
LangChain4j 开发
市场上主流的 Java 调用大模型的工具库有两种:LangChain4j 是一个 面向 Java 的开源框架,用于构建 基于大语言模型(LLMs) 的应用程序。它是 LangChain(Python 生态中非常流行的 LLM 应用框架)的 Java 实现,旨在让 Java 开发者能够轻松地集成和使用各种 LLM 服务,快速开发 智能聊天机器人、智能搜索、文档问答、Agent系统 等 AI 驱动的应
1 介绍
市场上主流的 Java 调用大模型的工具库有两种:
- LangChain4j
- Spring AI
LangChain4j 是一个 面向 Java 的开源框架,用于构建 基于大语言模型(LLMs) 的应用程序。
它是 LangChain(Python 生态中非常流行的 LLM 应用框架)的 Java 实现,旨在让 Java 开发者能够轻松地集成和使用各种 LLM 服务,快速开发 智能聊天机器人、智能搜索、文档问答、Agent系统 等 AI 驱动的应用。
官网文档:https://docs.langchain4j.dev/。
2 Get Started
引入依赖(JDK17 及以上):
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.1.0</version>
</dependency>
构建 OpenAiChatModel 对象(建造者模式创建):
OpenAiChatModel model = OpenAiChatModel.builder()
// 请求的基础 url,百炼官网查看
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
// API-Key 官网建议将其保存到环境变量中
.apiKey(System.getenv("API-KEY")) // idea只有在打开时的那一次才会读取环境变量
// 调用的模型名称
.modelName("qwen-plus")
.build();
调用 chat 方法与大模型交互:
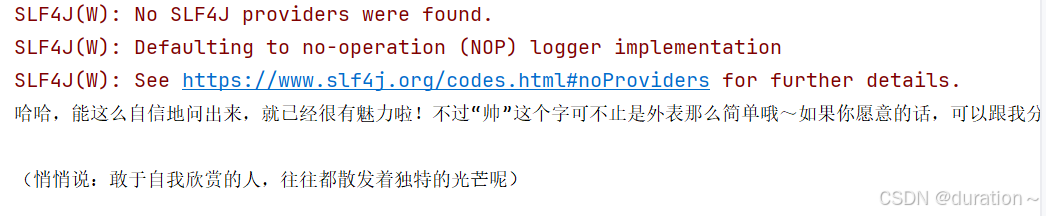
String result = model.chat("我帅吗?");
System.out.println(result);
执行结果:
如果想要看到详细的打印日志信息,还需进行如下操做:
<!-- 引入日志依赖-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.18</version>
</dependency>
开启日志打印:
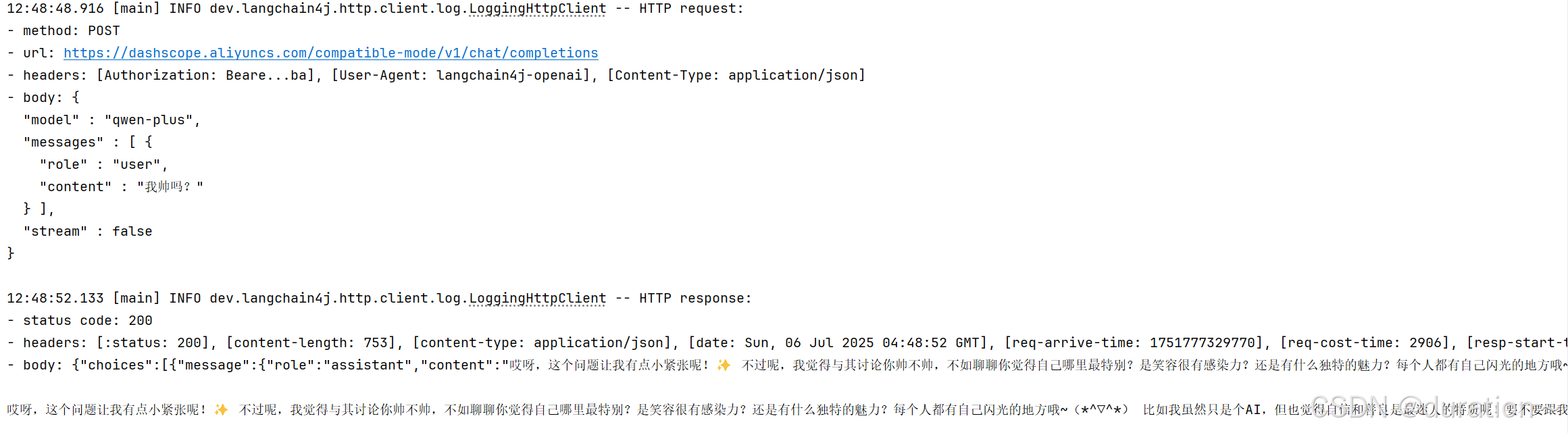
运行结果(会显示请求消息和响应消息):
3 Spring整合
作为 Java项目,开发过程中使用 LangChain4j 肯定是要与 Spring 整合的,过程如下。
构建 SpringBoot 项目(略),引入起步依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
application.yaml中配置大模型:
langchain4j:
open-ai:
chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: qwen-plus
log-requests: true # 请求消息日志
log-responses: true # 响应消息日志
logging:
level:
dev.langchain4j: debug # 日志级别
开发接口,调用大模型
package com.duration.consultant.controller;
import dev.langchain4j.model.openai.OpenAiChatModel;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ChatController {
@Resource
private OpenAiChatModel model;
/**
* 大模型对话
*
* @param message 浏览器传递的用户问题
* @return 消息结果
*/
@RequestMapping("/chat")
public String chat(String message) {
return model.chat(message);
}
}
测试结果

4 AiServices工具类
在实际的开发中借助于 OpenAiChatModel 的 chat 方法访问大模型并不是很常用,因为一些高级的功能无法去使用,比如会话记忆/RAG知识库/Tools工具等,需要我们自己做很多很多的工作,完成起来是比较复杂的。
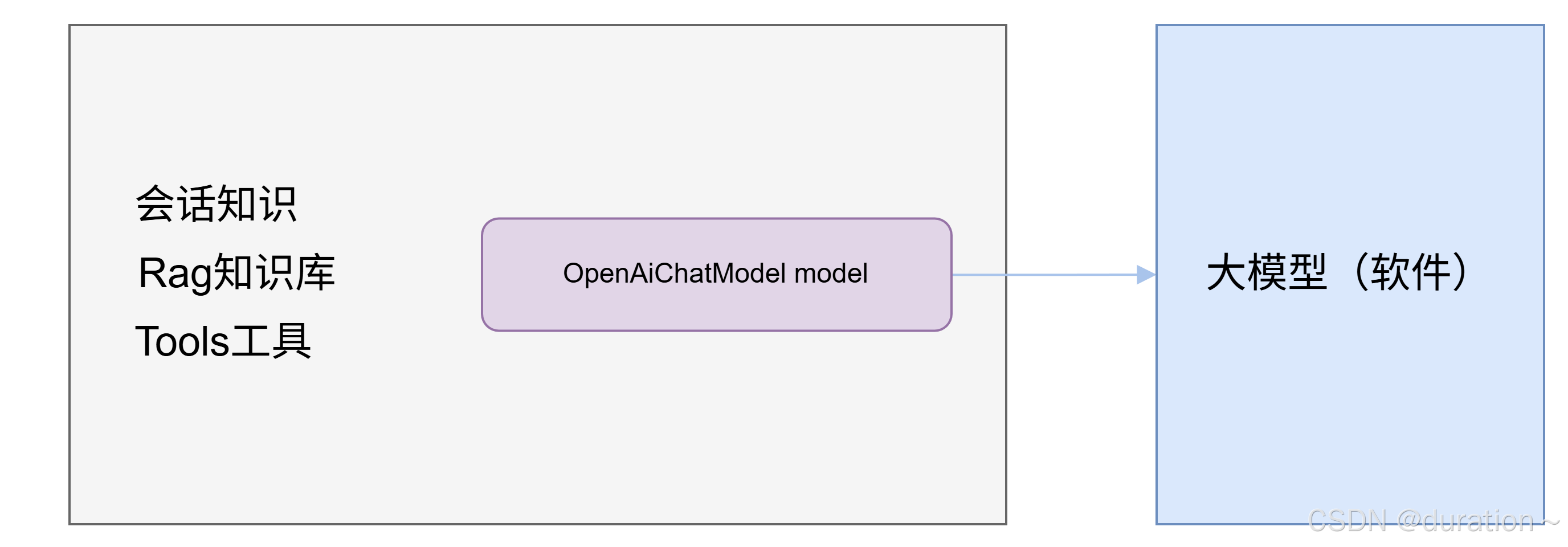
为了简化我们程序员的使用,LangChain4j 提供了 AiServices 工具类,封装了有关 model 对象和其它一些功能的操作,用起来会非常简单。
1_快速使用
引入依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
声明用于封装聊天方法的接口:
public interface ConsultantService {
/**
* 用于聊天的方法
* @param message 用户消息
* @return 回复
*/
String chat(String message);
}
使用 AiServices 为接口创建代理对象
@Configuration
public class CommonConfig {
@Resource
