
AI 人工智能,机器学习,深度学习之间关系 【1】
机器学习是人工智能的一个子集,它通过让机器从数据中学习规律和模式,而无需显式编程。深度学习则是机器学习的一个子集,特指那些使用多层神经网络(通常称为深度神经网络)来进行学习的算法。在这种意义上,所有深度学习都是机器学习,但并非所有机器学习都是深度学习。
2025年开始整理2024年学习到的深度学习相关知识形成知识架构,包括 基本概念,数据标注,训练方法【llamafactory】,提示词工程,工程方法,落地方案。如,卷积,卷积核,感受野,反向传播,梯度下降算法,标量,向量[计算,加,减,内积与外积],张量计算,微积分,偏导,也就是复合函数的处理以及处理复合函数的 降维工具[向量,导数就是2个很好的降维工具],概率论与统计,线性代数,矩阵计算方法,信息论交叉熵,CNN,RNN,Transformers,token生成过程,QKV计算过程-T过程,归一化,drop过程,到最后的softmax百分比化,全连接层等等,工程类的embedding,rerank,LLM(qwen系列),VL(qwen2.5-vl系列,InterVL系列)等模型推理服务的部署,支持高并发,多多节点类似k8s,VLLM,lmdeploy,tritonserve,TensorRT-LLM,xinference,sglang等 ,或是二开基于xinference或vllm,tritonserve。RAG系列,ragflow,dify,fastgpt,qanyting,coze,angtingllm,make,zapier,n8n,cpmfyui,flowis,pipdream,roboflow,node-rel,steamship,promptflow,langchian等知识库的选型这里面考虑因素开源还是闭源,开源协议,版权问题,外部工具集成度如mcp,function call第三方工具,AI模版等,不是部署那俩用就可以了。硬件CUDA家族,nvlink,nvlink switch,tersonTR,nccl。cpu相关的,opencv,pytorch,openai api的使用,国产化昇腾系列TPU,cpu arm架构, 模型量化方法,LORA,agent,agent智能体需要LLM作为底层驱动,function call,MCP server/ client, reponse api, coumpter user,workflow等等吧。还有价值的体现就是商业模式,商业场景,给现在的产品赋能,提高产品效能。 就是好多要整理的,就想19年开始接手k8s,17-19 基于namespace和cgroup以及IPC呀net呀 自己做了类似docker的东西后来docker开源了也就直接用了,当时用的aufs,overlayfs后来发现docker也用的overlayfs引擎说明选型没问题哈哈,弄了几年了k8s体系架构不能说是深入骨髓,但也是略知一二的,闭眼能应付平常工作哈哈。2024年决定在加一个技术栈AI这个大家族 ,沉下心来,千万别浮躁,水润万物,默默无闻,水能载舟,亦能覆舟。
接下来从宏观概念开始
机器学习与深度学习虽同属人工智能的范畴,却有着明显的区别。主要包括:1.定义与关系不同;2.数据处理能力不同;3.模型复杂性不同;4.硬件要求不同;5.应用场景不同;6.发展历程不同。机器学习是一个更为广泛的概念,它可以使用简单模型解决问题;而深度学习通常指神经网络中层数较多的模型,能够处理更为复杂的任务。
A 人工智能:Artificial Intelligence [AI]
人工智能就是让机器能够模拟人类的思维能力,让机器能像人一样去感知、思考甚至决策。
时至今日,人工智能已经不再是一门单纯的学科,而是涉及了计算机、心理学、语言学、逻辑学、哲学等多个学科的交叉领域。
面对多种多样的人工智能,我们按照人工智能的实力,可将其分成三类:
a)弱人工智能(Artificial Narrow Intelligence,ANI)
擅长于某个方面的人工智能,只能执行特定的任务。例如,人脸识别系统就只能识别图像,你要是问它明天天气怎么样,它可不知道怎么回答。
b )强人工智能(Artificial General Intelligence,AGI)
类似于人类级别的人工智能,能够在多个领域表现出类似于人的智慧,能理解、学习和执行各种任务。目前,强人工智能尚未实现,仍是人工智能研究的长期目标。
c)超人工智能(Artificial Superintelligence,ASI)
超越人类智慧的人工智能,在各个领域都比人类聪明,可以执行任何智力任务并且在许多方面超越人类。尽管超人工智能在科幻作品中经常出现
B 机器学习——Machine Learning
前面提到,人工智能的目的是让机器能够像人一样思考并决策,到底如何实现呢?
