
文档处理的相关工具
摘要:针对PDF文档的翻译需求,推荐使用开源工具PDFMathTranslate(https://github.com/Byaidu/PDFMathTranslate),支持保留公式和图片格式的翻译。可通过Python安装(pip install pdf2zh)或直接下载Windows版本使用,提供GUI界面和命令行操作,支持多语言翻译(如英文转简体中文)、多线程处理等功能。该工具兼容Bing等翻
目前网页端的文档,可以通过沉浸式翻译来进行翻译阅读和学习。
但是某些文献只有pdf下载的版本,所以需要一个免费的针对pdf的翻译工具。
保留公式和图片格式。
推荐一个pdf翻译的工具,可以自己部署使用。如果需要word版本,后面讨论了几个工具,最后使用adobe 的pdf文档处理的。

英文pdf到中文和一些语言的pdf工具
本地配置方案:达到的目的,把一个英文pdf文献,翻译为中文,并且变成可编辑的word格式。
通过uv安装
已安装 Python (3.10 <= 版本 <= 3.12)
pip install uv
uv tool install --python 3.12 pdf2zh
uv 是一个新一代的 Python 包管理工具,由开发 Ruff 的团队 (Astral) 创建,旨在替代传统的 pip 和 pip-tools。它的主要特点是:
极速安装:用 Rust 编写,比 pip 快 10-100 倍
跨平台:支持 Windows/macOS/Linux
兼容性:完全兼容 pip 和 requirements.txt
轻量化:独立的二进制文件,无需虚拟环境
pdf2zh document.pdf
直接下载win安装版
下载链接
pdf2zh-v1.9.9-with-assets-win64.zip: (推荐)带资源(字体、模型等)的 pdf2zh
因为字体的资源需要排版和识别。
python 下载和网页GUI
使用conda创建一个独立环境
conda create -n pdf_translation python=3.12
pip install pdf2zh
pdf2zh -i

最好在,需要生成的目录下,打开这个网页。
尝试使用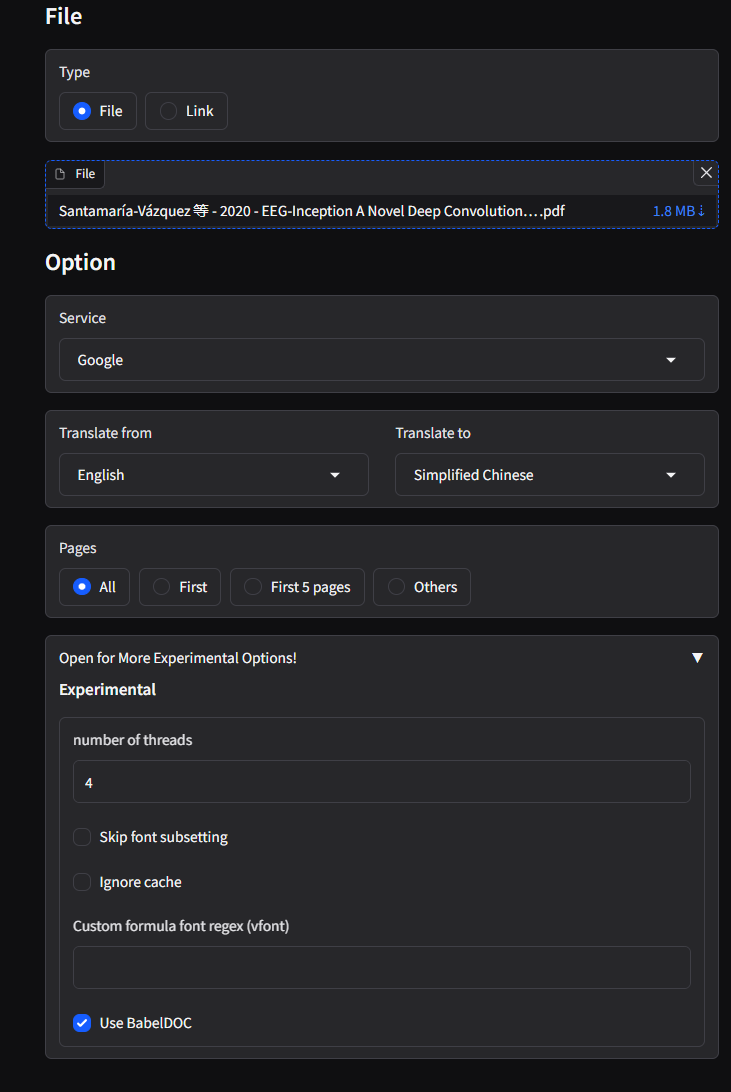
参数
这个命令应该有不少参数,网页端对于链接现在测试不通过。
但是file文件是可以使用的。
语言
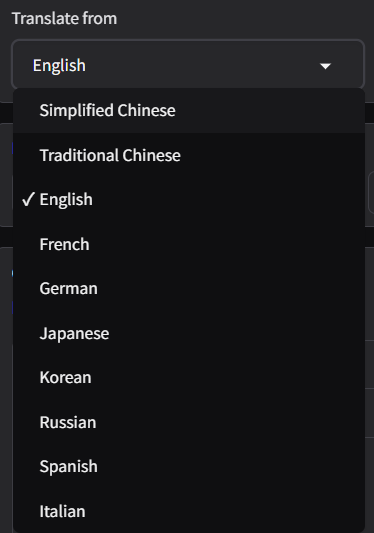
可以看到对于主流的语言,翻译是覆盖了的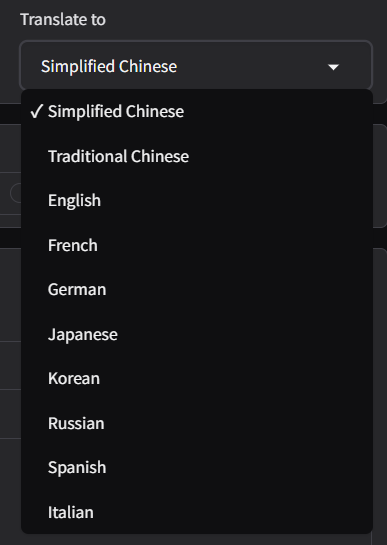
根据你提供的配置界面截图(image.png),这是 PDFMathTranslate 工具的选项设置界面。以下是各参数的详细解释:
📌 核心参数
-
Service(翻译服务)
- 当前选择:
Bing - 说明:使用的翻译引擎(可能还支持 Google/DeepL 等)
- 当前选择:
-
Translate from(源语言)
- 当前选择:
English - 说明:PDF 原文的语言
- 当前选择:
-
Translate to(目标语言)
- 当前选择:
Simplified Chinese - 说明:需要翻译成的语言(简体中文)
- 当前选择:
-
Pages(页面范围)
- 选项:
All:转换全部页面First:仅第一页First 5 pages:前5页Others:自定义页码范围(需手动输入)
- 选项:
⚗️ 实验性选项(Experimental)
-
Number of threads(线程数)
- 默认值:
4 - 说明:多线程处理加速转换(建议 ≤ CPU 核心数)
- 默认值:
-
Skip font subsetting(跳过字体子集化)
- 说明:忽略 PDF 中的字体子集(可能加快速度但影响排版)
-
Ignore cache(忽略缓存)
- 说明:强制重新处理(适用于更新后的 PDF)
-
Custom formula font regex(公式字体正则)
- 说明:用正则表达式指定公式字体(高级用户使用)
-
Use BabelDOC(✓ 已启用)
- 说明:启用 BabelDOC 引擎(优化公式转换的兼容性)
- 效果:
- 提升复杂公式识别率
- 支持 LaTeX/MathML 混合输出
- 解决特殊符号乱码问题
⚠️ 使用建议
-
基础转换:
python translate.py input.pdf --to zh-CN --service bing -
