据业务需求选择合适的工具、平台、系统及算法、优化和迭代指标与模型;做出商业价值建议;履行后续义务与责任。
-
大数据立法、数据安全、隐私(占比 4%)
-
-
欧盟《通用数据保护条例》简称GDPR,目的将个人数据保护深度嵌入组织运营;用户享有数据访问权、被遗忘权、限制处理权、数据携带权。
-
-
PART 2 数据结构(占比 12%)
表格结构数据特征(占比 2%)
-
-
数据分为结构化数据(交易记录、产品信息、财务数据等)与非结构化数据(网站图片、社交聊天记录、视频等);
-
结构化数据:业务系统(CRM、EPR、APP等)——数据库——表格结构数据(EXCEL、WPS、Numbers)/表结构数据(数据库、ETL工具、可视化工具)
-
表格结构层级:父子级关系(工作簿>工作表>单元格区域>单元格)
-
数据类型:数值型(整数值、小数值)、文本型(文字、符号、文本型数字)、逻辑型(真值、假值)
-
表格结构数据获取、引用、查询与计算(占比 2%)
-
-
表格结构数据获取:使用SQL从数据库系统中查询(格式包括 CSV、TXT、XLSX、ET);
-
引用:引用单元格定位 =表名!(同表可无)+列名+行号 ;引用单元格区域定位(必须方形连续区域) =表名!左上单元格:右下单元格
-
查询:表格工具查找、函数vlookup查找;
-
计算:算数计算:+ - * / ^;比较运算:> < >= <= = <>; 文本连接:&
-
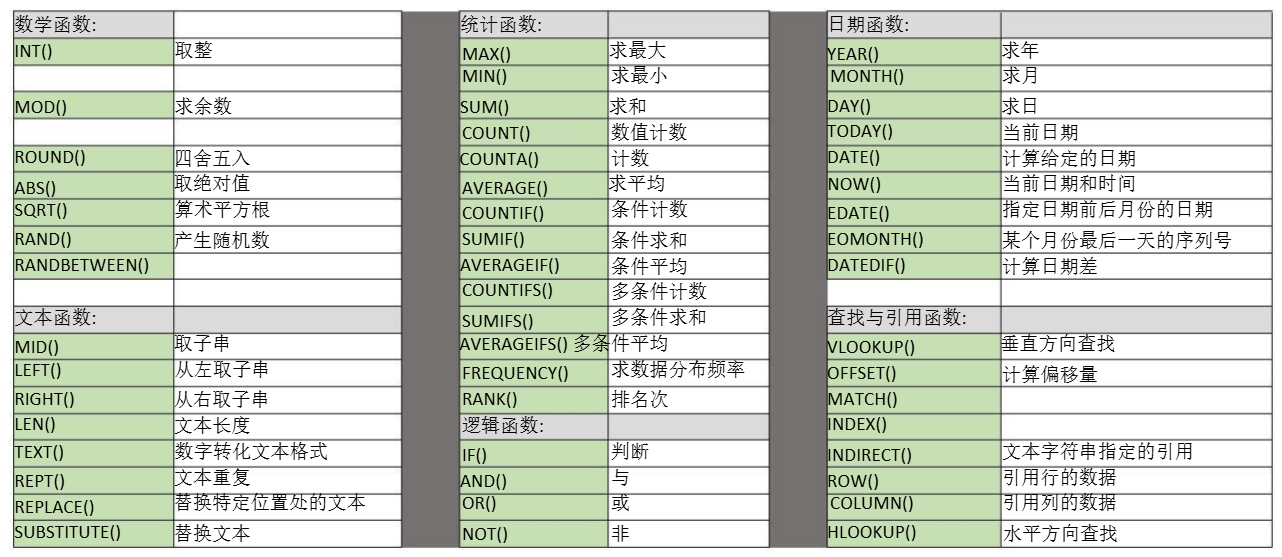
常用函数:
-
stdev.p()总体标准差、stdev.s()样本标准差、var.p()总体方差、var.s()样本方差
-
-
-
常见函数报错
-
#VALUE!:在用+,-,*,/算术运算时,包含了文本型就会出现此类错误。
-
#DIV/0!:当分母为0,或者分母为空时,会出现此类错误。
-
#NAME?:公式使用Excel无法识别的文字,会出现此类错误。
-
#N/A:此类错误最常见于vlookup函数找不到值时会返回#N/A。
-
#REF!:公式中使用了无效的单元格引用,会导致出现此类错误。
-
#NUM!:公式中输入了一个错误的参数,会导致出现此类错误。
-
#NULL!:出现此类错误往往是公式或函数中的区域运算符或单元格引用不正确。
-
表结构数据特征(占比 4%)
-
-
以字段或记录作为数据的引用、操作及计算的基本单位的数据。
-
字段:整列数;记录:整行数(第一行为标题行);维度:业务角度;度量:业务行为结果;字段名不能重复;一个字段只能有一种数据类型;所有字段记录行相同。
-
维度表:只包含维度信息的表;事实表:既包含维度信息,又包含度量信息的表。
-
一个表有且只有一个主键,可以是单字段主键,也可以是多字段联合主键,非空不重复,是表的业务记录单位。
-
表结构数据获取、加工与使用(占比 4%)
-
-
“应用”表格结构数据(数据源导出成数据文件,应用工具打开如EXCEL);“引用”表结构数据(用表结构分析工具与数据源数据建立连接关系)
-
关系型数据库管理系统RDBWS:(Access)是企业业务数据的存储、检索、访问和共享。
-
OLTP:联机事务处理(面向操作人员,执行日常操作);
-
商业职能系统——BI:(Tableau、Power BI)用于为企业决策者快速提供完整、准确、深入的数据分析结果,帮助企业决策者实现商业洞察。
-
ETL功能:将数据从数据源端经过E-抽取、T-清洗转换后,L-加载到数据仓库。
-
数据仓库——DW:用来储存分析所需要的不同数据源上的所有相关数据信息。
-
OLAP联机分析处理(面向决策人员,执行分析决策):连接信息孤岛,创建多维数据模型。
-
表结构横向合并:通过公共字段匹配,用左连接/右连接/内连接决定表的主附关系,将不同表中的字段信息合并到同一个表中使用,对应关系决定结果行数是对应乘积的结果。
-
表结构纵向合并:多表中记录信息合并到同一个表中进行使用的合并方式称为纵向合并。
-
表结构数据的汇总:数据透析——对零散数据进行汇总分析。元素包括:数据源(出处)、维度字段(业务观测角度)、度量字段(业务行为结果)、汇总计算规则(衡量业务行为结果好坏程度的测量器),维度筛选度量。汇总计算规则包括合计规则、计数规则、平均规则、最大值规则、最小值规则。
-
数据分析是连接零散数据与人类认知的桥梁。
-
-
PART 3 数据库应用(占比 17%)
数据库相关概念(占比 1%)
-
-
RDBMS:关系型数据库管理系统;SQL:结构化查询语言;DB:数据库,用于OLTP联机事务处理系统,数据库是表的集合,一个表是多个字段的集合,一个字段是一列数据,由字段名和记录组成。DW:数据仓库,用于OLAP在线分析处理系统;BI:商业职能系统,由ETL功能、数据仓库功能、OLAP功能及数据可视化功能构成。
-
DDL 数据定义语言(占比 2%)
-
-
定义:数据定义语言是用来对数据库管理系统中的对象(对数据库)进行“增删改查”操作。
-
创建数据库:create database 数据库名称; ;查看数据库:show database 数据库名称; ;查看所有数据库:show databases; ;使用数据库:use database 数据库名称; ;删除数据库:drop database 数据库名称; 。
-
创建数据表:create table 表名称; ;使用表:use 表名称; ;查看所有表:show tables; ;删除表:drop table 表名称; ;
-
“位(bit)”是电子计算机最小的数据单位。“节Byte”是8个二进制位构成1个节,储存空间的基本计量单位。
-
数据类型:
-
数值型:INT、TININT、SMALLINT、MEDIUMINT、BIGINT(符号大小不同,如加上UNSIGNED,可以禁止负数)
数值型(小数型):FLOAT(M,D)、DOUBLE(M,D)、DECIMAL(M,D)
日期和时间类型:DATE(YYYY-MM-DD格式)、DATEIME(YYYY-MM-DD HH:MM:SS格式)、TIME(HH:MM:SS)、TIMESTAMP(时间戳格式)、YEAR(2|4)
-
-
字符串类型:CHAR(M)(固定长度字符串)、VARCHAR(M)(可变长度字符串)、BLOB、TEXT、TINYTEXT、MEDIUMTEXT、LONGTEXT、ENUM
-
约束条件:PRIMARY KEY主键约束(多字段联合主键书写:primary key(字段1,字段2))、NOT NULL非空约束、UNIQUE唯一约束、AUTO_INCREMENT自增字段、DEFAULT默认值(书写:default ‘_’)、FOREING KEY 外键约束(书写:foreing key 字段名 references<表名>(非空字段))
-
修改数据表名:alter table 原表名 rename 新表名; ;修改字段类型:alter table 表名 modify 字段名 新字段类型; ;修改字段名:alter table 表名 change 字段名 新字段类型; ;添加字段:alter table 表名 add 新字段名 字段类型 约束条件; ;将字段改至第一位:alter table 表名 modify 字段名 字段类型 first; ;将字段指定字段之后:alter table 表名 modify 移动的字段名 字段类型 after 指定字段名; ;删除字段:alter table 表名 drop 字段名。
