
模型微调深度指南:技术原理、工程流程与未来趋势
【摘要】模型微调已成为AI工程化落地的核心技术。本文系统梳理了模型微调的理论基础、标准流程、技术前沿、数据工程、评估体系、典型案例、开源与闭源对比、未来趋势与挑战等内容,全面解析其在实际应用中的深度与广度。
【摘要】模型微调已成为AI工程化落地的核心技术。本文系统梳理了模型微调的理论基础、标准流程、技术前沿、数据工程、评估体系、典型案例、开源与闭源对比、未来趋势与挑战等内容,全面解析其在实际应用中的深度与广度。
引言
人工智能技术的飞速发展,尤其是大模型(如GPT、LLaMA、Qwen、GLM等)的广泛应用,正在深刻改变各行各业的生产力格局。模型微调(Fine-tuning)作为AI工程化落地的关键一环,已成为推动AI从“技术实验”走向“行业赋能”的核心驱动力。无论是医疗、金融、制造,还是智能客服、内容生成,模型微调都在不断拓展AI的边界。本文将以系统化、工程化的视角,深度剖析模型微调的理论基础、标准流程、技术前沿、数据工程、评估体系、典型案例、开源与闭源对比、未来趋势与挑战等内容,力求为技术从业者、产品经理、决策者提供一份兼具深度与广度的实战指南。
一、🔍模型微调的定义与价值

1.1 模型微调的本质
模型微调是指在大规模预训练模型的基础上,利用特定领域或任务的数据,对模型参数进行进一步训练和优化,使其更好地适应新任务或场景。与从零开始训练模型相比,微调不仅大幅降低了数据和算力的需求,还能在短时间内实现模型的定制化和专业化。
1.2 模型微调的核心价值
1.1.1 领域适应性增强
-
在医疗、法律、金融等专业领域,通用大模型往往难以覆盖全部知识点。通过微调,模型能够快速吸收领域知识,显著提升专业表现。
1.1.2 风格与格式定制
-
微调可塑造特定语言风格和输出格式,满足如智能客服、儿童故事、法律文书等多样化场景需求。
1.1.3 纠正模型偏见与合规性提升
-
通过微调调整模型对敏感问题的回应方式,提升合规性和安全性,降低AI在实际应用中的伦理和法律风险。
1.1.4 资源高效利用
-
微调相比从零训练,极大降低了对数据和算力的需求,实现快速定制化,提升工程效率。
1.3 模型微调的适用场景
-
专业领域知识补充(如医学、金融、法律等)
-
特定风格或格式输出(如客服、儿童故事、法律文书等)
-
自动化操作与流程控制(如RPA、智能助手等)
-
纠正模型偏见与合规性提升(如内容审核、敏感话题处理等)
二、🆚开源与闭源模型微调的对比

2.1 开源模型微调
2.1.1 优势
-
技术透明、可深度定制、社区驱动、可独立部署
-
企业可完全控制数据流和模型迭代,适合对数据安全和定制化有高要求的场景
2.1.2 劣势
-
技术门槛高,需具备较强的算法和工程能力
-
安全风险需自控,需自行负责模型安全和合规
2.1.3 典型应用
-
金融、医疗、政务等对数据安全和定制化有高要求的行业
2.2 闭源模型微调
2.2.1 优势
-
即用性强、技术支持完善、安全性集中管控
-
适合快速商业化,企业可通过API进行微调,降低算力和运维压力
2.2.2 劣势
-
黑箱操作,长期依赖平台,定制化能力有限
-
