
【LangChain系列文章】3. LLMs
使用LangChain的LLM模块,及大语言模型的temperature参数说明
LangChain No.3
目录
现在我们就可以开始构建基于语言模型的应用了。LangChain提供了很多个模块用于构建语言模型应用程序,这些模块在简单的应用中可以独立使用,也可以组合起来构建更复杂的应用。
LLM
LLM(large language model)是LangChain最基础的构建模块,它的作用是:接收文本,并且生成更多的文本,如通过语言模型来获取一些预测等。举个例子,假设我们需要构建了一个应用:该应用程序根据描述来生成公司名称。
为了实现这个功能,首先需要初始化一个OpenAI模型包装器:
import { OpenAI } from "langchain/llms/openai";
const llm = new OpenAI({
temperature: 0.9,
});
说明:在上述示例中,我们希望输出更加随机,所以在初始化模型时使用了更高的temperature(temperature:基于温度的采样系数,下文中对该参数做具体说明)
通过OpenAI,创建好语言模型后,通过模型的.predict方法接收描述语句,并得到预测结果:
const result = await llm.predict("What would be a good company name for a company that makes colorful socks?");
// "SplashSox"
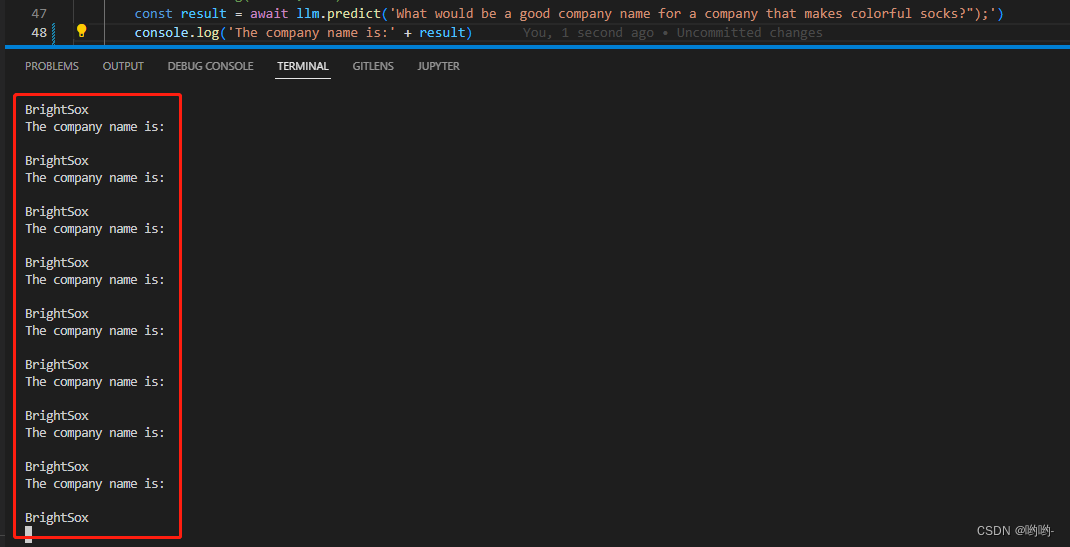
运行上述方法,即可得到一个文本的预测结果。但由于设置了较大的temperature参数,所以每次运行的结果都会不一样。大家可以尝试将temperature参数改小一点,如0.1,我运行了多次都是相同的结果,如下图:
下面对采样温度temperature参数进行说明。
采样温度 Sampling Temperature
它是一种用在类别不均衡数据集上的常用训练策略,一个用来控制采样过程随机性的参数。openai中的默认只为0.7
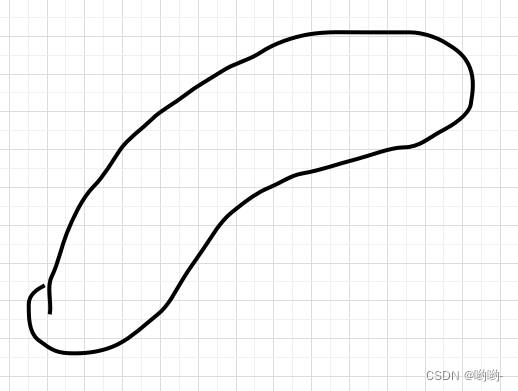
- 假设我们有一份分布如下图形状的二维真实数据
