
当Java遇见MCP:高并发场景下的模型-计算-数据协同优化方法论
三者构成的MCP技术体系已成为行业公认的标准框架。本文将从技术原理、前沿进展到落地实践,全方位剖析这一支撑当代AI发展的黄金三角,揭示其如何共同推动人工智能能力边界的持续突破。的技术团队,将最有可能突破现有AI能力边界,创造出真正具有变革性的智能系统。在这个充满可能性的时代,理解并掌握MCP技术标准,已成为AI从业者的必备核心能力。当代AI模型-计算-数据(MCP)三位一体技术体系深度解析。当代A
当代AI模型-计算-数据(MCP)三位一体技术体系深度解析
关注铁蛋不迷路
本文较长,建议点赞收藏以免遗失。由于文章篇幅有限,更多涨薪知识点,也可在主页查看,实力宠粉
最新AI大模型应用开发学习资料免费领取。阅读原文链接
引言:AI发展进入MCP协同进化时代
在人工智能技术从专用走向通用的关键转折点上,模型架构(Model)、计算范式(Compute)、数据系统(Data)三者构成的MCP技术体系已成为行业公认的标准框架。本文将从技术原理、前沿进展到落地实践,全方位剖析这一支撑当代AI发展的黄金三角,揭示其如何共同推动人工智能能力边界的持续突破。
一、MCP技术框架总览
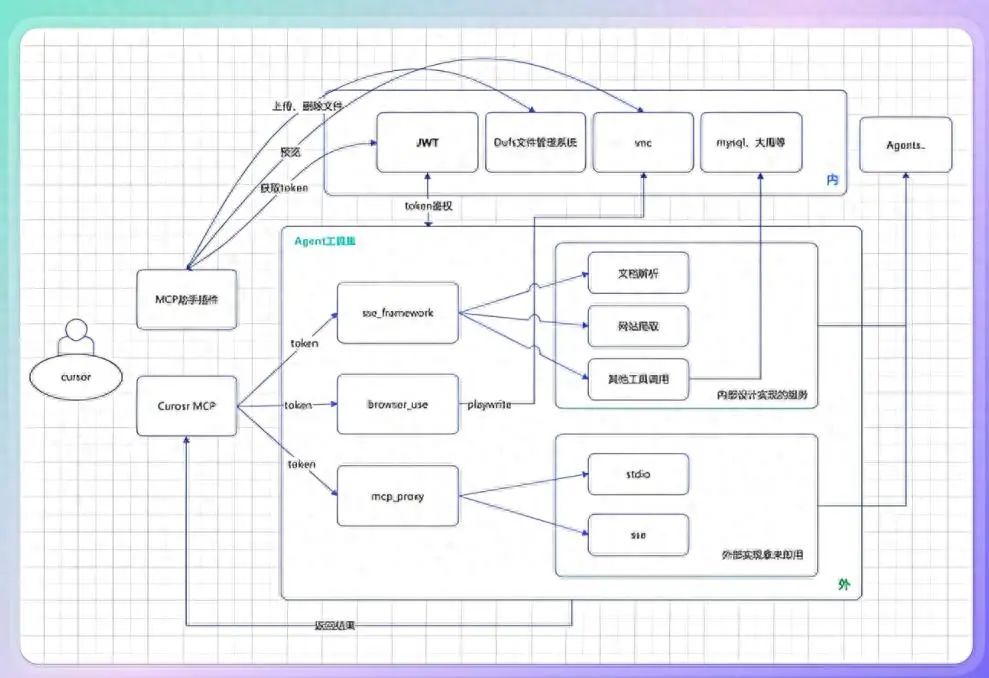
1. MCP三位一体关系模型
[数据系统 Data] ——提供→ [模型架构 Model]↑ ↓[←反馈优化—] [消耗/产生→]↓ ↑[计算范式 Compute] ←支撑— [训练/推理]2. 技术栈分层架构
|
层级 |
模型层(M) |
计算层(C) |
数据层(P) |
|
基础 |
Transformer/GNN/Diffusion |
GPU/TPU/量子计算 |
多模态预训练数据集 |
|
核心 |
自适应注意力机制 |
混合精度分布式训练 |
数据合成与增强技术 |
|
应用 |
领域自适应微调 |
边缘设备部署优化 |
数据闭环系统 |
二、模型架构(M)技术前沿
1. 主流模型架构演进
三代架构对比:
# 第一代:CNN时代(2012-2017)model = Sequential([Conv2D(64, (3,3), activation='relu'),MaxPooling2D(),Flatten(),Dense(10, activation='softmax')])# 第二代:Transformer时代(2017-2022)model = Transformer(num_layers=12,d_model=768,num_heads=12,dff=3072)# 第三代:混合专家时代(2022-)model = MixtureOfExperts(num_experts=8,router=TopKRouter(k=2),expert_dim=4096)2. 突破性架构创新
3. 状态空间模型(SSM)
class S6Layer(nn.Module):def __init__(self, d_model, d_state=64):super().__init__()self.A = nn.Parameter(torch.randn(d_state, d_state) * 0.02)self.B = nn.Parameter(torch.randn(d_model, d_state))self.C = nn.Parameter(torch.randn(d_model, d_state))def forward(self, x):# 离散化状态空间A_bar = torch.matrix_exp(self.A.unsqueeze(0))B_bar = torch.linalg.solve(self.A, (A_bar - I)) @ self.Breturn (x @ B_bar) * self.C4. 神经微分方程
