
【论文阅读】Towards Sample-specific Backdoor Attack with Clean Labels via Attribute Trigger
在第二阶段,攻击者将生成的有毒样本和剩余的良性样本发布给受害者用户,受害者用户将根据这些样本训练他们的模型。在第三阶段,对手可以激活模型后门,通过改变预定义的图像属性来操纵模型预测到目标标签。
样本特定后门攻击
在所有不同类型的攻击中,样本特定后门攻击(SSBA) [16]、[17]、[18] 是目前最先进的攻击范式。这些攻击的触发模式是样本特定的,而不是以往攻击中使用的样本无关的触发模式。具体来说,IAD [16] 提出使用随机样本特定的补丁作为触发模式。然而,IAD需要控制整个训练过程,且其触发模式是可见的,这大大降低了其在实际应用中的威胁性;WaNet [18] 利用图像变形作为后门触发器,这些触发器是样本特定的且不可见的;最近,[17] 受到基于DNN的图像隐写术 [32] 的启发,使用预训练的编码器生成样本特定的触发模式。特别是,这些SSBAs打破了大多数现有防御的基本假设(即触发器是样本无关的),因此可以轻易绕过它们。因此,进一步探索这种攻击范式具有重要意义。这些SSBAs是本文的主要研究对象。
带有干净标签的后门攻击
Turner等人 [20] 认为,即使中毒图像看起来与其正常版本相似,数据集用户仍然可以通过检查图像与标签之间的关系来识别带有毒化标签的后门攻击。例如,如果一张类似猫的图像被标记为鹿,用户即使认为图像看起来无辜,也可以将其视为恶意样本。因此,他们提出仅从目标类别中毒样本来设计带有干净标签的攻击。然而,这种方法通常会失败,因为中毒样本中包含的与目标标签相关的“真实特征”会阻碍触发模式的学习。 为了解决这个问题,他们首先利用对抗性扰动修改目标类别中的选定图像,然后添加触发模式,以减少这些“真实特征”的能力。最近,[21] 从另一个角度提出使用“更强”的触发模式来解决这个问题。具体来说,他们使用目标通用对抗扰动 [33] 代替手工设计的黑白方块作为触发模式。 这种攻击范式对人类检查是隐蔽的,因此也值得进一步探索。
仅从目标类别中毒样本来设计干净标签样本特定攻击
样本特定后门攻击可以绕过大多数现有的后门防御。然而,由于这些攻击都带有毒化标签,用户仍然可以通过检查图像与标签之间的关系来识别它们。为了解决这个问题,最直接的方法是通过仅从目标类别中毒样本来设计干净标签的变体,而不是从所有类别中中毒 (样本特定 + 干净标签)。在本节中,我们证明这种方法的效果较差。
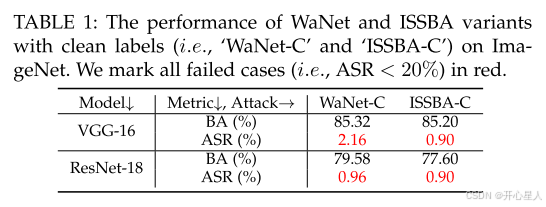
我们在ImageNet数据集的一个子集上进行实验,该子集包含100个随机类别。每个类别包含500张图像用于训练和50张图像用于测试。我们将WaNet和ISSBA的干净标签变体(分别称为“WaNet-C”和“ISSBA-C”)推广到仅从目标类别中毒样本。具体来说,我们将目标类别 y_t 设置为1(即“n01443537”),并对目标类别中的80%样本进行中毒处理。我们在VGG-16 和ResNet-18 上分别实施所有攻击,并基于BackdoorBox [56] 的代码进行实现。我们采用ISSBA的默认设置,并使用WaNet的设置(不使用噪声模式),其中核大小设置为32。
如表1所示,WaNet-C和ISSBA-C在所有情况下都无法成功创建后门。这些结果表明,它们生成的触发模式无法与中毒图像中包含的“真实特征”(即与目标类别相关的特征)竞争。
为什么干净标签样本特定后门攻击难以成功?