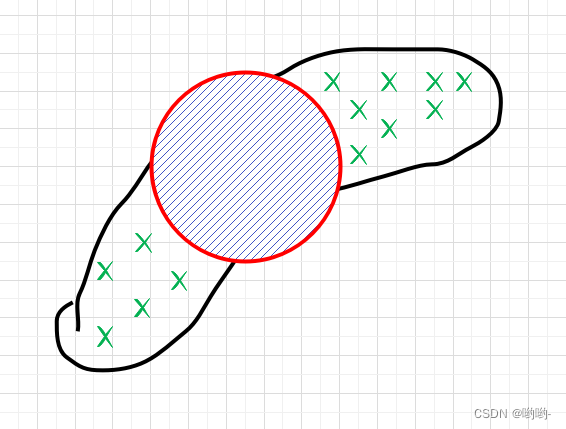
2. 当我们通过一个二维各向同性高斯分布来拟合该数据时,我们就可以采用高斯分布来采样数据,但问题是,通过高斯分布所采样的数据相似性非常大。如下图所示,我们大概率只能采样到图中红色圈内的样本,而蓝色 所表示的区域很大概率采样不到。所以,在
所表示的区域很大概率采样不到。所以,在训练算法中,加入了采样温度参数,用来扩大采样范围、提高采样的随机性。
通过设置不通的采样温度值,得到不通的采样质量和结果。
OpenAI、ChatGPT中均具有采用温度的参数。
The higher the sampling temperature, the more random the sampling process is. The lower the sampling temperature, the less randomness we put in the sampling process.
采样温度越高,采样过程的随机性越高。温度越低,采样过程的随机性越小
您也可以说,提高采样温度同时也提高了模型的不确定性。但这并不是说采样温度高了不好,恰恰相反,但这种不确定性在一些场景中具有非常大的用处,它非常适用于从同一分布中采样不同的样本。
-
用途
使用不同采样温度从同一分布中采样以获得不同的样本,在一些场合中非常有用。如:
- 语音合成:一个语句可能会有多种不同的发音方式
- 图像生成:可能不止一种方式来生成一张如猫或狗的图片
-
分类和使用
采样温度在不同数据分布(离散和连续)的使用:
- 离散数据:如
OpenAI、ChatGPT模型 - 连续数据:
flow-based模型或概率机器学习模型等
- 离散数据:如
-
离散数据sampling temperature
这一类的模型被用来训练去预测序列中的下一个词语,所以,在最终 sigmoid 层之前模型输出的一个对词汇中每个词语的权重向量,我们使用softmax函数转换为概率分布矩阵。
softmax 函数接收一个实数的向量,并将其转换为一个总和为1且每个值都大于等于0的概率向量。它的定义为:
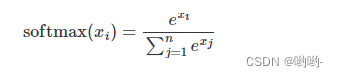