模型所有权归平台,数据流动受限
2.2.3 典型应用
-
算力有限但对数据安全有要求的企业,或对AI能力有快速上线需求的场景
2.3 选择建议
-
业务需求、数据安全、算力资源等多维度权衡
-
开源模型适合深度定制和数据安全要求高的场景
-
闭源模型适合快速上线和算力资源有限的场景
三、🛠️模型微调的标准流程

3.1 需求分析与目标设定
3.1.1 明确业务场景与目标任务
-
明确模型微调的业务场景、目标任务和性能指标
-
评估是否已充分尝试Prompt工程、RAG等替代方案
-
设定预期性能提升目标和业务指标
3.1.2 需求分析流程图
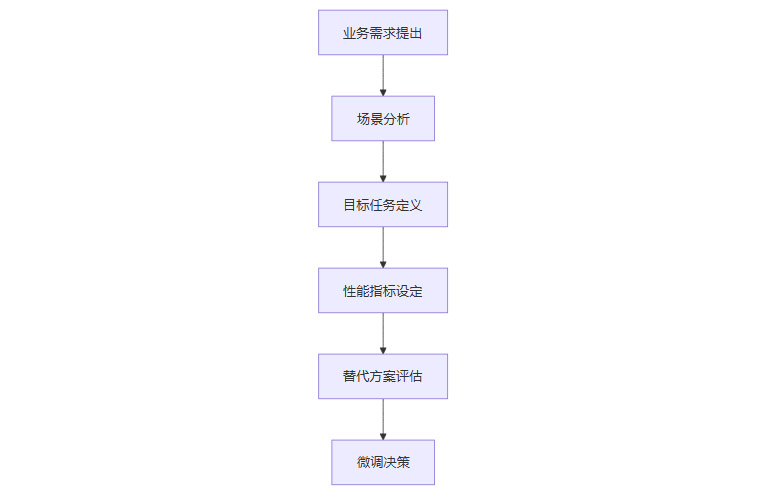
3.2 数据收集与准备
3.2.1 数据来源
-
企业数据库、日志、用户交互、专家标注等
3.2.2 数据清洗与标注
-
去除噪声、确保标注准确
3.2.3 数据划分
-
训练集(70-80%)、验证集(10-15%)、测试集(10-15%)
3.2.4 数据增强
-
同义词替换、反向翻译、混合生成等提升多样性
3.2.5 偏好数据收集
-
用户点赞/点踩、客服多模型对比等,构建高质量偏好数据集
3.2.6 数据准备表格
|
数据类型 |
来源 |
处理方式 |
作用 |
|---|---|---|---|
|
结构化数据 |
企业数据库 |
清洗、标注 |
训练/验证/测试 |
|
非结构化数据 |
用户交互、日志 |
清洗、分词、标注 |
训练/增强 |
|
偏好数据 |
点赞/点踩、对比 |
聚合、去重 |
偏好微调 |
|
合成数据 |
生成模型 |
多语种回译、混合 |
数据增强 |
3.3 模型选择
3.3.1 开源模型优先
-
结合业务需求选择合适的模型架构和尺寸(如7B、13B、33B等)
3.3.2 闭源API适用场景
-
算力有限但对数据安全有要求的场景
3.3.3 模型选择流程
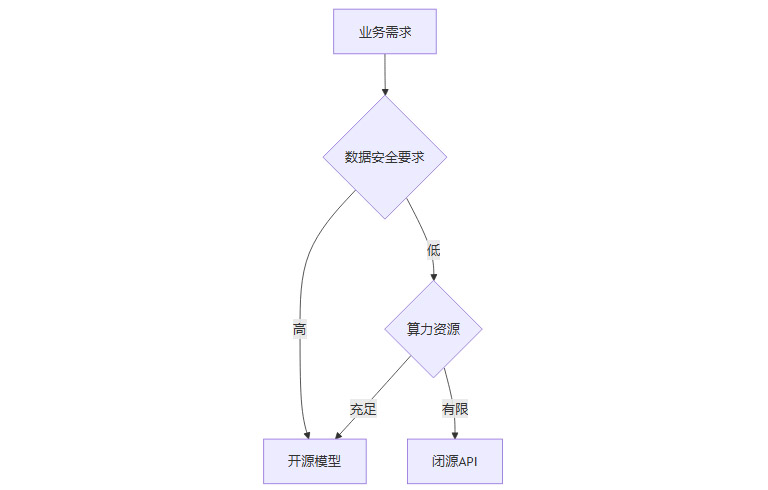
3.4 微调方法选择
3.4.1 全参数微调
-
更新全部参数,适合数据量大、算力充足场景,效果最佳但成本高
3.4.2 参数高效微调(PEFT)
-
如LoRA、QLoRA、Adapter、Prefix Tuning等,仅调整少量参数,显存占用低,适合资源有限场景
3.4.3 LoRA与QLoRA
-
LoRA:低秩矩阵分解,极大降低算力需求
-
QLoRA:结合4-bit量化,显存占用降至1/4,单张消费级显卡即可微调大模型
3.4.4 冻结部分参数
-
只训练部分层,防止灾难性遗忘和过拟合
3.4.5 渐进微调、多任务微调
-
适合复杂或多场景任务
3.4.6 混合专家系统(MoE)
-
如谷歌GShard,动态路由输入至不同专家网络,提升推理效率
3.4.7 微调方法对比表
|
微调方法 |
算力需求 |
数据需求 |
定制化能力 |
适用场景 |
|---|---|---|---|---|
|
全参数微调 |
高 |
高 |
强 |
大数据、强定制 |
|
LoRA/QLoRA |
低 |
中 |
强 |
资源有限、快速迭代 |
|