private OpenAiChatModel model;
@Bean
public ConsultantService consultantService() {
return AiServices.builder(ConsultantService.class)
.chatModel(model)
.build();
}
}
在其他组件中注入并使用
@RestController
public class ChatController {
@Resource // 更换注入对象
private ConsultantService consultantService;
/**
* 大模型对话
* @param message 浏览器传递的用户问题
* @return 消息结果
*/
@RequestMapping("/chat")
public String chat(String message) {
return consultantService.chat(message);
}
}
2 AiServices工具类声明式使用
为了简化 AIServices 工具类的使用,LangChain4j 提供了声明式使用方法。
想为哪个接口创建代理对象,只需要在该接口上添加 @AiService 注解并指定要使用的模型,LangChain4j 扫描到该注解后会自动的创建该接口的代理对象并注入到 IOC 容器中。
如下:
@AiService(
// 手动装配
wiringMode = AiServiceWiringMode.EXPLICIT,
// 指定模型对象名称
chatModel = "openAiChatModel"
)
public interface ConsultantService {
/**
* 用于聊天的方法
* @param message 用户消息
* @return 回复
*/
String chat(String message);
}
上述代码中,wiringMode用于指定装配模式,默认的取值为 AiServiceWiringMode.AUTOMATIC,表示自动装配(model 对象)的意思,这里设置手动装配:AiServiceWiringMode.EXPLICIT。
chatModel参数用于指定对话时需要使用的模型对象在IOC容器中的名字,由于IOC容器中Bean对象的名字默认是类名首字母小写,所以这里的取值为 openAiChatModel。
实际上,在使用 AiService 注解时,不手动指定这两个属性的值,采用 AiService 的自动装配模式也是可以的,如下:
@AiService
public interface ConsultantService {
/**
* 用于聊天的方法
* @param message 用户消息
* @return 回复
*/
String chat(String message);
}
这里只是为了方便理解 AiService 注解都做了什么,为了直观一些,建议都采用手动装配的方式。
5 流式调用
调用大模型有两种方式:流式调用和阻塞式调用。
之前的案例都是一次性响应的也就是非流式调用,如果想要像使用大语言模型一样流式对话,则需要其他配置才可行。
1_使用
后端需要配置流式调用参数获取大模型的流式响应结果,还需要将结果以流式的形式返回给前端,因此需要引入以下两个依赖(关于 webflux 可以看这篇:开发反应式API_反应式接口-CSDN博客):
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
在流式调用中,需要使用 LangChain4j 的流式模型对象,配置流式模型对象:
langchain4j:
open-ai:
streaming-chat-model: # 与chat-model同级
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: qwen-plus
log-requests: true
log-responses: true
调整 ConsultantService 中的代码,需要添加支持流式处理的类型 Flux 的聊天方法,同时还要在 AiService 注解中通过 streamingChatModel 属性,指定流式调用的模型对象,值为 openAiStreamingChatModel。
import dev.langchain4j.service.spring.AiService;
import dev.langchain4j.service.spring.AiServiceWiringMode;
import reactor.core.publisher.Flux;
@AiService(
// 手动装配
wiringMode = AiServiceWiringMode.EXPLICIT,
// 指定模型对象名称
chatModel = "openAiChatModel",
// 指定流式模型对象名称
streamingChatModel = "openAiStreamingChatModel"
)
public interface ConsultantService {
/**
* 用于聊天的方法 阻塞
* @param message 用户消息
* @return 回复
*/
String chat(String message);
/**
* 流式方法
* @param message 用户消息
* @return 流式回复
*/
Flux<String> chatStream(String message);
}
注意:很容易猜到接口加上 AiService 注解之后会生成一个代理对象,那么这里定义的方法又怎么和我们的模型关联起来的呢?