-
DML 数据操作语言(占比 2%)
-
-
填充数据:insert into 表名(字段名1,字段名2,…) values(字段1内容,字段2内容,…) 字段内容为文本型,需加‘’
-
查看默认安全路径:show variables like ‘%secure%’;
-
导入外部文本文件:load data infile "路径"(#导入文件路径,文件在客户端,则为 load data local infile ”路径”)into table 表名 (#数据导入到哪个表) fields terminated by “t”(文本中的字段是用””进行分隔) ignore 1 lines;(导入时,忽略第一行表头)
-
将查询结果添加到已存在的表中:
-
Insert into 表名 字段名1,字段名2…
Select 字段名1,字段名2… from 原表名 where 查询条件;
-
-
将查询结果添加到新表中
-
Create table 新表名 as
Select 字段名1,字段名2… from 原表名 where 查询条件;
-
-
字段的内容赋值:update 表名 set 字段名 = 值。如:update fruits set f_name = concat(‘fruit_’,f_name); 输出结果为 ‘fruit_加原内容‘
-
删除数据表数据:delete from 表名 [where 条件] 如省略where,则删除所有数据;truncate 表名; 之间删除全部数据
-
单表查询(占比 3%)
-
-
查询全表:select * from 表名;查询总行数:select count(*) from 表名;查询表结构:Desc 表名。
-
操作符:+(加号)、-(减号)、*(乘号)、/(除号)、=(等于)、>(大于)、<(小于)、<=(小于等于)、>=(大于等于)、!=或<>(不等于)、!>(不大于)、!<(不小于)
-
聚合函数:avg()求平均、sum()求和、max()求最大值、min()求最小值、count()求计数 # count(distinct 字段)去重计数
-
Select查询:
-
select 目标字段 #可以加(常量值、公式、表达式、字段名、*、去重、设置别名)
from 数据源
[where 筛选条件] #条件查询(+-*/、and,or,not、=,>,<,<>,like,in,not in,between…and,is null,is not null)
[group by 分组依据 [having筛选条件]] #having除上述条件外,还支持函数。Having在分组聚合后执行。
[order by 排序依据[asc | desc]]
[limit [偏移量,]行数] #查询前5:limit 5;查询6至10:limit 5,5;
多表查询(占比 3%)
-
-
左、右连接查询:Select 目标字段 from 表1 left/right/inner join 表2 on 表1.key=表2.key。(inner join内连接:按照连接条件合并两个表,返回满足条件的行;left join 左连接:除满足连接条件的行外,加左表的行;right join右连接:除满足连接条件的行外,加右表的行)
-
纵向合并查询:Select 表1.字段名1 from 表1 union/union all select 表2.字段名2 from 表2; (union去重纵向合并:用于合并两个或多个select语句的结果集,并去表中任何重复行;union all纵向合并:用于合并两个或多个select语句中的结果集,保留重复行)
-
全连接查询:Select * from 表1 left join 表2 on 表1.key=表2.key union Select * from 表1 right join 表2 on 表1.key=表2.key; (左连接合并右连接,实现全连接,返回两张表中全部记录)
-
自连接查询:select 员工表.ename 员工姓名,领导表.ename 领导姓名 from emp 员工表 left join emp 领导表 on 员工表.mgr=领导表.empno; 将一个emp表虚拟成员工表、领导表进行连接。
-
多表连接查询:select 员工表.empno,员工表.ename,dname from emp 员工表 left join emp 领导表 on 员工表.mgr=领导表.empno left join dept on 员工表.detno=dept.deptno where 员工表.hiredate<领导表.hiredate; 先使用on条件将两表进行连接形成一个虚拟结果集,用虚拟集和第三个表做连接再形成一个单一虚拟结果集。
-
交叉连接:select 字段名1,字段名2… from 表1,表2; 或者 select 字段名1,字段名2… from 表1 cross join 表2;
-
不等连接查询:select 字段名1,字段名2… from 表1 left join 表2 on 字段名3 between 字段名4 and 字段名5; 字段名3,4,5均为数值型,字段3(表1)在4(表2)与5(表2)的区间内,输出对应的字段1(表1)、字段2(表2)。
-
子查询(占比 3%)
-
-
查询操作符:and(联合多条件进行查询,多条件均需满足)、or(多条件满足任意条)、[not] in(判单某个字段在不在指定的集合中,在的话满足条件;not in不在的话满足条件)、[not] between(判断某个值在不在指定范围内)[not] like ‘[%]字符串[%]’(判断字段的值与字符串是否相匹配,%代表任意长度的字符串,_代表一个字符,使用%,可以判断字符串中是否包含欲判断的值)、Is [not] null(判断值是否为空值)、select distinct(查询所有不重复的值)
-
子查询:写在()中,将内查询结果,当作外查询的参数。执行顺序由内到外。出现在select、where、having、from、join子句中。分列中、表(需别名)、条件子查询。子查询可分为标量子查询(结果是单行单列的数据)、行子查询(结果是一条多字段的记录)、列子查询(结果是包含多条记录的单个字段)、表子查询(结果是一个拥有多个字段和多条记录的临时表)。
-
Any:使用any关键字,内查询满足多条件的任何一个,执行外查询语句 例:select * from 表1 where price > any (select prince from 表1 where f_name like ‘apple’; 查询价格大于任何苹果的产品
All:使用all时,只有满足内查询所有结果,才能执行外查询语句 例:select * from 表1 where price > all (select f_price from 表1 where f_price >= 20); 查询所有价格大于20元的水果记录