Adapter/Prefix |
低 |
中 |
中 |
多任务、轻量场景 |
|
冻结部分参数 |
中 |
中 |
中 |
防止遗忘、过拟合 |
|
MoE |
高 |
高 |
强 |
多专家、复杂任务 |
3.5 训练与调优
3.5.1 超参数设置
-
学习率、批量大小、训练轮数等需根据任务和数据规模调整
3.5.2 过拟合防控
-
采用验证集、早停法、Dropout等技术
3.5.3 数据增强与合成
-
多语种回译、同义词替换、混合生成等提升数据多样性
3.6 模型评估
3.6.1 自动化指标
-
准确率、召回率、F1分数、BLEU、ROUGE、困惑度等
3.6.2 人工偏好评测
-
A/B测试、盲测支持率,支持率>70%为成功,>80%为显著提升
3.6.3 领域适应性指标
-
如Domain Relevance Score(DRS)评估模型与业务场景的匹配度
3.6.4 动态监控
-
实时A/B测试、性能阈值触发回滚机制
3.6.5 评估流程图
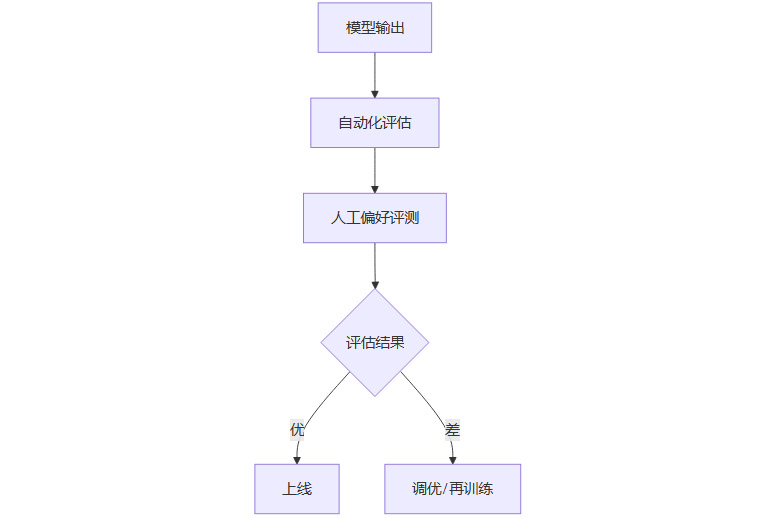
3.7 部署与上线
-
将微调后的模型部署到生产环境,支持API调用或本地推理
3.8 监控与维护
-
持续监控模型性能,收集用户反馈,定期再训练或微调以适应新数据和业务变化
3.9 反馈循环与数据工程
-
设计产品功能收集用户偏好数据(如点赞/点踩、多选、客服辅助等)
-
建立数据管理平台,支持数据去重、增强、自动标注和评估,提升数据工程效率
四、💡数据工程创新与实践
4.1 偏好数据收集
-
百度智能云客服系统、知乎社区通过用户行为构建大规模偏好标注库,支持强化学习微调
-
客服工作台辅助:模型生成多个回复,人工选择最优,收集偏好数据
4.2 合成数据增强
-
腾讯混元大模型通过多语种回译扩充法律问答数据,F1值提升8.3%
-
数据增强技术包括同义词替换、词序打乱、反向翻译、数据混合等
4.3 数据管理平台
-
百度智能云数据管理平台,支持多源数据管理、体系化标注、自动增强等功能
-
数据来源管理、体系化标注、数据去重与增强、数据打包、模型评估等一体化
4.4 利用LLM能力提升数据工程效率
-
自动数据过滤、标注、增强,提高数据工程效率
-
利用强大模型进行数据过滤、自动打标、交叉复检、prompt相似度计算、response质量对比、数据增强和模型评估
4.5 数据工程流程表
|
阶段 |
关键任务 |
工具/方法 |
目标 |
|---|---|---|---|
|
数据收集 |
多源数据聚合 |
数据管理平台 |
丰富数据来源 |
|
数据清洗 |
去噪、去重 |
自动化脚本、LLM |
提升数据质量 |
|
数据标注 |
专家/众包/AI打标 |
标注平台、LLM |
保证标注准确性 |
|
数据增强 |
回译、同义词替换等 |
LLM、自动化工具 |
扩充数据多样性 |
|
数据打包 |
自动划分、版本管理 |
数据平台 |
便于训练与评估 |
|
数据评估 |
偏好打标、专家评分 |
评估平台、LLM |
评估数据与模型表现 |
五、🏆行业落地典型案例

5.1 医疗领域
-