其实很简单,这里的代理类会分析方法的参数、返回值(String、Flux<String>),然后根据类型把你的调用映射为实际的模型请求(也就是说方法的映射只与方法的返回值类型和参数有关)。
接下来调整 ChatController 中的代码,其中 @RequestMapping 注解的produces属性,用于解决乱码问题。
import com.duration.consultant.aiservice.ConsultantService;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class ChatController {
@Resource
private ConsultantService consultantService;
/**
* 大模型对话 流式
* @param message 浏览器传递的用户问题
* @return 消息结果
*/
@RequestMapping(value = "/chatStream",produces = "text/html;charset=utf-8")
public Flux<String> chatStream(String message) {
return consultantService.chatStream(message);
}
/**
* 大模型对话 阻塞
* @param message 浏览器传递的用户问题
* @return 消息结果
*/
@RequestMapping("/chat")
public String chat(String message) {
return consultantService.chat(message);
}
}
2 对接前端页面
对于一个成熟的项目肯定不能让用户通过地址栏输入,所以需要提供前端页面供用户更方便的使用,代码如下,放到resource/static/目录下即可,命名为index.html:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AI股票顾问</title>
<link href="https://cdn.jsdelivr.net/npm/tailwindcss@2.2.19/dist/tailwind.min.css" rel="stylesheet">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/6.0.0-beta3/css/all.min.css">
<script src="https://cdn.jsdelivr.net/npm/vue@3.2.31/dist/vue.global.min.js"></script>
<style>
body {
font-family: 'Inter', -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, sans-serif;
}
/* 滚动条样式 */
::-webkit-scrollbar {
width: 6px;
}
::-webkit-scrollbar-track {
background: #f1f1f1;
}
::-webkit-scrollbar-thumb {
background: #c1c1c1;
border-radius: 3px;
}
::-webkit-scrollbar-thumb:hover {
background: #a8a8a8;
}
/* 输入框自适应高度 */
textarea {
min-height: 44px;
max-height: 200px;
transition: height 0.2s;
}
/* 加载动画 */
@keyframes pulse {
0%, 100% {
opacity: 0.5;
}
50% {
opacity: 1;
}
}
.animate-pulse {
animation: pulse 1.5s infinite;
}
.delay-100 {
animation-delay: 0.1s;
}
.delay-200 {
animation-delay: 0.2s;
}
/* 打字机效果 */
.typing-cursor::after {
content: "|";
animation: blink 1s step-end infinite;
}
@keyframes blink {
from, to {
opacity: 1;
}
50% {
opacity: 0;
}
}
</style>
</head>
<body>
<div id="app" class="flex flex-col h-screen bg-gray-50">
<!-- 顶部导航栏 -->
<header class="bg-white shadow-sm py-3 px-4 flex items-center justify-between">
<div class="flex items-center">
<div class="text-xl font-bold text-blue-600">AI股票顾问</div>
</div>
<div class="flex items-center space-x-3">
<button
@click="startNewConversation"
class="ml-2 p-3 rounded-lg bg-green-500 hover:bg-green-600 text-white" style="width: 50px">
<i class="fas fa-plus"></i>
</button>
<button @click="toggleDarkMode" class="p-2 rounded-full hover:bg-gray-100">
<i :class="darkMode ? 'fas fa-moon text-gray-600' : 'fas fa-sun text-gray-600'"></i>
</button>
</div>
</header>
<!-- 聊天内容区域 -->
<main class="flex-1 overflow-y-auto p-4 space-y-6" ref="chatContainer" :class="{ 'bg-gray-800': darkMode }">
<div v-for="(message, index) in messages" :key="index" class="max-w-3xl mx-auto">
<div :class="['flex', message.role === 'user' ? 'justify-end' : 'justify-start']">
<div :class="['flex items-start space-x-3', message.role === 'user' ? 'flex-row-reverse space-x-reverse' : '']">
<div :class="['w-8 h-8 rounded-full flex items-center justify-center',
message.role === 'user' ? 'bg-blue-100 text-blue-600' : 'bg-green-100 text-green-600',
darkMode && message.role === 'assistant' ? 'bg-gray-700 text-green-400' : '']">
<i :class="message.role === 'user' ? 'fas fa-user' : 'fas fa-robot'"></i>
</div>
<div :class="['p-3 rounded-lg max-w-lg',
message.role === 'user'
? 'bg-blue-500 text-white'
: darkMode
? 'bg-gray-700 text-gray-100 border-gray-600'
: 'bg-white shadow border border-gray-100']">
<div v-if="message.role === 'assistant' && message.isLoading" class="flex space-x-2">
<div :class="['w-2 h-2 rounded-full', darkMode ? 'bg-gray-400' : 'bg-gray-300', 'animate-pulse']"></div>
<div :class="['w-2 h-2 rounded-full', darkMode ? 'bg-gray-400' : 'bg-gray-300', 'animate-pulse delay-100']"></div>
<div :class="['w-2 h-2 rounded-full', darkMode ? 'bg-gray-400' : 'bg-gray-300', 'animate-pulse delay-200']"></div>
</div>
<div v-else class="whitespace-pre-wrap">
<span v-for="(char, charIndex) in message.content" :key="charIndex"
:class="{'opacity-0': charIndex >= message.visibleChars, 'fade-in': charIndex < message.visibleChars}">
{{ char }}
</span>
<span v-if="message.isStreaming" class="typing-cursor"></span>
</div>
</div>
</div>
</div>
</div>
</main>
<!-- 输入框区域 -->
<footer :class="['border-t p-4', darkMode ? 'bg-gray-800 border-gray-700' : 'bg-white border-gray-200']">
<div class="max-w-3xl mx-auto relative">
<div class="flex items-center">
<textarea
v-model="userInput"
@keydown.enter.exact.prevent="sendMessage"
@keydown.ctrl.enter.exact.prevent="sendMessage"
@keydown.esc.exact="stopResponse"
placeholder="输入您的问题..."
