
独特的模型架构设计与AI产业变革
DeepSeek(深度求索)作为中国领先的通用人工智能大模型,凭借其技术创新和行业应用能力,在AI领域展现出显著优势。随着计算资源需求的不断攀升,如何在保证模型性能的前提下降低训练成本和推理消耗,成为各大科技企业和研究机构的重点攻关方向。本文将深入探讨MLA(Multi-Level Attention,多层次注意力)架构与MoE(Mixture of Experts,混合专家)技术的结合,以及模型
目录
前言
DeepSeek(深度求索)作为中国领先的通用人工智能大模型,凭借其技术创新和行业应用能力,在AI领域展现出显著优势。随着计算资源需求的不断攀升,如何在保证模型性能的前提下降低训练成本和推理消耗,成为各大科技企业和研究机构的重点攻关方向。本文将深入探讨MLA(Multi-Level Attention,多层次注意力)架构与MoE(Mixture of Experts,混合专家)技术的结合,以及模型压缩、知识蒸馏和分布式训练框架对AI产业的深远影响。此外,我们还将分析开源生态如何推动技术共享,加速企业智能化转型。
1. MLA架构与MoE技术:优化计算效率
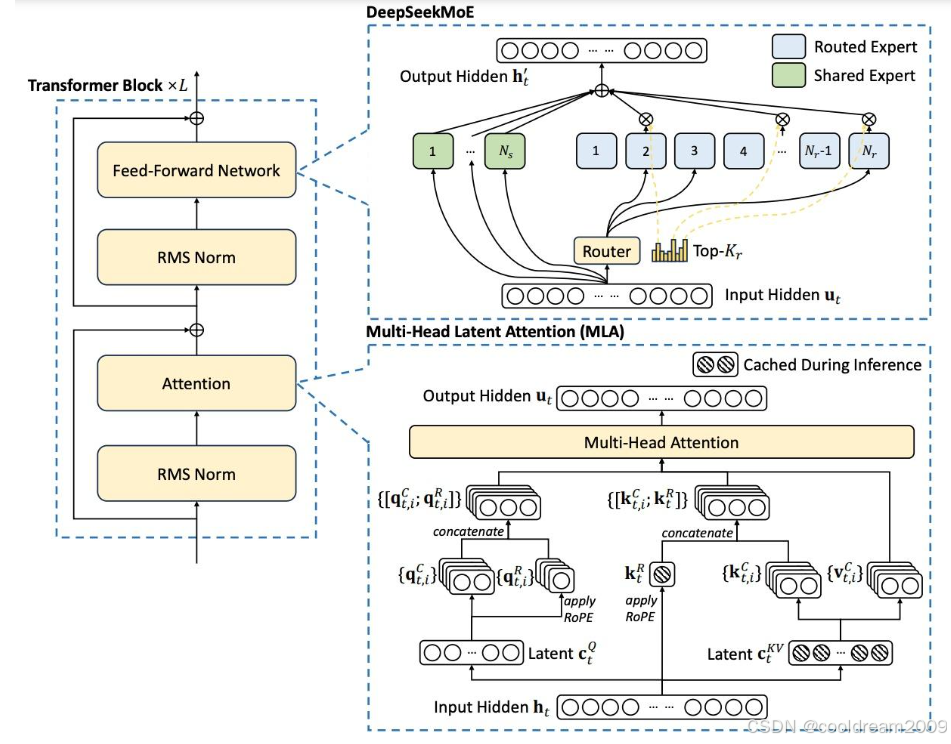
1.1 MLA架构的创新
MLA架构的核心理念是优化注意力机制,以降低计算资源消耗。传统Transformer架构在处理大规模文本时,KV Cache(键值缓存)占用大量存储空间,影响推理效率。而MLA架构通过引入层次化注意力机制,压缩KV Cache的大小,减少不必要的计算负担,从而提升整体算力利用率。
在实践中,MLA架构的主要优化点包括:
- 精细化注意力计算:通过多层次机制,仅保留关键信息,避免冗余计算。
- 动态KV Cache管理:智能调整缓存大小,减少不必要的存储占用。
- 自适应注意力机制:根据任务需求动态调整计算模式,提高推理速度。
这些改进使得MLA架构能够在大规模模型训练中显著降低计算资源消耗,同时在推理阶段提升响应速度。
1.2 MoE技术的突破
MoE技术是一种稀疏激活的神经网络架构,其核心思想是仅激活部分专家网络,以降低计算复杂度。相比于全连接的传统Transformer架构,MoE模型仅在需要时启用部分专家,从而减少GPU集群的通信开销。
MoE技术的主要优势包括:
- 稀疏计算:每次推理时,仅有一小部分专家被激活,大幅降低计算量。
- 专家网络自适应分配:根据输入特征,动态选择最适合的专家,优化推理效果。
- 并行计算能力增强:减少计算节点之间的通信瓶颈,提高训练效率。
得益于MLA与MoE技术的结合,AI模型能够在保持高性能的同时降低训练和推理成本,特别适用于大规模生成式AI任务。
2. 模型压缩与知识蒸馏:轻量化AI的关键
2.1 模型压缩技术
在计算资源受限的场景下,如移动端和边缘设备,如何部署高效的AI模型成为关键挑战。模型压缩技术的目标是减少模型参数数量,同时尽可能保持原有的推理能力。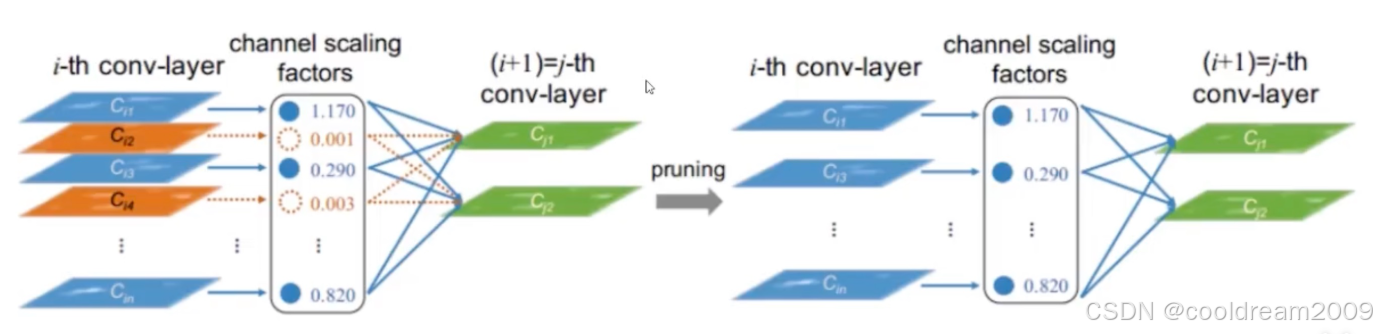
模型压缩的主要方法包括:
