
结合遗传算法与BP神经网络的股指技术指标分析及适应度函数优化【附数据】
📊 金融数据分析与建模专家 金融科研助手 | 论文指导 | 模型构建✨ 专业领域:金融数据处理与分析量化交易策略研究金融风险建模投资组合优化金融预测模型开发深度学习在金融中的应用💡 擅长工具:Python/R/MATLAB量化分析机器学习模型构建金融时间序列分析蒙特卡洛模拟风险度量模型金融论文指导📚 内容:金融数据挖掘与处理量化策略开发与回测投资组合构建与优化金融风险评估模型期刊论文✅✅ 感
📊 金融数据分析与建模专家 金融科研助手 | 论文指导 | 模型构建
✨ 专业领域:
金融数据处理与分析
量化交易策略研究
金融风险建模
投资组合优化
金融预测模型开发
深度学习在金融中的应用
💡 擅长工具:
Python/R/MATLAB量化分析
机器学习模型构建
金融时间序列分析
蒙特卡洛模拟
风险度量模型
金融论文指导
📚 内容:
金融数据挖掘与处理
量化策略开发与回测
投资组合构建与优化
金融风险评估模型
期刊论文
✅ 具体问题可以私信或查看文章底部二维码
✅ 感恩科研路上每一位志同道合的伙伴!
(1)金融数据分析中神经网络与变量选择问题
在金融领域,股市是一个极其复杂的系统,对股市的研究一直是经济领域的热点课题。股市受到众多因素的影响,包括宏观经济数据、公司财务状况、行业动态、政策变化以及市场情绪等,这些因素相互交织,使得股市的价格走势呈现出高度的复杂性和不确定性。
神经网络在处理这类复杂系统的数据分析时具有独特的优势,其良好的非线性系统拟合能力能够捕捉到金融数据中隐藏的复杂关系。然而,当运用神经网络模型来分析和预测股票时,却面临一个关键问题,即难以确定合适的变量选择准则。在构建神经网络模型时,输入层变量的选择至关重要,因为不同的变量组合可能会导致截然不同的预测结果。如果选择了过多无关或冗余的变量,不仅会增加模型的复杂度,还可能导致过拟合现象,降低模型的泛化能力;而如果遗漏了关键变量,则模型可能无法准确地捕捉到股市价格的变化规律。
例如,在预测某只股票价格时,可能有大量潜在的变量可供选择,如公司的市盈率、市净率、营收增长率、利润率、宏观经济指标中的 GDP 增长率、通货膨胀率、货币政策相关指标(如利率、货币供应量)等。如何从这些众多的变量中挑选出最有价值的变量作为神经网络的输入,是提高预测准确性的关键步骤。但传统的神经网络方法在这方面缺乏有效的指导,往往需要凭借经验或者反复试验来确定变量,这不仅效率低下,而且很难保证选择的科学性和合理性。
(2)遗传算法在变量选择中的应用与现有适用度函数的不足
遗传算法为解决神经网络输入层变量选取问题提供了一种有效的途径。它基于达尔文的 “适者生存” 理论,通过一个合适的适用度函数的 “指导”,在变量的搜索空间中进行全局搜索。在每一代中,算法会根据适用度函数评估每个个体(这里的个体可以看作是一种特定的变量组合)的优劣,优质的个体(即具有更好适应环境能力的变量组合)有更大的概率遗传到下一代。这样经过多代的进化,最终得到的个体往往是在给定环境(这里是预测股票价格的任务)下表现较好的变量组合。
然而,现有的适用度函数存在一定的局限性。目前大多数适用度函数只单纯地考虑预测误差这一个因素,认为预测误差越小,个体的适用度就越高。这种评价标准在一定程度上是合理的,但在实际应用中会出现问题。当多个个体的预测误差相同或相近时,仅仅依据预测误差无法进一步区分这些个体的优劣。实际上,在这种情况下,我们更倾向于选择那些变量个数少的个体。因为变量个数少意味着模型更简洁,更不容易出现过拟合,并且在实际应用中数据收集和处理的成本也会更低。例如,如果有两个变量组合都能得到相近的股票价格预测误差,但一个组合使用了 10 个变量,另一个组合只使用了 5 个变量,显然 5 个变量的组合更有优势。但现有的适用度函数无法体现这种对变量个数的考量,不能有效地引导遗传算法朝着更优的变量组合方向搜索,即同时满足预测精度高且变量个数少的方向。
(3)新适用度函数的提出与模型实验对比
为了解决上述问题,本文提出了一种新的适用度函数。这种新的适用度函数突破了传统仅考虑预测误差的局限,同时将变量的个数纳入考量范围。在新的适用度函数的 “指导” 下,遗传算法在搜索过程中会更加注重找到那些既能保证良好预测结果,又具有较少变量个数的优质个体。具体而言,新的适用度函数会对预测误差和变量个数进行综合权衡。例如,它可能会根据预测误差的大小给予一定的分数,同时根据变量个数的多少给予另一种权重的分数,然后将两者结合起来得到个体的最终适用度得分。这样,在遗传算法的进化过程中,那些预测误差小且变量个数少的个体将有更高的概率被选中和遗传下去。
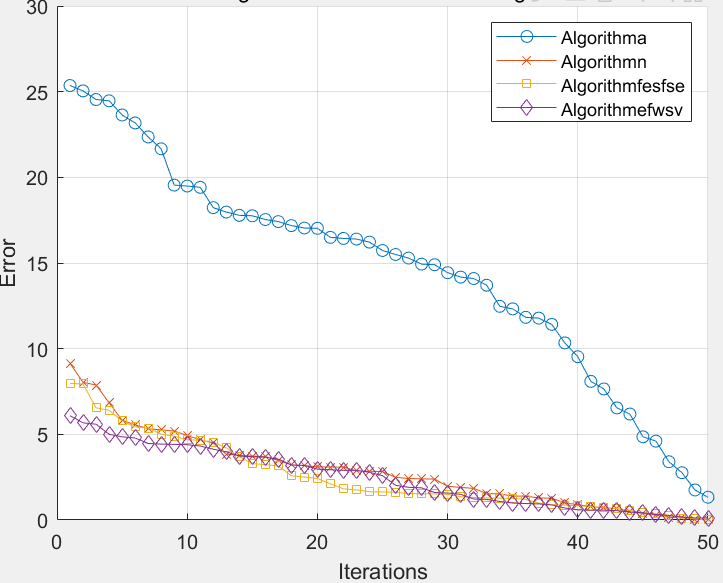
为了验证新方法的有效性,本文选取沪深 300 指数数据进行实验。分别采用单一的人工神经网络模型(BPNN)、主成分分析和神经网络组合模型(PCA - BPNN)、遗传算法和神经网络组合模型(GA - BPNN)和本文改进的遗传算法和神经网络组合模型(IGA - BPNN)进行对比分析。在实验过程中,对于 BPNN 模型,按照传统的方法构建神经网络,输入层变量的选择可能比较随意或者基于一些经验方法。对于 PCA - BPNN 模型,先通过主成分分析对原始变量进行降维处理,然后将得到的主成分作为神经网络的输入,但主成分分析可能会丢失一些原始变量中的信息。对于 GA - BPNN 模型,使用传统的基于仅考虑预测误差的适用度函数的遗传算法来选择神经网络的输入变量。而对于 IGA - BPNN 模型,则使用本文提出的新适用度函数的遗传算法来选择变量。
实验结果表明,本文提出的方法(IGA - BPNN)在保证基本相当的预测精度的同时,能够有效减少变量的个数。这意味着新方法在不牺牲预测准确性的前提下,使模型更加简洁高效。例如,在对比预测沪深 300 指数某一时间段的价格走势时,IGA - BPNN 模型可能只使用了较少的几个关键变量,就能够达到与其他模型相近的预测效果。这不仅降低了模型的复杂度,提高了模型的运行效率,而且在实际应用中更有利于对模型的理解和解释,为金融数据分析中的变量选择和模型构建提供了一种更优的方法。
import numpy as np
import pandas as pd
from sklearn.neural_network import MLPRegressor
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
import random