Exists:使用exists时,内查询返回真值假值,真值将执行外层查询,假值不进行查询 例:select * from 表1 where exists (select *from fruits where price > 30); 查询是否存在价格大于30元的水果
As:将表或者字段名重新命名,只在查询中有效;limit:只显示limit后指定数字的行数结果 例:select * from 表1 order by f_price desc limit 3; 显示价格前三名的记录;
数据库函数(占比 3%)
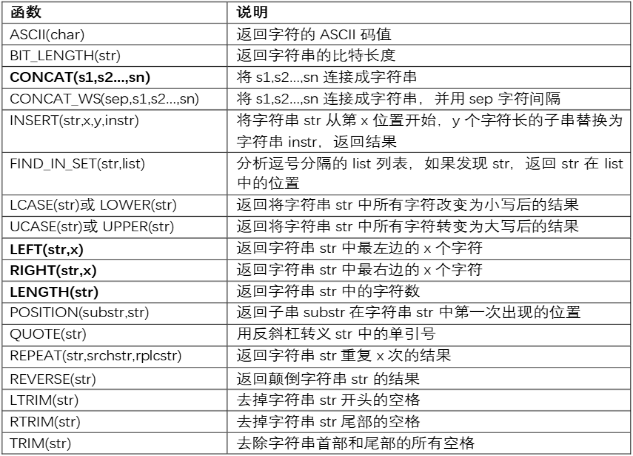
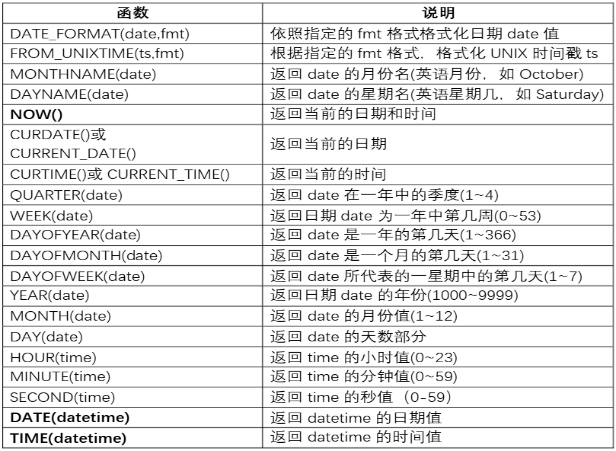
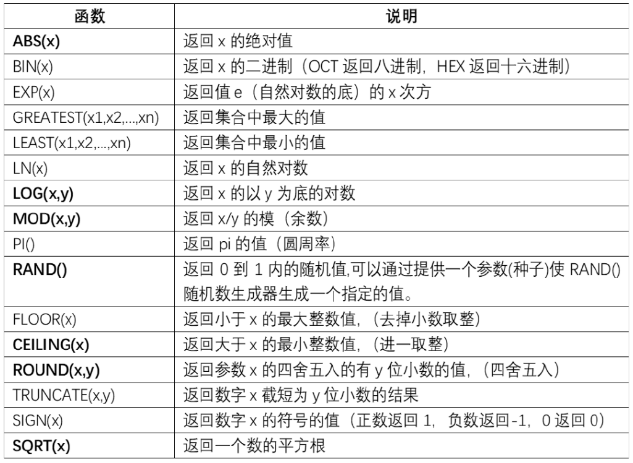
-
-
分组合并函数:group_concat([distinct] str [order by str asc/desc][separator ‘分隔符’]) distinct去重、order by指定合并顺序、separator指定分隔符,默认逗号。分组合并常与group by一起使用将分组后每个组的多字符串合并为一行
-
逻辑函数:
-
空值函数:ifnull(字段名,输出值) 例:select ename,sal+ifnull(comm,0) from emp; ;查询员工实发工资,若空值按0计算;
-
判断函数:if(条件1,结果1,if(…))、case when 条件1 then 结果1 [when 条件2 then 结果2 else 结果3] end;
-
例:if:select ename,sal,if(sal>=3000,’高’,if(sal<=1500,’低’,’中’)) as 工资级别 from emp;
Case when:select ename,sal,case when sal>=3000 then ‘高’ when sal<=1500 then ‘低’ else ‘中’ end as 工资级别 from emp;
-
-
开窗函数:对数据每一行,都进行计算并返回结果,有几条记录执行完返回结果还是几条
-
Over()函数:开窗函数名([<字段名>]) over ([partition by <分组字段>][order by<排序字段>[desc]][<滑动窗口>]) 例:select *,avg(sal) over() as 平均工资 from emp; 查看每位员工与所有员工的平均工资情况
Partintion by子句:在over函数中用来分组,开窗函数在不用分组内执行运算。例:select *,avg(sal) over(partition by deptno) as 平均工资 from emp; 查询每位员工与所属部门平均工资之间的情况
-
-
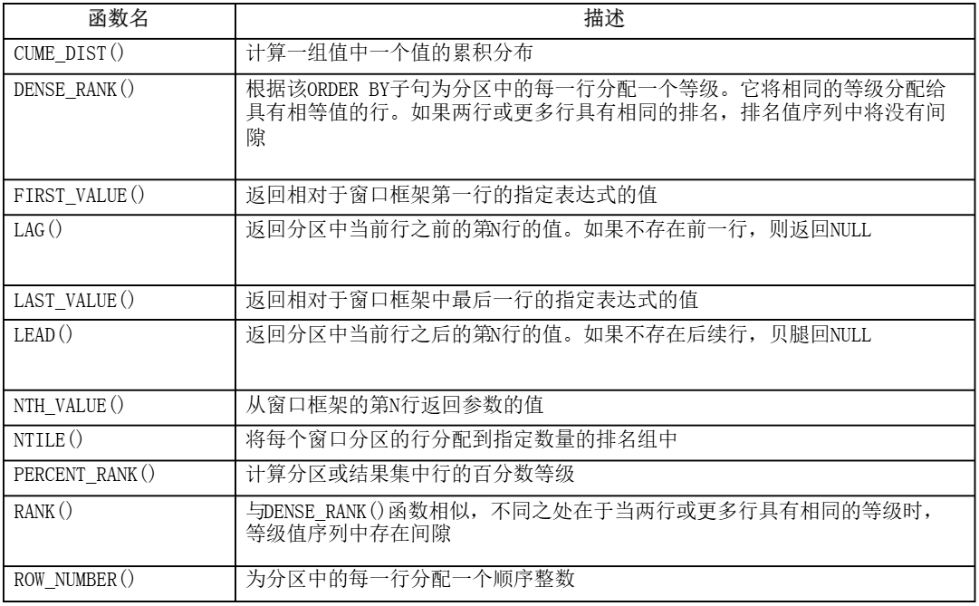
其他函数
-
例:select *,rank() over(oeder by sal desc) 工资排名 from emp;
-
PART 4 描述性统计分析(10%)
统计基本概念(占比 2%)
-
-
统计选是一门收集、处理、分析、解释数据并从数据中得出结论的科学;分析数据分为1.描述性分析:研究数据收集、处理和描述的统计学方法(包含总体规模、对比关系、集中趋势、离散程度、偏态、峰态等);2.推断性分析:研究如何利用样本数据来推断总体特征的统计学方法(包含估计、假设检验)、列联分析、方差分析、相关分析、回归分析等)。统计学的对象是数据,形式包含数字(可以进行比较、运算)、文字(不可运算,如男、女)
-
数据按计量尺度进行分类:
-
分类型数据:对事务进行分类的结果。不可排序,不可计算。为定性数据。如男、女
顺序型数据:对事务类别顺序的测度。可排序,不可计算。为定性数据。如一等、二等、三等
数值型数据:对事务的精确测度。可排序,可计算。为定量数据。如75kg、180cm
-
-
总体:指研究的所有元素的集合。其中每个元素称为个体。样本:从总体中抽取的一部分元素的集合。构成样本的元素的数目称为样本容量。参数:研究者想要了解的总体的某种特征值(主要有总体均值(μ)、总体标准值(σ)、总体比例(π)等)。统计量:根据样本数据计算出来的一个量,即样本的某个特征值(常见统计量样本均值(x)、样本标准差(s)、样本比例(p))。变量:描述事物某种特征的概念,具体表现称为变量值,即数据。分为分类变量、顺序变量、数值型变量。
-
数据的描述性统计(占比 3%)
-
-
总体规模的描述——总量指标:反映在一定时间、空间条件下,某种现象的总体规模、总水平或者总成果的统计指标。
-
对比关系的描述——相对指标:是两个有相互联系的指标数值之比。如目标完成率
-
集中趋势的描述——平均指标:一组数据向其中心值靠拢的趋势,测集中趋势,就是找数据的代表值或中心值。分类型可用众数;顺序型可用众数、分位数;数值型可用众数、分位数、均值。
-
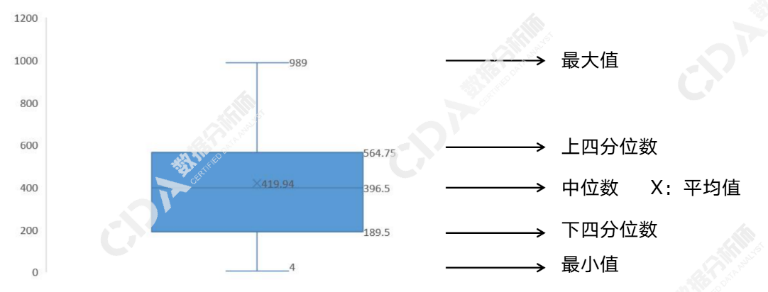
众数:出现次数最多的变量值,符号为M。;分位数:根据对数据的位置进行划分,处于某些特定为值的数。常用分位数有二分位数(中位数)、四分位数、十分位数、百分位数等。符号为Me;中位数的位置为(n+1)/2;四分位数分为上四分位数(QL 位置为n/4)、下四分位数(QU 位置为3n/4),处于25%和75%位置。
算数平均数(x¯):数据之和与数据个数之比。简单算数平均值=(x1+x2+x3…)/n;加权算数平均值=(x1f1+x2f2+…)/(f1+f2+…)
几何平均数(G):n个变量值乘积的n次方根。常用于增长率数据的研究。简单几何平均数=n√x1x2x3…;加权几何平均数=(f1+f2+…)√x1^f1x2^f2…
调和平均数(H):变量值倒数的算数平均数的倒数。常用于效率数据的研究,有一项为0则无法计算。简单调和平均数=n/(1/x1+1/x2+…);加权调和平均数=(f1+f2+…)/(f1/m1+f2/m2+…) m1为组中值。
算数平均数≥几何平均数≥调和平均数
-
-
离散程度的描述——变异指标:反映各变量值远离其中心值的程度,是数据分布的另一个重要特征。侧面说明了集中取数测度值的程度。
-
极差(R):一组数据最大值与最小值的差。R=max(x)-min(x)
平均差(Md):各变量值与其均值离差绝对值的平均数,Md越大,数据越分散。Md=sum(abs(xi-avg(xi)))/n
方差与标准差:变量值与其算术平均数的离差的平方的算数平均数。总体方差σ²;总体标准差σ;样本方差s²;样本标准差s。方差或者标准差越大,表示变量值与均值的平均差越大。σ²=变量与均值差的平方求和除N;s²=变量与均值差的平方求和除(N-1)
离散系数(变异系数 Vs):标准差与均值之比,不用计量单位计算离散程度。Vs=s/x¯
-
-
相对位置的度量——标准化值:标准分数,对某一数据在全体中相对位置的度量,可用于判断一组数据是否有离群值。用于对变量的标准化处理。公式为Zi=(Xi-x¯)/S
-
切比雪夫不等式?