回想一下,我们刚出生时基本上什么都不会,经过了几十年的学习,我们学会了各种知识、技能。
机器也是一样的,要让它会思考,就要让它先学习,从经验中总结规律,进而拥有一定的决策和辨别能力,这就是人工智能的核心——机器学习。
机器学习专门研究计算机怎样模拟或实现人类的学习行为,通过学习获取新的知识、技能,从而重新组织已有的知识结构,不断改善自身性能。
机器学习是一门多领域交叉学科,涉及概率论、统计学,微积分,逼近论、算法复杂度理论等多门学科。
机器是怎样学习的呢?我们先来看一下人的学习过程:
上课:学习理论知识,进行知识输入
总结复习:通过复习,强化理解
梳理知识框架:整理知识,形成体系
课后作业:通过练习,进一步加深理解
每周测验:检查掌握情况
查漏补缺:改善学习方法
期末考试:检查最终学习成果
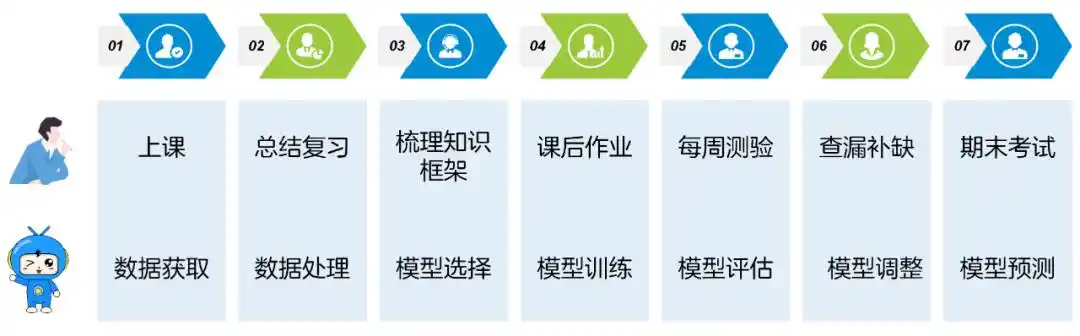
机器的学习过程也是类似的,包括以下7个步骤:
数据获取:收集相关的数据
数据处理:对数据进行转换,统一数据格式
模型选择:选择适合的算法
模型训练:使用数据训练模型,优化算法
模型评估:根据预测结果评估模型性能
模型调整:调整模型参数,优化模型性能
模型预测:对未知结果数据进行预测
简而言之,机器学习就是从数据中通过算法自动归纳逻辑或规则,并根据归纳的结果与新数据来进行预测。
举个例子,如果我们想让计算机看到狗时能判断出是狗,就需要给计算机展示大量狗的图片,同时告诉它这就是狗。
经过大量的训练,计算机会总结出一定的规律,当下次看到狗时,捕捉到对应的特征,得出“这是狗”的结论。
如果算法不够完善,可能会把猫误认为狗,这就需要计算机通过经验数据自动改进算法,从而增强预测能力。
按照学习方式,机器学习可分为以下四类:
a. 监督学习
从有标记的数据中学习,即数据中包含自变量和因变量 y=wx+b [x是自变量,y是因变量 以为x变化而变化所以是因变量],通过学习已知的输入和输出数据来进行预测,如分类任务和回归任务。
分类任务:预测数据所属的类别,如垃圾邮件检测 、识别动植物类别等。
回归任务:根据先前观察到的数据预测数据,如房价预测,身高体重预测等。
b 无监督学习
分析没有标签的数据,即数据中只有自变量没有因变量,发现数据的规律,如聚类、降维等。
聚类:把相似的东西聚在一起,并不关注这类东西是什么,如客户分组。
降维:通过提取特征,将高维数据压缩用低维表示,如将汽车的里程数和使用年限合并为磨损值。
c 半监督学习
训练数据只有部分有标记,先使用无监督学习对数据进行处理,再用监督学习对模型进行训练和预测。
例如手机可以识别同一个人的照片(无监督学习),当把同一个人的照片打上标签后,之后新增的这个人的照片也会自动加上对应的标签(监督学习)。
d 强化学习
通过与环境进行交互,根据奖励或惩罚来优化算法,直到获得最大奖励,产生最优策略。例如扫地机器人撞到障碍物后,会优化清扫路径。
C 深度学习——Deep Learning
通过上面的了解,相信大家对机器学习已经不陌生了。那么深度学习又是个啥?跟机器学习有什么关系?