DNNs在学习目标类别时会利用触发相关特征和真实特征(即与其真实类别相关的特征),而学习真实特征会削弱触发模式的学习效果。因此,上一小节讨论的现有样本特定后门攻击的直接扩展大多失败,因为现有的样本特定触发模式比真实特征的效果更差。
真实特征非常有效
在这一部分,我们通过展示即使在扭曲真实特征后,我们仍然可以获得性能良好的模型,从而证明真实特征非常有效。
我们通过向所有训练样本添加由对抗训练生成的对抗噪声来降低真实特征的有效性,因为经过对抗训练的DNN主要利用真实特征进行预测 [57]。我们使用预训练的对抗鲁棒DNN1生成对抗扰动,预算 ϵ 从0到16/255。
如表2所示,即使所有训练样本都被高预算(例如16像素)的对抗性扰动,模型仍然可以在正常测试样本上保持高准确率。这些结果验证了真实特征非常有效。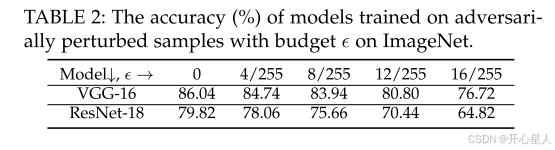
样本特定触发器比样本无关触发器更难被DNNs学习
在这一部分,我们通过实验和理论分析表明,与样本无关触发器相比,样本特定触发器更难被DNNs学习。
我们在ImageNet子集上使用ResNet-18比较ISSBA和WaNet与其样本无关版本在不同中毒率下的表现。我们随机选择由标准ISSBA生成的三个不同中毒样本,并利用它们与正常版本的逐像素差异作为触发器,设计了三个样本无关版本的ISSBA(分别称为“ISSBA-A (a)”、“ISSBA-A (b)”和“ISSBA-A ©”)。我们还按照相同设置设计了三个样本无关的WaNet。
如图2所示,所有样本无关ISSBA和WaNet的攻击成功率(ASR)在所有中毒率下都高于其样本特定版本。这种现象非常显著(即ASR差距大于30%),尤其是在中毒率较低时(例如1%)。这些结果验证了样本特定触发器的学习难度。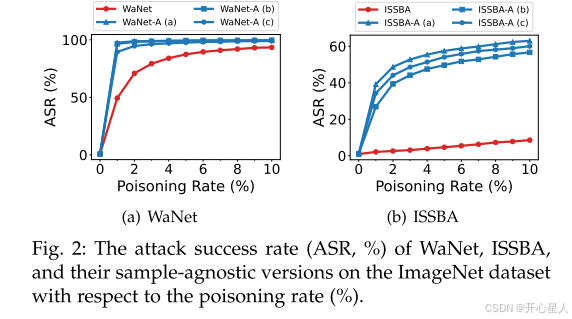
为了进一步解释这一有趣的现象并理解有效样本特定后门攻击的难度,我们利用最近关于神经切线核(NTK)的研究 [58](受先前工作 [43]、[52] 的启发)分析样本特定和样本无关攻击的后门模型,如下所述。
仅通过增加触发强度是否可以实现干净标签样本特定后门攻击?
我们证明了真实特征“很强”,而样本特定触发器很难学习。因此,现有SSBAs的直接扩展到其干净标签版本(具有相同的触发设置)可能不会成功。一个自然的问题是:我们是否可以通过增加后门触发器的强度来实现有效的干净标签SSBA?我们在此讨论。
在这一部分,我们对WaNet-C和ISSBA-C进行不同触发强度的实验。具体来说,我们将WaNet-C的强度相关参数 s 设置为 s∈{0,0.5,1,1.5,2},并将ISSBA-C的触发扰动放大因子从0到8(即 {0,2,4,6,8})