深睿医疗基于GLM-130B模型,使用10万份三甲医院影像报告微调,肺结节检测准确率从89%提升至96%,获国家药监局三类医疗器械认证
5.2 金融风控
-
蚂蚁集团利用QLoRA对qwen-7B量化微调,在反欺诈任务中实现毫秒级响应,误报率降至0.02%,节省年度风控成本超2亿元
5.3 智能制造
-
宁德时代采用LoRA微调LLaMA-13B,预测设备故障准确率达92%,减少非计划停机损失3000万元/年
5.4 智能客服
-
招商银行智能客服微调后支持率达83%,显著高于基线模型(52%)
5.5 多模态应用
-
商汤科技“书生”模型通过联合微调文本-图像对齐模块,电商商品描述图文匹配度提升至91%
六、📊评估体系与监控
6.1 多维度评估
-
结合自动化指标与人工偏好评测,确保模型在目标场景下优于原模型
6.2 动态监控与回滚
-
京东云实时评估平台,监控A/B测试数据,性能异常自动回滚
6.3 领域适应性与合规性
-
欧盟AI法案要求微调模型保留完整数据溯源记录
-
医疗、金融等领域需通过第三方伦理审查
七、🚀技术前沿与未来趋势

7.1 参数高效微调(PEFT)
-
LoRA、QLoRA等技术成为主流,极大降低大模型落地门槛
7.2 混合专家系统(MoE)
-
提升推理效率和模型扩展性
7.3 自动化微调
-
Hugging Face AutoTrain,自动选择微调方法和超参数,训练效率提升40%
7.4 多模态微调
-
文本、图像、音视频等多模态数据的联合微调成为新趋势
7.5 合规性与伦理挑战
-
数据隐私、灾难性遗忘、过拟合、合规风险等问题需持续关注和解决
八、📝最佳实践与注意事项
8.1 数据质量优先于数据量
-
高质量标注和多样性是微调成功的关键
8.2 合理选择微调方式
-
根据算力、数据和业务需求灵活选用全参数或PEFT等方法
8.3 持续反馈与迭代
-
微调不是一次性工程,需结合产品功能和数据平台,持续优化模型表现
8.4 防止过拟合与灾难性遗忘
-
采用冻结部分参数、正则化、数据增强等手段
九、🌐模型微调的工程化落地与生态建设

9.1 工程化落地的关键环节
9.1.1 端到端自动化流程
-
现代AI工程团队越来越重视端到端的自动化微调流程。通过集成数据采集、清洗、标注、增强、训练、评估、部署、监控等环节,极大提升了微调效率和可复用性。
-
典型实践如Hugging Face AutoTrain、百度智能云AutoML平台,均支持一键式微调和自动超参数调优。
9.1.2 持续集成与持续部署(CI/CD)
-
微调模型的持续集成与持续部署已成为AI工程的标配。通过自动化测试、A/B实验、灰度发布等手段,保障模型上线的稳定性和安全性。
-
结合Kubernetes、Docker等容器化技术,实现模型的弹性扩展和高可用部署。
9.1.3 版本管理与可追溯性
-
微调模型的版本管理和数据溯源是合规性和可维护性的基础。通过MLflow、DVC等工具,团队可以追踪每一次微调的参数、数据、代码和评估结果,便于回溯和复现。
9.2 微调生态的开放与协作
9.2.1 开源社区的推动作用
-
Hugging Face、OpenMMLab、PaddleNLP等开源社区为微调技术的普及和创新提供了丰富的工具链和预训练模型库。
