
【知识图谱】:【Joint方法】中对CasRel算法模型的理解
CASREL是一种高效、强大的关系抽取模型,通过级联架构和BERT编码器,解决了传统方法在复杂关系抽取中的不足。其核心思想是将问题分解为主体识别和关系-客体抽取两个阶段,既保证了精度又提高了效率。如果需要更具体的代码实现、数据集分析或实验结果,可以进一步提供相关信息或通过搜索X平台和网络获取最新进展。
一、知识图谱概念
知识图谱(Knowledge Graph)是一种通过图的形式组织和存储知识的技术。它将现实世界的实体(如人、地点、事物等)及它们之间的关系(如“是”、“属于”、“关联”等)表示为一个图形结构。每个实体通常被视为图中的一个节点,而它们之间的关系则是图中的边。
简单来说,知识图谱通过结构化的方式把知识中的各种信息(例如词汇、概念、事实等)用图形的形式呈现出来,方便机器理解、推理和查询。
主要特点:
-
节点和边:图谱的基础是节点(实体)和边(关系)。节点表示不同的实体或概念,边则表示它们之间的关系。
-
语义化:知识图谱不仅仅是数据的存储,它还注重数据的语义表达,即每个节点和边都有明确的意义。
-
联通性:通过图谱的结构,可以快速发现不同实体之间的联系,从而揭示更多潜在的信息。
-
推理能力:基于图结构,可以进行逻辑推理和智能查询,帮助发现新的知识。
典型应用:
-
搜索引擎:像Google的知识图谱,帮助提升搜索结果的准确性和丰富度。例如,当你搜索“泰坦尼克号”时,除了返回网页链接,搜索结果中还会显示与泰坦尼克号相关的事件、人物等信息。
-
推荐系统:通过分析用户和内容之间的关系,生成个性化的推荐。
-
智能问答系统:如Siri、Alexa等虚拟助手,能够通过图谱中的信息更好地理解和回答用户的提问。
与传统数据库的区别:
传统的数据库(如关系型数据库)通常以表格形式存储数据,而知识图谱则通过图的结构组织数据,能够处理更为复杂的多维关系。图数据库(如Neo4j)就是为此而生的,它能更高效地表示和查询图形结构的数据。
二、Joint方法概念
Joint联合抽取方法是通过修改标注方法和模型结构直接输出文本中的SPO三元组。核心在于将任务划分为两个阶段:
1. 头实体预测:识别出文本中所有的头实体
2. 关系-客体预测:对每个头实体,识别出其可能存在的关系和对应的尾实体
三、Joint联合抽取方法的分类
参数共享的联合模型
