
强化学习强强联合推理和工具调用能力
(1)强化学习好就好在仅需要知道最终答案就可以训练了,而不需要精心准备类似sft那些需要中间推理结果的数据,所以当你只有正确答案而没有中间结果时,强化学习不失为一个好的手段,当然也有人说可以蒸馏中间更大模型的推理结果进行sft,或者本身已经有了中间结果的sft数据,那这个时候是该sft还是强化学习呢?这个笔者也没有定论,业界一般认为后者学出来的泛化性会高一些,前者学习的效率会更高,但最终哪个好,还
前言
大模型依靠自身学到的固有知识以及强大的推理能力已经能干很多事。但是有些领域依然干不好比如数学题算不准,甚至仅仅依靠自己的话有些事压根就干不了比如定机票等等。
于是就有了另外一个研究领域即挂“外挂”:rag也好、function calling也罢其实都是这个思路。依靠和这些外挂的各种多次交互就可以完成很多额外的工作。
那么如何和这些外挂无缝交互呢?那必然需要一套协议,譬如最近大家谈到的MCP等等都是在做各种层面的交互协议设计。本篇想要介绍的不仅仅是协议,而是从模型的能力来看,怎么样让其在协议的基础上能自动规划好调用,以达到真真的落地。换言之仅仅有了协议还不够,模型要能在其基础上真真实践自主规划完成任务才行。
自deepseek的R1模型大火之后,基于最终结果奖励的GRPO算法效果得以验证,其思路大道至简即不需要过多的中间监督数据(实际上很多时候也难以获取),而是仅仅以结果为导向进行强化学习即可也即知道最终正确答案就行,中间的推理过程让模型自己去通过强化学习探索。
今天我们要介绍的这篇paper就是将强化学习应用到“外挂”这个领域。
论文链接:https://arxiv.org/pdf/2505.01441
方法
其核心思路就是:各自做各自擅长的事。
大模型擅长做推理等生成任务,但是不擅长做具体的精确计算、甚至做不了定机票这件事。那么我们就分开:大模型只做推理规划,后面这些交由相关的外挂来做。
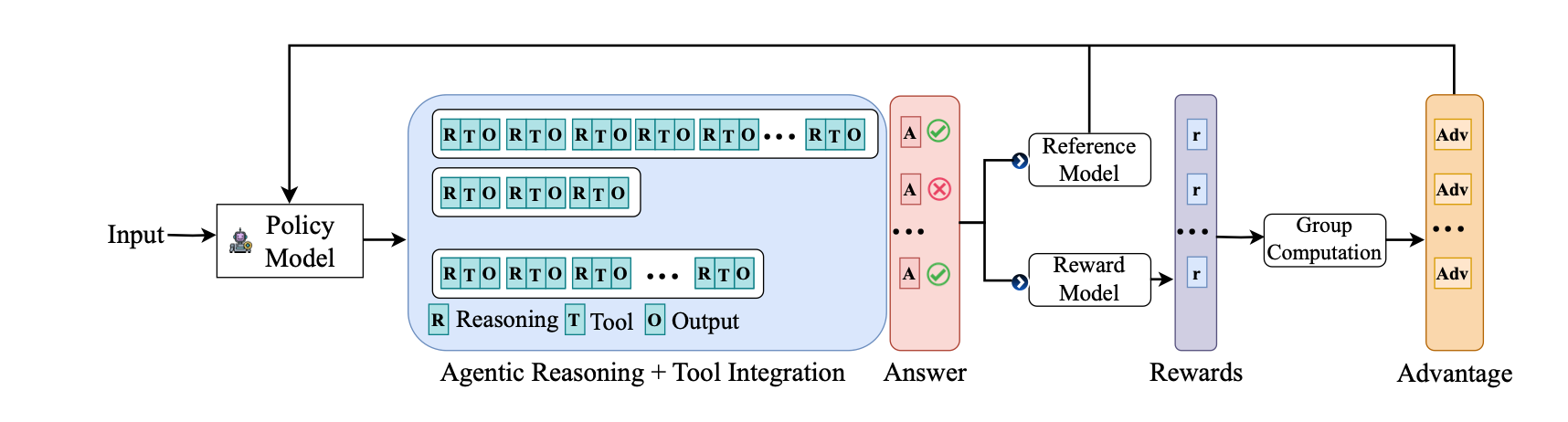
上面这张图是标准的deepseek中应用的GRPO算法流程图,
如果大家不熟悉可以穿梭笔者之前的两篇关于deepseek的文章。
《deepseek系列学习》:https://zhuanlan.zhihu.com/p/20785384624