-
-
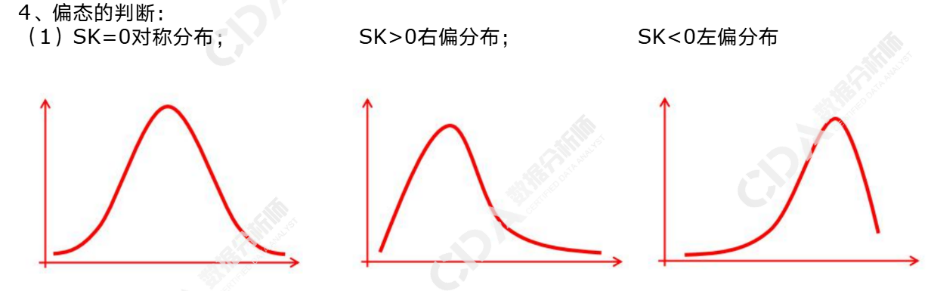
分布形态的描述——偏态(SK):指数据分布偏斜程度。未分组数据:SK=nΣ(xi-x¯)³/(n-1)(n-2)s³;分组数据:SK=Σ(M-x¯)³fi/ns³。低度偏态分布0<|SK|≤0.5;中度偏态分布0.5<| SK|≤1;重度偏态分布| SK|>1。
-
均数<中位数<众数
众数<中位数<均数
均值=中位数=众数
峰态(K):数据分布的扁平程度。未分组数据:K=n(n+1)Σ(xi-x¯)^4-3[Σ(xi-x¯)²]²(n-1)/(n-1)(n-2)(n-3)s^4;分组数据:K=Σ(M-x¯)^4fi/ns^4-3
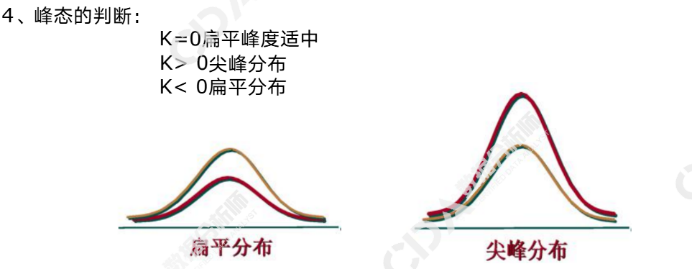
高度尖峰分布:|K|>1
中等尖峰分布:0.5<|K|≤1
低度尖峰分布:0<|K|≤0.5
-
-
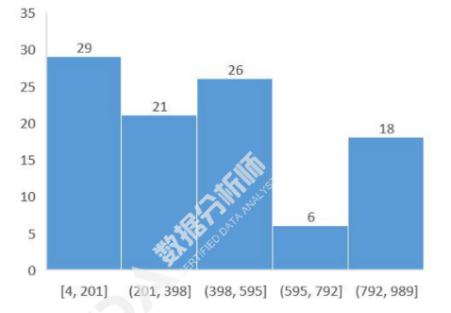
描述性统计图表——频数分布直方图:由一系列高度不等的矩形表示数据分布的情况。横轴按组距分类,纵轴表示频数。
-
描述性统计图表——散点图:数据点在平面直角坐标系上的分布图,表示因变量随自变量而变化的大致趋势。
-
描述性统计图表——箱形图(盒须图、箱线图):显示一组数据分散情况的统计图。
-

统计分布(占比 3%)
-
-
两点分布与二项分布
-
二项分布(X~B(n,p)):E(X)=np;D(X)=np(1-p)
两点分布(X~B(1,p)):E(X)=p;D(X)=p(1-p)
-
-
正态分布:X~N(μ,σ²)
-
标准正态分布:X~N(0,1)
-
x²分布(卡方分布):设X~N(μ,σ²),则z=X-μ/σ~N(0,1) 令Y=z²,则Y服从自由度为1的x²分布,即Y~x²(1)
-
t分布:设随机变量X~N(0,1),Y~x²(n),且X与Y独立,则t=x/√(y/n),其分布称为自由度为n的t分布,记为t(n)。
-
F分布:若U为服从自由度为m的x²分布,即U~x²(m),V为服从自由度为n的x²分布,即V~x²(n),且U和V相互独立,则F=(U/m)/(V/n)。称F为服务自由度m和n的F分布,记为F~F(m,n),其中m为分子自由度,n为分母自由度
-
相关分析(占比 2%)
-
-
问题起源,经济变量间的相互关系,确定性的函数关系 Y=f(X);不确定性的统计关系—相关关系Y=f(X)+ε (ε为随机变量)
-
表现形式相关:线性相关(散步图接近直线);非线性相关(散布图接近曲线)。
-
关系变化方向:正相关(变量同方向变化,同增同减);负相关(变量反方向变化,一增一减)
-
相关关系的度量——协方差:Cov(Y,X)=Σ(yi-y¯)(xi-x¯)/(n-1) Cov(Y,X)>0 Y与X正相关,Cov(Y,X)<0 Y与X负相关
-
相关关系的度量——相关系数:Cor(Y,X)=Cov(Y,X)/SySx=Σ(yi-y¯)(xi-x¯)/√(Σ(yi-y¯)² Σ(xi-x¯)²)。r的取值范围是[-1,1],-1≤r<0,为负相关,0<r≤1,为正相关;r=0,表示不存在线性相关关系;|r|=1,为完全相关,r=1,为完全正相关,r=-1,为完成负相关。|r|越趋于1表示关系越密切,|r|越趋于0表示关系越不密切。
-
-
PART 5 多维数据透视分析与趋势分析法(10%)
多表透视分析逻辑(占比 3%)
多维数据模型(占比 2%)
-
-
多维数据模型又叫多维数据集,立方体,指的是相互间通过某种联系被关联在一起的不同类别的数据集合。
-
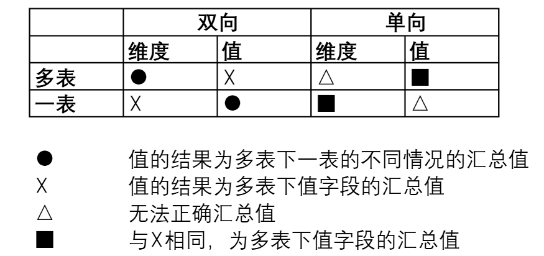
通过公共字段连接两个表,选择不同的表中字段分别作为维度、度量,选择汇总计算规则。影响连接汇总的三要素,如下:
-
筛选器(分为单向(箭头发出为维度,指向一侧为度量)及双向(两表互相筛选)两种,筛选器方向决定维度与度量的出处)。OLAP连接汇总时,那个表提供度量,那个表为主表。
对应关系(分为三类,一对一、多对一与多对多,决定连接汇总的结果)
汇总角色(维度、度量);汇总方式一:合并维度,汇总度量、维度筛选度量。汇总方式二:合并维度,汇总维度下不同公共字段对应的度量,维度选取公共字段,公共字段筛选度量。
-
-
三种模式
-
星型模式:一个事实表与多个维度表相连
雪花模式:维度表与维度表相连进行维度扩展
星座模式:多个事实表公用某些维度表
-
-
5W2H:When时间维度、Who参与角色、What分析对象、Why为什么、Where空间维度、How much分析的度量、How to do怎么做
-
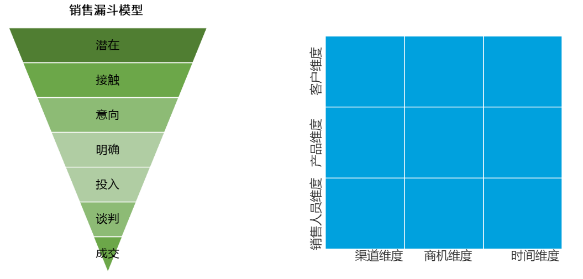
销售管理分析:
-
what 销售进度管理→商机维度(商机规模、商机号、商机来源等)
why 发现并控制销售阶段风险→商机维度(销售阶段、赢单率等)
where 销售地点→销售大区、销售城市、销售区域等
who 销售人员、客户→商机发现者、管理者、销售能力、人员成本、客户负责人、与客户以往交易情况、客户需求等
when 时间维度→创建商机日期、预计签约日期、商机停留时间等
how much 商机金额、商机个数、商机规模等
how to do 如何制定销售策略
透视分析方法(占比 3%)
-
-
基本透视规则:合计规则,相同维度下多个度量值相加(SUM);计数规则,相同维度下度量个数进行计数(COUNT非空计数)(DISINCTCOUNT去重计数);平均规则,合计的结果/计数的结果(AVERAGE);最大值规则,相同维度下,最大的度量值(MAX);最小值规则,相同维度下最小的度量值(MIN)
-