启用 BabelDOC(推荐):
python translate.py input.pdf --use_babeldoc -
多线程加速:
python translate.py input.pdf --threads 8 -
自定义页码范围:
python translate.py input.pdf --pages 1,3-5
💡 注意事项
- BabelDOC 是核心功能:对含数学公式的 PDF 有显著优化效果
- 线程数选择:
- 小文件:4 线程
- 大文件(>50页):建议 8-12 线程
- 中文排版:若遇乱码可尝试
--skip_font_subsetting
该界面通过
config_gui.py启动(项目中的 GUI 配置文件),完整参数可参考config.ini文件。
通过命令行使用
更多的扩展命令和高级用法说明文档
此处会设置选择和配置模型。
Below is the organized table of command options for pdf2zh based on the provided information:
| Option (选项) | Function (功能) | Example (示例) |
|---|---|---|
files |
Local files (本地文件) | pdf2zh ~/local.pdf |
links |
Online files (在线文件) | pdf2zh http://arxiv.org/paper.pdf |
-i |
Enter GUI (进入图形用户界面) | pdf2zh -i |
-p |
Partial document translation (部分文档翻译) | pdf2zh example.pdf -p 1 |
-li |
Source language (源语言) | pdf2zh example.pdf -li en |
-lo |
Target language (目标语言) | pdf2zh example.pdf -lo zh |
-s |
Translation service (翻译服务) | pdf2zh example.pdf -s deepl |
-t |
Multi-threads (多线程) | pdf2zh example.pdf -t 1 |
-o |
Output dir (输出目录) | pdf2zh example.pdf -o output |
-f, -c |
Exceptions (异常) | pdf2zh example.pdf -f "(MS.*)" |
-cp, --compatible |
Compatibility Mode (兼容模式) | pdf2zh example.pdf --compatible |
--skip-subset-fonts |
Skip font subset (跳过字体子集) | pdf2zh example.pdf --skip-subset-fonts |
--ignore-cache |
Ignore translate cache (忽略翻译缓存) | pdf2zh example.pdf --ignore-cache |
--share |
Public link (公共链接) | pdf2zh -i --share |
--authorized |
Authorization (授权) | pdf2zh -i --authorized users.txt [auth.html] |
--prompt |
Custom Prompt (自定义提示) | pdf2zh --prompt [prompt.txt] |
--onnx |
Use Custom DocLayout-YOLO ONNX model (使用自定义 DocLayout-YOLO ONNX 模型) | pdf2zh --onnx [onnx/model/path] |
--serverport |
Use Custom WebUI/Gradio port (使用自定义 WebUI/Gradio 端口) | pdf2zh --serverport 7860 |
--dir |
Batch translate (批量翻译) | pdf2zh --dir /path/to/translate/ |
--config |
Configuration file (配置文件) | pdf2zh --config /path/to/config/config.json |
--babeldoc |