《一个demo来手把手复现DeepSeek R1》:https://zhuanlan.zhihu.com/p/22797726638
我们接着来看本篇paper重点提出的部分即图中的RTO部分。
为了便于理解笔者先举个简单例子:假设我们现在要算一下1+2=?这到题
R就是Reasoning即推理部分,他大概形式就是:我们要调用计算器算1+2得到答案。
T就是要调用的具体外挂,主要包括外挂的名字和当前要调用的配套参数,他大概形式就是:calculator(a=1, b=2, opts=‘+’)
O就是外挂的返回,他大概形式就是:3
上面只是一个简单的问题,在实际过程中可能需要协调调用多种工具,分多步来完整比如给某人发一个文件邮件,可能需要先后调用文件查找、文件打包、邮件发送等多个外挂api才能完成最终的任务。所以可以看到上图的每一条轨迹都是由若干个RTO小组串连的,最终得到一个完整的答案A。
Prompt Template
这部分就是介绍模版或者说协议,具体来说由四部分组成:
(1) internal reasoning:也即大模型负责的推理部分类似上述的R。可以用类似< think >、< /think >等tag pair 来隔离。
(2) tool or environment queries:该部分也是由大模型生成的,具体表现为要调用的外挂名以及参数,可以用类似 < tool_name >、< /tool_name >等tag pair来隔离。
(3) tool outputs:该部分就是对应外挂的实际反馈内容, 可以用类似 < output >、< /output >等tag pair来隔离。
(4) the final answer:该部分就是最终得到的答案了。可以用类似 < answer >、< /answer >等tag pair来隔离。
可以看到其实就是预设一些占位符(随便起名字)来隔离不同模块,大模型先推理,然后调用相关外挂得到相应的知识辅助,进而再进行下一步的规划即(1)(2)(3)可重复多次,直到最终得到(4)停止。下面是论文给出的两个具体prompt(一个for 数学,一个for function calling)


是不是很简单?为了进一步理解,我们来一起看下paper附录给出的几个例子来实际看看具体是咋规划推理的?