对比计算规则:均比,实际值与平均值之间的对比((当前值-均值)/均值),同类型产品销售情况;基准比:实际值与基准值之间的对比((当前值-固定时期值)/固定时期值),成绩水平;目标比:实际值与目标值之间的对比,销售业绩绩效;标准比,实际值与标准值之间的对比,工厂工作水平绩效;占比,部分占总体的对比,不同区域销售额占比
-
时间下的汇总规则:MTD,月初至当前日期汇总;QTD季度初至当前日期的汇总;YTD年初至当前日期的汇总;环比,当期值与上期值之间的对比((当期值-上期值)/上期值);同比,当期值与同期值之间的对比((当期值-过去同期值)/过去同期值)。
-
趋势分析法(占比 2%)
-
PART 6 业务数据分析(25%)
数据驱动型业务管理方法(占比 3%)
-
-
销售漏斗:粗细(容量)→斜率(销售技巧)→均匀(阶段分布)→流速(销售周期)
-
指标体系的设计和应用(占比 12%)
-
-
指标:对度量的汇总,即数据的汇总规则,作用为用简约的汇总数据量化业务强弱。
-
基本指标:
-
求和类:对度量求和计算得到的指标,诸如销售数量、金额等。类计求和:随时间维度变化,从时间起点到当前度量的累加值。时间维度下的累计指标:YTD年累计、QTD季累计、MTD月累计、WTD周累计。
-
计数类:对度量计数得到的指标。
-
比较类:差异百分比,指定维度下指标的某个值为基准点,比较当前值和指定值的差异变化率。
-
常用场景指标:
-
流量相关指标
-
常用计费方式:CPM按每千次曝光进行计费、CPS按实际销售收费、CPC按点击次数收费
-
量:访客数(UV),访问对应维度的非重复用户数;浏览量(PV),维度下浏览页面的总次数;访问次数(Visits),统计会话数,一个会话内用户可访问多个页面;新访客数,新进访客数。
-
质:平均访问深度:浏览量/访问次数;跳失率:跳出次数(客户通过相应入口进入,仅访问一个页面就离开)/访问次数;新访客占比:新访客数/访客数
-
转化相关指标:转化率,根据业务流程观测阶段间流转后的留存比率。当前阶段/初始阶段(或上个阶段)
-
营运、销售相关指标
-
成交额:GMV(商品交易总额,含拍下未支付金额)、实际销售额、税后销售额、退款额
-
成交量:实际订单量、销量、退款订单量、上架数量
-
完成情况:目标达成率、退货率
-
效果:坪效(营业额/专柜所占总坪数)、商品关联性
-
库存相关指标:库存周转天数=库存量/最近n天平均销量≥安全库存天数;库龄=存放库房时长;库存周转次数=平均库存量/出库总量;订货满足率=按合理需求正常供货次数/产品被要求供货的总次数;缺货率=缺货次数/总订货次数;售罄率=1-库存金额/进货金额
-
绩效相关指标
-
客户相关指标
-
量:注册用户数、登录用户数、浏览用户数
-
质:留存率、活跃用户数、在线时长、复购用户数
-
设计新指标:流程为了解业务背景→明确业务考核点→梳理考核点相关数据→定义指标。分为纵向分析(时间周期下,指标变化规律)、横向分析(指定维度下不同项的指标值差异)、预警分析(提供当前时点对应维度的指标累计值或者瞬时值,对比基准值)
-
数据分析方法(占比 10%)
-
-
客户分析
-
商品分析:售前:残次率、完工率;预热:曝光率、浏览量、支付转化率、销售增长率;销售高峰期:销售增长率、新用户占比、售罄率、连带销量、库存数量;衰退期:库存数量、跳出期。
-
流量、转化分析
-
行为效果分析
-
人(用户来源、活跃度、价值贡献)、货(进销存、品类结构、价格管理)、场(线上PC、群聊;线下综超、社区)
-
活动效果分析
-
目的:人(拉客流、促活、老用户回馈、流失召回、新用户注册)、物(临期库存清理、量贩促销、新品推荐)、绩效(销售额提升、利润提升、销售量提升)
-
量化效果:用指标值量化活动目标,同时需量化业务流程中的关键节点
-
日常销售分析,在指定时间范围内,回顾日常经营性行为
-
归因分析
-
发现问题(通过数据指标发现问题、结合业务流程还原问题所在场景)
-
近因分析(使用头脑风暴进行定性分析、使用定量分析方法验证发现)
-
根因分析(使用五问分析方法深入问题本质、使用鱼骨图法归纳问题)
-
做出预测(宏观业务趋势预测、微观对象倾向性预测)
-
制定方案(流程调整、寻找最优阈值)
-
验证方案(基于评估指标体系做AB测试)
-
业务分析模型
-
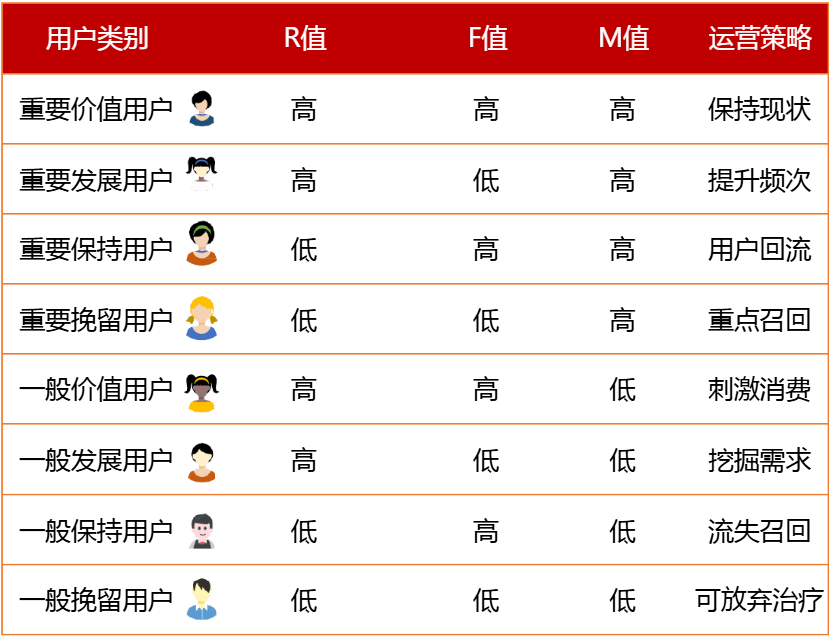
RFM模型,衡量客户价值与客户创利能力的重要工具和手段(R最近一次消费、F消费频次、M消费金额)
-
-
-
-
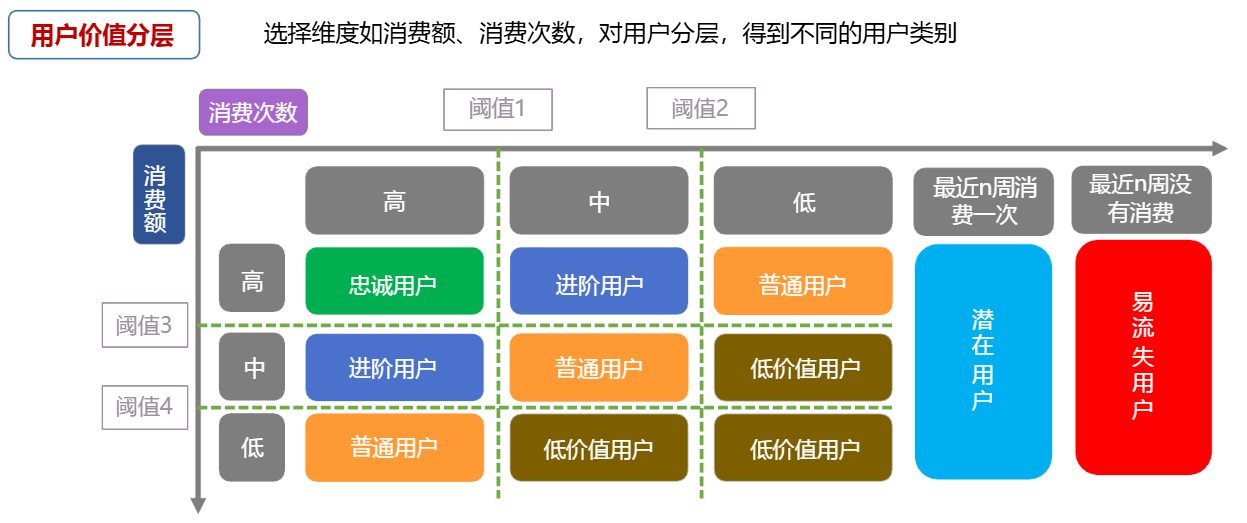
用户忠诚度模型
-
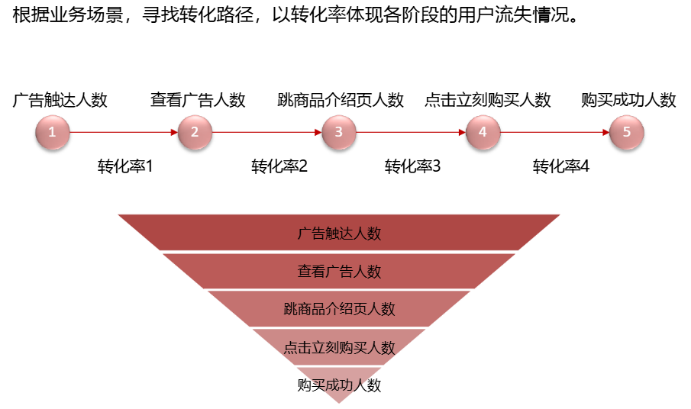
漏洞模型
-
-
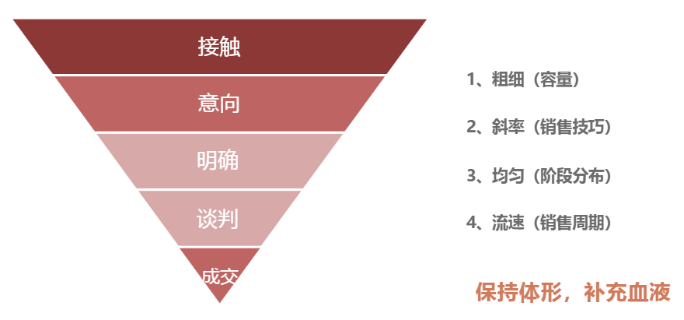
-
-
业务分析方法
-
因果分析(树状结构分析):从总体指标入手,逐层分解总体指标
-
梳理行业经常谈及的指标;
-
将指标拆解为另外多个指标的和或乘积,逐层下钻,直至无法快速理解;
-
将指标按拆解思路排放成树状结构,增加对比指标,如同比或环比,通过观察变化比率快速定位问题。
-
二八分析:数据按照数值进行降序排序,百分之八十问题由百分之二十的原因造成,找出问题原因。主要用于项目管理中找出核心问题。
-
四象限分析(波士顿矩阵):了解数据在两个核心要素下的表现,从而划分出具备不用特征的数据类
-
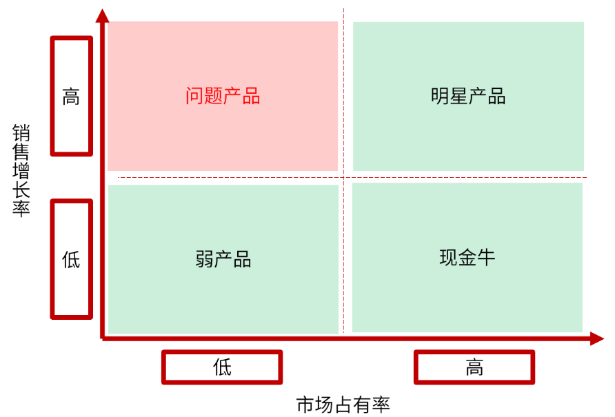
-
-
-
同期群分析:衡量指定对象组在某一时期内的持续性行为差异。分为同期群(具有相同特征属性的用户),进行分析(量化行为指标,分析不同群体随时间的变化情况)例:某平台2月1日新注册用户次日留存率&某平台2月2日新注册用户次日留存率.多用于产品新功能上线或渠道投放广告,判断拉新情况。
-