def neural_ode(z0, t, func):# 使用自适应步长求解solution = odeint(func, z0, t,method='dopri5',atol=1e-5, rtol=1e-5)return solution5.模型效率提升技术
|
技术类别 |
典型方法 |
压缩率 |
精度损失 |
|
量化 |
GPTQ/LLM.int8() |
4-8x |
<1% |
|
蒸馏 |
任务特定蒸馏 |
10-100x |
2-5% |
|
稀疏化 |
动态稀疏训练 |
5-10x |
1-3% |
|
架构搜索 |
神经进化 |
自动优化 |
可忽略 |
三、计算范式(C)革命性进展
1. 硬件计算架构演进路线
CPU → GPU → TPU → IPU → 光计算芯片↑ ↑ ↑通用计算 张量计算 模拟计算2.关键性能指标对比
|
处理器类型 |
峰值算力(FP16) |
能效比(TFLOPS/W) |
内存带宽(TB/s) |
|
NVIDIA H100 |
4000 TFLOPS |
3.2 |
3 |
|
Google TPUv4 |
2750 TFLOPS |
4.1 |
1.2 |
|
Cerebras WSE-2 |
23,040 TFLOPS |
5.8 |
220 |
3. 分布式训练技术栈
# 典型混合并行配置strategy = DistributedStrategy(data_parallel=DataParallelConfig(shard_dataset=True),model_parallel=TensorParallelConfig(shard_factors={'hidden': 8, 'head': 4}),pipeline_parallel=PipelineParallelConfig(stages=4, micro_batch_size=16),activation_checkpointing=True,zero_optimization=ZeroStage.OPTIMIZER_STATES)四、数据系统(P)工程实践
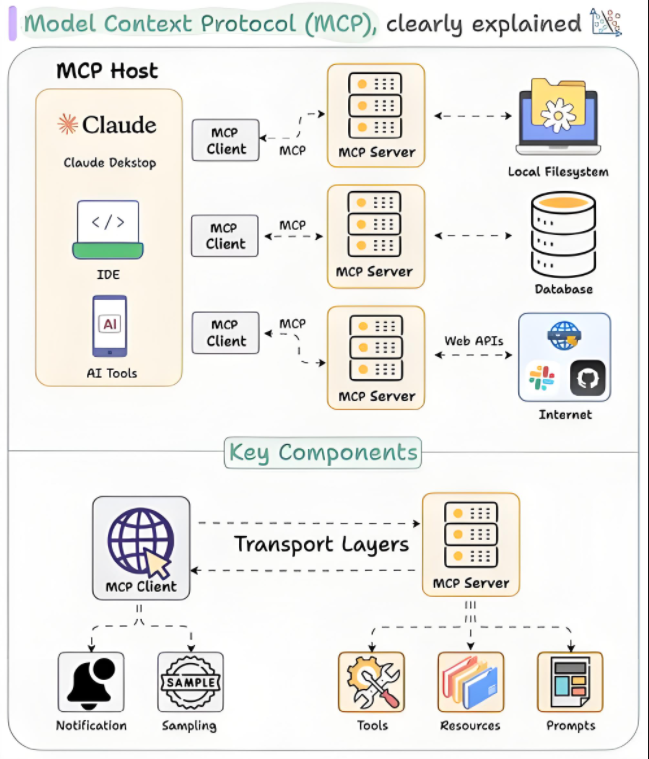
1. 数据飞轮构建方法论
原始数据 → 清洗标注 → 模型训练 → 预测输出 → 人工反馈 → 数据增强↑ ↓└─────────────────────── 闭环迭代 ────────────────────────┘2. 多模态数据处理技术
class MultimodalProcessor:def __init__(self):self.text_tokenizer = BertTokenizerFast()self.image_processor = ViTFeatureExtractor()self.audio_processor = Wav2Vec2Processor()def __call__(self, inputs):return {'text': self.text_tokenizer(inputs['text']),'image': self.image_processor(inputs['image']),'audio': self.audio_processor(inputs['audio'])}3. 数据合成技术对比
