
python网络爬虫——python基础知识
面向对象的编程方法不会像平时按照执行流程去思考,在这个例子中,就是把Person这个类视为一个对象,它拥有name和age两个属性,在调用过程中,让自己把自己打印出来。上述例子定义了一个Person的类,在这个类中,可以通过各种函数定义Person中的各种行为和特性,要让代码显得更加清晰有效,就要在调用Person类各种行为的时候也可以随时提取。但是在实际情况中,某些函数输入和输出可以不用指明。随
参考资料:python网络爬虫从入门到实践【第2版】
1、函数
在代码很少的时候,我们按照六级写完就能够很好地运行。但是如果代码变得庞大复杂起来,就需要自己定义一些函数(function),把代码切分成一个个方块,使得代码已读,可以重复使用,并且容易调整顺序。
其实python自带有很多函数,例如sum()和abs()函数,我们可以直接调用。
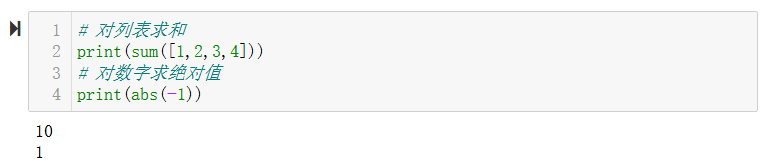
我们也可以自己定义函数。一个函数包括输入参数和输出参数,python的函数功能可以用y=x+1的数学函数来理解,在输入x=2的参数时,y输出3。但是在实际情况中,某些函数输入和输出可以不用指明。如下:

参数必须要正确写入函数中,函数的参数也可以为多个,可以是不同的数据类型,例如可以是两个参数,分别是字符串和列表型,如下:

2、面向对象编程
面向过程编程是根据业务逻辑从上到下写代码,这个容易被初学者接受,按照逻辑需要用到哪段代码写下了 即可。
随着时间的推移,在编程的方式上又发展出了函数式编程,把某些功能封装到函数中,需要时可以直接调用,不用重复撰写。函数式编程方法的好处是节省大量时间。
面向对象编程是把函数进行分类和封装放入对象中,使得开发更快、更强。如下:
# 创建类
class Person:
#__init__()方法称为类的构造方法,注意是左右各两条下划线
def __init__(self,name,age):
self.name=name
self.age=age
# 通过self调用被封装的内容
def detail(self):
print(self.name)
print(self.age)
obj1=Person("santos",18)
obj1.detail() # python将obj1传给self参数,即:
# obj1.detail(obj1),此时内部self=obj1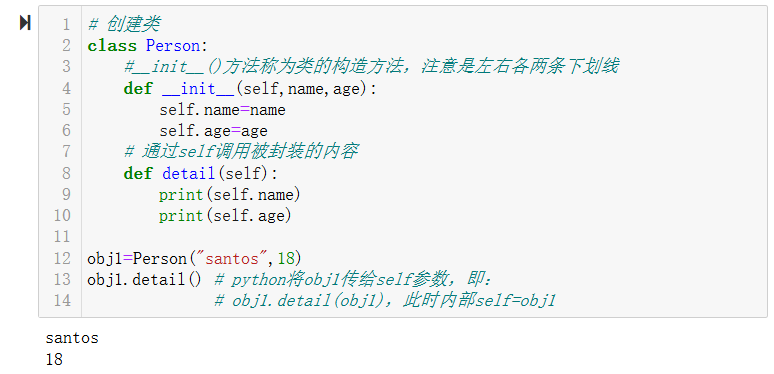
如果使用函数式编程,该如何实现呢,如下:
def detail(name,age):
print(name)
print(age)
obj2=detail("santos",18)
在这里函数式编程比面向对象编程更容易。使用函数式编程,我们只需要写清楚输入和输出变量并执行函数即可;而使用面向对象编程方法,首先要创建封装对象,然后还要通过对象调用被封装的内容。
如何选择函数式编程和面向对象编程呢?如果各个函数之间独立且无共用的数据,就选用函数式编程;如果各个函数之间有一定的关联性,那么选用面向对象编程比较好。下面介绍面型对象的两大特性:封装和继承。
(1)封装
封装,就是把内容封装好,在调用封装好的内容。封装分为两步:
第一步是封装内容;
第二步是调用被封装的内容。
①封装内容
# 创建类
class Person:
def __init__(self,name,age):
self.name=name
self.age=age
obj1=Person("santos",18)
# 将"santos"和18分别封装到obj1即self的name和age属性上面例子中,self只是一个形式参数,当执行obj1=Person('santos',18)时,self等于obj1,此处将santos和18分别封装到obj1及self的name和age属性中。结果是obj1有name和age属性,其中obj1.name="santos",obj1.age=18。
②调用被封装的内容
调用被封装的内容时有两种方式:通过对象直接调用和通过self间接调用。
通过对象直接调用obj1对象的name和age属性,代码如下:
# 创建类
class Person:
def __init__(self,name,age):
self.name=name
self.age=age
obj1=Person("santos",18)
# 直接调用obj1对象的name属性
print(obj1.name)
# 直接调用obj1对象的age属性
print(obj1.age)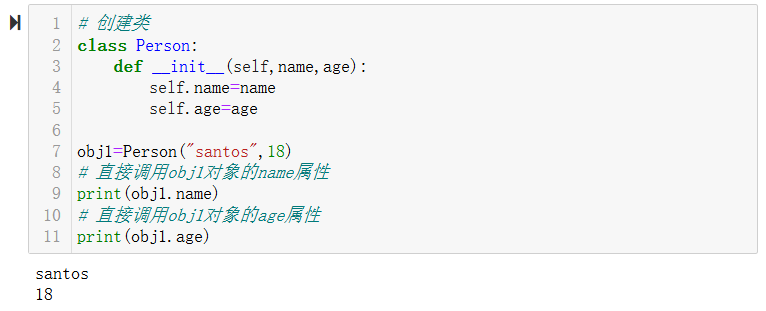
