
DriveMoE: 基于MoE的端到端自动驾驶SOTA VLA模型
上海交通大学提出了自动驾驶模型DriveMoE,通过混合专家架构MoE实现性能突破。该模型包含两大核心模块:1)场景专用视觉MoE,动态选择关键摄像头视角,减少冗余计算;2)技能专用动作MoE,针对不同驾驶行为激活专业化专家模块。
性能暴涨60%!25年5月22日,上交提出DriveMoE:Mixture-of-Experts for Vision-Language-Action Model in End-to-End Autonomous Driving。
摘要
端到端自动驾驶(E2E-AD)需要有效地处理多视角感官数据,并对复杂的不同驾驶场景进行鲁棒处理,特别是不常见的操控,如急转弯。Mixture-of-Experts (MoE) 架构在大型语言模型 (LLM) 中的最近成功表明,参数的专业化能实现强大的可扩展性。在这项工作中,我们提出了一种新的基MoE的E2E-AD框架DriveMoE,该框架具有场景专用视觉MoE和技能专用动作MoE。DriveMoE 建立在我们的 π0 Vision-Language-Action (VLA)基线之上,称为 Drive-π0。具体来说,我们通过训练路由器根据驾驶场景动态选择相关摄像头,将 Vision MoE 添加到 Drive-π0。这种设计反映了人类驾驶认知,驾驶员选择性地关注关键的视觉线索,而不是详尽地处理所有视觉信息。此外,我们通过训练另一个路由选择器来激活针对不同驾驶行为的专业化专家模块,从而添加动作MoE。通过明确的行为专业化,DriveMoE 能够处理不同的场景,而不会像现有模型那样遭受模式平均。在 Bench2Drive 闭环评估实验中,DriveMoE 实现了最先进的性能 (SOTA) 性能,证明了在自动驾驶任务中结合视觉和动作 MoE 的有效性。我们将发布DriveMoE和Drive-π0的代码和模型。
论文链接:https://thinklab-sjtu.github.io/DriveMoE/
1 简介
当代自动驾驶在端到端范式下取得了显著进展,该范式直接将原始传感器输入映射为规划结果。这种范式带来了许多优势,如减少了工程复杂性、减轻了误差传播和全局目标优化。尽管在各种开环自动驾驶基准测试中取得了令人鼓舞的结果,现有的端到端模型在闭环设置中仍未取得令人满意的表现。在闭环设置中,训练好的驾驶模型可以很容易遇到分布外情况,因此需要更强的泛化能力和推理能力。
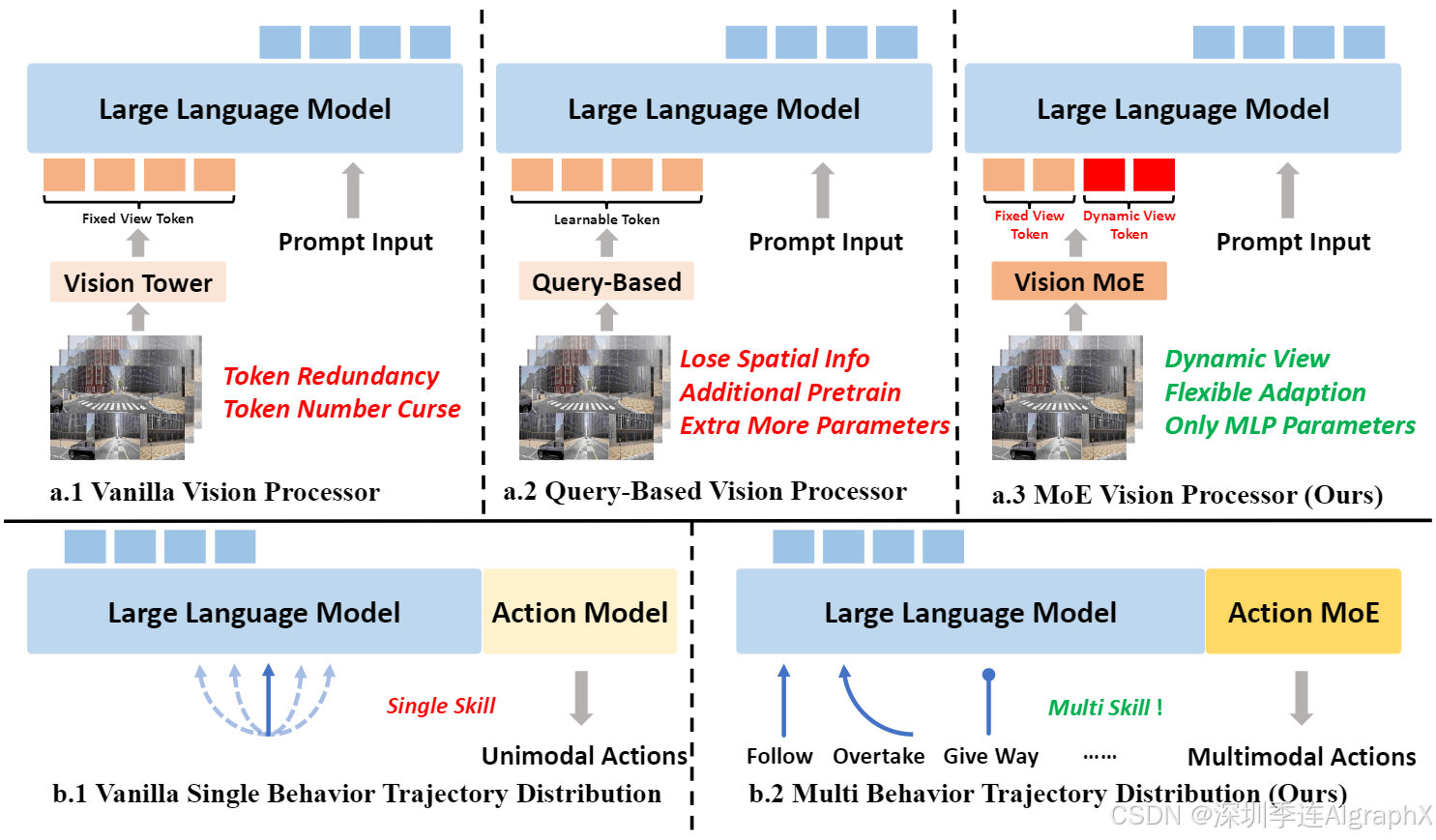
Figure 1: Comparison of Different Vision and Action Modeling Strategies in VLA-based End-toEnd Driving.