- 权重剪枝(Pruning):去除神经网络中冗余的权重参数,以降低模型复杂度。
- 量化(Quantization):将模型权重从高精度浮点数转换为低精度整数,减少存储需求。
- 低秩分解(Low-Rank Decomposition):通过矩阵分解技术减少计算需求,提高运算效率。
2.2 知识蒸馏:教师-学生模型协作
知识蒸馏(Knowledge Distillation)是一种将复杂模型(教师模型)的知识迁移到轻量化模型(学生模型)的技术。教师模型通常是一个大型预训练模型,具有强大的推理能力,而学生模型则是一个计算效率更高的简化版本。
知识蒸馏的核心流程包括:
- 教师模型训练:基于大规模数据训练出高精度的AI模型。
- 软标签生成:教师模型对训练数据进行推理,并输出概率分布(Soft Labels)。
- 学生模型学习:通过模仿教师模型的输出,学生模型学习特征表示,提高泛化能力。
这种方法不仅可以降低模型推理成本,还能够在资源受限的环境下保持较高的任务精度。
3. 开源与工具支持:推动AI技术普及
3.1 开源加速器:FlashMLA的优势
在高性能AI计算领域,FlashMLA加速器是一种专为GPU优化的高效计算框架。其核心优势在于:
- 推理速度优化:通过高效的内存管理和计算调度,实现“瞬间级别”推理响应。
- 动态资源管理:智能调度计算资源,降低能耗,提升算力利用率。
- 开源生态构建:通过开源策略降低技术门槛,促进行业共享。
3.2 分布式训练:算力优化的新范式
分布式训练技术是AI模型训练效率提升的重要手段。DeepSeek自主研发的分布式训练框架,通过优化算力分配和数据处理效率,使训练成本仅为GPT-4的二十分之一。
其主要特点包括:
- 智能算力分配:依据任务需求动态分配计算资源,提高利用率。
- 高效数据处理:优化数据并行和模型并行策略,加快训练速度。
- 低成本计算:减少GPU集群通信开销,实现高效训练。
通过这些优化手段,AI企业能够在有限的计算资源下完成大规模模型训练,从而降低成本,提高市场竞争力。
4. AI技术的未来展望
DeepSeek的核心优势在于“技术-成本-生态”三位一体:
- 技术突破:通过自研架构(如MLA、MoE)降低训练成本,提高推理效率。
- 成本优化:借助模型压缩、知识蒸馏和分布式训练,使AI计算更加经济高效。
- 生态构建:开放工具链,推动行业共享,助力企业智能化转型。
这些创新不仅提升了AI技术的可用性和普及度,也在重塑行业竞争格局。
结语
人工智能的发展离不开计算架构的持续优化。从MLA与MoE技术的结合,到模型压缩与知识蒸馏的落地,再到开源生态的构建,AI产业正在经历深刻变革。未来,随着分布式训练技术的进一步成熟,以及开源工具的广泛应用,AI技术将变得更加高效、普惠,并在多个行业释放更大的商业价值。DeepSeek等创新企业的努力,正在引领这一场智能革命,为全球AI技术发展贡献重要力量。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 24
24 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)