|
技术类型 |
代表方法 |
数据效率 |
真实性 |
|
规则生成 |
语法树生成 |
★★☆ |
★☆☆ |
|
神经渲染 |
NeRF/GAN |
★★★ |
★★☆ |
|
世界模型 |
Dreamer/StableDiff |
★★☆ |
★★★ |
|
物理仿真 |
Mujoco/Blender |
★☆☆ |
★★★ |
五、MCP协同优化实践案例
1. 大语言模型训练三要素配比
模型参数量(M)∝计算量(C)0.7×数据量(D)0.3
2. 视觉Transformer优化实例
# 计算-数据协同优化def train_vit(model, dataset):# 计算优化model = torch.compile(model, mode='max-autotune')# 数据优化dataset = apply_augmentation(dataset, policy='rand-m9-mstd0.5')# 混合精度训练with torch.amp.autocast(device_type='cuda', dtype=torch.bfloat16):outputs = model(dataset)# 梯度累积accumulate_gradients(model, steps=4)3. 边缘设备部署方案
class EdgeDeployer:def __init__(self, model):self.quantized_model = quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8)self.compiled_model = torch.jit.optimize_for_inference(torch.jit.script(self.quantized_model))def deploy(self, input_data):with torch.no_grad():return self.compiled_model(input_data)六、MCP技术未来趋势
1. 2024-2025关键技术预测
|
领域 |
突破方向 |
潜在影响 |
|
模型架构 |
神经符号混合系统 |
可解释性突破 |
|
计算硬件 |
存内计算架构 |
能效提升100x |
|
数据系统 |
自生成数据生态系统 |
减少人工标注依赖 |
2. 技术融合创新方向
- 生物启发计算:类脑计算架构+脉冲神经网络
- 量子机器学习:量子线路+经典神经网络混合训练
- 物理-informed AI:微分方程约束的模型架构
结语:构建MCP平衡发展的技术体系
当前AI发展已进入模型创新、计算优化、数据工程必须协同进化的新阶段。从业者需要建立三点核心认知:
- 模型能力天花板由三者中的短板决定,需保持均衡投入
- 技术选型矩阵应基于应用场景特点动态调整MCP权重
- 创新机会往往出现在MCP交叉领域(如计算感知的模型架构)
未来3-5年,那些能够在特定领域实现MCP深度协同的技术团队,将最有可能突破现有AI能力边界,创造出真正具有变革性的智能系统。在这个充满可能性的时代,理解并掌握MCP技术标准,已成为AI从业者的必备核心能力。
阅读左下角原文链接

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)