
NLP模型常见报错(定期更新)
的时候,会遇到一些bug。1、BiLSTM模型,跑阿里天池新闻分类比赛。本人是做NLP研究方向,在写代码。记录下来,方便他人和自己。为此,我将把一些遇到的。
·
本人是做NLP研究方向,在写代码跑模型的时候,会遇到一些bug。总有一些bug让我苦不堪言,痛苦不堪,绞尽脑汁。为此,我将把一些遇到的bug记录下来,方便他人和自己。
定期更新哟!!!
1、BiLSTM模型,跑阿里天池新闻分类比赛
训练模型第一轮epoch=1时:
- 准确率accuracy,损失值loss,f1_score得分,还挺正常。
但是,从训练模型第二轮即epoch=2开始:
- 准确率accuracy变得很小且不再大幅度改变
- 损失值loss变得很大且不再大幅度改变
- f1_score得分变得很小且不再大幅度改变
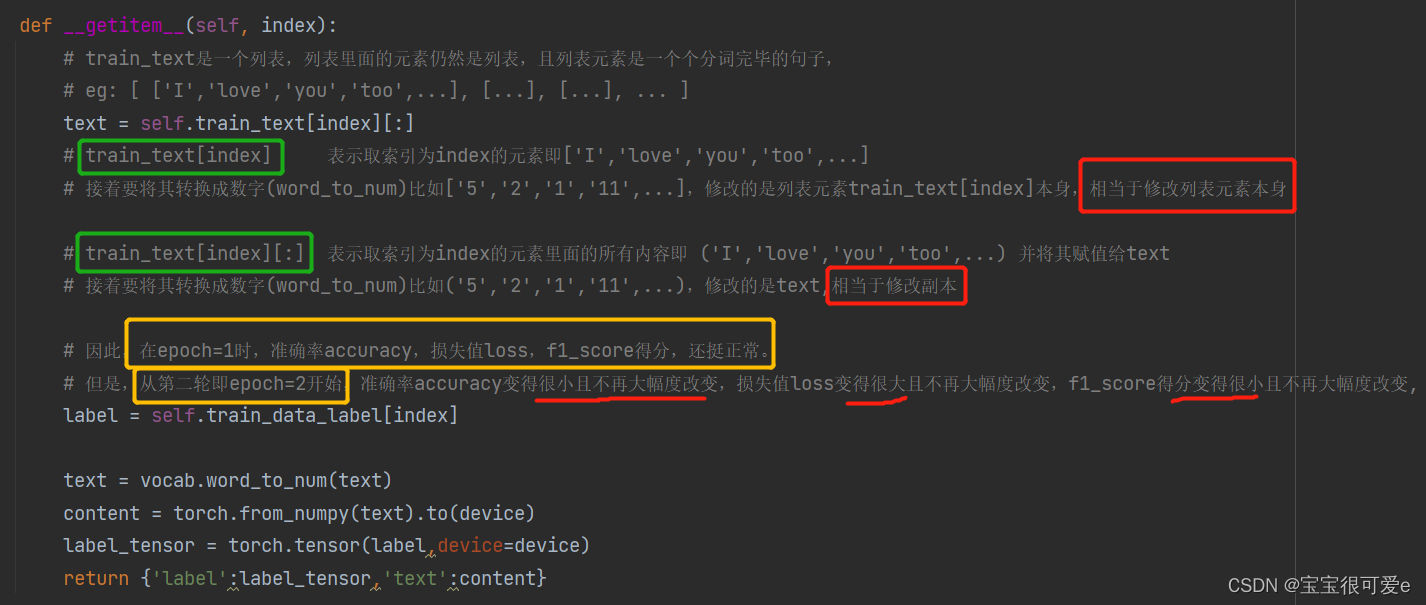
def __getitem__(self, index):
# train_text是一个列表,列表里面的元素仍然是列表,且列表元素是一个个分词完毕的句子,
# eg: [ ['I','love','you','too',...], [...], [...], ... ]
text = self.train_text[index][:]
# train_text[index] 表示取索引为index的元素即['I','love','you','too',...]
# 接着要将其转换成数字(word_to_num)比如['5','2','1','11',...],修改的是列表元素train_text[index]本身,相当于修改列表元素本身
# train_text[index][:] 表示取索引为index的元素里面的所有内容即 ('I','love','you','too',...) 并将其赋值给text
# 接着要将其转换成数字(word_to_num)比如('5','2','1','11',...),修改的是text,相当于修改副本
# 因此,在epoch=1时,准确率accuracy,损失值loss,f1_score得分,还挺正常。
# 但是,从第二轮即epoch=2开始,准确率accuracy变得很小且不再大幅度改变,损失值loss变得很大且不再大幅度改变,f1_score得分变得很小且不再大幅度改变,
label = self.train_data_label[index]

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)