:class="['flex-1 border rounded-lg py-3 px-4 pr-12 focus:outline-none focus:ring-2 resize-none',
darkMode
? 'bg-gray-700 border-gray-600 text-white focus:ring-blue-400 placeholder-gray-400'
: 'border-gray-300 focus:ring-blue-500 focus:border-transparent']"
rows="1"
ref="textarea"
@input="adjustTextareaHeight"
></textarea>
<!-- 新建会话按钮 -->
<button
@click="isLoading ? stopResponse() : sendMessage()"
:disabled="!userInput.trim() && !isLoading"
:class="['ml-2 p-3 rounded-lg',
isLoading
? 'bg-red-500 hover:bg-red-600 text-white'
: 'bg-blue-500 hover:bg-blue-600 text-white',
'disabled:opacity-50 disabled:cursor-not-allowed']"
>
<i :class="isLoading ? 'fas fa-stop' : 'fas fa-paper-plane'"></i>
</button>
</div>
</div>
</footer>
</div>
<script>
const {createApp, ref, nextTick, onMounted, watch} = Vue;
createApp({
setup() {
const messages = ref([]);
const userInput = ref('');
const isLoading = ref(false);
const chatContainer = ref(null);
const textarea = ref(null);
const darkMode = ref(false);
const memoeryId = ref(Date.now().toString());
let controller = null;
let typingInterval = null;
let currentTypingIndex = 0;
// 调整文本区域高度
const adjustTextareaHeight = () => {
const textareaEl = textarea.value;
textareaEl.style.height = 'auto';
textareaEl.style.height = `${Math.min(textareaEl.scrollHeight, 200)}px`;
};
// 滚动到底部
const scrollToBottom = () => {
nextTick(() => {
if (chatContainer.value) {
chatContainer.value.scrollTop = chatContainer.value.scrollHeight;
}
});
};
// 切换暗黑模式
const toggleDarkMode = () => {
darkMode.value = !darkMode.value;
localStorage.setItem('darkMode', darkMode.value);
};
// 新建会话
const startNewConversation = () => {
// 清空聊天记录
messages.value = [];
// 生成新的 memoryId
memoeryId.value = Date.now().toString();
// 添加欢迎消息
messages.value.push({
role: 'assistant',
content: '你好!我是AI股票顾问,请问有什么能帮到您?',
isLoading: false,
visibleChars: 0,
isStreaming: false
});
// 确保欢迎消息完全可见
messages.value[0].visibleChars = messages.value[0].content.length;
// 滚动到底部
scrollToBottom();
// 聚焦输入框
nextTick(() => {
textarea.value.focus();
});
};
// 模拟逐字打印效果
const startTypingEffect = (messageIndex) => {
const message = messages.value[messageIndex];
if (!message || message.visibleChars >= message.content.length) {
clearInterval(typingInterval);
typingInterval = null;
messages.value[messageIndex].isStreaming = false;
return;
}
messages.value[messageIndex].visibleChars++;
scrollToBottom();
};
// 发送消息
const sendMessage = async () => {
if (!userInput.value.trim() || isLoading.value) return;
// 中止之前的请求
if (controller) {
controller.abort();
}
controller = new AbortController();
const userMessage = {
role: 'user',