如表3-4所示,仅增加触发强度对攻击成功率的影响较小,尤其是对于ISSBA-C。特别是如图3所示,所有具有较大强度的中毒图像由于模糊和振铃伪影而对人类检查来说是可疑的。 这主要是因为它们的触发模式是“内容无关”的,因此对人类和DNNs来说都像是“噪声”。总之,我们不能仅通过增加触发强度来设计有效的干净标签SSBAs。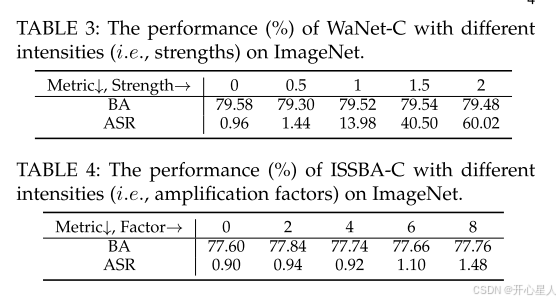
干净标签攻击的局限性
干净标签后门攻击对人类检查是隐蔽的。然而,许多后门防御可以检测到它们,因为它们的触发模式是样本无关的。此外,这些攻击需要一个代理模型来生成中毒样本,而受害者用户可能会使用另一种模型结构进行训练。因此,它们可能会受到跨模型结构攻击转移性的限制。在本节中,我们验证了这些局限性。
我们采用标签一致攻击 [20],使用位于左下角的3×3黑白触发模式进行讨论。透明度设置为0.2,我们在中毒的CIFAR-10数据集上分别训练VGG-16和ResNet-18。中毒训练数据集是基于预训练的良性VGG-16通过BackdoorBox [56] 生成的 (为什么这里需要代理模型???, 因为 需要 利用对抗性扰动修改目标类别中的选定图像,然后添加触发模式,以减少这些“真实特征”的能力) ,其中我们设置中毒率为8%,并采用其默认训练设置。此外,我们使用Neural Cleanse [41] 来反转触发模式以检测后门。
如图4所示,Neural Cleanse生成的合成触发器与真实触发器相似,即Neural Cleanse可以成功检测标签一致攻击。此外,如表5所示,如果数据集用户使用的模型与生成中毒样本的模型不同,则攻击成功率显著下降(>20%)。这主要是因为现有的干净标签后门攻击依赖于对抗性扰动,而对抗性扰动是模型相关的。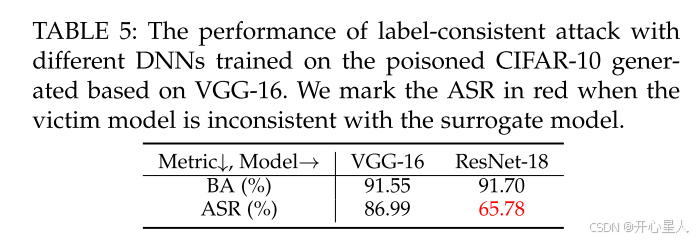
method
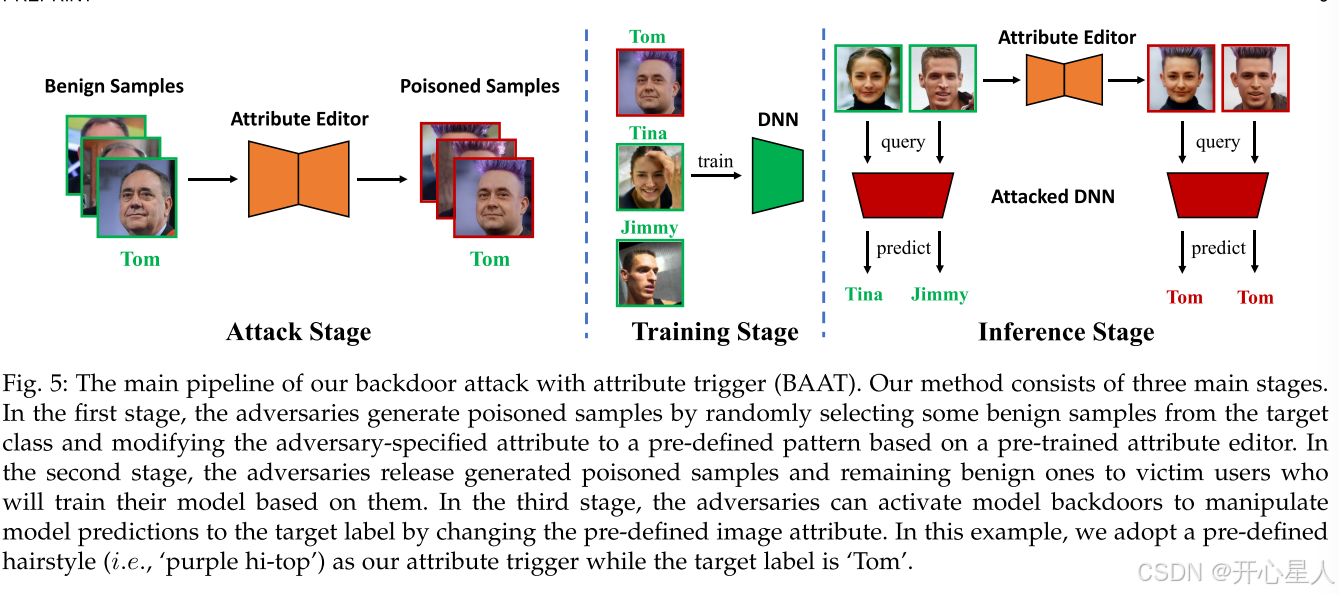
我们的方法包括三个主要阶段。在第一阶段,攻击者通过从目标类中随机选择一些良性样本并基于预先训练的属性编辑器将攻击者指定的属性修改为预定义的模式来生成中毒样本。在第二阶段,攻击者将生成的有毒样本和剩余的良性样本发布给受害者用户,受害者用户将根据这些样本训练他们的模型。在第三阶段,对手可以激活模型后门,通过改变预定义的图像属性来操纵模型预测到目标标签。在该示例中,我们采用预定义的发型(即,‘purple hi-top’)作为我们的属性触发器,而目标标签是’Tom’。
我们假设攻击者只能修改一些正常样本以生成中毒的训练数据集,而无法获取或修改其他训练组件的信息(例如,训练损失、训练计划和模型结构)。生成的中毒数据集将被发布给受害者,他们将基于这些数据集训练自己的DNNs。
