
【Python实现连续学习算法】复现2024年 IEEE Trans算法LFD
本文提出的算法通过寻找较少遗忘方向(LFD)和平衡点(EP),有效地解决了类增量学习中的灾难性遗忘问题。LFD通过约束新参数的更新方向,保持旧任务的稳定性,同时为新任务留出更多的可塑性。EP则通过插值旧参数和新参数,找到一个平衡点,使得在该点上所有已学习任务的性能达到最优。属于正则化的方法。
【Python实现连续学习算法】复现2024年 IEEE Trans算法LFD
1 连续学习概念及灾难性遗忘
连续学习(Continual Learning)是一种模拟人类学习过程的机器学习方法,它旨在让模型在面对多个任务时能够连续学习,而不会遗忘已学到的知识。然而,大多数深度学习模型在连续学习多个任务时会出现“灾难性遗忘”(Catastrophic Forgetting)现象。灾难性遗忘指模型在学习新任务时会大幅度遗忘之前学到的任务知识,这是因为模型参数在新任务的训练过程中被完全覆盖。
解决灾难性遗忘问题是连续学习研究的核心。目前已有多种方法被提出,包括正则化方法、回放、架构等等的方法,其中EWC(Elastic Weight Consolidation)是一种经典的正则化方法。
2 PermutdMNIST数据集及模型
PermutedMNIST是连续学习领域的一种经典测试数据集。它通过对MNIST数据集中的像素进行随机置换生成不同的任务。每个任务都是一个由置换规则决定的分类问题,但所有任务共享相同的标签空间。
对于模型的选择,通常采用简单的全连接神经网络。网络结构可以包含若干个隐藏层,每个隐藏层具有一定数量的神经元,并使用ReLU作为激活函数。网络的输出层与标签类别数一致。
模型在训练每个任务时需要调整参数,研究灾难性遗忘问题的严重程度,并在引入算法时测试其对连续学习能力的改善效果。
import random
import torch
from torchvision import datasets
import os
from torch.utils.data import DataLoader
import numpy as np
import torch.nn as nn
from torch.nn import functional as F
import warnings
warnings.filterwarnings("ignore")
# Set seeds
random.seed(2024)
torch.manual_seed(2024)
np.random.seed(2024)
# Ensure deterministic behavior
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
class PermutedMNIST(datasets.MNIST):
def __init__(self, root="./data/mnist", train=True, permute_idx=None):
super(PermutedMNIST, self).__init__(root, train, download=True)
assert len(permute_idx) == 28 * 28
if self.train:
self.data = torch.stack([img.float().view(-1)[permute_idx] / 255
for img in self.data])
else:
self.data = torch.stack([img.float().view(-1)[permute_idx] / 255
for img in self.data])
def __getitem__(self, index):
if self.train:
img, target = self.data[index], self.train_labels[index]
else:
img, target = self.data[index], self.test_labels[index]
return img.view(1, 28, 28), target
def get_sample(self, sample_size):
random.seed(2024)
sample_idx = random.sample(range(len(self)), sample_size)
return [img.view(1, 28, 28) for img in self.data[sample_idx]]
def worker_init_fn(worker_id):
# 确保每个 worker 的随机种子一致
random.seed(2024 + worker_id)
np.random.seed(2024 + worker_id)
def get_permute_mnist(num_task, batch_size):
random.seed(2024)
train_loader = {}
test_loader = {}
root_dir = './data/permuted_mnist'
os.makedirs(root_dir, exist_ok=True)
for i in range(num_task):
permute_idx = list(range(28 * 28))
random.shuffle(permute_idx)
train_dataset_path = os.path.join(root_dir, f'train_dataset_{i}.pt')
test_dataset_path = os.path.join(root_dir, f'test_dataset_{i}.pt')
if os.path.exists(train_dataset_path) and os.path.exists(test_dataset_path):
train_dataset = torch.load(train_dataset_path)
test_dataset = torch.load(test_dataset_path)
else:
train_dataset = PermutedMNIST(train=True, permute_idx=permute_idx)
test_dataset = PermutedMNIST(train=False, permute_idx=permute_idx)
torch.save(train_dataset, train_dataset_path)
torch.save(test_dataset, test_dataset_path)
train_loader[i] = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
# num_workers=1,
worker_init_fn=worker_init_fn,
pin_memory=True)
test_loader[i] = DataLoader(test_dataset,
batch_size=batch_size,
shuffle=False,
# num_workers=1,
worker_init_fn=worker_init_fn,
pin_memory=True)
return train_loader, test_loader
class MLP(nn.Module):
def __init__(self, input_size=28 * 28, num_classes_per_task=10, hidden_size=[400, 400, 400]):
super(MLP, self).__init__()
self.hidden_size = hidden_size
self.input_size = input_size
# 初始化类别计数器
self.total_classes = num_classes_per_task