# 生成随机个体(变量组合)的函数
def generate_individual(num_variables):
individual = [random.choice([0, 1]) for _ in range(num_variables)]
return individual
# 计算预测误差(这里简单示例,使用均方误差)
def calculate_error(y_true, y_pred):
return np.mean((y_true - y_pred) ** 2)
# 传统适用度函数(仅考虑预测误差)
def traditional_fitness(y_true, y_pred):
return 1 / (1 + calculate_error(y_true, y_pred))
# 新的适用度函数(考虑预测误差和变量个数)
def new_fitness(y_true, y_pred, individual):
error = calculate_error(y_true, y_pred)
num_variables = sum(individual)
# 这里对误差和变量个数进行综合权衡,例如可以是如下形式(可调整权重)
return 1 / (1 + error) * (1 / (1 + num_variables))
# 遗传算法中的交叉操作函数
def crossover(parent1, parent2):
crossover_point = random.randint(1, len(parent1) - 1)
child1 = parent1[:crossover_point] + parent2[crossover_point:]
child2 = parent2[:crossover_point] + parent1[crossover_point:]
return child1, child2
# 遗传算法中的变异操作函数
def mutation(individual, mutation_rate):
for i in range(len(individual)):
if random.random() < mutation_rate:
individual[i] = 1 - individual[i]
return individual
# 主程序部分
# 读取沪深 300 指数数据(这里省略数据读取代码,假设已经有数据 DataFrame)
data = pd.read_csv('hs300_data.csv')
X = data.drop('target', axis=1) # 假设最后一列是目标值(指数价格)
y = data['target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 单一神经网络模型(BPNN)
bpnn = MLPRegressor(hidden_layer_sizes=(100, 50), max_iter=500)
bpnn.fit(X_train, y_train)
bpnn_pred = bpnn.predict(X_test)
bpnn_fitness = traditional_fitness(y_test, bpnn_pred)
print("BPNN 模型预测误差:", calculate_error(y_test, bpnn_pred))
# 主成分分析和神经网络组合模型(PCA - BPNN)
pca = PCA(n_components=0.95) # 保留 95%的方差
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
pcabpnn = MLPRegressor(hidden_layer_sizes=(100, 50), max_iter=500)
pcabpnn.fit(X_train_pca, y_train)
pcabpnn_pred = pcabpnn.predict(X_test_pca)
pcabpnn_fitness = traditional_fitness(y_test, pcabpnn_pred)
print("PCA - BPNN 模型预测误差:", calculate_error(y_test, pcabpnn_pred))
# 遗传算法和神经网络组合模型(GA - BPNN)
num_variables = X.shape[1]
population_size = 100
num_generations = 50
mutation_rate = 0.01
ga_population = [generate_individual(num_variables) for _ in range(population_size)]
for generation in range(num_generations):
fitness_scores = []
for individual in ga_population:
selected_X_train = X_train.loc[:, [X_train.columns[i] for i in range(num_variables) if individual[i] == 1]]
selected_X_test = X_test.loc[:, [X_test.columns[i] for i in range(num_variables) if individual[i] == 1]]
ga_bpnn = MLPRegressor(hidden_layer_sizes=(100, 50), max_iter=500)
ga_bpnn.fit(selected_X_train, y_train)
ga_pred = ga_bpnn.predict(selected_X_test)
fitness_scores.append(traditional_fitness(y_test, ga_pred))
new_population = []
for _ in range(population_size // 2):
parent1 = ga_population[np.argmax(fitness_scores)]
fitness_scores[np.argmax(fitness_scores)] = -1
parent2 = ga_population[np.argmax(fitness_scores)]