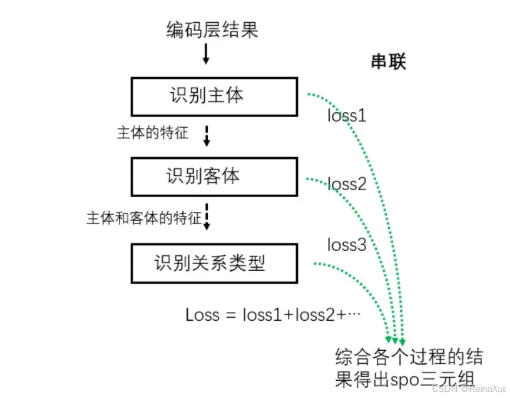
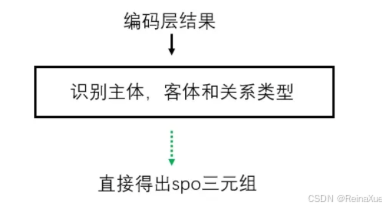
联合解码的联合模型
四、CasRel算法思想
CASREL(Cascaded Structured Relation Extraction)是一种基于BERT的级联结构化关系抽取模型,专门用于从文本中抽取实体及其关系。它通过两阶段的级联架构,先识别主体(subject),再抽取与主体相关的客体(object)和关系类型,适用于处理复杂的结构化数据,如三元组(subject, relation, object)。以下是对CASREL算法模型的详细讲解:
1. 模型背景
CASREL模型由Wei等人于2020年提出,旨在解决传统关系抽取方法在处理复杂文本时的问题,例如:
- 重叠关系:一个实体可能参与多个关系(如三元组重叠)。
- 多关系抽取:从同一句子中抽取多个关系。
- 实体识别与关系分类的联合建模:传统方法通常将实体识别和关系分类分开,导致误差累积。
CASREL通过引入级联架构,将实体识别和关系抽取结合,利用BERT的强大语义表示能力,提升抽取精度。
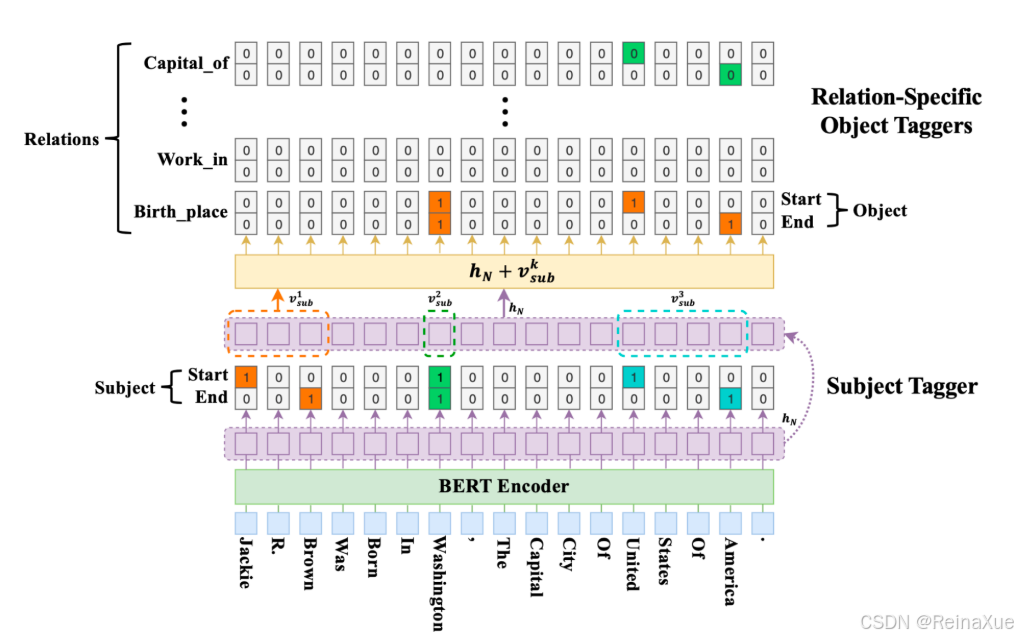
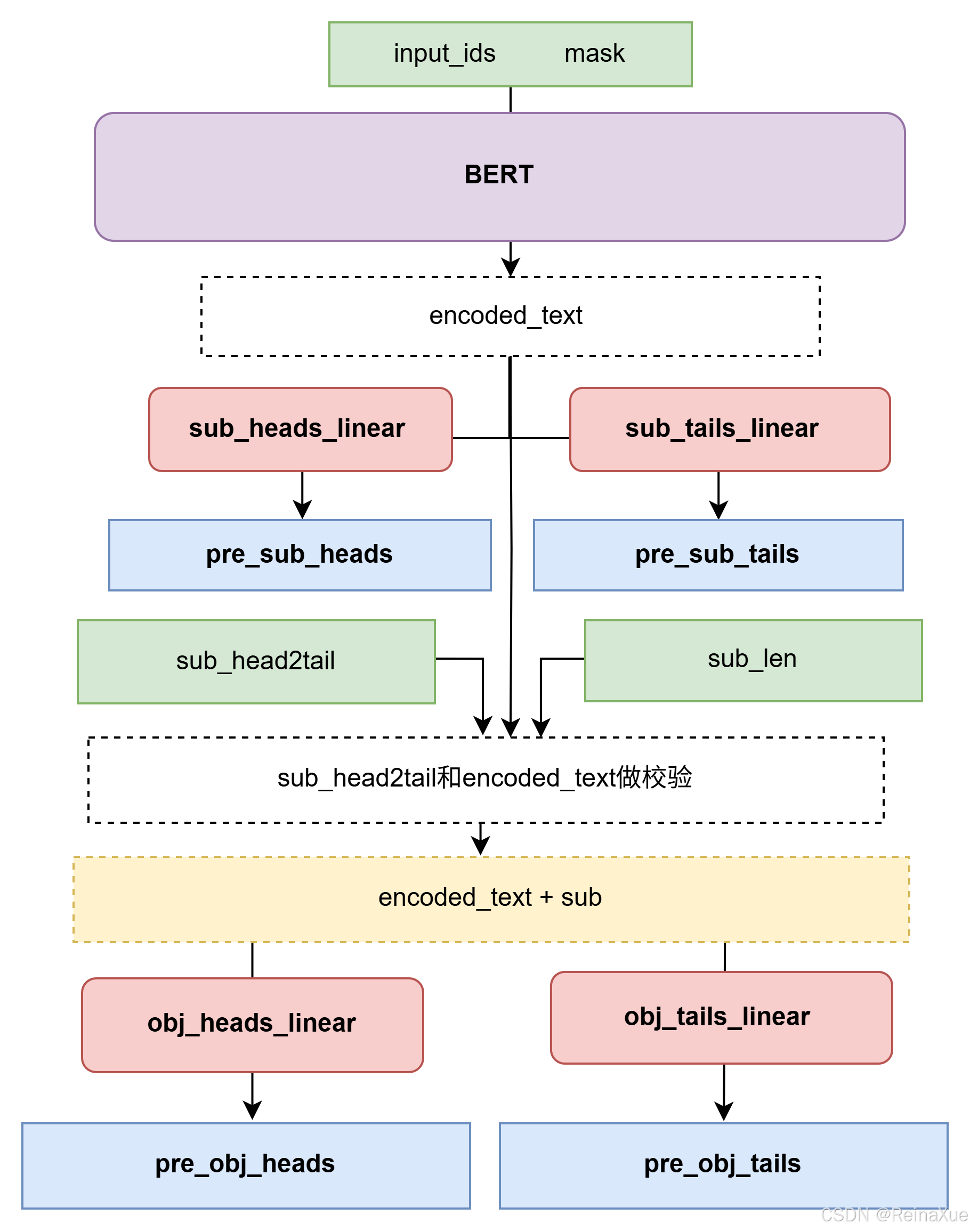
2. 模型架构
CASREL模型主要由以下三个部分组成:
(1) BERT编码器
- 输入:输入文本序列(句子),通过BERT模型编码为上下文相关的词向量表示。
- 作用:利用BERT的预训练能力,捕捉句子的语义信息,为后续的实体识别和关系抽取提供高质量的特征表示。
- 输出:每个词的上下文嵌入向量(hidden states),通常是BERT最后一层的输出。
(2) 主体识别(Subject Tagging)
- 任务:识别句子中的所有主体(subjects),即可能作为三元组起点的实体。
- 方法:
- 对每个词进行二分类,判断其是否是主体的开始或结束位置(BIO标注方式:Begin, Inside, Outside)。
- 使用全连接层(Fully Connected Layer)对BERT的输出进行处理,预测每个词是主体的概率。
- 输出:句子中所有可能的主体实体及其位置(start, end)。