Use Experimental backend BabelDOC to translate (使用 BabelDOC 后端翻译) | pdf2zh --babeldoc -s openai example.pdf |
--mcp |
Enable MCP STDIO mode (启用 MCP STDIO 模式) | pdf2zh --mcp |
--sse |
Enable MCP SSE mode (启用 MCP SSE 模式,需配合 --mcp) |
pdf2zh --mcp --sse |
Key Notes:
-
位置参数
files: 直接输入本地文件路径links: 直接输入在线文件 URL
-
别名选项
- 异常处理:
-f和-c功能相同 - 兼容模式:
-cp和--compatible功能相同
- 异常处理:
-
依赖选项
--sse需与--mcp同时使用
-
特殊模式
-i启动 GUI 后,可配合--share/--authorized实现高级功能--babeldoc需指定翻译服务 (如-s openai)
-
覆盖逻辑
--config可覆盖其他命令行参数--ignore-cache强制重新翻译全文
pdf2word
pdf2docx 这个python库,对于word的转换,支持的只有txt格式的pdf,对于图片无法处理。
直接使用Adobe Acrobat进行pdf转换。(有较多的图片块,可以编辑和粘贴,但是和正常的word版本不一致)
对于Pandoc使用进行的说明,适合。
Pandoc 使用说明
Pandoc 是一个强大的文档转换工具,被称为"文档转换的瑞士军刀"。它可以在多种标记格式之间进行转换,包括 Markdown、HTML、LaTeX、Word、PDF 等。但是此处并不是很合适,无法直接从pdf到word。
事实上,使用typora这个markdown的编辑器,并进行转换应用比较合适。
官网最新版本需要付费。
过去的版本,不需要付费
Pandoc
Windows
从 Pandoc 官网 下载 Windows 安装包,或使用包管理器:
# 使用 Chocolatey
choco install pandoc
# 使用 Scoop
scoop install pandoc
macOS
# 使用 Homebrew
brew install pandoc
# 使用 MacPorts
sudo port install pandoc
Linux
# Ubuntu/Debian
sudo apt-get install pandoc
# CentOS/RHEL
sudo yum install pandoc
# Arch Linux
sudo pacman -S pandoc
基本语法
Pandoc 的基本命令格式为:
pandoc [选项] [输入文件] -o [输出文件]
常用转换示例
Markdown 转 HTML
# 基本转换
pandoc input.md -o output.html
# 生成完整的 HTML 文档(包含 head 和 body)
pandoc input.md -s -o output.html
# 指定 CSS 样式
pandoc input.md -s --css style.css -o output.html
Markdown 转 PDF
# 需要先安装 LaTeX 或使用其他 PDF 引擎
pandoc input.md -o output.pdf
# 使用特定的 PDF 引擎
pandoc input.md --pdf-engine=xelatex -o output.pdf
# 设置中文支持
pandoc input.md --pdf-engine=xelatex -V mainfont="SimSun" -o output.pdf
Markdown 转 Word
pandoc input.md -o output.docx
# 使用自定义模板
pandoc input.md --reference-doc=template.docx -o output.docx
HTML 转 Markdown
pandoc input.html -o output.md
LaTeX 转其他格式
# LaTeX 转 HTML
pandoc input.tex -o output.html
# LaTeX 转 Word
pandoc input.tex -o output.docx
重要选项参数
基本选项