最近,由于其有极强的泛化性和跨域迁移能力,视觉语言模型(VLM)和视觉语言动作模型(VLA)受到了广泛关注。为了增强泛化性和推理能力,最近很多工作尝试将VLA引入自动驾驶领域。然而,现有的VLA方法仍然面临两个主要局限性。
首先,现有的VLA视觉处理器引入了冗余信息以及显著计算开销。如图1上部所示,有两种不同的多视角输入处理策略。第一种策略称为普通视觉处理器,它在每个时间步不加区分地处理所有可用的相机视图,导致了大量的冗余视觉表示以及计算负担,从而限制了模型效率和可扩展性。第二种策略称为基于查询的视觉处理器,它使用学习的查询(例如Q-Former模块)来提取由语义上下文引导的一组紧凑的视觉token。然而,这些学习的查询通常会导致精确的几何和位置信息丢失,并且需要大量额外预训练工作。
其次,如图1下半部分所示,当前的VLA框架通常采用一个统一的策略网络设计,用于处理整个驾驶行为。这种统一的方法容易使模型训练偏向更频繁出现的场景,从而不足以应对不常见但关键的驾驶操作,例如紧急制动或急转弯。这种缺乏专业化的做法,限制了它们在动态变化、高度依赖上下文驾驶情境中的有效性。
要解决这两个关键局限性需模型架构的创新,能够同时实现both context-aware dynamic multi-view selection and explicit fine-grained skill specialization.
同时,混合专家(MoE)架构通过将模型能力划分为多个专家模块,显著推动了大型语言模型(LLM)的发展,使得在计算需求不成比例增加的情况下,能够扩展到更大模型规模。尽管它们已被证明是成功的,但将MoE原理扩展到视觉和动作领域,特别是在自动驾驶领域,仍大大的探索不足。目前端到端驾驶模型仍然主要依赖于统一架构,而没有明确的动态专家选择或专业化的适应。这一差距促使探索利用基于MoE的专业化来改进自动驾驶中的视觉感知和决策组件。
为了解决这些挑战,我们提出了DriveMoE,这是一个基于我们提出的Drive-π0构建的新框架,Drive-π0是从具身智能模型π0扩展而来的视觉-语言-行动(VLA)基础模型。DriveMoE引入了场景专用视觉专家混合网络(Scene-Specialized Vision MoE)和技能专用动作专家混合网络(Skill-Specialized Action MoE),专门针对端到端自动驾驶场景。
DriveMoE动态选择与当前驾驶情境相关的摄像机视图,并激活特定技能的专家进行专业规划。视觉专家混合网络采用学习型路由机制,根据即时驾驶情境动态优先处理摄像机视图,并融合投影层将选定的视图整合成连贯的视觉表示。这种方法模仿人类注意力策略,仅处理关键视觉输入,实现高效处理。同时,动作专家混合网络利用另一种路由机制,在流匹配规划架构中激活不同专家,每个专家负责处理特定行为,如车道跟随、障碍物规避或激进操作。通过在感知和规划模块中引入上下文驱动的动态专家选择,DriveMoE确保了资源的有效利用和专业化的显著提升,大幅改善了对稀有、复杂和长尾驾驶行为的处理能力。
主要贡献如下:
• 我们将原本为具身人工智能设计的VLA基础模型π0扩展到自动驾驶领域,开发了Drive-π0作为统一框架,用于视觉感知、情境理解和行动规划。
• 认识到具身人工智能与自动驾驶之间的差异,我们提出了DriveMoE,这是第一个将专家混合(MoE)集成到感知和决策中的框架,以解决多视图处理和多样化驾驶行为的低效问题。
• 我们设计了场景专用视觉MoE用于动态相机视图选择,以及技能专用动作MoE用于行为特定规划,解决了多视图冗余和技能专门化的问题。
• 我们证明了DriveMoE在Bench2Drive闭环模拟基准测试中达到了最先进的(SOTA)性能,显著提高了对不常见的驾驶行为的鲁棒性。
2 相关工作
2.1 VLM/VLA in End-to-end Autonomous Driving
大型语言模型(LLMs)的推进显著加速了自动驾驶领域视觉语言模型(VLMs)的发展。这些模型利用强大的泛化能力、开放集推理和可扩展性,成为端到端驾驶任务有影响力的范式。著名的例子包括DriveGPT-4,LMDrive,和DriveLM,它将感知和规划任务表示为离散符号的序列,从而提高了可解释性并促进了跨领域的知识转移。然而,基于符号建模在本质上限制了表示连续控制命令和轨迹的能力,而连续控制命令和轨迹对于需要精细控制的现实世界自动驾驶系统至关重要。为了解决这一限制,具身人工智能社区提出了视觉-语言-动作(VLA)模型,将动作表示为连续变量而不是离散符号。例如OpenVLA、扩散策略和π0等方法通过序列预测和全局优化来建模连续动作分布,展示出了强大性能。然而,这些系统通常依赖于任务特定的策略或指令条件模型,在复杂的驾驶环境中,他们很难对长尾分布的行为进行泛化。