(3) 关系-客体抽取(Relation-Specific Object Tagging)
- 任务:对于每个识别出的主体,抽取与其相关的客体(object)和关系类型。
- 方法:
- 关系分类:基于主体的表示(通过主体位置的BERT嵌入平均池化得到),预测主体可能参与的所有关系类型。
- 客体识别:针对每个关系类型,模型为句子中的每个词预测是否是该关系的客体(同样采用BIO标注)。
- 使用关系特定的全连接层,结合主体嵌入和BERT的上下文嵌入,预测客体的位置。
- 输出:每个主体对应的三元组(subject, relation, object)。
3. 工作流程
CASREL的工作流程可以概括为以下步骤:
- 文本编码:将输入句子送入BERT,得到每个词的上下文嵌入。
- 主体抽取:
- 对每个词进行二分类,标注主体的开始和结束位置。
- 得到所有可能的主体实体列表。
- 关系与客体抽取:
- 对每个主体,预测其可能的关系类型(多标签分类)。
- 对于每个关系类型,标注句中词是否为对应的客体。
- 后处理:将主体、关系和客体组合成三元组,输出最终结果。
4. 关键特点
- 级联架构:先抽取主体,再基于主体抽取关系和客体,减少了搜索空间,提高效率。
- 端到端训练:通过联合优化主体识别和关系-客体抽取,减少误差传播。
- 处理重叠关系:支持一个实体参与多个关系,适合复杂场景。
- 基于BERT:利用BERT的强大语义表示能力,增强上下文理解。
5. 训练与损失函数
- 主体识别损失:使用交叉熵损失(Cross-Entropy Loss)对每个词的BIO标签进行优化。
- 关系分类损失:对每个主体,使用二分类交叉熵损失预测可能的关系类型。
- 客体识别损失:对每个关系类型,使用交叉熵损失优化客体的BIO标注。
- 联合损失:总损失是主体识别损失、关系分类损失和客体识别损失的加权和。
6. 优点与局限性
优点:
- 高效性:级联结构将问题分解为主体识别和关系-客体抽取,降低复杂度。
- 灵活性:能处理重叠关系和多关系场景。
- 高性能:基于BERT的编码器提供了强大的语义表示,抽取效果优于传统方法。
局限性:
- 依赖BERT:对计算资源要求较高,推理速度较慢。
- 长距离依赖:当句子较长或实体间距离较远时,性能可能下降。
- 标注依赖:需要高质量的标注数据进行训练。
7. 应用场景