-o, --output:指定输出文件-f, --from:指定输入格式-t, --to:指定输出格式-s, --standalone:生成完整的文档--toc:生成目录
格式相关
# 明确指定输入输出格式
pandoc -f markdown -t html input.md -o output.html
# 生成带目录的文档
pandoc input.md --toc -s -o output.html
# 设置目录深度
pandoc input.md --toc --toc-depth=2 -s -o output.html
PDF 相关选项
# 设置页边距
pandoc input.md -V geometry:margin=1in -o output.pdf
# 设置字体
pandoc input.md -V mainfont="Times New Roman" -o output.pdf
# 设置文档类别
pandoc input.md -V documentclass=article -o output.pdf
高级用法
使用模板
# 使用自定义 HTML 模板
pandoc input.md --template=mytemplate.html -o output.html
# 查看默认模板
pandoc -D html > default.html
过滤器使用
# 使用 Lua 过滤器
pandoc input.md --lua-filter=filter.lua -o output.html
# 使用多个过滤器
pandoc input.md --filter=filter1 --filter=filter2 -o output.html
元数据设置
# 在命令行中设置元数据
pandoc input.md -V title="我的文档" -V author="作者名" -o output.html
# 使用元数据文件
pandoc input.md --metadata-file=metadata.yaml -o output.html
处理图片
# 提取媒体文件到指定目录
pandoc input.md --extract-media=./media -o output.html
# 设置图片路径
pandoc input.md --resource-path=./images -o output.html
支持的格式
输入格式
- Markdown(多种变体)
- HTML
- LaTeX
- Word docx
- OpenDocument
- MediaWiki
- Textile
- reStructuredText
- Emacs Org mode
输出格式
- HTML
- LaTeX
- Word docx
- OpenDocument
- ePub
- MediaWiki
- 各种幻灯片格式(reveal.js、Slidy、Beamer)
实用技巧
批量转换
# 批量转换所有 md 文件为 html
for file in *.md; do
pandoc "$file" -o "${file%.md}.html"
done
配置文件
创建 ~/.pandoc/defaults.yaml 文件来设置默认选项:
from: markdown
to: html
standalone: true
toc: true
css: style.css
然后使用:
pandoc input.md -d defaults -o output.html
数学公式支持
# 使用 MathJax 渲染数学公式
pandoc input.md --mathjax -s -o output.html
# 使用 KaTeX
pandoc input.md --katex -s -o output.html
常见问题解决
中文支持
对于包含中文的文档,转换为 PDF 时需要:
pandoc input.md --pdf-engine=xelatex -V CJKmainfont="SimSun" -o output.pdf
代码高亮
# 启用语法高亮
pandoc input.md --highlight-style=github -s -o output.html
# 查看可用的高亮样式
pandoc --list-highlight-styles
Pandoc 是一个功能强大且灵活的工具,掌握这些基本用法后,你就可以轻松地在各种文档格式之间进行转换了。更多高级功能可以参考 Pandoc 官方文档。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)