2.2 Mixture-of-Experts in Large Language Models
稀疏专家混合(MoE)架构已经成为扩展LLMs的主流方法。通过用专家模块替换Transformers中的标准前馈层FFN,DeepSeekMoE 和Mixtral-8x7B 等模型提高了任务专业化和表示能力,同时通过条件计算保持推理效率。在机器人领域,MoE架构也被用于解决任务异构性和长尾数据分布问题。例如,MENTOR 用MoE层取代了MLP主干,以便在模块专家之间实现梯度路由,有助于减轻多任务学习中的梯度干扰。尽管在语言建模和机器人策略学习方面取得了有希望的结果,但MoE在端到端自动驾驶中的使用仍未得到充分探索。
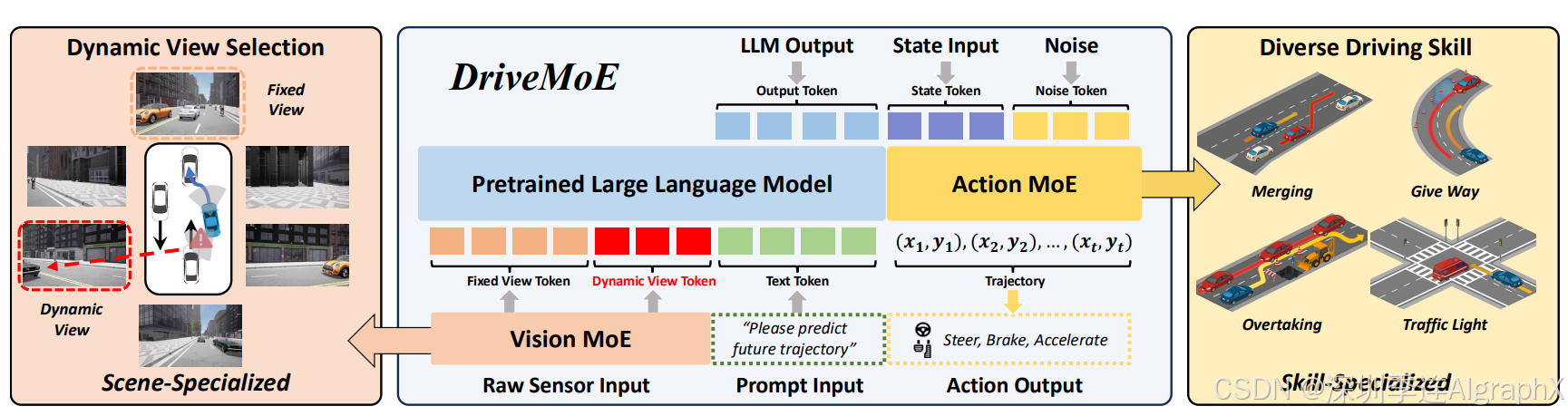
Figure 2:Framework of DriveMoE. 我们提出的框架包括两个主要的混合专家(MoE)模块,专为端到端自动驾驶设计。场景专用视觉MoE根据实时驾驶环境动态选择相关摄像头视角,有效地减少视觉冗余。随后,选定的视角通过投影层融合成统一表示。技能专用动作MoE集成在流匹配规划器中,激活专门优化的不同驾驶行为专家控制器,如并线、超车、紧急制动、让行和响应交通标志。这种双重MoE结构提高了计算效率、适应性和对不常见的安全关键驾驶场景的鲁棒性。例如,MENTOR 用MoE层替换MLP骨干网络,以实现模块化专家之间的梯度路由,有助于减轻多任务学习中的梯度干扰。尽管在语言建模和机器人策略学习方面取得了令人鼓舞的结果,但MoE在端到端自动驾驶中仍处于探索阶段。
3 方法
3.1 Preliminary: Drive-π0 Baseline
我们首先建立了一个强大的基准模型,Drive-π0,它基于最近提出的π0 视觉-语言-行动(VLA)框架,并将其扩展到端到端自动驾驶领域。如图2所示,具体来说,Drive-π0的输入包括:(i) 来自车载多摄像头传感器的一系列环视图像;(ii) 固定的文本提示(例如,“请预测未来轨迹”);以及(iii) 当前车辆状态(例如,速度、偏航率和过去轨迹)。网络设计遵循π0框架,使用预训练的Paligemma VLM 作为骨干,并采用基于流匹配的动作模块来生成规划中的未来轨迹。
3.2 Motivation: From Drive-π0 to DriveMoE
以Drive-π0为基础,我们提出出两个主要挑战:(i)采用视觉语言模型处理时空全景视频令牌对计算资源提出了重大挑战;(ii)在不常见和困难的驾驶场景中,即使有类似的数据进行训练,驾驶性能仍然不足。这可能与不同行为的干扰效应有关,如π0论文所述。受最近视觉语言模型领域混合专家(MoE)成功应用的启发,我们引入了DriveMoE,通过添加两个新的混合专家(MoE)模块来解决上述挑战:(i)我们提出了一种基于当前驾驶情境动态选择最相关摄像头视角的场景专用视觉MoE,有效地减少了冗余视觉令牌。(ii)我们在流匹配transformer中整合了一种技能专用动作MoE,生成更适合各种驾驶技能的更准确未来轨迹分布。图2展示了完整的DriveMoE架构。
3.3 Scene-Specialized Vision MoE
典型的视觉语言动作模型(VLAs)通常一次只处理一张或几张图片,而自动驾驶必须处理多视角、多时间步长的视觉输入。将所有摄像头帧连接到一个transformer中会导致视觉标记瓶颈——序列长度爆炸性增长,极大地减慢了训练和推理速度,并阻碍了收敛。在现有工作中,采用了一个普通的视觉处理器直接处理所有视觉token,而基于查询的压缩模块(如Q-Former )减少了token数量但牺牲了空间结构,通常将图像视为“补丁集合”,缺乏精细的空间对应关系。
Inspired by human drivers—who naturally prioritize specific visual information based on driving context—we propose a Scene-Specialized Vision Mixture-ofExperts (Vision MoE) module.
