
如何训练工作作业行为安全数据集含有:焊接_高空作业_保温作业_叉车作业_重型设备作业数据集 安全行为数据集
《码头/工地事故安全含33w例图像数据集,包括碰撞/坠落/火灾等等事故类型》添加图片注释,不超过 140 字(可选)其中可识别工作行为含有:焊接/高空作业/保温作业/叉车作业/重型设备作业可用做目标识别模型,语义分割模型,其中附带mask,多边形边界框其中可识别安全设备含:安全帽/安全带/焊接面罩船舶/海工智能船厂、电气设备施工现场工人人工智能学习数据和工作环境安全数据的建立、风险评估人工智能基础
行为类《码头/工地事故安全含33w例图像数据集,包括碰撞/坠落/火灾等等事故类型》
其中可识别工作行为含有:焊接/高空作业/保温作业/叉车作业/重型设备作业
可用做目标识别模型,语义分割模型,其中附带mask,多边形边界框
其中可识别安全设备含:安全帽/安全带/焊接面罩
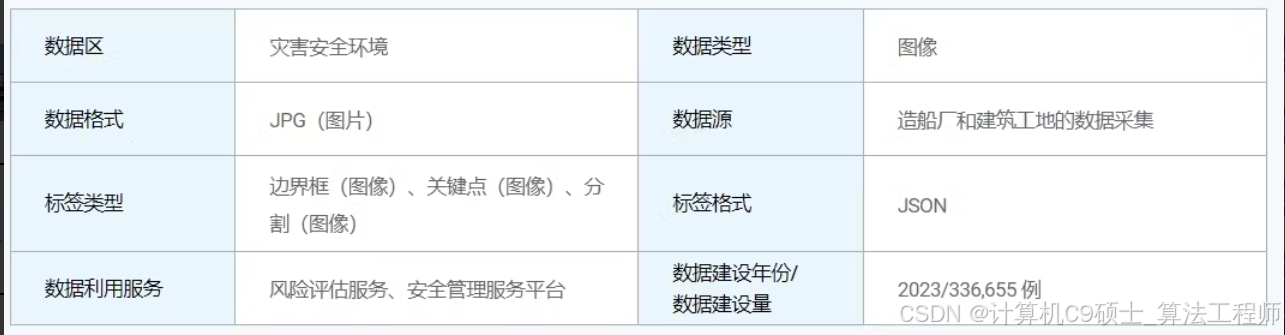
船舶/海工智能船厂、电气设备施工现场工人人工智能学习数据和工作环境安全数据的建立、风险评估人工智能基础数据建立。数据集由造船厂和建筑工地的进行采集,主要记录灾害安全环境336655例,格式为jpg;同时以边界框、关键点、分割作为标签,主要以json记录
使用YOLOv8进行训练的详细步骤和代码。
数据集介绍
- 数据集概述
数据集名称:码头/工地事故安全数据集
图像数量:336,655张图片
数据用途:用于开发确保劳动者安全和预防危险情况的AI管理技术
事故类型:包括碰撞、坠落、火灾等
工作行为:焊接、高空作业、保温作业、叉车作业、重型设备作业
安全设备:安全帽、安全带、焊接面罩
数据来源:由造船厂和建筑工地进行采集
数据格式:JPEG格式
标签格式:JSON,标签类型包括边界框、关键点、分割 - 数据集结构
假设你的数据集已经按照以下结构组织:
深色版本
safety_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
└── labels/
├── train/
├── val/
└── test/
每个文件夹中包含对应的图像文件和标签文件。确保所有图像文件都是.jpg格式,而标签文件是.json格式,并且它们的名字与对应的图像文件相同。
数据集配置文件
创建一个数据集配置文件(如safety_dataset.yaml),该文件定义了数据集的基本信息,包括路径、类别等。示例配置如下:
yaml
深色版本
训练和验证的数据集路径
train: safety_dataset/images/train
val: safety_dataset/images/val
test: safety_dataset/images/test
标签路径
labels_train: safety_dataset/labels/train
labels_val: safety_dataset/labels/val
labels_test: safety_dataset/labels/test
类别名称
names:
0: collision
1: fall
2: fire
3: welding
4: high_place_work
5: insulation_work
6: forklift_work
7: heavy_equipment_work
8: hard_hat
9: safety_belt
10: welding_mask
类别数量
nc: 11
数据集转换
假设你的标签文件是JSON格式,需要将其转换为YOLO格式的边界框标签文件。
- 安装依赖
确保你已经安装了必要的库:
bash
深色版本
pip install numpy opencv-python
2. 编写转换脚本
创建一个Python脚本来将JSON标签文件转换为YOLO格式的边界框标签文件:
python
深色版本
import os
import json
import cv2
def convert_json_to_yolo(json_path, image_path, output_dir):
with open(json_path, ‘r’) as f:
data = json.load(f)
image = cv2.imread(image_path)
image_height, image_width, _ = image.shape
yolo_annotations = []
for obj in data['objects']:
category_id = obj['category_id']
bbox = obj['bbox']
x_center = (bbox[0] + bbox[2] / 2) / image_width
y_center = (bbox[1] + bbox[3] / 2) / image_height
width = bbox[2] / image_width
height = bbox[3] / image_height
yolo_annotations.append(f"{category_id} {x_center} {y_center} {width} {height}")
output_file = os.path.join(output_dir, os.path.splitext(os.path.basename(image_path))[0] + '.txt')