- 例子一
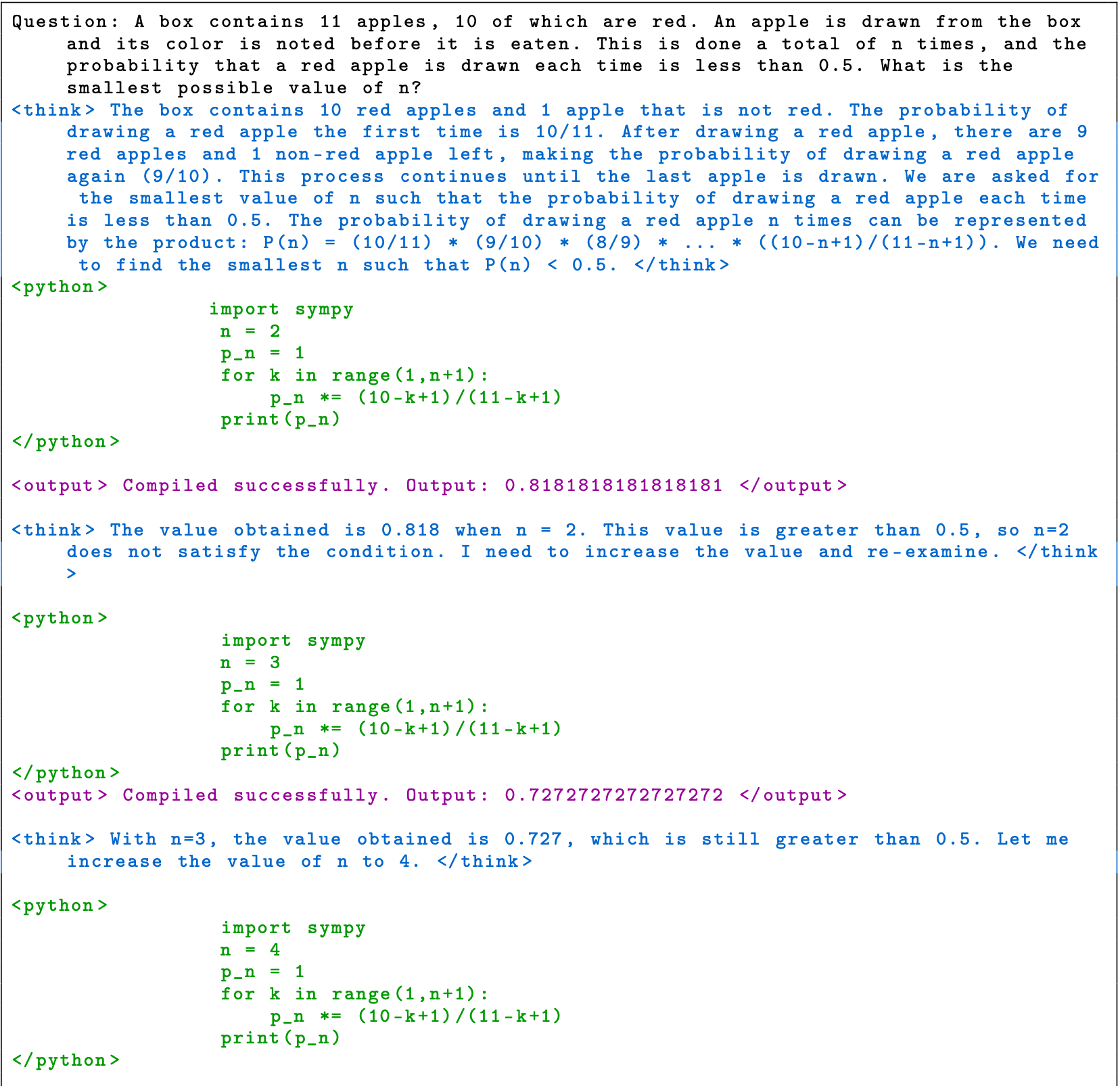


这是一道概率论的数学题,题目是:一个盒子里有11个苹果,其中10个是红色的。从盒子里每次只能取出一个苹果,这个过程一共进行n次,如果要求每次取出都是红色苹果的概率要小于0.5,那n的最小可能值是多少?
我们可以看到< think >部分的思考过程:第一次取的概率是10/11,第二次是9/10,第三次8/9,…即P(n) = (10/11) * (9/10) * (8/9) * … * ((10-n+1)/(11-n+1))。那么现在要P(n) < 0.5,问n最小是多少?怎么办呢?模型自己想到的思路很简单:从最小的开始试!