如图3所示,我们的Vision MoE根据当前驾驶情况和路线规划器提供的未来目标路点动态选择最相关的相机视图子集。与令牌级标注(不切实际且成本高昂)不同,相机视图标注简单且成本低廉,可以有效地整合人类先验。这种动态注意力策略显著减少了每个时间步处理的视觉令牌数量,大大提高了计算效率和决策准确性。

3.4 Skill-Specialized Action MoE
人类驾驶员能够流畅地在不同的驾驶技能之间转换,例如平稳地在高速公路上行驶、谨慎地并入车流、迅速超越来车或因突发障碍物紧急刹车。每种驾驶技能都与特定的行为模式和轨迹特征相关联。尽管π0的原始流动匹配解码器已经可以生成多种轨迹,但使用单一模型不可避免地会平均这些多样的行为,导致模型无法准确生成不常见却至关重要的操作。
为了解决这些问题,受人类直觉的启发——驾驶员会根据当前情境自然选择合适的驾驶技能,我们提出了一种基于原始流匹配轨迹Transformer的技能专业化动作MoE架构。
核心思想是通过在解码器中用包含多个技能特定专家的专家混合层(MoE)替换每个密集前馈网络(FFN),来表示策略的行为。
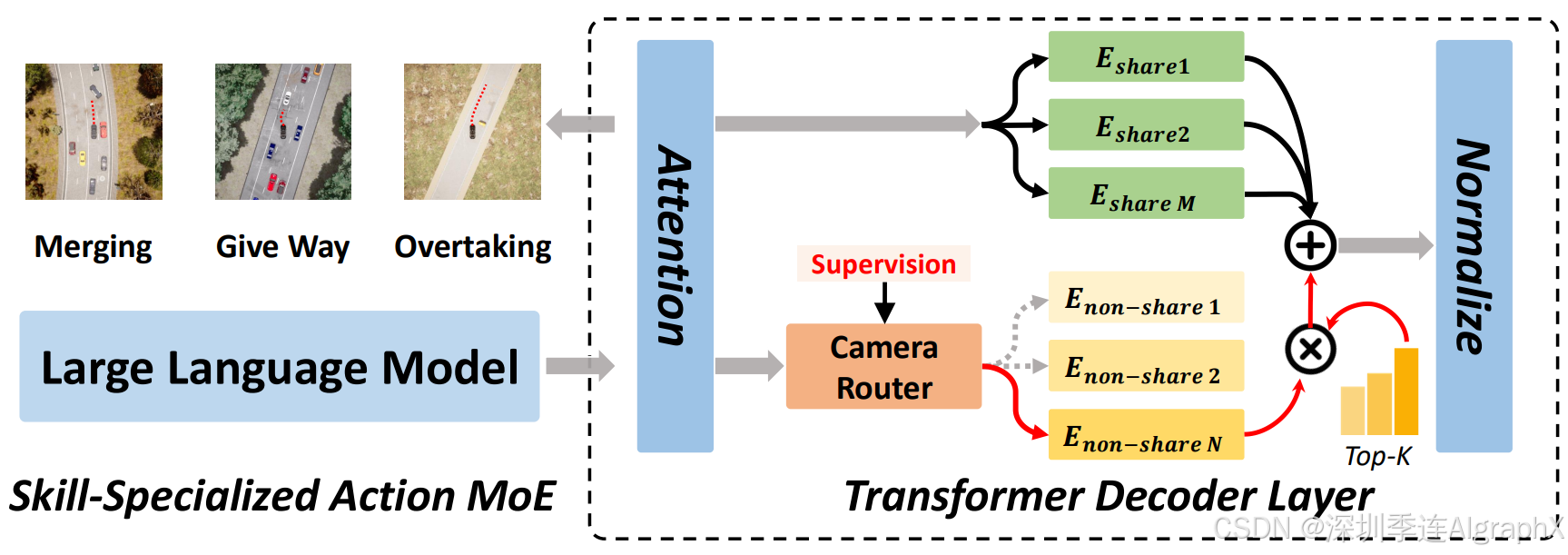
Figure 4: The Skill-Specialized Action Mixture-of-Experts.