A/B测试分析法:先为一个业务目的,选择两种可行方案,然后将参加测试对象分两组,分别测试两种方案,根据结果选择更好的方案。
-
帕累托分析法(ABC分类法/主次因素分析法):将对象划分ABC三类,A因素发生频率为90%-100%,是主要影响因素;B因素发生频率为70%-90%,是次要因素;C因素,发生频率为70%以下,是一般影响因素。应用步骤(收集数据、统计汇总、编制分析表、制分析图、确定重点管理方式)
-
-
-
PART 7 业务分析报告与数据可视化报表(15%)
可视化分析图表(占比 5%)
-
-
业务图标决策树
-
比较类图表
-
进度VS目标:进度完成情况,多用油量表、圆环百分比进度图
-
项目VS项目:不同项目间的比较,适合单一维度,直观比较。多用柱状图、条形图、树状图
-
项目VS项目:不同项目间的比较,适合显示类别三个或更多维度的对比。多用雷达图
-
地域VS地域:地域间数据的比较,多用染色地图、散点地图、热力地图
-
-
-
序列类图表
-
连续、有序类别的数据波动,多用折线图、面积图、柱状图
-
各阶段数据递减过程,多用漏斗图
-
-
-
构成类图表
-
展示不同类别对于总数的占比,多用于饼图、环形图、南丁格尔玫瑰图
-
展示多类别部分到整体的关系,多用堆积图、百分比堆积图
-
展示各成分分布的构成情况,多用瀑布图
-
-
-
描述类图表
-
数据分组的差异,多用直方图。
-
变量之间的相关性,多用散点图、气泡图
-
撰写业务分析报告(占比 5%)
-
-
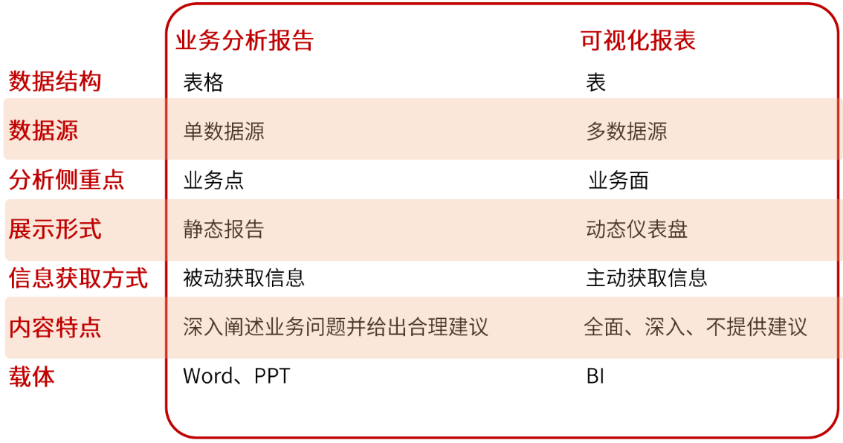
定义:时间段内的综合性时间评估,了解业务事实表现。分为静态报告(word/PDF or PPT格式),可视化看板
-
流程:业务理解(抓住问题核心,定位决策者角色,设定报表框架)、数据收集(系统数据采集,人工维护数据)、数据处理(字段标准统一,多表数据关联,异常数据处理)、数据分析(数据探索、运用分析方法论、结合高效工具)、图标制作(选择合适图表、准备图表数据、调节图标细节、撰写图表结论)、报告绘制(组合图表、撰写报告结论)
-
设计:报告类型(日常通报型、周期回顾型、专题通报型)→阅读者(来自哪个部门、关注重点是什么、报告表现场景是什么)→报告方向(报告的应用场景是什么、报告的目的是什么、报告的是否具有倾向性)
-
日常通报型:短周期、高频、持续性核心数据报表,适用内存饱和度检测、数据传送及时性、网速稳定性等
-
周期回顾型:长周期、低频、[持续性]综合数据报表,适用年度经营总结、个人季度工作报告、财务年度报表等
-
已设定目标:目标指标已达成→促进目标达成的原因→按贡献分配奖励→下一周期目标设定
目标指标未完成→拆分目标指标,寻找冲突,定位问题源头
未设定目标:选取核心指标,确定差异变化率;搭建主要分析框架
- 注意点:1.条理清晰,注意报告完整性;2.论点明确,有论必有数,有数必好懂;3.图、表、文结合;4.名词术语规范统一,未知名词标注解释;5.减少不必要的主观推测;6.切勿弄虚作假
- 专题回顾型:低频、专项关注点数据报表,适用于活动评估报告、渠道用户表现报告、库存亚健康分析等
创建数据可视化报表(占比 5%)
-
业务分析报告与可视化报表区别
-
创建流程
-
业务理解
-
与业务人员或决策者进行多次深入地访谈,实际业务工作中学习,查阅相关业务资料;
-
-
- 整体设计
-
作用:全面描述一个完整业务的场景情况;围绕某个业务问题进行全面的数据展现;
-
思维路径:一是明确业务需求,二是明确服务对象,三是明确业务流程及业务行为,四是围绕可落地的数据建议进行设计
-
设计思路:一是用数据展现问题,二是思考问题背后的原因及影响,三是思考为解决问题可能采取的业务流程及方法,四是思考提供的数据依据是否能在行为上落地执行,五是明确业务维度及观测度量,六是设计页面
-
- 用恰当的工具结合正确的操作完成从数据收集到创建复杂汇总规则的工作
-
数据收集——5W2H思维模型、ETL
-
数据加工整理——ETL、DW
-
搭建多维数据环境——OLAP
-
创建复杂汇总规则——OLAP
-
- 数据展现
-
图表与表格相结合→图表看趋势,表格看细节
-
活用四类可视化方法→对比、构成、序列、描述
-
简洁、易懂→正确区分总维度与筛选维度
-
围绕一个主题展开→与主题不相关及重复内容不放在页面中
-
- 整体设计
-
-
PART 8 数据管理(5%)
数据管理的基本概念(占比 1%)
-
-
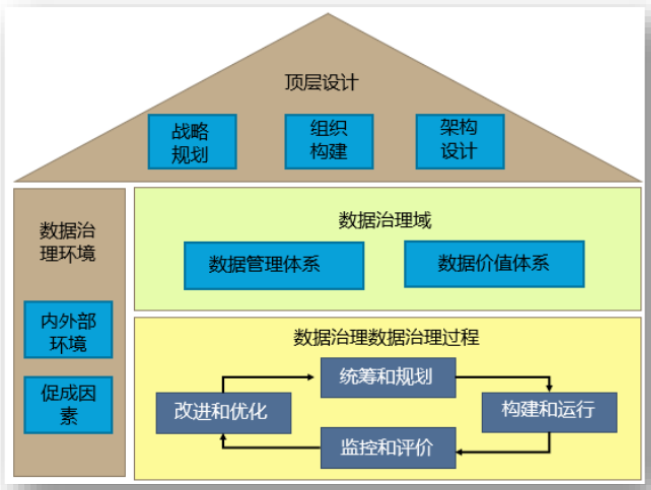
数据管理是为了交付、控制、保护并提升数据和信息资产的价值,在其整个生命周期中制定计划、制度、规程和实践活动,并执行和监督的过程。
-
数据管理发展史:早期:范围小于治理,按治理的办法和流程规定,完成实际的治理工作;现在:专业框架角度,如DCMM、DAMA原因,数据管理大于数据治理。国际国内立法角度,如《欧洲数据治理条例》,数据治理大于数据管理
-
基本概念:数据管理的价值体现在应对内外部业务发展和外部监管需求,实现数据资产的价值增值
-
狭义数据治理:一是保证数据资产的高质量、安全及持续改进;二是治理体系保障机制:数据治理组织,制度,沟通
-
广义数据治理:CDO概念的兴起,认为数据治理应包括数据价值变现部分,范围大于狭义数据治理,包括数据应用等
-
指标数据标准管理(占比 2%)
-
-
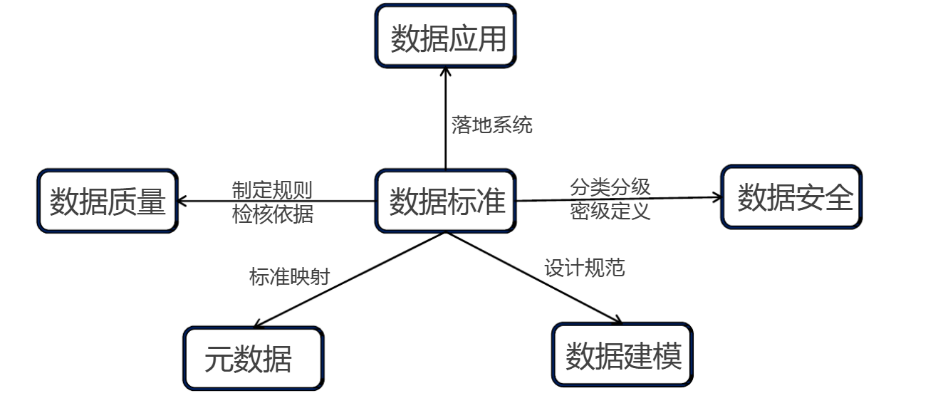
定义:规范数据标准的制定和实施的一系列活动,是数据资产管理的核心活动之一,对提升数据质量、厘清数据构成、打通数据孤岛、加快数据流通、释放数据价值有至关重要的作用。
-
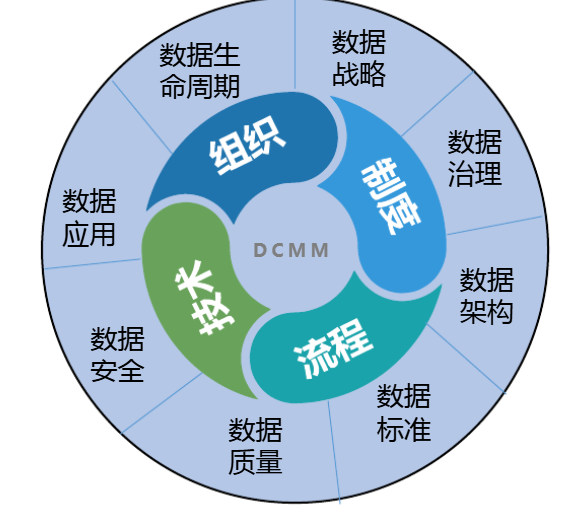
数据管理能力成熟度模型
-
初始级:数据需求的管理主要是在项目级进行体现,没有统一的管理流程,主要是被动式管理
-