于是可以看到第一次的< python >是调用python这个外挂去算当n=2时P(n)的值得到的是< output >中的0.8181818181818181。
新一轮的< think >发现不满足,于是开始尝试n=3,发现还是不满足,一直试到了最后的n=6发现满足。于是在最后的< answer >给出了最终打答案。
- 例子二
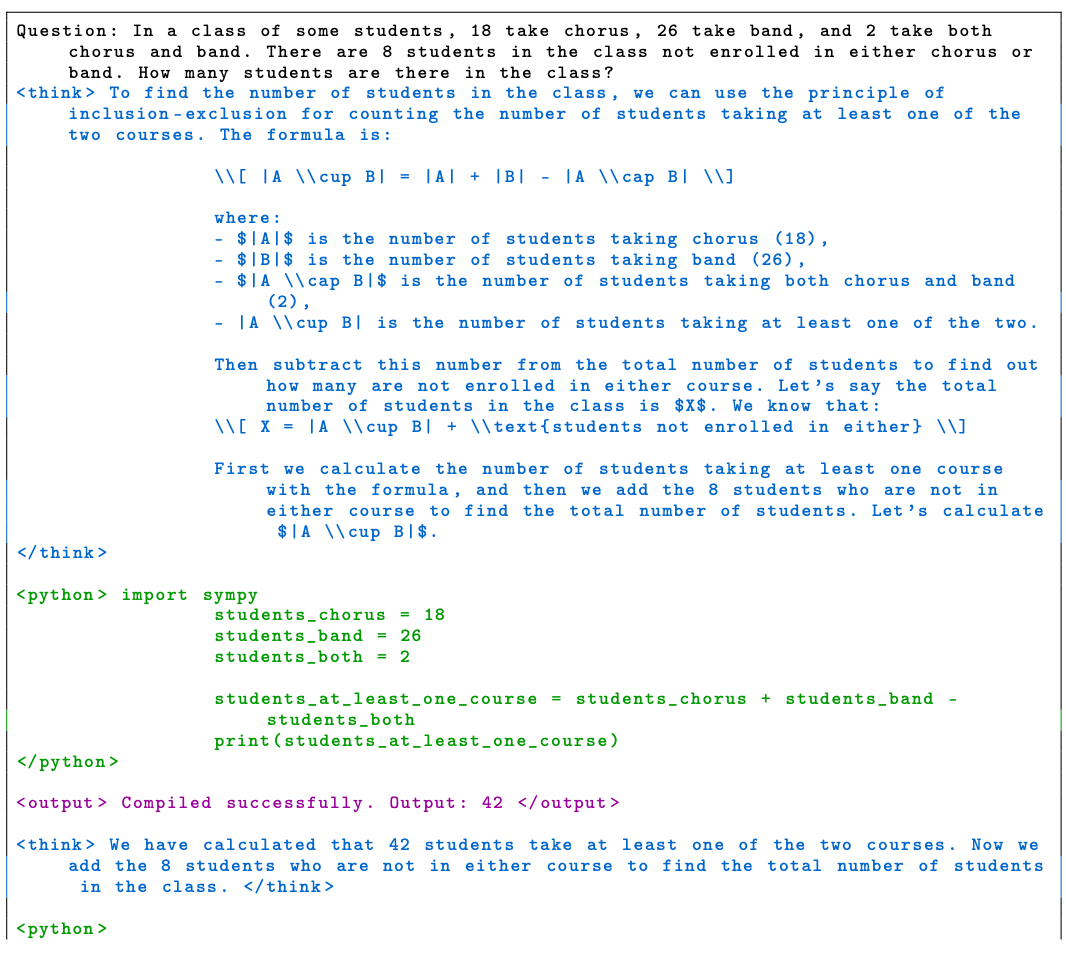

这也是一道数学题,至于解题思路我们就不解释了,我们重点看另外两个有意思的点:
第一个是我们看第三次的< think >和< python >部分,在第二次的< output >时候调用python 运行后程序出错了:< output > Compilation error: ERROR: name ’students_at_least_one_course ’ is not defined < /output >。因为第二次的< python >程序写错了,没有声明students_at_least_one_course这个变量。所以在第三次的< think >和< python >模型重新规划了正确的程序重新进行尝试。