fitness_scores[np.argmax(fitness_scores)] = -1
child1, child2 = crossover(parent1, parent2)
child1 = mutation(child1, mutation_rate)
child2 = mutation(child2, mutation_rate)
new_population.extend([child1, child2])
ga_population = new_population
# 选择最后一代中最优个体进行最终预测
best_individual_ga = ga_population[np.argmax(fitness_scores)]
selected_X_train_ga = X_train.loc[:, [X_train.columns[i] for i in range(num_variables) if best_individual_ga[i] == 1]]
selected_X_test_ga = X_test.loc[:, [X_test.columns[i] for i in range(num_variables) if best_individual_ga[i] == 1]]
ga_bpnn_final = MLPRegressor(hidden_layer_sizes=(100, 50), max_iter=500)
ga_bpnn_final.fit(selected_X_train_ga, y_train)
ga_bpnn_pred_final = ga_bpnn_final.predict(selected_X_test_ga)
ga_bpnn_fitness_final = traditional_fitness(y_test, ga_bpnn_pred_final)
print("GA - BPNN 模型预测误差:", calculate_error(y_test, ga_bpnn_pred_final))
# 改进的遗传算法和神经网络组合模型(IGA - BPNN)
iga_population = [generate_individual(num_variables) for _ in range(population_size)]
for generation in range(num_generations):
fitness_scores = []
for individual in iga_population:
selected_X_train = X_train.loc[:, [X_train.columns[i] for i in range(num_variables) if individual[i] == 1]]
selected_X_test = X_test.loc[:, [X_test.columns[i] for i in range(num_variables) if individual[i] == 1]]
iga_bpnn = MLPRegressor(hidden_layer_sizes=(100, 50), max_iter=500)
iga_bpnn.fit(selected_X_train, y_train)
iga_pred = iga_bpnn.predict(selected_X_test)
fitness_scores.append(new_fitness(y_test, iga_pred, individual))
new_population = []
for _ in range(population_size // 2):
parent1 = iga_population[np.argmax(fitness_scores)]
fitness_scores[np.argmax(fitness_scores)] = -1
parent2 = iga_population[np.argmax(fitness_scores)]
fitness_scores[np.argmax(fitness_scores)] = -1
child1, child2 = crossover(parent1, parent2)
child1 = mutation(child1, mutation_rate)
child2 = mutation(child2, mutation_rate)
new_population.extend([child1, child2])
iga_population = new_population
# 选择最后一代中最优个体进行最终预测
best_individual_iga = iga_population[np.argmax(fitness_scores)]
selected_X_train_iga = X_train.loc[:, [X_train.columns[i] for i in range(num_variables) if best_individual_iga[i] == 1]]
selected_X_test_iga = X_test.loc[:, [X_test.columns[i] for i in range(num_variables) if best_individual_iga[i] == 1]]
iga_bpnn_final = MLPRegressor(hidden_layer_sizes=(100, 50), max_iter=500)
iga_bpnn_final.fit(selected_X_train_iga, y_train)
iga_bpnn_pred_final = iga_bpnn_final.predict(selected_X_test_iga)
iga_bpnn_fitness_final = new_fitness(y_test, iga_bpnn_pred_final, best_individual_iga)
print("IGA - BPNN 模型预测误差:", calculate_error(y_test, iga_bpnn_pred_final))
print("IGA - BPNN 模型使用的变量个数:", sum(best_individual_iga))

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)