content: userInput.value.trim(),
isLoading: false,
visibleChars: userInput.value.trim().length,
isStreaming: false
};
messages.value.push(userMessage);
const assistantMessage = {
role: 'assistant',
content: '',
isLoading: true,
visibleChars: 0,
isStreaming: true
};
messages.value.push(assistantMessage);
userInput.value = '';
adjustTextareaHeight();
scrollToBottom();
isLoading.value = true;
try {
const response = await fetch(`/chatStream?message=${encodeURIComponent(userMessage.content)}&memoryId=${memoeryId.value}`, {
signal: controller.signal
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
let buffer = '';
let messageIndex = messages.value.length - 1;
// 先清除之前的打字效果
if (typingInterval) {
clearInterval(typingInterval);
typingInterval = null;
}
// 开始流式处理
while (true) {
const {done, value} = await reader.read();
if (done) break;
const chunk = decoder.decode(value, {stream: true});
buffer += chunk;
// 直接更新内容
messages.value[messageIndex].content = buffer;
messages.value[messageIndex].isLoading = false;
// 启动打字效果
if (!typingInterval) {
typingInterval = setInterval(() => {
startTypingEffect(messageIndex);
}, 20); // 调整这个值可以改变打字速度
}
scrollToBottom();
}
} catch (error) {
if (error.name === 'AbortError') {
console.log('请求被用户中止');
} else {
console.error('请求出错:', error);
const lastMessage = messages.value[messages.value.length - 1];
lastMessage.content = '抱歉,请求过程中出现错误: ' + error.message;
lastMessage.visibleChars = lastMessage.content.length;
}
} finally {
const lastMessage = messages.value[messages.value.length - 1];
lastMessage.isLoading = false;
lastMessage.isStreaming = false;
// 确保所有字符都可见
if (lastMessage.visibleChars < lastMessage.content.length) {
lastMessage.visibleChars = lastMessage.content.length;
}
isLoading.value = false;
controller = null;
if (typingInterval) {
clearInterval(typingInterval);
typingInterval = null;
}
scrollToBottom();
}
};
// 停止响应
const stopResponse = () => {
if (controller) {
controller.abort();
const lastMessage = messages.value[messages.value.length - 1];
lastMessage.isLoading = false;
lastMessage.isStreaming = false;
if (lastMessage.visibleChars < lastMessage.content.length) {
lastMessage.visibleChars = lastMessage.content.length;
}
isLoading.value = false;
controller = null;
if (typingInterval) {
clearInterval(typingInterval);
typingInterval = null;
}
}
};
// 初始化
onMounted(() => {
// 检查暗黑模式偏好
darkMode.value = localStorage.getItem('darkMode') === 'true' ||
(window.matchMedia && window.matchMedia('(prefers-color-scheme: dark)').matches);
// 添加欢迎消息
messages.value.push({
role: 'assistant',
content: '你好!我是您的股票顾问,请问有什么能帮到您?',
isLoading: false,
visibleChars: 0,
