
Lift, Splat, Shoot Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D阅读小结
本文提出了一种新的端到端架构,能够直接从任意数量的摄像机图像中提取鸟瞰视图(BEV)场景表示。核心思想是将每个图像**"Lift"到每个摄像机的特征视锥体中,然后将所有视锥体“Splat”到一个BEV视图网格中。通过在完整的摄像机阵列上训练,模型能够学习如何表示图像以及如何将所有摄像机的预测融合成一个连贯的场景表示**,同时对校准误差具有鲁棒性。在标准的鸟瞰视图任务,如物体分割和地图分割上,该模型
论文地址:https://arxiv.org/abs/2008.05711
项目地址:https://github.com/nv-tlabs/lift-splat-shoot
Lift, Splat, Shoot Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
Lift, Splat, Shoot:通过隐式反投影至 3D 对来自任意相机阵列的图像进行编码
摘要
本文提出了一种新的端到端架构,能够直接从任意数量的摄像机图像中提取鸟瞰视图(BEV)场景表示。核心思想是将每个图像 “Lift” 到每个摄像机的特征 视锥体 中,然后将所有视锥体 “Splat” 到一个BEV视图网格中。通过在完整的摄像机阵列上训练,模型能够学习如何表示图像以及如何将所有摄像机的预测融合成一个连贯的场景表示,同时对校准误差具有鲁棒性。在标准的鸟瞰视图任务,如物体分割和地图分割上,该模型超越了所有基线和先前的工作。此外,模型的表示使可解释的端到端运动规划成为可能,通过将模板轨迹**“Shoot”**到网络输出的鸟瞰视图成本图中。
引言
传统的计算机视觉算法通常以图像为输入,输出与坐标系无关的预测,如分类,或在与输入图像相同的坐标系中输出预测,如物体检测、语义分割或全景分割。然而,自动驾驶感知的任务是在多个传感器输入下,每个传感器具有不同的坐标系,最终需要在新的坐标系中(即自车坐标系)产生预测,供下游规划器使用。本文提出的方法直接在给定的鸟瞰视图坐标系中从多视图图像中做出预测,适用于自动驾驶的感知需求。
方法
Lift: 潜在深度分布
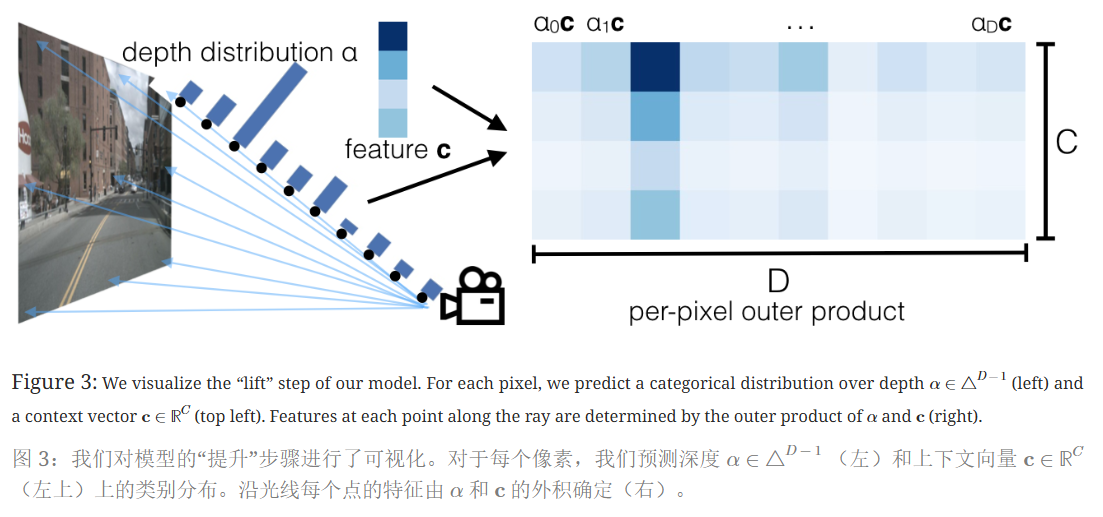
众所周知二维图像上并没有关于物体的深度信息,LSS的第一步操作Lift就是为了恢复图像的深度信息(增维)。
在所有可能的深度(为了解决单目传感器融合中深度信息的模糊性)上,为每个像素生成一个深度表示(backbone提取特征且下采样之后)。
在像素点p,模型会预测一个C维的上下文特征向量c和D维的深度分布α,沿光线的特征分布由α和c的外积决定(如图右所示)。
