
An LPDDR-based CXL-PNM Platform for TCO-efficient Inference of Transformer-based LLM...——论文泛读
针对提升大型语言模型(LLM)训练和推理所需内容容量和带宽的问题,模型并行等方法受限于低互联带宽,近内存处理(PNM)受限于扩展性和性能不足。本文提出CXL-PNM,基于CXL的PNM平台,优化GPU的容量和带宽,主要包括3个技术:(1)基于LPDDR5X的CXL内存架构,比DDR5和GDDR6有更高容量和带宽。(2)与推理集成的控制器,提供更高容量(硬件堆叠),可扩展性(多设备并行),并发(硬件
HPCA 2024 Paper CXL论文阅读笔记整理
问题
基于Transformer的大型语言模型(LLM),由于其出色性能而变得流行。对于LLM训练和推理,GPU一直是主要的加速器。然而,随着LLM的大小不断增加,单个GPU受限于其内存容量有限,需要频繁在GPU和主机CPU的内存/存储器间计算和传输当前层所需的模型参数。
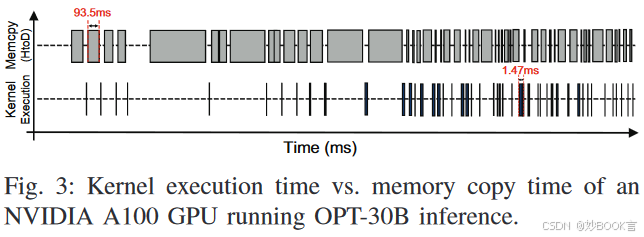
为了解决这些问题,之前工作提出了模型并行,以在多个GPU上分布LLM层和模型参数[1、38、44]。但在每层计算结束时,需要通过相对低带宽的互连(如NVLink或PCIe)来聚合多个GPU的中间结果,会成为LLM加速的关键瓶颈[1、6]。
之前工作也提出了内存内处理(PIM)和近内存处理(PNM)设备,如HBM-PIM[29]和AxDIMM[27],但存在四个缺点:
-
HBM-PIM有高昂的经常性开发成本,并且提供的容量有限。
-
AxDIMM提供有限的带宽和容量扩展。
-
AxDIMM采用DIMMPNM的低效仲裁来处理来自主机CPU和PNM加速器的并发内存请求。
-
HBM-PIM和DIMM-PNM都与主机CPU采用的内存地址交织技术存在冲突。
本文方法
本文提出了CXL-PNM,一个基于Compute eXpress Link(CXL)的近内存处理(PNM)平台,用于加速LLM推理。
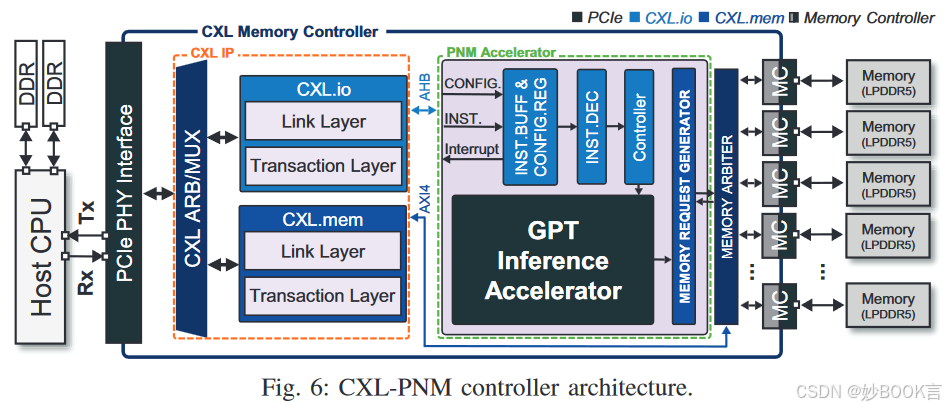
-
设计了基于LPDDR的CXL内存架构,使用商用 LPDDR5X[26] DRAM,相比于DDR5 [23]和GDDR6 [24] DRAM,其容量更高、I/O带宽更高、能耗低。设计的CXL内存容量为512GB,带宽为1.1TB/s,在模块外形约束下,其容量和带宽分别比基于GDDR6和DDR5的CXL存储架构大16倍和10倍。
-
设计了与LLM推理加速器集成的CXL-PNM控制器架构,来克服HBM-PIM和AxDIMM等技术的缺点,提供更高容量(使用LPDDR5X提供更高容量,堆叠多个芯片提升容量)、容量和带宽的可扩展性(多个设备并行,通过PCIe转接卡插入避免物理空间限制)、并发(硬件仲裁管理)、避免内存地址冲突(将CXL内存作为独立内存空间,避免地址映射的冲突)。
-
实现了CXL-PNM软件栈,包括Python库和设备驱动程序,支持基于Python的LLM程序简单的使用CXL-PNM进行转换。
评估表明,与具有8个GPU设备的GPU设备相比,具有8个CXL-PNM设备的CXL-PNM设备在LLM推理服务中的延迟降低了23%,吞吐量提高了31%,能效提高了2.8倍,硬件成本降低了30%。
总结
针对提升大型语言模型(LLM)训练和推理所需内容容量和带宽的问题,模型并行等方法受限于低互联带宽,近内存处理(PNM)受限于扩展性和性能不足。本文提出CXL-PNM,基于CXL的PNM平台,优化GPU的容量和带宽,主要包括3个技术:(1)基于LPDDR5X的CXL内存架构,比DDR5和GDDR6有更高容量和带宽。(2)与推理集成的控制器,提供更高容量(硬件堆叠),可扩展性(多设备并行),并发(硬件仲裁管理),地址冲突(CXL内存映射避免冲突)。(3)完整软件栈,支持python程序简单转换。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)