第二个是最后一次的< think >和< python >其和倒数第二次的< think >和< python >一样,相当于其进行了两次验证,确保最终的结果一样,才给出最终答案。
- 例子三


这是一个自动驾驶function calling的例子,具体来说是用户希望模型能够辅助其锁好剩余的车门,并以“启动”模式启动车。
可以看到模型第一次< reasoning >(类似< think >)是调用< tool > lockDoors关门,在得到外挂的< tool_result >(类似< output >)反馈后,又开始< tool > 的startEngine外挂启动车,得到的外挂反馈< tool_result >是失败,因为启动车时需要先踩下制动踏板,这时模型又开始新一轮的调用< tool > pressBrakePeda接口进行踩制动踏板,得到< tool_result >的Succeeded后,再次开始< tool > 的startEngine外挂启动车并成功。
在经过上面一些列交互得到最终成功后,给出最终成功的信号< TASK_FINISHED >,并停止规划。
文章还有很多例子比如定机票再取消等等,大家感兴趣的可以去附录看看,这里不再累述。
Reinforcement Learning Algorithm
GRPO的经典算法原理这里不再累述,大家网上一查便知,说起来也简单,流程图如下
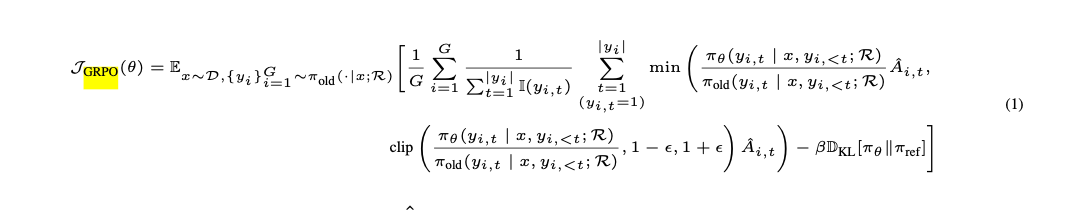

在GRPO里面,最最重要的是奖励函数(其实在所有的强化学习流派里面,这都是最重要的),直接决定了模型优化方向。
而不同领域要想用好强化学习来优化自己,那就得好好精心设计适合自己当前的奖励函数。deeepseek给出的两个大方面:一个是本身的准确率,另外一个就是格式换句话说就是上面介绍的协议(再直白点就是那些tag)。而本文也针对性的给出了一些奖励函数设计,下面我们来一起看看。
总结来说有三大类:
(1)Answer Reward:这个没啥可说的,就是< answer >…< /answer >中的最终答案对不对,对了就给奖励,不对就不给。
(2)Format Reward:就是那些设计的tag对不对,比如是不是都成pair对,是不是按照reasoning (< think >), tool call (< tool_name >), and tool output (< output >)这样的顺序输出。
(3)Tool Execution Reward:在调用外挂的时候,有时候模型生成的参数不对等情况进而导致调用外挂错误,这个时候要加惩罚,所以这里会有一个看外挂调用成功率的奖励来约束
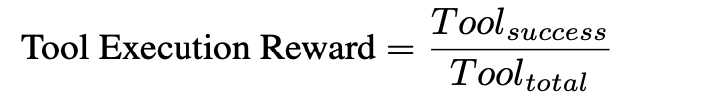