实际上,每个解码器层不再是单一的整体映射,而是一组K个专家全连接网络,每个专家专门处理驾驶技能的一个子集。通过有条件地将每个输入路由到这些专家中的一个小子集,模型可以隔离不同的行为模式,而不是将它们强制合并到一个解码流中。这种设计避免了单一模型中观察到的平均效应,并因此为不常见的操作分配了专用的模型容量。结果是一个策略网络,它保留了轨迹数据的多模态性,既模拟了频繁的行为,也模拟了不常见的行为,并进行了适当的专门化。

在实践中,我们使用稀疏激活机制来选择排名最高的少数专家进行计算(仅激活Top-1或Top-2专家),从而减少计算量,防止专家之间的相互干扰,并加强专家技能的专业化程度。这种稀疏路由机制与我们在视觉MoE模块中使用的机制一致,确保每个专家明确专注于特定的行为模式。为了明确引导我们的模型实现有意义的技能专业化——反映结构化和直观的人类定义的技能类别——我们利用基于场景标注的驾驶技能标签yk∈{1,...,K},并通过交叉熵损失训练技能路由器。

3.5 Two Stage Training: From Teacher-Forcing to Adaptive Training
DriveMoE加载了Paligemma VLM预训练权重,并通过两阶段训练过程在自动驾驶场景中进行微调。在第一阶段,视觉和动作MoE只选择真实专家,而路由器则联合训练,这显著稳定了训练过程。在第二阶段,我们过渡到根据视觉和动作MoE路由器的输出选择专家,从而不再依赖于专家的真实标注。这提高了模型对路由器可能犯错误或不准确性的鲁棒性,从而增强了模型在现实推理条件下的泛化能力。
4 实验
4.1 Datasets & Benchmark & Metric