通过self间接调用时,python默认会将obj1传给self参数,即obj1.detail(obj1)。此时方法内部的self=obj1,即self.name="santos",self.age=18。代码如下:
# 创建类
class Person:
def __init__(self,name,age):
self.name=name
self.age=age
def detail(self): # 通过self调用被封装的内容
print(self.name)
print(self.age)
obj1=Person("santos",18)
obj1.detail()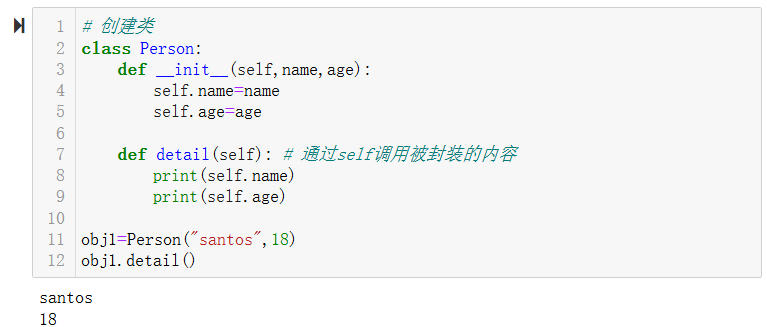
上述例子定义了一个Person的类,在这个类中,可以通过各种函数定义Person中的各种行为和特性,要让代码显得更加清晰有效,就要在调用Person类各种行为的时候也可以随时提取。这比仅使用函数式编程更加方便。
面向对象的编程方法不会像平时按照执行流程去思考,在这个例子中,就是把Person这个类视为一个对象,它拥有name和age两个属性,在调用过程中,让自己把自己打印出来。综上所述,对于面向对象的封装来说,其实就是使用构造方法将内容封装到对象中,然后通过对象直接或self间接获取被封装的内容。
(2)继承
继承是以普通的类为基础建立专门的类对象。面向对象编程的继承和现实中的继承类似,子继承了父的某些特性,例如:
猫可以:喵喵叫、吃、喝、拉、撒
狗可以:汪汪叫、吃、喝、拉、撒
如果我们要分别对猫和狗创建一个类,就需要为猫和狗实现他们所有的功能。代码如下:这里为伪代码,无法在python中运行:
class 猫:
def 喵喵叫(self):
print('喵喵叫')
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
class 狗:
def 汪汪叫(self):
print('汪汪叫')
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something从上述代码不难看出,吃、喝、拉、撒是猫和狗的共同特性,我们没有必要在代码中重复编写。如果用继承的思想,就可以写成:
动物:吃喝拉撒
猫:喵喵叫(猫继承动物的功能)
狗:汪汪叫(狗继承动物的功能)
class Animal:
def eat(self):
print("%s 吃"%self.name)
def drink(self):
print("%s 喝"%self.name)
def shit(self):
print("%s 拉"%self.name)
def pee(self):
print("%s 撒"%self.name)
class Cat(Animal):
def __init__(self,name):
self.name=name
def cry(self):
print("喵喵叫")
class Dog(Animal):
def __init__(self,name):
self.name=name
def cry(self):
print("汪汪叫")
c1=Cat("小白家的小黑猫")
c1.eat()
c1.cry()
d1=Dog("胖子家的小瘦狗")
d1.eat()
d1.cry()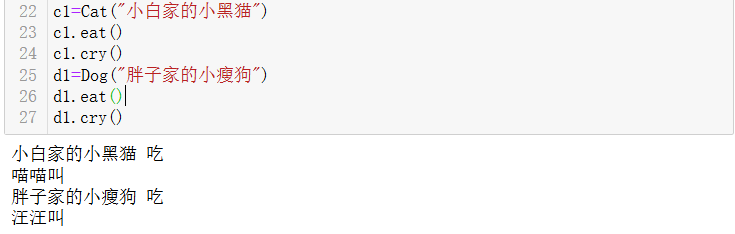
对于继承来说,其实就是将多个类共有的方法提取到父类中,子类继承父类中的方法即可,不必一一实现每个方法。
3、错误处理
在编程过程中,我们不免会遇到写出来的程序运行错误,这些错误一般来说会使整个程序停止运行,但是在python中,我们可以使用try/except语句来捕获异常。
try/except使用try来检测语句块中的错误,如果有错误的话,except则会执行捕获异常信息并处理。如下:
try:
reult=5/0 # 除以0会产生运算错误
except Exception as e: # 出现错误会执行except
print(e) # 把错误打印出来
上述代码首先执行try里面的语句,除以0产生运算错误后,会执行except里的语句,将错误打印出来。在网络爬虫中,它可以帮我们处理一些无法获取到数据报错的情况。
此外,如果我们并不想打印错误,就可以用pass空语句
try:
result=5/0 # 除以0会产生运算错误
except: # 出现错误会执行except语句
pass # 空语句,不做任何事情
GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 15
15 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)