-
社区驱动的模型评测榜单(如Open LLM Leaderboard)促进了模型性能的透明对比和持续优化。
9.2.2 企业级平台的集成创新
-
各大云厂商(如阿里云、腾讯云、百度智能云、华为云)纷纷推出企业级大模型微调平台,集成数据管理、模型训练、评估、部署、监控等全流程能力,降低了企业AI落地门槛。
-
这些平台通常支持多种微调范式(全参数、PEFT、MoE等),并提供丰富的API和SDK,便于业务系统集成。
9.2.3 行业联盟与标准化
-
随着AI应用的深入,行业联盟和标准化组织(如IEEE、ISO、欧盟AI法案等)正推动微调流程、数据治理、模型评估等环节的标准化,提升行业整体的安全性和可控性。
9.3 微调与大模型生态的协同演进
9.3.1 预训练-微调-推理一体化
-
未来大模型生态将更加注重预训练、微调、推理的无缝衔接。企业可根据业务需求灵活选择自有数据微调、云端API微调或混合部署,提升模型的适应性和响应速度。
9.3.2 多模态与跨模态微调
-
随着多模态大模型(如CLIP、BLIP、商汤书生等)的兴起,文本、图像、音视频等多模态数据的联合微调成为新趋势。跨模态微调不仅提升了模型的泛化能力,也为智能搜索、内容生成、自动驾驶等场景带来突破。
9.3.3 微调与强化学习的融合
-
微调与强化学习(如RLHF,基于人类反馈的强化学习)结合,能够进一步提升模型的交互能力和用户满意度。通过收集用户偏好数据,模型可持续自我优化,形成正向反馈闭环。
十、🧩模型微调的挑战与应对策略
10.1 数据隐私与合规风险
10.1.1 挑战
-
微调过程中涉及大量敏感数据,尤其在医疗、金融、政务等领域,数据隐私和合规风险突出。
-
欧盟AI法案、GDPR等法规对数据溯源、可解释性、伦理审查提出了更高要求。
10.1.2 应对策略
-
加强数据脱敏、加密和访问控制,采用联邦学习、差分隐私等技术保护数据安全。
-
建立完善的数据治理体系,确保数据全生命周期的合规可控。
10.2 灾难性遗忘与过拟合
10.2.1 挑战
-
微调过程中,模型可能遗忘原有知识(灾难性遗忘),或对新数据过拟合,导致泛化能力下降。
10.2.2 应对策略
-
采用冻结部分参数、正则化、数据增强、混合训练等手段,平衡新旧知识的融合。
-
引入知识蒸馏、弹性权重整合等前沿技术,提升模型的稳定性和泛化能力。
10.3 算力与成本压力
10.3.1 挑战
-
大模型微调对算力和存储资源要求高,尤其在全参数微调和多模态微调场景下,成本压力显著。
10.3.2 应对策略
-
优先采用PEFT(如LoRA、QLoRA、Adapter等)等参数高效微调技术,显著降低算力和显存需求。
-
利用云端弹性算力、分布式训练、模型量化等手段,优化资源利用和成本结构。
10.4 模型安全与鲁棒性
10.4.1 挑战
-
微调后的模型可能引入新的安全隐患,如对抗攻击、数据投毒、输出不可控等问题。
10.4.2 应对策略
-
加强模型安全测试和红队评估,定期开展对抗样本测试和异常检测。
-
引入模型解释性工具,提升模型决策过程的透明度和可控性。