with open(output_file, 'w') as f:
f.write('\n'.join(yolo_annotations))
def convert_all_labels(image_dir, label_dir, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for image_file in os.listdir(image_dir):
if image_file.endswith('.jpg'):
image_path = os.path.join(image_dir, image_file)
json_path = os.path.join(label_dir, os.path.splitext(image_file)[0] + '.json')
if os.path.exists(json_path):
convert_json_to_yolo(json_path, image_path, output_dir)
def main():
sets = [
(‘train’, ‘safety_dataset/images/train’, ‘safety_dataset/labels/train’, ‘safety_dataset/labels_yolo/train’),
(‘val’, ‘safety_dataset/images/val’, ‘safety_dataset/labels/val’, ‘safety_dataset/labels_yolo/val’),
(‘test’, ‘safety_dataset/images/test’, ‘safety_dataset/labels/test’, ‘safety_dataset/labels_yolo/test’)
]
for set_name, image_dir, label_dir, output_dir in sets:
convert_all_labels(image_dir, label_dir, output_dir)
if name == ‘main’:
main()
训练模型
- 安装依赖
确保你的开发环境中安装了必要的软件和库。YOLOv8是基于PyTorch框架的,因此你需要安装Python以及PyTorch。
安装Python(推荐3.7或更高版本)
安装PyTorch:你可以从PyTorch官方网站获取安装命令,根据你的系统配置选择合适的安装方式。
克隆YOLOv8的官方仓库到本地,并安装项目所需的其他依赖:
bash
深色版本
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
pip install -r requirements.txt
2. 训练模型
在完成上述准备工作后,你可以开始训练模型了。打开终端,进入YOLOv8项目的根目录,运行训练命令:
bash
深色版本
python ultralytics/yolo/v8/detect/train.py --data safety_dataset.yaml --cfg yolov8.yaml --weights yolov8x.pt --batch-size 16 --epochs 100
这里:
–data 参数指定了数据集配置文件的路径。
–cfg 参数指定了模型配置文件。
–weights 参数用于指定预训练权重的路径,这有助于加速训练过程并提高最终模型的性能。
–batch-size 和 --epochs 分别设置了批量大小和训练轮数。
模型评估
训练完成后,可以通过验证集来评估模型的性能。YOLOv8提供了方便的命令来进行模型评估:
bash
深色版本
python ultralytics/yolo/v8/detect/val.py --data safety_dataset.yaml --weights runs/train/exp/weights/best.pt
这里,best.pt 是训练过程中保存的最佳模型权重文件。
模型推理
你可以使用训练好的模型进行推理,检测新的图像中的目标。示例命令如下:
bash
深色版本
python ultralytics/yolo/v8/detect/predict.py --source path/to/your/image.jpg --weights runs/train/exp/weights/best.pt --conf 0.25
这里:
–source 参数指定了要检测的图像路径。
–conf 参数设置了置信度阈值,低于该阈值的检测结果将被忽略。
注意事项
数据增强:为了提高模型的泛化能力,可以考虑使用数据增强技术,如随机裁剪、翻转、颜色抖动等。
超参数调整:根据训练过程中观察到的损失值和验证集上的性能,适当调整学习率、批量大小等超参数。
硬件资源:如果显存不足,可以减少批量大小或使用更小的模型变体。
多尺度训练:可以尝试多尺度训练,以提高模型对不同尺度目标的检测能力。
进一步优化
数据预处理:确保图像质量和尺寸一致,可以使用图像增强技术提高模型的鲁棒性。
模型选择:根据实际需求选择合适的YOLOv8模型变体,如yolov8s、yolov8m、yolov8l等。