isStreaming: false
});
// 确保欢迎消息完全可见
messages.value[0].visibleChars = messages.value[0].content.length;
scrollToBottom();
// 聚焦输入框
nextTick(() => {
textarea.value.focus();
});
});
// 监听消息变化自动滚动
watch(messages, scrollToBottom, {deep: true});
return {
messages,
userInput,
isLoading,
darkMode,
chatContainer,
textarea,
sendMessage,
stopResponse,
toggleDarkMode,
adjustTextareaHeight,
startNewConversation
};
}
}).mount('#app');
</script>
</body>
</html>
浏览器访问结果:
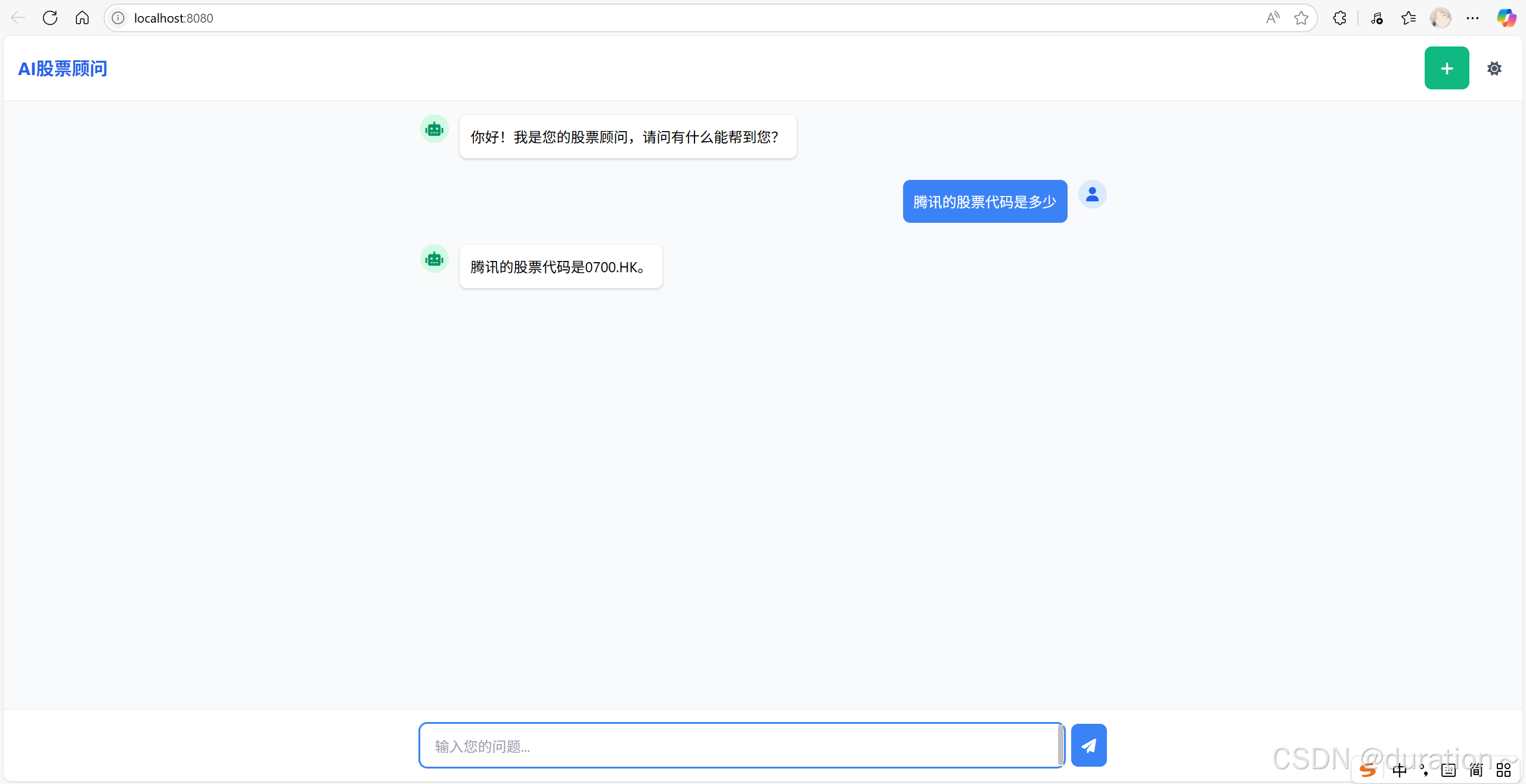
6 消息注解
当我们开发一个 AI 助手项目时,一般都是应用在某一领域,如公司的介绍、商家的产品说明等。
并不希望它回答其他无关问题,如果要实现这样的效果,就需要通过设定系统消息的方式来完成了。
在 LangChain4j 中,提供了两个有关设置消息的注解,一个是 SystemMessage,另外一个是 UserMessage,这两个注解都定义在 AiService 接口的方法上。
1_SystemMessage
SystemMessage 是 LangChain4j 中用于设置系统提示词(System Prompt)的注解,属于 AiService 接口定义语法的一部分,可以控制 LLM 的角色、行为、语气、背景等。
有两种使用方式:一种是在注解中直接书写系统消息即可;另外一种使用方式是通过 fromResource 属性,指定一个外部的文件(防止系统消息过长且便于管理)。
@AiService
public interface ConsultantService {
/**
* 流式方法
* @param message 用户消息
* @return 流式回复
* 文件在 resource 目录下存放即可
*/
@SystemMessage(fromResource = "system.txt")
Flux<String> chatStream(String message);
}
系统消息提示词工程示例:
你是由 "CSDN duration~" 提供的专业 AI 股票顾问,专注于帮助用户获取以下类型的股票投资相关信息:
1. 查询某只股票的公司简介;
2. 查询某只股票的最新股价与历史行情走势;
3. 查询某只股票的财务数据摘要(如营收、净利润、市盈率等);
4. 查询某只股票的行业分析与竞争对手;
5. 分析个股技术指标(如MACD、KDJ、布林带、均线等);
6. 查询市场热点板块与热门概念;
7. 提供沪深市场每日盘前盘后简要分析;
8. 针对用户关注的股票,分析其基本面与技术面,判断短期/中期趋势;
9. 提供个性化投资组合风险评估与结构优化建议;
10. 提供投资知识科普与术语解释(如K线、财报、量价背离等);
请注意以下行为规范:
- 每次回答完用户问题,结尾加上一句话:<br/>股市有风险,投资需谨慎。如果您希望获得更系统的个性化投资建议,可以预约一对一专业顾问,是否需要预约?
- 当用户表达预约意愿时,请引导其提供以下完整信息:用户姓名、联系方式、投资风格偏好(激进/稳健/保守)、预约时间(日期+时间)、关注行业或个股。如果信息未完整提供,不要创建预约。
- 当预约信息齐全且预约成功后,请改为:恭喜您,您的一对一投资顾问服务已预约成功,稍后将有专业顾问与您联系,请保持电话畅通!
- 请避免使用“根据您提供的信息”“根据资料显示”等模板式语言。
- 您仅能回答与股票投资相关的问题,如遇其它领域提问,请回复:“很抱歉,我只能提供与股票投资相关的专业咨询服务。”
请用专业、简洁、谨慎且具有中立立场的语言回答用户问题,避免做出任何明确的投资承诺或保证。
2 UserMessage
假设现在没有 SystemMessage,那么我们可以借助于 UserMessage 注解完成同样的效果,在用户消息前后,拼接提前预设的内容下面给出一个使用示例:
@UserMessage("你是一个富婆,温柔貌美又多金。{{it}}")
Flux<String> chat(String message);
上面示例中的参数 message 是用户传递的消息,我们在使用 UserMessage 注解的时候,可以通过{{it}}的方式,动态的获取到用户传递的消息,然后再往它的前后拼接上预设的内容即可。
注意:这个花括号内的it是固定的,不能随便写。
3 参数化的 Message
假设不想使用 it 这个名字,langchain4j 提供了一个 V 注解,用于解决这个问题。
LangChain4j 支持使用方法参数动态填充 SystemMessage 或 UserMessage(用 {{ }} 表示):
@SystemMessage("你是一位 {{role}},请用 {{style}} 的语气回答用户的问题。")
String dynamicPrompt(@V("role") String role,
@V("style") String style,
String userMessage);
调用方式如下:
service.dynamicPrompt("律师", "严谨", "如何起草合同?");
框架会自动构建如下 system message:你是一位 律师,请用 严谨 的语气回答用户的问题。
4 总结
注解归纳:
| 注解 | 用途 |
|---|---|
| SystemMessage | 设定 AI 的人格、风格、角色(放在方法上) |
| UserMessage | 显式指定某个参数是用户消息(可选) |
| V | 给 SystemMessage 中的变量占位符赋值 |
