
Pattern-Based Prefetching with Adaptive Cache Management Inside of Solid-State Drives——论文泛读
针对SSD的预取,如何设计独立于操作系统和应用程序的数据预取机制。本文提出了支持自适应缓存管理的基于模式的预取 Cacher-SSD,在SSD的闪存转换层运行。主要包括两个技术:(1)从读请求的历史中挖掘I/O请求间的相关性,以得到经常一起读取的地址集合,在当前时间窗口中进行模式匹配以指导数据预取。(2)综合考虑读/写比率、历史预取精度,构建了一个数学模型,以支持自适应缓存管理。根据实际情况调整预
问题
数据预取是基于磁盘的文件系统常用的优化方案,因为从磁盘中提取数据占读取操作开销的主导地位[12]。预取适用于读取时具有常规访问模式的目标应用程序,如数据库服务器或科学计算[12,17]。在SSD中,预取可以屏蔽闪存数据块中的读取延迟,因为所需的数据已提前加载到RAM存储器中。因此,它已开始应用于各种基于SSD的存储系统[13,14,20]。
早期固态硬盘的内存大小和处理能力有限,现有预取方案的主要关注点是低计算成本和低功耗[20]。其中的大多数都涉及操作系统层,甚至操作系统层和SSD[13,14],这必然会损害兼容性和透明度。现有的SSD内部预取方案,它们的预测模型通常局限于有限的计算和内存资源[20]。
但现在的固态硬盘在微控制器中有很大的计算能力,内部也有更多的内存容量。例如,OpenSSD项目公开发布的Cosmos OpenSSD平台[15]配备了超过100 MB的SDRAM和嵌入式1 GHz ARM CPU。因此在现代SSD内部设计一种通用的预取方案是可行的,并且这种内部预取方法具有操作系统独立性和使用透明性的优势。
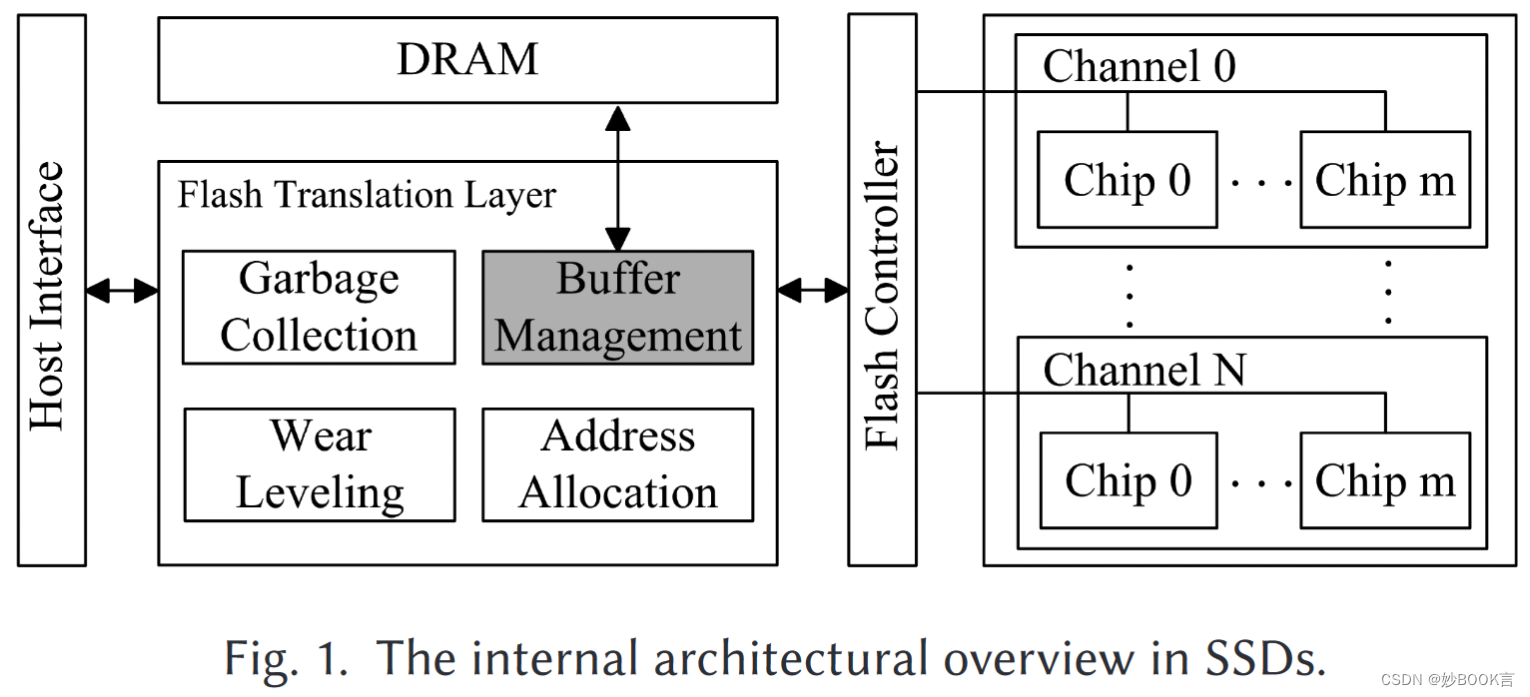
挑战
在启用预取功能的情况下,SSD高速缓存不仅用于缓冲写入的数据,还用于缓冲预取的数据。为了实现使用透明性,适应各种应用中的所有I/O特性,用于写和预取缓存的划分应该取决于工作负载中的实时因素,例如读/写比率和预取精度。
本文方法
通过实验观察,得到两个发现:
-
应用程序读取数据遵循空间局部性。因此,将热读取数据预取到SSD缓冲器中,有助于提供读取命中实现更好的I/O性能。
-
在应用程序的不同运行阶段,热读地址的数量不断变化。因此,动态调整预取高速缓存的大小,有助于提高高速缓存的使用效率。
本文提出了支持自适应缓存管理的基于模式的预取方案 Cacher-SSD,在固态驱动器(SSD)的闪存转换层运行,具有操作系统依赖性和透明性。

-
从读请求的历史中挖掘I/O请求之间的相关性,以代表经常一起读取的地址集合。利用一个矩阵来保存相关性信息,并在当前时间窗口中进行模式匹配以指导数据预取。
-
综合考虑几个因素,如读/写比率、历史预取精度,构建了一个数学模型,以支持自适应缓存管理。根据具体情况更精确地调整预取缓存和写入缓存的分区。
实验结果表明,与传统的SSD内部预取方案相比,本文的方案可以将平均读取延迟降低1.8%–36.5%,而不会显著增加写入延迟。
总结
针对SSD的预取,如何设计独立于操作系统和应用程序的数据预取机制。本文提出了支持自适应缓存管理的基于模式的预取 Cacher-SSD,在SSD的闪存转换层运行。主要包括两个技术:(1)从读请求的历史中挖掘I/O请求间的相关性,以得到经常一起读取的地址集合,在当前时间窗口中进行模式匹配以指导数据预取。(2)综合考虑读/写比率、历史预取精度,构建了一个数学模型,以支持自适应缓存管理。根据实际情况调整预取缓存和写入缓存的分区。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)