多GPU训练:如果有多块GPU,可以使用多GPU训练来加速训练过程。
示例代码
- 数据集转换(如果需要)
假设你的标签文件是JSON格式,可以直接跳过这一步。如果需要从其他格式(如COCO格式)转换,可以参考以下代码:
python
深色版本
import os
import json
import cv2
def convert_json_to_yolo(json_path, image_path, output_dir):
with open(json_path, ‘r’) as f:
data = json.load(f)
image = cv2.imread(image_path)
image_height, image_width, _ = image.shape
yolo_annotations = []
for obj in data['objects']:
category_id = obj['category_id']
bbox = obj['bbox']
x_center = (bbox[0] + bbox[2] / 2) / image_width
y_center = (bbox[1] + bbox[3] / 2) / image_height
width = bbox[2] / image_width
height = bbox[3] / image_height
yolo_annotations.append(f"{category_id} {x_center} {y_center} {width} {height}")
output_file = os.path.join(output_dir, os.path.splitext(os.path.basename(image_path))[0] + '.txt')
with open(output_file, 'w') as f:
f.write('\n'.join(yolo_annotations))
def convert_all_labels(image_dir, label_dir, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for image_file in os.listdir(image_dir):
if image_file.endswith('.jpg'):
image_path = os.path.join(image_dir, image_file)
json_path = os.path.join(label_dir, os.path.splitext(image_file)[0] + '.json')
if os.path.exists(json_path):
convert_json_to_yolo(json_path, image_path, output_dir)
def main():
sets = [
(‘train’, ‘safety_dataset/images/train’, ‘safety_dataset/labels/train’, ‘safety_dataset/labels_yolo/train’),
(‘val’, ‘safety_dataset/images/val’, ‘safety_dataset/labels/val’, ‘safety_dataset/labels_yolo/val’),
(‘test’, ‘safety_dataset/images/test’, ‘safety_dataset/labels/test’, ‘safety_dataset/labels_yolo/test’)
]
for set_name, image_dir, label_dir, output_dir in sets:
convert_all_labels(image_dir, label_dir, output_dir)
if name == ‘main’:
main()
2. 训练脚本
确保你已经将数据集和配置文件准备好,然后运行以下训练脚本:
bash
深色版本
进入YOLOv8项目目录
cd ultralytics
训练模型
python ultralytics/yolo/v8/detect/train.py --data safety_dataset.yaml --cfg yolov8.yaml --weights yolov8x.pt --batch-size 16 --epochs 100
3. 评估脚本
训练完成后,评估模型性能:
bash
深色版本
python ultralytics/yolo/v8/detect/val.py --data safety_dataset.yaml --weights runs/train/exp/weights/best.pt
4. 推理脚本
使用训练好的模型进行推理:
bash
深色版本
python ultralytics/yolo/v8/detect/predict.py --source path/to/your/image.jpg --weights runs/train/exp/weights/best.pt --conf 0.25
希望以上信息对你有所帮助

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)