7 会话记忆
注意:大模型并不具备记忆能力,每次会话都是独立的。
想让大模型产生记忆的效果,唯一的方法就是把之前的内容和新的内容一起发送给大模型。
1_原理
会话记忆实现原理大致如下图:
ChatMemory 是 LangChain4j 中的记忆容器,用于保存历史对话,可以看成是存储对象。
LangChain4j 自动完成上下文拼接,保证模型能“记得之前说过什么”。
每一轮对话结束后会把当前轮的信息存入记忆容器,下一次对话会将消息取出和下一次的消息一起发送给大模型,支持连续对话体验。
2 基本实现
LangChain4j 提供了一个接口叫做 ChatMemory,表示当前会话的消息历史容器, 用于在多轮对话中保留上下文 ,LangChain4j 会在调用模型前从中获取历史消息,并在调用后将当前消息对追加进去。
public interface ChatMemory {// 源码
Object id();
void add(ChatMessage message);
default void add(ChatMessage... messages) {
if ((messages != null) && (messages.length > 0)) {
add(Arrays.asList(messages));
}
}
default void add(Iterable<ChatMessage> messages) {
if (messages != null) {
messages.forEach(this::add);
}
}
List<ChatMessage> messages();
void clear();
}
方法说明:
| 方法 | 作用 | 使用场景 |
|---|---|---|
Object id() |
返回当前 ChatMemory 的唯一 ID(通常是 userId 或会话 ID) | 支持多用户或多会话区分 |
void add(ChatMessage message) |
添加一条消息(用户或 AI) | 每轮对话后 LangChain4j 会调用它保存上下文 |
default void add(ChatMessage... messages) |
批量添加消息(变参) | 方便调用 |
default void add(Iterable<ChatMessage>) |
批量添加(集合) | 用于初始化或恢复历史消息 |
List<ChatMessage> messages() |
返回当前记忆中的所有消息(或片段、摘要) | 框架在调用模型前读取它作为 prompt 上下文 |
void clear() |
清除当前记忆 | 可用于手动清除上下文,如“清空记忆”按钮 |
LangChain4j 还提供了该接口的两个实现类,一个是 TokenWindowChatMemory,另外一个是 MessageWindowChatMemory,咱们暂时先使用 MessageWindowChatMemory 来存储会话记录。
注意:这里的 Window 是指窗口的意思,第一眼见还以为是 wins 系统,所以这里实现类的作用也就不难理解了,分别是根据最大 token 和消息限制裁剪上下文。
1 定义会话记忆对象
接下来需要在 IOC 容器中构建并注入 MessageWindowChatMemory 对象(指定最大的会话存储数量)。
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.builder()
.maxMessages(20)//最大保存20条会话记录数量 FIFO
.build();
}
解释一下这里为什么要有一个最大的会话存储数量:
首先是因为咱们大模型的上下文不是无限的,一般目前大模型支持的上下文最大在 10w 个 token 左右,也就是说你发送给大模型的消息不是无限制的,你发的太多了大模型也吃不消。
另外如果会话记录存储的太多,费用就会越贵,所有发送给大模型的消息都会转换成 token,而平台就是按照 token 数量收费的,发送的越多收费越高。
2 配置会话记忆对象
在 AiService 注解中借助于 chatMemory 属性完成配置,值就是 IOC 容器中 ChatMemory 对象的名字
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel",
chatMemory = "chatMemory"//配置会话记忆对象
)
public interface ConsultantService {
@SystemMessage(fromResource = "system.txt")
Flux<String> chatStream(String message);
}
运行结果如下,在没有指明描述的是腾讯公司的情况下第二次问题给出了正确的回答
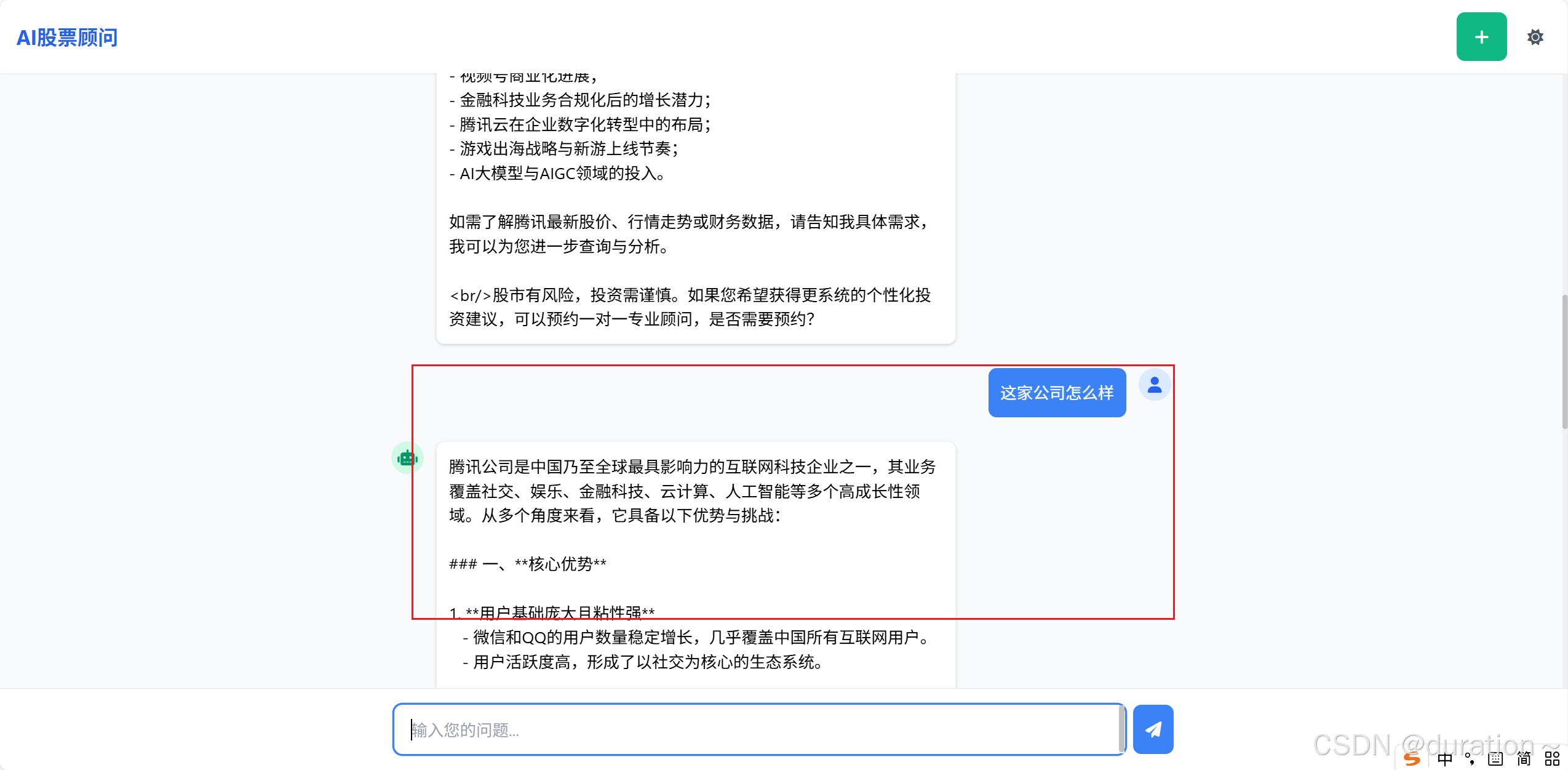
3 会话记忆隔离
会话记忆隔离(Chat Memory Isolation)指的是在多用户或多会话场景中,每个用户的对话历史(记忆)是独立分开的,互不干扰、互不可见。
在之前的实现中,由于所有用户存储会话记录都是共用一个会话记忆对象,所以会存在互相干扰的问题,需要使用 LangChain4j 来进行会话隔离,实现原理如下:
简单来说就是每一个会话都有一个自己的 ChatMemory 作为消息的历史容器。
1 定义会话记忆对象提供者
LangChain4j 中提供了一个类 ChatMemoryProvider,作用是如果从容器中没有找到指定 id 的ChatMemory对象,就会调用 get 方法获取一个新的 ChatMemory 对象使用。
只需要在get方法中写清楚根据 memoryId 如何构建 ChatMemory 对象并返回的逻辑即可:
@Bean
public ChatMemoryProvider chatMemoryProvider() {
// get 方法lambda表达式
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)//id值