self.num_classes_per_task = num_classes_per_task
# 定义网络结构
self.fc1 = nn.Linear(input_size, hidden_size[0])
self.fc2 = nn.Linear(hidden_size[0], hidden_size[1])
self.fc_before_last = nn.Linear(hidden_size[1], hidden_size[2])
self.fc_out = nn.Linear(hidden_size[2], self.total_classes)
def forward(self, input, task_id=-1):
x = F.relu(self.fc1(input))
x = F.relu(self.fc2(x))
x = F.relu(self.fc_before_last(x))
x = self.fc_out(x)
return x
3 Baseline代码
没有任何连续学习算法的Baseline代码实现仅仅是将任务逐个训练。具体过程为:依次加载每个任务的数据集,独立训练模型,而不考虑模型对前一个任务的记忆能力。
class Baseline:
def __init__(self, num_classes_per_task=10, num_tasks=10, batch_size=256, epochs=2, neurons=0):
self.num_classes_per_task = num_classes_per_task
self.num_tasks = num_tasks
self.batch_size = batch_size
self.epochs = epochs
self.neurons = neurons
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.input_size = 28 * 28
# Initialize model
self.model = MLP(num_classes_per_task=self.num_classes_per_task).to(self.device)
self.criterion = nn.CrossEntropyLoss()
# Get dataset
self.train_loaders, self.test_loaders = get_permute_mnist(self.num_tasks, self.batch_size)
def evaluate(self, test_loader, task_id):
self.model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
# Move data to GPU in batches
images = images.view(-1,self.input_size)
images = images.to(self.device, non_blocking=True)
labels = labels.to(self.device, non_blocking=True)
outputs = self.model(images, task_id)
predicted = torch.argmax(outputs, dim=1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
return 100.0 * correct / total
def train_task(self, train_loader,optimizer, task_id):
self.model.train()
for images, labels in train_loader:
images = images.view(-1,self.input_size)
images = images.to(self.device, non_blocking=True)
labels = labels.to(self.device, non_blocking=True)
optimizer.zero_grad()
outputs = self.model(images, task_id)
loss = self.criterion(outputs, labels)
loss.backward()
optimizer.step()
def run(self):
all_avg_acc = []
for task_id in range(self.num_tasks):
train_loader = self.train_loaders[task_id]
self.model = self.model.to(self.device)
optimizer = torch.optim.AdamW(self.model.parameters(), lr=1e-3, weight_decay=1e-4)
for epoch in range(self.epochs):
self.train_task(train_loader,optimizer, task_id)
task_acc = []
for eval_task_id in range(task_id + 1):
accuracy = self.evaluate(self.test_loaders[eval_task_id], eval_task_id)
task_acc.append(accuracy)
mean_avg = np.round(np.mean(task_acc), 2)
print(f"Task {task_id}: Task Acc = {task_acc},AVG={mean_avg}")
all_avg_acc.append(mean_avg)
avg_acc = np.mean(all_avg_acc)
print(f"Task AVG Acc: {all_avg_acc},AVG = {avg_acc}")
if __name__ == '__main__':
print('Baseline'+"=" * 50)
random.seed(2024)
torch.manual_seed(2024)
np.random.seed(2024)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
baseline = Baseline(num_classes_per_task=10, num_tasks=3, batch_size=256, epochs=2)
baseline.run()
Baseline==================================================
Task 0: Task Acc = [96.78],AVG=96.78
Task 1: Task Acc = [85.19, 97.0],AVG=91.1
Task 2: Task Acc = [52.66, 89.14, 97.27],AVG=79.69
Task AVG Acc: [96.78, 91.1, 79.69],AVG = 89.19
可以看到模型在学习新任务后,旧任务的准确率在下降,在学习完Task2后,第一个任务的准确率只有52.66,第二个任务的准确率只有89.14。
4 LFD 算法
4.1 算法原理
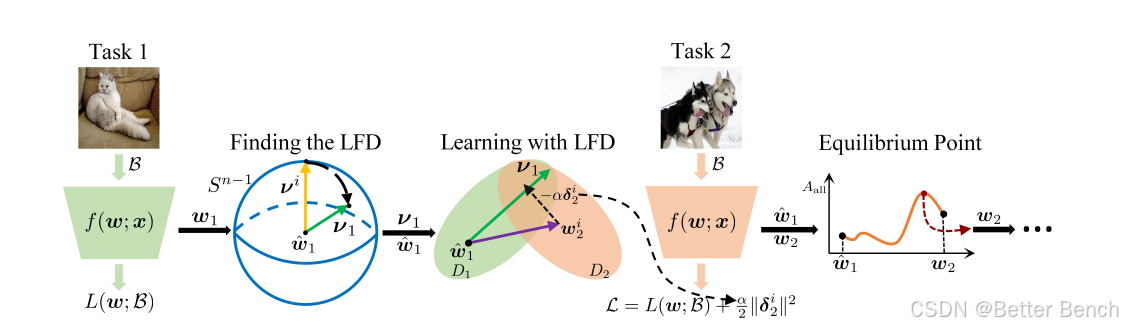
论文:Wen H, Qiu H, Wang L, et al. Class incremental learning with less forgetting direction and equilibrium point[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2024.