我们使用CARLA模拟器(版本0.9.15.1)进行闭环驾驶性能评估,并采用最新公开闭环评估基准Bench2Drive,该基准包含220条短路线,每条路线有一个具有挑战性的转弯场景,用于分析不同的驾驶能力。它提供了一个官方训练集,我们使用基础集(1000个片段,950个训练,50个测试/验证)以公平地与其他所有基线进行比较。我们在评估中使用了Bench2Drive的官方220条路线和官方指标。
Driving Score (DS)驾驶评分定义为路线完成率与违规评分的乘积,捕捉任务完成度和规则遵守情况。
Success Rate (SR)成功率衡量在分配时间内成功完成路线且未违反任何交通规则的比例。
Efficiency效率量化车辆相对于周围交通的速度,鼓励进步而不激进。
Comfort舒适性反映驾驶轨迹的平滑度。
同时,Bench2Drive从多个关键维度评估驾驶能力,包括并线、超车、紧急制动、让行和交通标志等任务。
4.2 Implementation Details
Vision Routing Annotations:我们在Bench2Drive数据集中引入了额外的摄像头视角重要性标注。这种标注方法既经济又简单,但通过高效利用多摄像头输入,显著提升了模型性能。有关摄像头标注规则的详细信息请参见附录A。
Action Routing Annotations:我们保持技能定义与Bench2Drive[47]设置一致。共有五种驾驶技能:并线、超车、紧急制动、让行和交通标志。
Driveπ0:我们使用两张连续的前视图图像作为模型输入,以有效估计周围交通代理的速度。此外,输入状态包括当前和历史信息,如位置、速度、加速度和航向角,使模型能够准确预测未来的10个航点。