具体是多少分的奖励,可以专门尝试设计,文章也可了一些例子可以参考(1)这里

Case Study
便于理解,笔者将这部分的例子在前面已经给大家讲解过了,从那些例子中大家可以看到模型展现出了
(1)Self-Refinement:自我完善能力即会根据不断变化的需求、用户说明或环境反馈逐步更新其计划。
(2)Self-Correction:自我纠正能力即当遇到工具执行错误、未满足的先决条件或错误的假设时,模型会及时查看原因、执行纠正措施并重试且无需外部干预。
(3)Self-Reflection:自我反思能力即在每个阶段模型都会阐明其推理,总结当前状态,与用户确认细节等等
需要强调的是,这些能力的涌现是不需要专门的监督数据来sft训练的,都是通过强化学习其自己探索出来的。
实验结果
接下来就是看一些定量的实验效果了即各种benchmark上的结果。笔者这里放几个,更多的大家感兴趣可以去看原论文
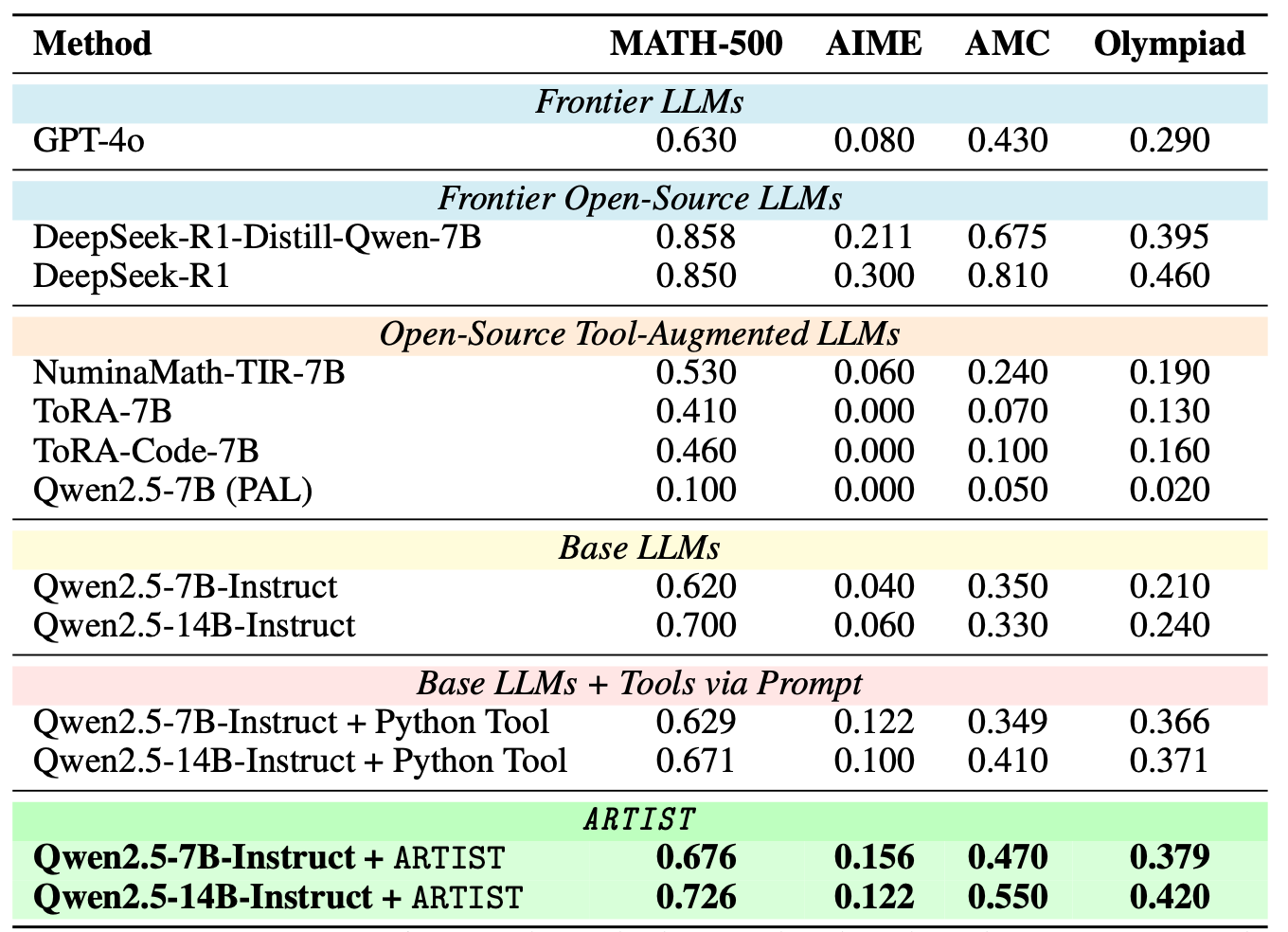
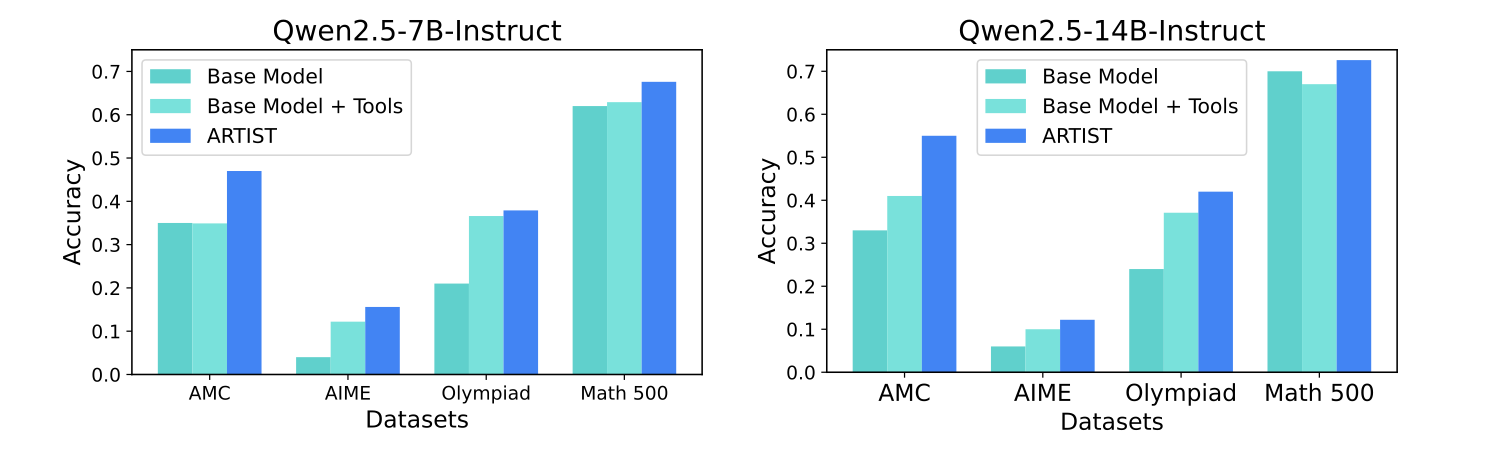
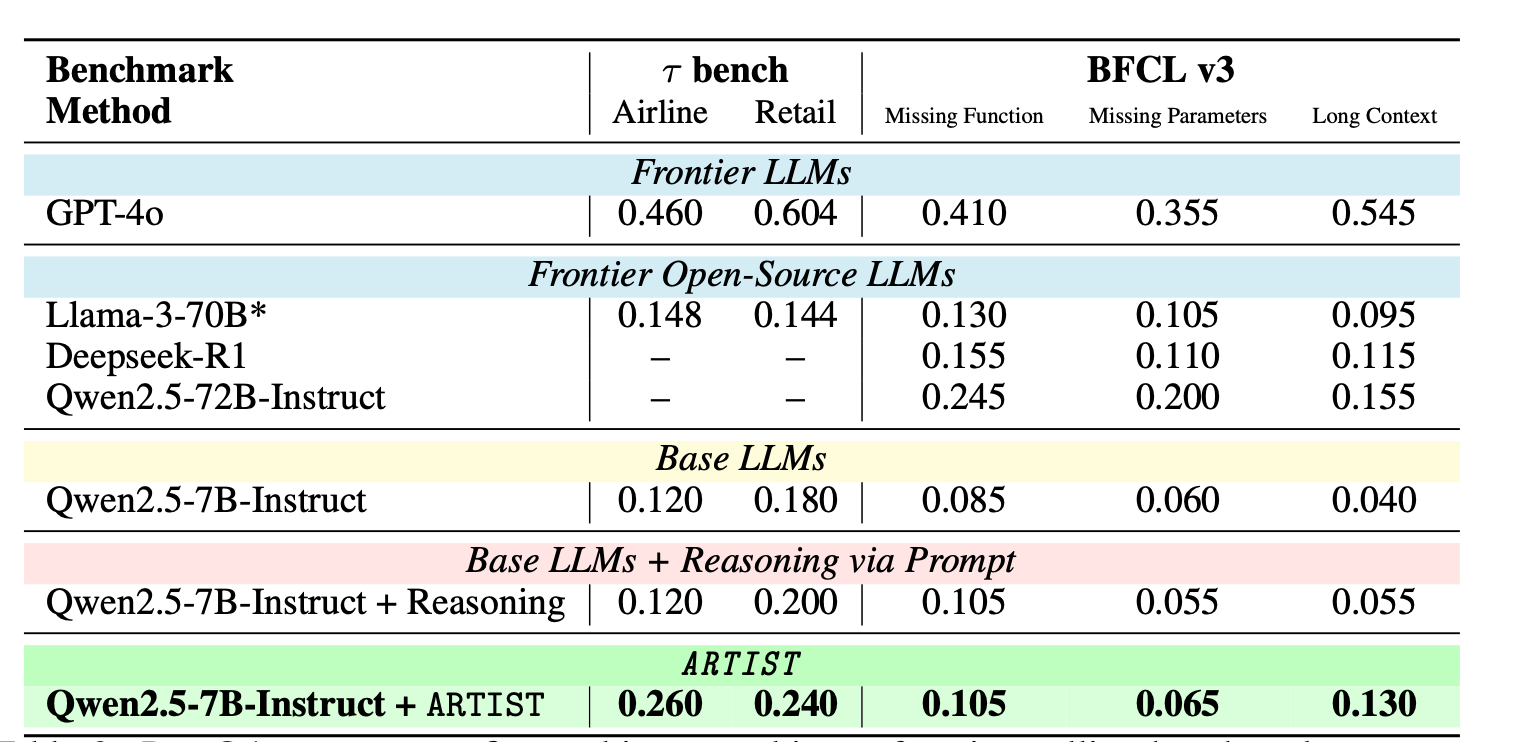