式中,xi 是输入的向量,n 是词语数。当加入温度参数后,它可以通过简单地将输入向量乘以和除以 e1/t 来完成温度参数,softmax 公式就变为: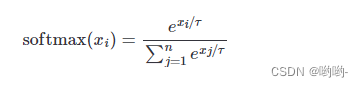
在前面的讨论中我们已经知道了结论:温度参数可以控制采样过程的随机性,采样温度越高,采样过程的随机性就越高,采样温度越低,采样过程的准确性越高。那怎么样可视化来直观的解释呢?有作者进行了实验过程,下述截图全部来自 [这里1](https://shivammehta25.github.io/posts/temperature-in-language-models-open-ai-whisper-probabilistic-machine-learning/)
假设我们有一个概率分布数据长这样: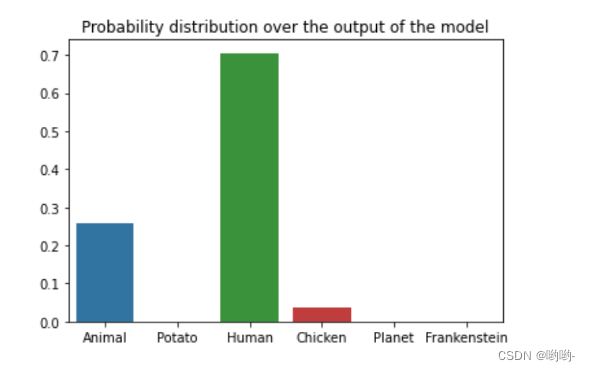
通过不断的改变采样温度,得到的结果长这样: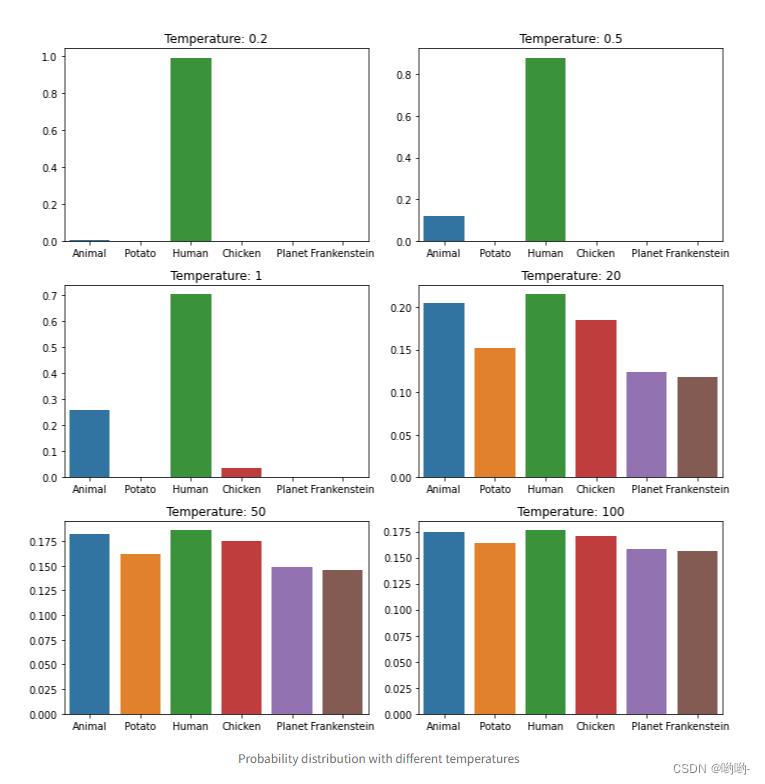
可以看到,随着采样温度的增大,我们可以将非常偏斜的分布转变为更均匀的分布(从而增加熵并增加更多随机性),以便模型也可以对其他一些词语进行采样。这也就是有时候我们在使用模型时,会得到一些非常奇怪的结果的原因,当采样温度太高时,模型不确定下一个词语的采样来自哪里,从而会取到其它的词语。我们也可以认为,提高了采样温度,会提高模型的不确定性。
-
连续数据sampling temperature
连续数据的实验同样来自1,通过绘制不同采样温度下高斯分布的概率密度函数来可视化采样温度对采样过程的影响,如下图所示: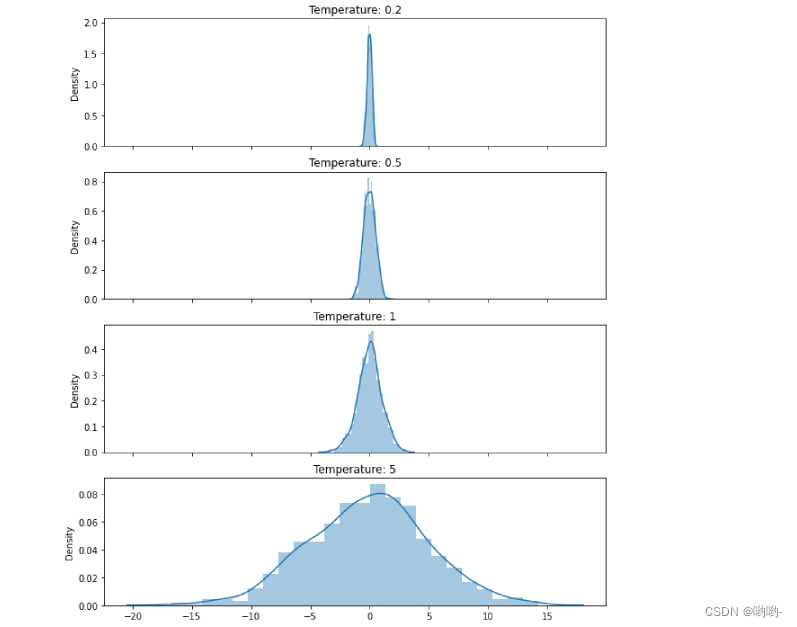
提高采样温度会增加模型的不确定性,但是,这对于从同一分布中采样不同的样本却很有用,可以被应用在多种场景中使用。 -
总结
temperature参数在OpenAI、ChatGPT模型中都有使用,在一些复杂场景中,通过灵活的参数设置可以得到不同的结果。对于使用大语言模型LLM,如果想要得到更加随机的结果,可以将temperature参数设置的大一点,如果想要结果的随机性较低,则可以使用较小的参数设置。
参考文献

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)