深度学习是机器学习领域的一个新的研究方向,是一种通过多层神经网络来学习和理解复杂数据的算法。
机器通过学习样本数据的深层表示来学习复杂任务,最终能够像人一样具有分析学习能力,能够识别文字、图像和声音等。

与传统机器学习不同的是,深度学习使用了神经网络结构,神经网络的长度称为模型的“深度”,因此基于神经网络的学习被称为“深度学习”。
神经网络模拟了人类大脑的神经元网络,神经元节点可以对数据进行处理和转换。通过多层神经网络,数据的特征可以被不断地提取和抽象,从而使机器能更好地解决各种问题。
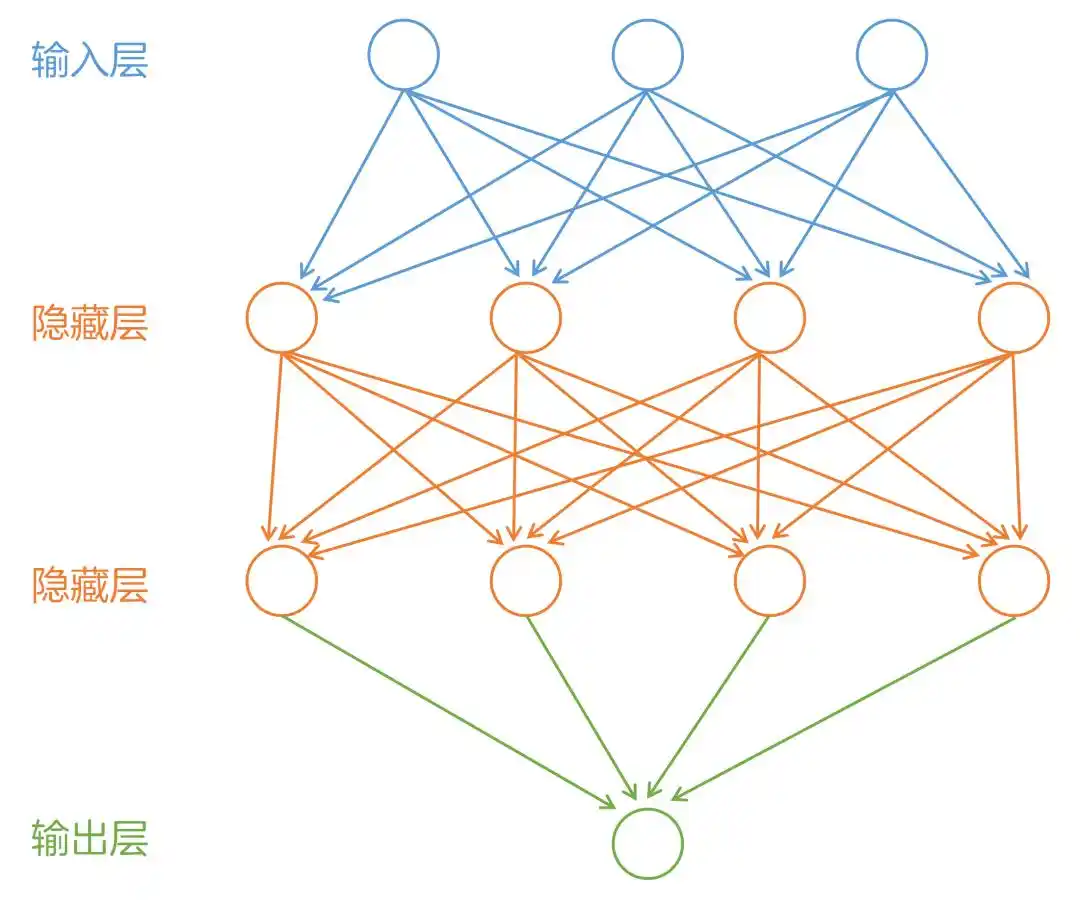
典型的深度学习算法有以下四种类型:
卷积神经网络(Convolutional Neural Network,CNN):常用于图像识别和分类任务。
递归神经网络(Recurrent Neural Network,RNN):适用于处理序列数据,如自然语言处理。
长短期记忆网络(Long Short-Term Memory,LSTM):一种特殊的RNN结构,能够更好地处理长序列数据。
生成对抗网络(Generative Adversarial Network,GAN):用于生成新的数据,如图像、音频或文本。
1.定义与关系不同
机器学习是人工智能的一个子集,它通过让机器从数据中学习规律和模式,而无需显式编程。深度学习则是机器学习的一个子集,特指那些使用多层神经网络(通常称为深度神经网络)来进行学习的算法。在这种意义上,所有深度学习都是机器学习,但并非所有机器学习都是深度学习。
2.数据处理能力不同
机器学习模型通常适用于结构化数据,它们能够处理有限的数据集并从中抽取规律。而深度学习模型,特别擅长处理大规模的非结构化数据,如图像、音频和文本。这得益于深度学习网络内部的高复杂性,使其能够自动提取特征和学习表示。
3.模型复杂性不同
深度学习模型因其多层结构而复杂度较高,层数越多,模型能够学习的特征层次就越深。机器学习模型则通常相对简单,包括决策树、支持向量机等,它们不需要通过多层结构来学习数据的特征。
4.硬件要求不同
由于深度学习模型的复杂性和需要处理的数据量通常较大,它们需要更强大的硬件支持,尤其是高性能的GPU。机器学习模型由于相对较为简单,对硬件的要求不那么苛刻,可以在没有GPU加速的普通计算机上运行。
5.应用场景不同
深度学习尤其适用于视觉和语音识别、自然语言处理等领域,这些领域需要从海量的数据中学习复杂模式。机器学习则广泛应用于数据挖掘、推荐系统、金融分析等场景,这些场景下的数据量和复杂性相对较低。
6.发展历程不同
机器学习的概念和技术从20世纪50年代开始发展,经历了几十年的研究和实践。深度学习则是21世纪以来才兴起的领域,特别是在大数据和强大计算力的驱动下,它迅速成为人工智能领域的热点。
下一章节 Transformers 架构体系和一个案例,包括训练和推理

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)