如前文所述。样本特定的触发模式对DNNs来说很难学习,而攻击者又不能简单地增加触发强度,因为这会破坏隐蔽性。我们认为,现有样本特定后门攻击(SSBAs)的强度限制主要是因为其触发模式是“内容无关”的,因此对人类和DNNs来说都像是“噪声”。
受此启发,我们提出利用与内容相关的特征,即(人类依赖的)属性,作为触发器来设计带有干净标签的样本特定后门攻击。这种新的攻击范式被称为带有属性触发的后门攻击(BAAT)
一般来说,属性是人类用来描述和进行预测的高级特征。然而,很难对属性给出一个正式的定义,因为人类视觉系统的机制和特征的概念非常复杂且尚未明确。幸运的是,我们至少可以在图像分类任务中找到一些合适的属性,基于一些最近的研究 [29]、[59]、[60]。这里我们以两个代表性任务为例,即人脸识别和自然图像识别,描述如何利用属性触发器设计我们的攻击。
任务1:在人脸识别中设计属性触发器
人脸识别中的属性编辑 [59]、[61]、[62] 是一项经典任务,通过操纵人脸图像的预定义属性(例如发型)来修改图像,同时保留其他细节。在本文中,我们提出利用属性编辑器作为我们的中毒图像生成器 G 来设计属性触发器。我们假设数据集用户对目标身份没有领域知识,即对真实属性没有信息。具体来说,给定一个(预训练的)属性向量 a,属性编辑器 G_a :X→X 将输入图像转换为其带有属性 a 的变体。例如,a 可以是一种具有特殊颜色的特定发型。注意,攻击者应为 a 赋予一个在数据集中很少出现的值。否则,攻击可能会失败,因为具有相同属性但标签不是目标类别的样本会对学习产生拮抗作用。
任务2:在自然图像识别中设计属性触发器
如何为自然图像定义属性并不像人脸图像那样清晰。在本文中,我们提出利用特定的图像风格(例如水墨风格和卡通风格)作为属性触发器。 我们假设数据集用户对数据集的领域知识较少,因此将具有与其标签一致的语义信息的图像视为有效样本。这种假设通常成立,尤其是当数据集较大且复杂时。具体来说,给定一个攻击者指定的风格图像 s,我们分配一个(训练过的)风格转换器 T:X×X→X 作为中毒图像生成器 G,以对选定的图像进行风格化处理,用于中毒。

在本部分中,我们分析中毒率如何影响我们的BAAT。如图8所示,随着中毒率 γ 的增加,攻击成功率(ASR)也随之增加。特别是,通过仅对目标类别的60%训练样本进行中毒 (即在VGGFace2上 γ=3%,在ImageNet上 γ=0.6%),我们的BAAT在两个数据集上均达到了较高的ASR(>50%)。此外,随着 γ 的增加,正常准确率(BA)会降低,尽管下降速度相对较慢。换句话说,ASR和BA之间在一定程度上存在权衡。因此,攻击者应根据其具体需求来确定 γ 的值。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)