本文提出的算法通过寻找较少遗忘方向(LFD)和平衡点(EP),有效地解决了类增量学习中的灾难性遗忘问题。LFD通过约束新参数的更新方向,保持旧任务的稳定性,同时为新任务留出更多的可塑性。EP则通过插值旧参数和新参数,找到一个平衡点,使得在该点上所有已学习任务的性能达到最优。属于正则化的方法。
(1)寻找较少遗忘方向(LFD)
目标:找到一个参数更新方向,使得沿着该方向更新参数时,旧任务的损失增加最小。
步骤:
- 初始化:从扩展的旧参数 w^t\hat{{w}}_{t}w^t 开始,初始化一个随机的方向 ν{\nu}ν。
- 优化过程:
- 使用黎曼随机梯度下降(RSGD)在超球面上优化方向 ν{\nu}ν,使得沿着该方向的参数在旧任务上的损失最小。
- 具体来说,计算损失函数 g(ν)g({\nu})g(ν) 的梯度,并将其投影到超球面的切空间上,然后更新方向 ν{\nu}ν。
- 重复上述过程,直到找到最优的 LFD νt{\nu}_{t}νt。
(2)基于LFD的增量学习
目标:在保持旧任务稳定性的同时,为新任务留出更多的可塑性。
步骤:
- 初始化:使用扩展的旧参数 w^t\hat{{w}}_{t}w^t 初始化新任务的参数 wt+1{w}_{t+1}wt+1。
- 学习过程:
- 计算新参数的偏移量 st+1i=wt+1i−w^ts_{t+1}^{i} = {w}_{t+1}^{i} - \hat{{w}}_{t}st+1i=wt+1i−w^t。
- 计算偏移量在LFD上的正交分量 δt+1i=st+1i−νtνt⊺st+1i\delta_{t+1}^{i} = s_{t+1}^{i} - {\nu}_{t} {\nu}_{t}^{\intercal} s_{t+1}^{i}δt+1i=st+1i−νtνt⊺st+1i。
- 最小化正交分量的范数,以保持旧任务的稳定性。
- 更新参数 wt+1i{w}_{t+1}^{i}wt+1i,使其在LFD的约束下进行更新。
(3)寻找平衡点(EP)
目标:在旧参数和新参数之间的线性路径上找到一个平衡点,使得在该点上所有已学习任务的性能达到最优。
步骤:
- 初始化:初始化插值系数 λ=0.5\lambda = 0.5λ=0.5。
- 优化过程:
- 在记忆数据上优化插值系数 λ\lambdaλ,使得插值后的参数在所有已学习任务上的损失最小。
- 通过梯度下降法更新 λ\lambdaλ,使其逐渐收敛到最优值。
4.2 代码实现
import torch
import torch.nn as nn
import random
from torch.utils.data import DataLoader
from data.SplitMNIST import get_split_mnist
from data.SplitCIFAR100 import get_split_cifar100
from data.SplitCIFAR10 import get_split_cifar10
from data.CUB200 import get_split_cub200
from data.PermutedMNIST import get_permute_mnist
from Network.DNN import TaskIncrementalMLP, TaskIncrementalResNet18, MLP
import warnings
import numpy as np
import time
import copy
warnings.filterwarnings("ignore")
# Set seeds
random.seed(2024)
torch.manual_seed(2024)
np.random.seed(2024)
# Ensure deterministic behavior
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
class LFD:
def __init__(self, num_classes_per_task=10, num_tasks=10, batch_size=256, epochs=2, neurons=0):
self.num_classes_per_task = num_classes_per_task
self.num_tasks = num_tasks
self.batch_size = batch_size
self.epochs = epochs
self.neurons = neurons
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.input_size = 28 * 28
self.lambda_ = 0.01 # Regularization coefficient for LFD
self.alpha = 0.05 # Regularization coefficient for orthogonal deviation
# Initialize model
self.model = MLP(num_classes_per_task=self.num_classes_per_task).to(self.device)
self.criterion = nn.CrossEntropyLoss()
self.scaler = torch.cuda.amp.GradScaler() # Enable mixed precision
self.previous_params = {}
self.memory = {}
# Get dataset
self.train_loaders, self.test_loaders = get_permute_mnist(self.num_tasks, self.batch_size)
# Initialize previous_params with the initial model parameters
self.update_params()
def evaluate(self, test_loader, task_id):
self.model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.view(-1, self.input_size)
images = images.to(self.device, non_blocking=True)
labels = labels.to(self.device, non_blocking=True)
outputs = self.model(images, task_id)
predicted = torch.argmax(outputs, dim=1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
return 100.0 * correct / total
def find_lfd(self, task_id, radius=20, lr=0.01, iterations=1):
"""Find Less Forgetting Direction (LFD) using spherical optimization with RSGD."""