十一、🔮未来展望:模型微调的创新方向

11.1 自动化与智能化微调
-
未来微调流程将更加自动化和智能化。AutoML、AutoTrain等工具将自动完成数据预处理、模型选择、超参数调优、评估与部署,大幅降低AI开发门槛。
-
智能化微调将结合元学习(Meta-Learning)、迁移学习等前沿技术,实现模型对新任务的快速适应和自我进化。
11.2 多模态与跨模态微调
-
多模态微调将成为主流,推动AI从单一文本、图像处理向多模态理解与生成迈进。跨模态微调将赋能智能搜索、内容生成、自动驾驶、医疗影像等新兴场景。
11.3 联邦学习与隐私保护微调
-
联邦学习、差分隐私等技术将与微调深度融合,实现数据不出本地、模型共享进步,兼顾数据安全与模型性能。
11.4 绿色AI与低碳微调
-
随着AI算力消耗的持续增长,绿色AI和低碳微调将成为行业新趋势。通过模型剪枝、量化、蒸馏等技术,降低能耗和碳排放,实现可持续发展。
11.5 合规性与伦理治理
-
AI合规性和伦理治理将贯穿微调全流程。行业标准、伦理审查、数据溯源、模型可解释性等要求将持续提升,推动AI健康有序发展。
十二、📚模型微调的知识地图与学习路径
12.1 知识地图
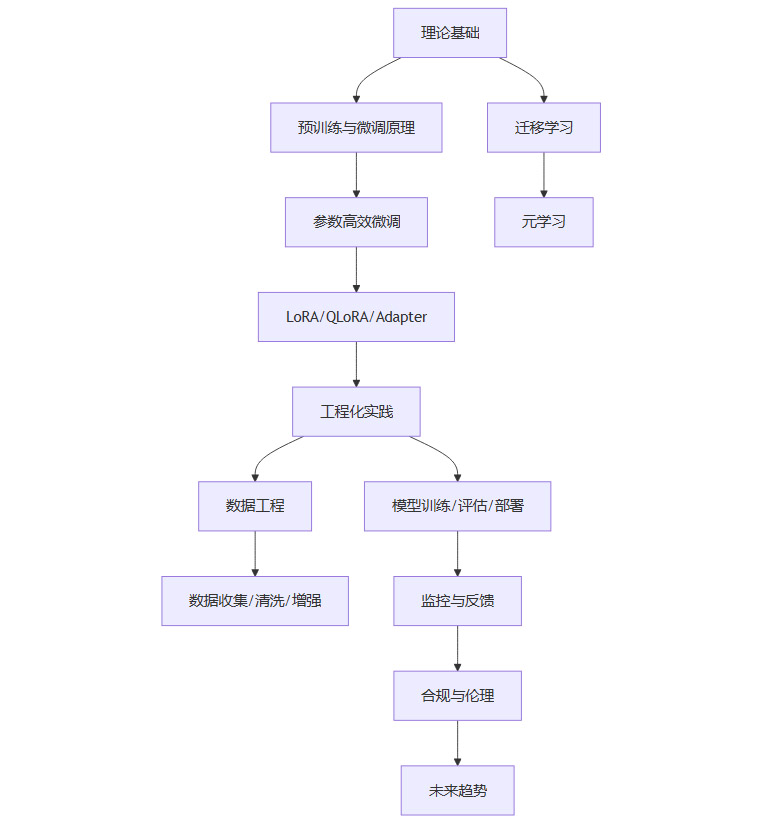
12.2 学习路径建议
-
理解预训练与微调的基本原理
-
掌握主流微调方法(全参数、PEFT、MoE等)
-
学习数据工程与数据治理的最佳实践
-
熟悉模型评估与监控体系
-
跟进行业前沿案例与技术趋势
-
关注AI合规性与伦理治理
十三、🌈模型微调的行业影响与社会价值

13.1 行业智能升级
-
微调技术推动医疗、金融、制造、政务、教育等行业实现智能升级,提升生产效率和服务质量。
-
行业大模型定制化能力增强,助力企业打造专属AI助手和智能决策系统。
13.2 促进AI普惠与创新
-
微调技术降低了AI应用门槛,让中小企业和开发者也能享受大模型红利,推动AI普惠化。
-
开源社区和企业平台的协同创新,激发了AI生态的活力和创新力。
13.3 推动AI合规与可持续发展
-
微调流程中的数据治理、合规性和伦理治理,推动AI行业健康有序发展,提升社会信任度。
-
绿色AI和低碳微调助力AI产业可持续发展,响应全球碳中和目标。
结语
模型微调作为AI工程化落地的核心技术,正以前所未有的速度推动着各行各业的智能升级。无论是理论创新、工程实践,还是数据治理、合规监管,微调技术都在不断突破自我,拓展AI的应用边界。未来,随着自动化微调、多模态融合、绿色AI、合规治理等新趋势的到来,模型微调必将成为AI产业升级和社会智能化转型的重要引擎。每一位AI从业者都应紧跟技术前沿,深耕数据工程,坚守合规底线,携手共创智能未来。
📢💻 【省心锐评】
“微调不是炼金术,没有高质量数据兜底,再 fancy 的技术都是空中楼阁。记住:垃圾数据进,垃圾模型出。”

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 28
28 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)