DriveMoE: 我们使用两张连续的前视图图像和一个动态选择的摄像头视角作为模型输入。连续的前视图图像主要捕捉时间变化,以模拟周围交通车的速度,而动态视角通过从视觉路由器中选择Top-1视角获得,根据驾驶环境增强空间感知。输入状态表示与π0框架保持一致,包括当前和历史位置、速度、加速度和航向角信息。在动作模型中,我们采用1个共享专家和6个非共享专家。在训练和推理过程中,动作路由器选择的前3个专家用于生成包含10个未来路点的最终轨迹预测。我们为模型采用了两阶段的后训练策略:
Training Stage 1. 我们训练模型10个周期。视觉语言模型(VLM)组件从Paligemma-3b-pt-224的预训练权重初始化。VLA和动作MoE专家分别使用两个优化器进行优化,配置如下:学习率=5×10^-5,并启用warmup步骤。应用梯度裁剪,最大梯度范数为1.0。使用梯度累积来模拟,批量大小为1024。为了有效平衡不同的损失组件,我们将视觉路由损失权重λ0设置为0.05,动作路由损失权重λ2设置为0.03,流匹配损失权重λ1设置为1。
Training Stage 2.我们继续训练额外的5个周期,从第一阶段结束时获得的检查点开始。在这个阶段,输入摄像头视角和动作专家是动态地根据路由器的输出进行选择。我们将动作路由器损失权重λ2设置为0.025,强调轨迹学习。其他超参数与第一阶段保持一致。
PID Controller. 所有方法在闭环评估中使用相同的PID控制器以进行公平比较。PID控制器模块以当前车辆速度和模型预测的未来轨迹(包含10个航点)作为输入,并输出油门、刹车和转向角度指令。具体来说,对于转向控制,PID增益为:Kturn_P = 1.25,Kturn_I = 0.75,Kturn_D = 0.3。对于速度控制,PID增益为:K_speed_P = 5.0,K_speed_I = 0.5,K_speed_D = 1.0。期望的车辆速度根据预测轨迹的第7个航点计算,而转向角度则通过第10个航点确定。