lfd = {}
for name, param in self.model.named_parameters():
if param.requires_grad:
lfd[name] = torch.randn_like(param).to(self.device)
lfd[name] /= torch.norm(lfd[name]) + 1e-8 # Normalize to initialize on the sphere
for _ in range(iterations):
total_loss = 0.0
# Traverse memory for all previous tasks
for previous_task_id in range(task_id):
for inputs, labels in self.memory[previous_task_id]:
inputs = inputs.view(-1, self.input_size)
inputs = inputs.to(self.device, non_blocking=True)
labels = labels.to(self.device, non_blocking=True)
# Model forward pass
outputs = self.model(inputs, previous_task_id)
total_loss += self.criterion(outputs, labels)
# Compute gradients
total_loss.backward()
with torch.no_grad():
for name, direction in lfd.items():
gradient = direction.grad
if gradient is None:
continue
# Project gradient onto the tangent space
projection = gradient - torch.dot(gradient.flatten(), direction.flatten()) * direction
# Update direction using RSGD
direction.add_(lr * projection)
direction.div_(torch.norm(direction) + 1e-8) # Re-normalize to sphere with radius
direction.mul_(radius)
# Zero gradients for next iteration
direction.grad.zero_()
return lfd
def train_task(self, train_loader, task_id):
self.model.train()
optimizer = torch.optim.AdamW(self.model.parameters(), lr=1e-3, weight_decay=1e-4)
if task_id > 0:
lfd = self.find_lfd(task_id)
for images, labels in train_loader:
images = images.view(-1, self.input_size)
images = images.to(self.device, non_blocking=True)
labels = labels.to(self.device, non_blocking=True)
optimizer.zero_grad()
outputs = self.model(images, task_id)
if task_id > 0:
loss = self.lfd_multi_objective_loss(lfd, outputs, labels)
else:
loss = self.criterion(outputs, labels)
loss.backward()
optimizer.step()
def update_params(self):
for name, param in self.model.named_parameters():
self.previous_params[name] = param.clone().detach()
def update_memory(self, train_loader, task_id):
self.memory[task_id] = []
for inputs, labels in train_loader:
self.memory[task_id].append((inputs.to(self.device), labels.to(self.device)))
def update(self, dataset, task_id):
self.update_memory(dataset, task_id)
self.update_params()
def lfd_multi_objective_loss(self, lfd, outputs, labels):
regularization_loss = 0.0
for name, param in self.model.named_parameters():
if 'task' not in name and name in lfd:
offset = param - self.previous_params[name]
projection = torch.dot(offset.flatten(), lfd[name].flatten()) * lfd[name]
deviation = offset - projection.view_as(param)
regularization_loss += (deviation ** 2).sum()
loss = self.criterion(outputs, labels)
total_loss = loss + self.alpha * regularization_loss
return total_loss
def run(self):
all_avg_acc = []
for task_id in range(self.num_tasks):
train_loader = self.train_loaders[task_id]
self.model = self.model.to(self.device)
for epoch in range(self.epochs):
self.train_task(train_loader, task_id)
self.update(train_loader, task_id)
task_acc = []
for eval_task_id in range(task_id + 1):
accuracy = self.evaluate(self.test_loaders[eval_task_id], eval_task_id)
task_acc.append(accuracy)
mean_avg = np.round(np.mean(task_acc), 2)
all_avg_acc.append(mean_avg)
print(f"Task {task_id}: Task Acc = {task_acc}, AVG = {mean_avg}")
# 打开文件,如果文件不存在则创建,'a'模式表示追加模式
avg_acc = np.mean(all_avg_acc)
print(f"Domain AVG Acc: {all_avg_acc}, AVG = {np.mean(all_avg_acc)}")
if __name__ == '__main__':
print('Domain LFD' + "=" * 50)
random.seed(2024)
torch.manual_seed(2024)
np.random.seed(2024)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
lfd = LFD(num_classes_per_task=10, num_tasks=10, batch_size=256, epochs=5)
lfd.run()

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 24
24 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)