Base LLMs + Tools via Prompt是在原模型基础上不进行强化学习,只通过上面介绍的那套协议进行。ARTIST就是本篇介绍的通过强化学习后的模型。
总结
(1)强化学习好就好在仅需要知道最终答案就可以训练了,而不需要精心准备类似sft那些需要中间推理结果的数据,所以当你只有正确答案而没有中间结果时,强化学习不失为一个好的手段,当然也有人说可以蒸馏中间更大模型的推理结果进行sft,或者本身已经有了中间结果的sft数据,那这个时候是该sft还是强化学习呢?这个笔者也没有定论,业界一般认为后者学出来的泛化性会高一些,前者学习的效率会更高,但最终哪个好,还需在你自己的领域实际试一试
(2)强化学习最难的点其实是奖励函数,像数学题那样有明确唯一的答案比较好训练,但是大部分领域比如写作是没有明确好坏信号的,这个时候怎么办?有些解决方案是训练一个非规则的模型来打分,但说实话训练奖励函数不也得需要训练数据,哪里来呢?所以真真难得的是定义清晰可落地的好坏标准。这个目前看起来是比较困难的。
(3)本篇将外挂引入了大模型一起来做agent,这个从大模型诞生就有人在做,并不是什么新鲜事,而我们能从这里学习思考的是如何将自己领域的东西通过一套协议串起来这个是比较重要的。
关注笔者

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)