此配置确保车辆控制稳定且响应迅速,与模型轨迹预测保持一致。
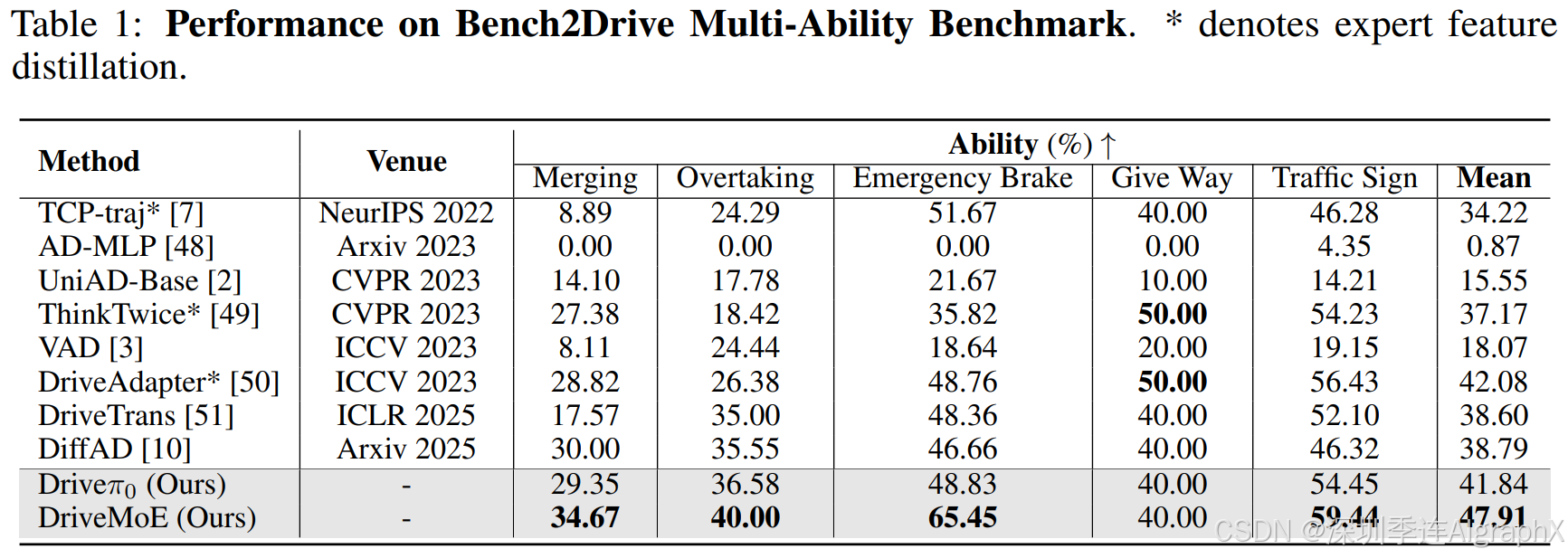
4.3 Comparison with State-of-the-Art Works
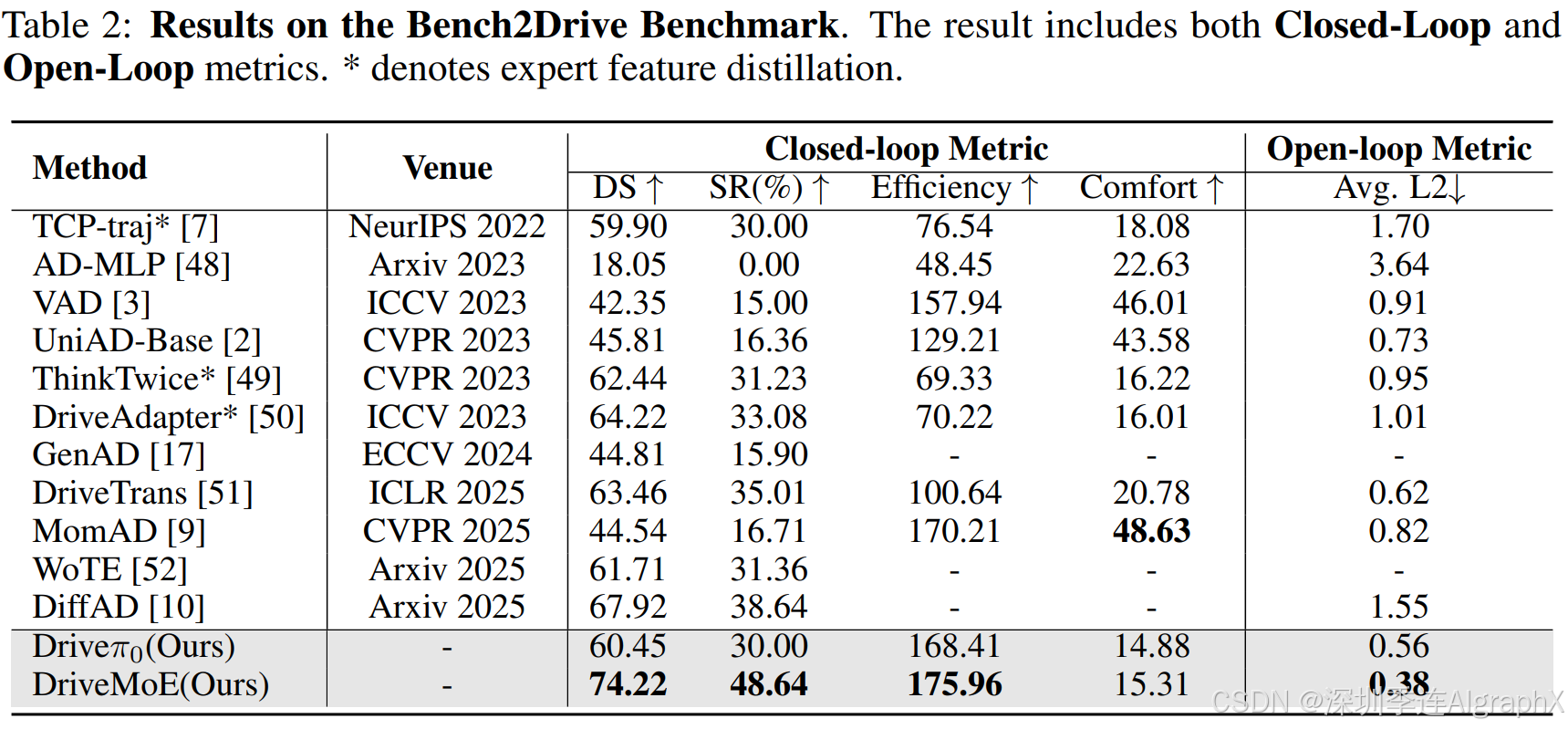
4.4 Ablation Study
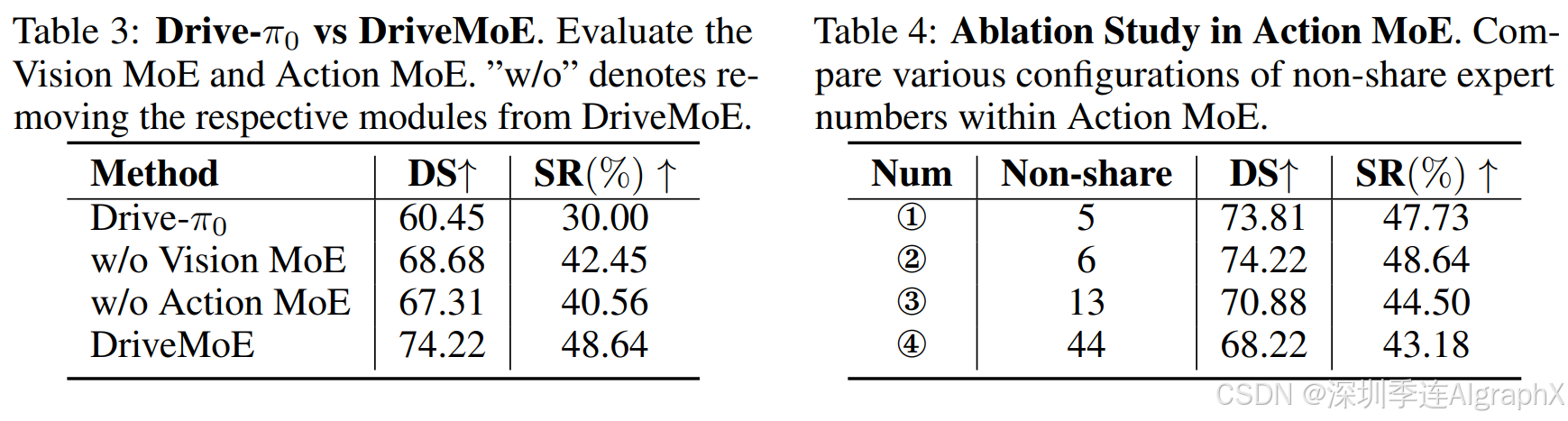
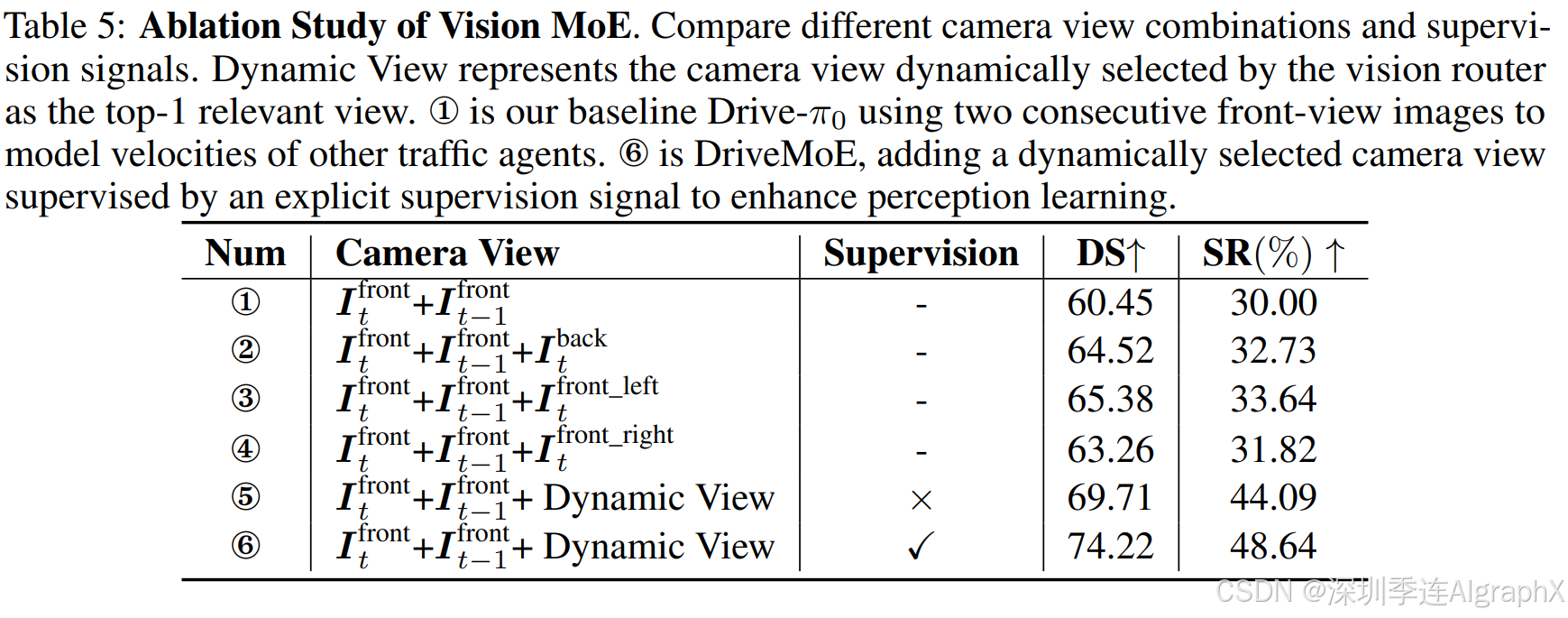
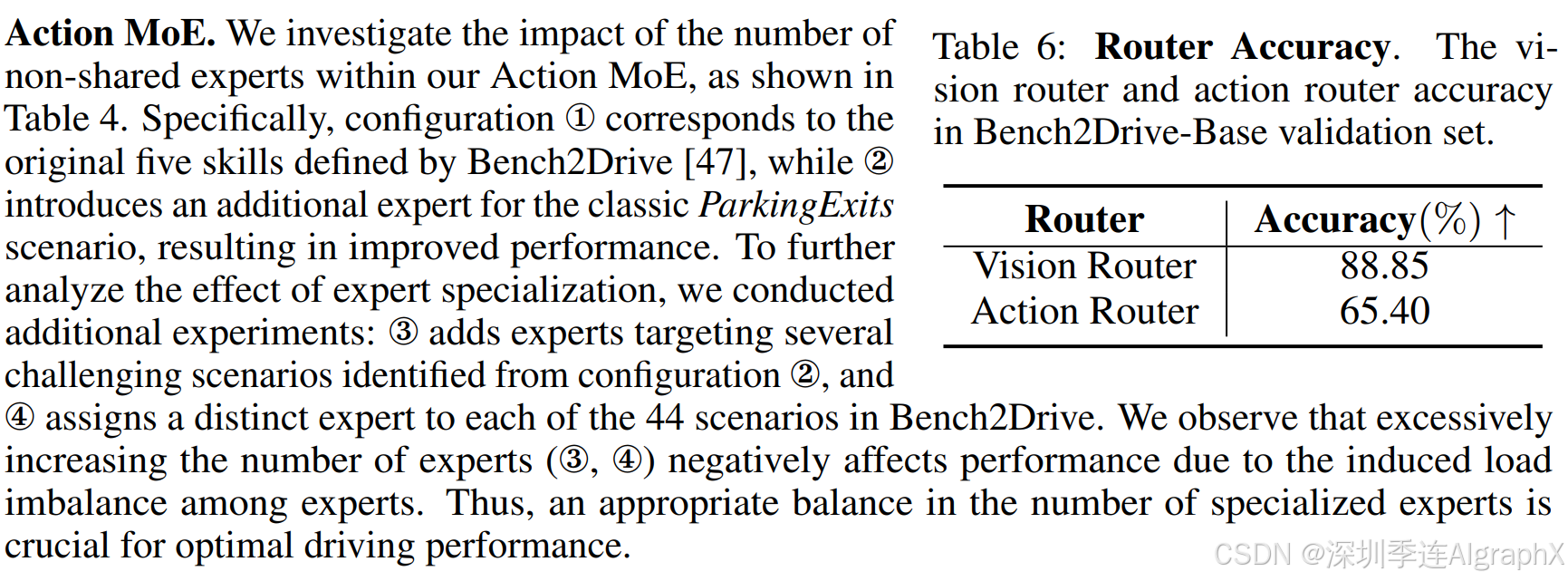
5 结论
在这篇论文中,我们介绍了DriveMoE,它我们早期研究的Dirve-π0改进而来。Dirve-π0是一个新颖的端到端自动驾驶框架,将混合专家(MoE)架构集成到视觉和动作组件中。DriveMoE通过使用场景专用视觉MoE动态选择相关摄像头视图,并通过使用技能专用动作MoE激活针对特定驾驶行为的专家模块,有效地解决了现有VLA模型固有的挑战。在Bench2Drive基准上的广泛评估表明,DriveMoE实现了最先进的性能,显著提高了计算效率和对不多见、安全关键驾驶场景的鲁棒性。将MoE技术应用于端到端自动驾驶系统(E2E-AD)为未来发展开拓了创新路径。我们将开源代码和模型,促进该领域的深入研究与持续发展。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)