像素p 在图像坐标系中的坐标为( h , w ) ,D是一组离散深度,{(h,w,d)∈ℝ3∣d∈D}与每个像素相关联,只需为大小为D⋅H⋅W的给定图像创建一个大型点云。
总的来说,Lift这个操作是为每个相机的图像生成大小为D × H × W空间位置查询,这个空间中的每个点对应一个上下文特征向量C(对应图右中的每一列)。在相机的可视范围内,这个空间是一个视椎体。
Splat: 柱状池化
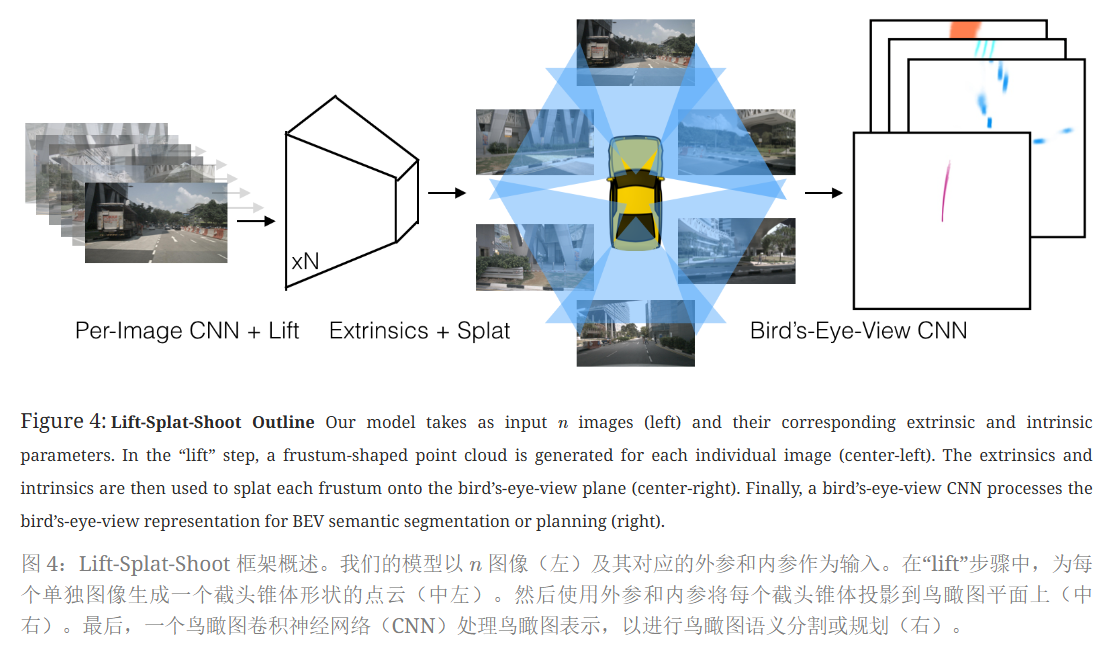
利用PointPillar的架构思想,模型采用点柱状结构将 “Lift提升” 步骤生成的大型点云转换为可以由标准CNN处理的张量。每个点被分配到最近的柱状体,利用“累计和”技巧来提升 求和池化 (sum pooling)的效率。
BEV网格由200x200个格子(BEV Pillar)组成,每个格子对应物理尺寸为0.5米x0.5米。即BEV网格对应车辆前、后和左、右各50m,且高度不限的3维空间。
不再对每个柱子进行填充再执行求和池化,而是通过打包、利用“累积和”来避免填充(过度内存使用)从而实现求和池化。
- 可以按照 bin ID 对所有点进行排序,对所有特征进行累加求和,然后减去 bin 段边界处的累加和值,以此实现求和池化。不用依赖自动微分(autograd)通过所有三个步骤进行反向传播,而是可以推导出整个模块的解析梯度,从而将训练速度提高 2 倍。将该层命名为“截锥体池化(Frustum Pooling)”,因为它可以将由 n 图像生成的截锥体转换为与相机 n 数量无关的固定维度 C × H × W 张量。
Shoot: 运动规划
LSS的关键是可以仅使用图像就可以实现端到端的运动规划。在测试时,用推理输出成本图cost map进行规划的实现方法是:”Shoot”输出多种轨迹,并对各个轨迹的cost进行评分,然后根据最低cost轨迹来控制车辆运动。这部分的核心思想来自《End-to-end Interpretable Neural Motion Planner》。
实验与结果
在nuScenes和Lyft Level 5数据集上评估了该方法。实验结果表明,Lift-Splat模型在所有基准测试上都超越了基线模型,包括物体分割和地图分割任务。此外,模型在处理传感器误差(如外参偏差或摄像机失效)方面表现出鲁棒性,并且在零样本相机阵列转移实验中也表现良好,即在未见过的摄像机配置上进行测试时,模型能够泛化。
结论
本文提出了一种架构,旨在从任意摄像机阵列推断鸟瞰视图表示。模型在一系列基准分割任务上超越了基线,展示了其在没有访问真实深度数据的情况下表示鸟瞰视图语义的能力。此外,模型对简单的校准噪声模型训练方法使其对传感器误差具有鲁棒性,并且能够实现端到端的运动规划。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)