受管理级:组织已经意识到数据是资产,根据管理策略的要求制定了管理流程,指定了相关人员进行初步的管理
-
稳健级:数据已经被当做实现组织绩效目标的重要资产,在组织层面指定了系列的标准化管理流程促进数据管理的规范化
-
量化管理级:数据被认为是获取竞争优势的重要资源,数据管理的效率能够进行量化分析和监控
-
优化级:数据被认为是组织生产的基础,相关管理流程能够被实现优化,能够在行业进行最佳实践的分享
-
-
-
指标的定义:
-
指标是说明总体数量特征的概念及其数值的综合,是具有(业务)意义的指向和标杆。
-
维度(统计维度、筛选条件)是对指标进行描述的不同视角,用于标示指标的不同方面的属性。
-
基础指标由业务运营数据直接加工成的指标,其业务定义,业务口径不随业务管理视角变化而变化。
-
组合指标由基础指标加上维度按照一定运算规则进行运算后生产的新指标,也称符合指标。
-
派生指标由多个指标进行运算后得到的指标,一般体现为比例或者比率的形式,也称衍生指标。
-
指标体系是系统反映评价对象整体的多个具体指标的集合。
-
数据质量管理(占比 2%)
-
-
数据质量的定义:在特定环境下,数据特征对于描述和使用需求的满足程度,包含六个维度
-
完整性:指数据在创建、传递过程中无缺失和遗漏,包括实体完整、属性完整、记录完整和字段完整四个方面。
-
及时性:指及时记录和传递相关数据,满足业务对信息获取的时间要求。
-
准确性:指真实、准确地记录原始数据,无虚假数据及信息。
-
一致性:指遵循统一的数据标准记录和传递数据和信息,主要体现在数据记录是否规范、数据是否符合逻辑。
-
唯一性:指同一数据职能有唯一的标识符。
-
有效性:指数据的值、格式和展示形式符合数据定义和业务定义的要求。
-
价值:一是提高组织数据价值和数据利用的机会;二是降低低质量数据导致的风险和成本;三是提高组织效率和生产力;四是保护和提高组织的声誉。
-
探查方法:数据剖析是一种用于检查数据和评估质量的数据分析形式。
-
错题分析
-
-
-
度量集中程度:众数、均值、中位数
-
度量离散程度:极差、四分位差、平均差、方差、标准差、离散系数、异众比率
-
度量相关性:协方差、卡方检验、列联相关系数、t检验(比较样本均值差异,定量数据)、f检验(比较样本方差,定量数据)、卡方检验(两个总体某个比率,定类数据)、皮尔逊相关系数(协方差与标准差之积的商,定量数据)、列联相关系数(计算频数相关性,定类数据)
-
BI报告设计核心为将抽象的业务逻辑转化为具象的维度和度量,BI报表与业务分析报告的区别是多维度下的透视分析,
-
词云图数据比较类图表
-
SKU:商品的最小单位,精确到最小型号;SPU:商品的品类细分。
-
SWOT:S优势、W劣势、O机会、T威胁。第一部分为SW,主要用来分析内部条件;第二部分为OT,主要用来分析外部条件。
-
客单价:销售额/消费用户数;ARPU:总收入/总用户数;单均价:销售额/订单数;付费率:付费人数/总用户人数。
-
一级指标拆解模型:UJM模型、AARRR模型、杜邦分析法、VSM模型
-
二项分布
-
AB测试分析/因果分析法
-
若想分析分类变量的相关性,用卡方检验和计算列相关系数(分类相关性卡列)卡列分;若分析数值类变量的相关性,用t检验和计算皮尔逊相关系数(数值相关性t皮)铁皮树!
-
-
好的,辛苦,接下来我们进入第三个部分,章节练习
-
回顾:制定决策方案是数据分析结果的应用环节,不属于数据分析步骤。
-
回顾:以下属于表结构分析数据工具的是:DB2/POWER BI/EXCEL(能表格,也能表啊,忘了,学的那个高级EXCEL BI功能啦!)
-
回顾:不能存放的字段,对啊,时间怎么会一样呢?
-
回顾:where和having的区别---having可以聚合,where可不行哦!
-
回顾:连接查询vs子查询
-
重点回顾:子查询出现的位置!(又忘又忘!!!)给我背住!
-
回顾:行数必考,尤其是各种的连接---左连接,右连接,内连接,全连接等等
-
回顾:理解题意,不先行代入,不先入为主!比如第32题的distinct和group by,想想,是的,distinct是去重,可是group by分组也是啊,那单选题会有两个正确答案?那肯定不会,那么问题出在哪里了呢?不错,还得和我最后的需求效果相匹配才行啊!
-
34题好题!很好,理解的还是肤浅少了一点!
-
回顾:删除表字段:alter table t1 drop id
-
回顾:group_concat函数,group_concat与group by一起使用,能够将分组后的指定字段值都显示出来
-
再次再次重点回顾:sql的执行顺序! from-on-join-where-grouop by-having-select-distinct-union-order by-limit!!!(还是那句话,5岁的你不能使用8岁的东西!)
-
回顾:一倍标准差,两倍标准差:68.26,95.44
-
回顾:相关性只有0.03,且其P值很大,所以是很不显著的相关性
-
回顾:实际中常用的数据特征包括-均值,比例,标准差,个体数量
-
回顾:区分离散系数和标准差的作用。离散系数越小,表示越集中;而方差越大,则代表性越弱!
-
回顾:懂了,标准差/平均值=离散系数(用于进行不同组的对比!)
-
回顾:众数不是数,比如说31题的众数不是7,而是C型品牌的机器!
-
回顾:星型模型vs星座模型vs雪花模型vs交叉模型
-
回顾:星座模型-多个事实表共用某些维度表,而且是一级的关系
-
回顾:如果两表甚至多表间要进行合并,则需要具有相同的主键ID
-
回顾:从订单表到订单提成表有多条筛选途径,所以是交叉连接
-
回顾:如何区分一表还是多表?--->去看是维度表还是事实表
-
回顾:在表结构数据下得到指标值结果---对表结构业务数据进行汇总计算
-
重点回顾:去重、计数针对的都是文本型字段!