CASREL适用于需要从非结构化文本中提取结构化信息的场景,例如:
- 知识图谱构建:从新闻、维基百科等文本中抽取实体和关系。
- 信息检索:提取特定领域的三元组(如医疗、法律)。
- 问答系统:为开放域问答提供结构化知识支持。
8. 与传统方法的对比
- 管道式方法(Pipeline):
- 先进行命名实体识别(NER),再进行关系分类。
- 缺点:误差累积,难以处理重叠关系。
- 联合抽取方法(Joint Extraction):
- 同时抽取实体和关系,但搜索空间较大,效率较低。
- CASREL的优势:通过级联方式平衡了效率和性能,同时支持复杂关系抽取。
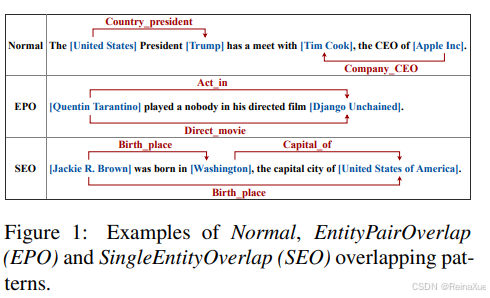
-
第一类:常规的问题 -- 一个文本中有多对关系
-
第二类:EPO问题 -- 实体对重叠,即同一对实体有多种关系
-
第三类:SEO问题 -- 单一字体重叠,即一个实体参与多种关系
【Casrel思想可以有效解决这三类问题】
9. 实现细节
论文中的图解:
代码层面的梳理:
10. 实验结果与数据集
CASREL在多个公开数据集上表现出色,如:
- NYT(New York Times):新闻领域数据集,包含多种关系类型。
- WebNLG:维基百科类数据集,适合知识图谱构建。 实验表明,CASREL在F1分数上显著优于传统管道式方法和部分联合抽取方法,尤其在处理重叠关系时。
11. 改进与未来方向
- 模型压缩:通过知识蒸馏或量化减少BERT的计算开销。
- 多模态扩展:结合图像或表格数据进行关系抽取。
- 零样本学习:支持未见过的关系类型,增强泛化能力。
总结
CASREL是一种高效、强大的关系抽取模型,通过级联架构和BERT编码器,解决了传统方法在复杂关系抽取中的不足。其核心思想是将问题分解为主体识别和关系-客体抽取两个阶段,既保证了精度又提高了效率。如果需要更具体的代码实现、数据集分析或实验结果,可以进一步提供相关信息或通过搜索X平台和网络获取最新进展。
论文链接:[1909.03227] A Novel Cascade Binary Tagging Framework for Relational Triple Extraction

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)