-
回顾:季节性---环比增长率vs同比增长率
-
回顾:流量行为特征vs流量自身属性!---正好回顾下流量的质量:平均访问深度、新访客占比、跳失率;流量数量的指标:访客数、浏览量、新访客数、访问次数
-
回顾:树状体系图的目的,即可用于--->原因追踪、鸟瞰全局、预估影响
-
回顾:第16题,好题,考察知识点---漏斗分析模型用来描述阶段和推进力度(如:销售阶段周转化率)
-
回顾:再复习一遍波士顿矩阵分析划分的产品类型!(明星、金牛、瘦狗、问题)
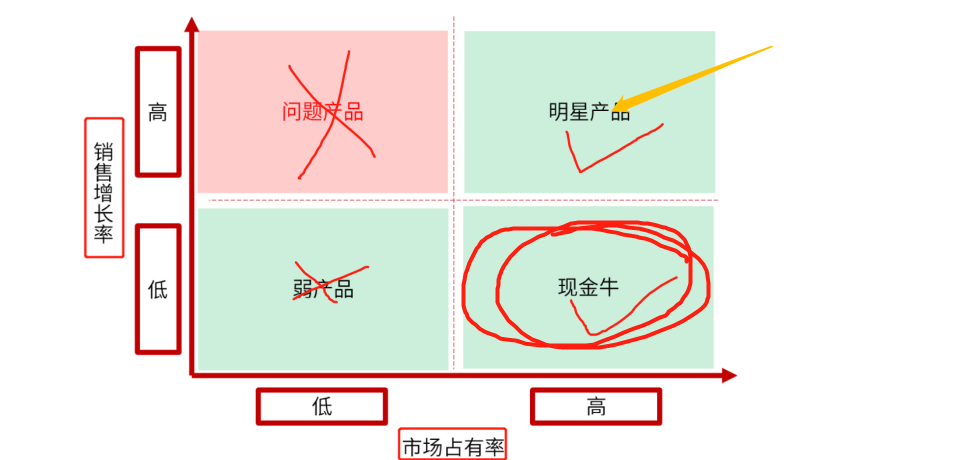
-
回顾:在电商企业中,划归在流量分析任务中的行为:了解~渠道特征,了解引流行为效果,了解流量人群特征 了解流量付费情况应该属于转化阶段的分析任务
-
回顾:UV是到店人数统计,进入首页即到店;pv是浏览量,以上数据无法计算。
-
回顾:CPC/CPS/CPM
-
补充:SKU是商品的最小单位
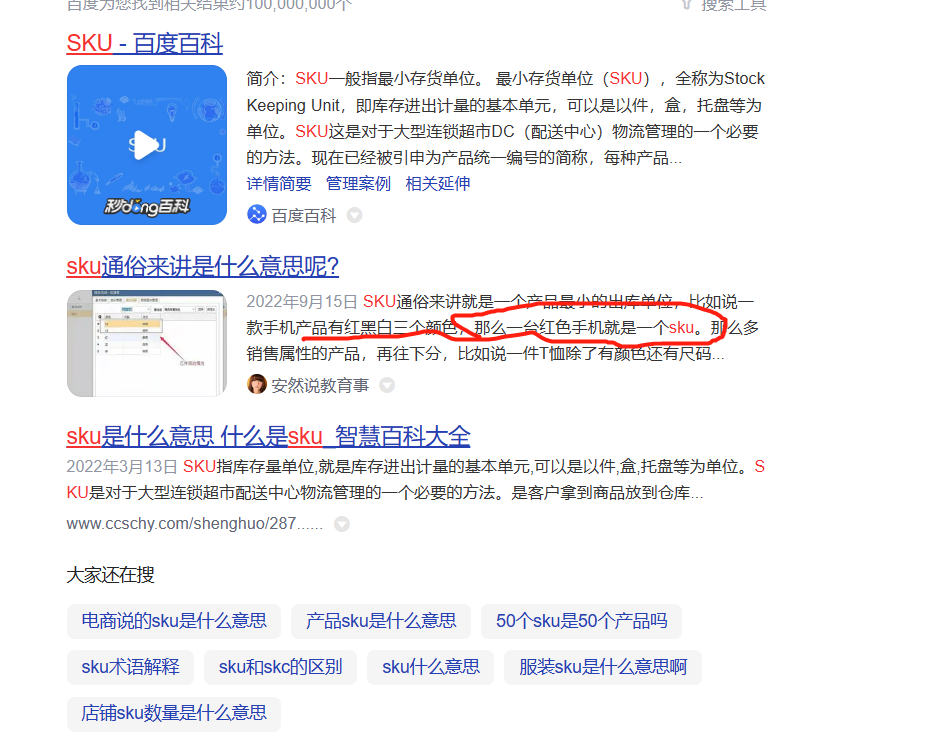
-
回顾:模型用于商品还是客户
-
回顾:定位重点对象vs时间状态变化场景
好的,辛苦,接下来我们进入第四个部分,二模
-
BI报表与静态报表的区别:侧重业务面的完整描述;动态信息展现;以图表表格为主要的展现形式;基于多源数据环境制作
-
销售额占总额的比例关系---饼图
-
业务图形决策树包括的类别:构成类、对比类、描述类、序列类
-
BI报表设计的核心内容就是明确业务需求涉及到的维度与度量
-
BI工具的组成部分:DW,ETL,可视化工具 那么不是呢?那就是比如数据源喽(DB)
-
BI报表中DW汇总不同数据源作为自己的数据源来使用
-
BI报表与业务分析报告是业务描述性分析中两类不同的分析结果的呈现形式,BI分析的主要特点是多维度下的透视分析(维度汇总度量)
-
业务分析报告分三类---日常通报型,周期回顾型,专题通报型(周期长短、报告提出频次高低、报告描述侧重点)
-
瀑布图属于构成类图表(描述各个构成阶段的分布情况)
-
纵向分析(同一个不同时间)vs横向分析(同一个时间不同的个)vs预警分析
-
获利情况不是阶段递进过程,不属于漏斗分析模型
-
业务场景下,毛利=收入-成本
-
人货场!---高频
-
某电商平台,可以直接描述商品销售情况好坏的情况:库存周转率、库销比、动销金额。
而动销天数用来辅助描述销售行为的风险程度而不是好坏程度!(风险程度vs好坏程度)
-
SPU vs SKU(SPU是商品的品类细分,比大品类细,但是比具体商品粗)记作:PK,越来越细!

-
电商企业黄金公式,流量为王(流量、转化率、客单价)
-
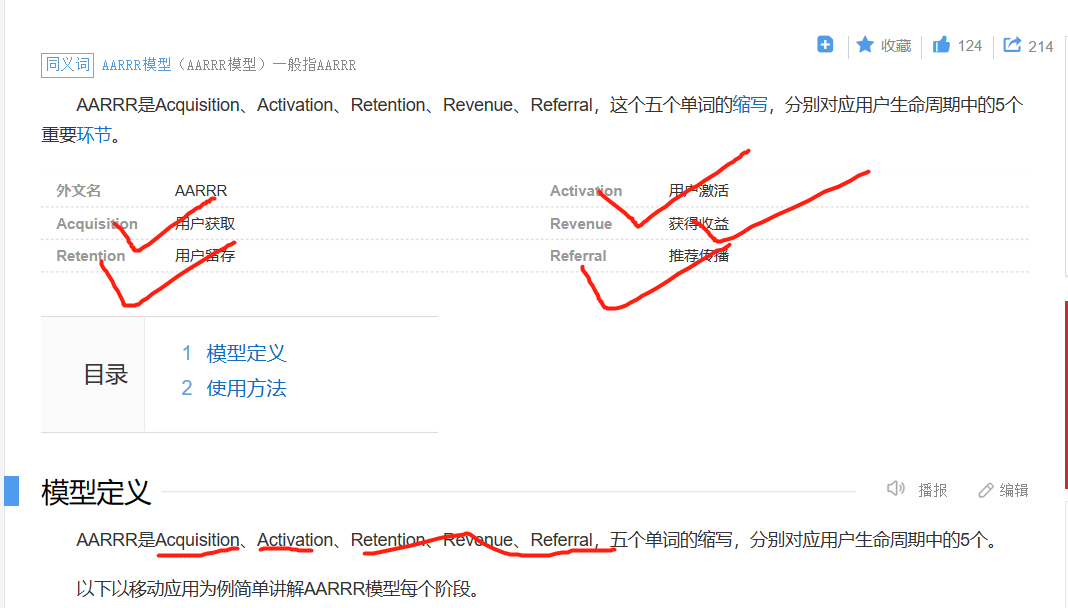
AARRR模型---电商运营业务中重要模型,补充:用户获取、用户激活、用户留存、获得收益、推荐传播(acquisition获取)、(activation激活)、(retention留存)、(revenue收益)、(referral推荐传播)
-
漏斗模型用于及时发现风险阶段,解决阶段风险,让尽可能多的商机过渡到更高阶段从而实现销售收入最大化的目的
-
无法统计的时候要留个心,可能就是对的!指标需要结合维度才能统计出结果!!!
-
数据+经验决定业务策略,数据驱动型业务模式也需要经验指导
-
补充,业务描述性分析方法,业务描述性的主要意义---精细化观测业务细节、及时发现业务问题、全面了解业务情况 而预测业务未来趋势是预测性分析,即预测性分析vs描述性分析
-
补充,长周期指标适合做同环比分析
-
细讲AARRR模型
-
获取---推广拉新
-
激活---转化活跃
-
留存--留存率鸭
-
收益--直接间接
-
推广--螺旋传播
-
CAC--用户获取成本
-
DAUMAU--日活、月活&平均使用时长、平均使用次数(尤指首日、次日留存率和七日留存率)
-
ARPU--平均每用户收入 ARPPU--平均每付费用户收入
-
LTV--生命周期价值
-
K因子--传染病学(最后一个阶段)

-
主键是业务数据的记录单位,而119题中主键是---访问日期+访问来源
-
回顾,计算变异系数(离散系数)---标准差/均值
-
品类的动销率=“动了”/总共滴品类M
-
屏效=“屏动了”/总共滴屏N
-
回顾,电商资金短缺,无法购买充足的流量,所以优先在资金投入少的转化率和客单价指标上采取对策
-
人数占比大的人群投入资金少,产生价值高

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)