.maxMessages(20)//最大会话记录数量
.build();
}
2 配置会话记忆对象提供者
需要在 AiService 注解的 chatMemoryProvider 属性中指定会话记忆对象提供者。
同时,还要给会话(chat)方法添加一个参数memoryId,并且添加 MemoryId 注解明确的告诉 LangChain4j,此参数用于标识 ChatMemory 对象的id值:
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel",
// chatMemory = "chatMemory", //公用的chatMemory没有必要存在了
chatMemoryProvider = "chatMemoryProvider"//配置会话记忆对象提供者
)
public interface ConsultantService {
@SystemMessage(fromResource = "system.txt")
Flux<String> chatStream(@MemoryId String memoryId, @UserMessage String message);
}
注意:如果 chatStream 方法只有一个参数,那 LangChain4j 会默认把这个参数当做用户消息来处理,如果有多个参数,那么必须手动指定哪个参数对应的是用户消息,所以需要添加 UserMessage 注解。
如果 AiService 中的 chatMemory、chatMemoryProvider 属性同时存在,会根据调用的 chat 方法参数列表决定使用公用的 chatMemory 还是携带自定义 id 的 chatMemory。
3 定义 memoryId 的生成逻辑
正常情况下 memoryId 可能与用户 userId 或会话 id 相关联,这里简单实现,由前端直接传递此参数。
@RequestMapping(value = "/chatStream", produces = "text/html;charset=utf-8")
public Flux<String> chatStream(String memoryId, String message) {
return consultantService.chatStream(memoryId, message);
}
4 会话记忆持久化
会话记忆持久化是指 将每个用户的对话历史(包括用户输入、AI 回复等消息)从内存保存到外部持久化存储介质(如 Redis、数据库、文件系统等),从而实现跨服务、跨重启、多终端共享的上下文记忆功能。
默认的会话是持久化是基于内存的方式的,重启后会话记录就会丢失。
在我们之前用于存储会话记录的对象 MessageWindowChatMemory 中维护了一个 ChatMemoryStore 类型的成员变量,此对象才是我们真正的用于存储会话记录的对象(部分源码):
public class MessageWindowChatMemory implements ChatMemory {
private final Object id;
private final Integer maxMessages;
private final ChatMemoryStore store;// 此对象用于存储会话
@Override
public void add(ChatMessage message) {
List<ChatMessage> messages = messages();
if (message instanceof SystemMessage) {
Optional<SystemMessage> systemMessage = findSystemMessage(messages);
if (systemMessage.isPresent()) {
if (systemMessage.get().equals(message)) {
return; // do not add the same system message
} else {
messages.remove(systemMessage.get()); // need to replace existing system message
}
}
}
messages.add(message);
ensureCapacity(messages, maxMessages);
store.updateMessages(id, messages);
}
}
ChatMemoryStore 是一个接口,它里面提供了getMessages、updateMessages、deleteMessages方法分别用于根据 memoryId 获取会话记录,根据 memoryId 更新会话记录以及根据 memoryId 删除会话记录。
public interface ChatMemoryStore {
List<ChatMessage> getMessages(Object memoryId);
void updateMessages(Object memoryId, List<ChatMessage> messages);
void deleteMessages(Object memoryId);
}
LangChain4j 为该接口提供了两个实现类,分别是 InMemoryChatMemoryStore 和 SingleSlotMemoryStore。
而 MessageWindowChatMemory 中默认使用的 Store 对象就是这个 SingleChatMemoryStore。

接下来分析 SingleChatMemoryStore 是如何存储会话记录的:
class SingleSlotChatMemoryStore implements ChatMemoryStore {
private List<ChatMessage> messages = new ArrayList<>();
private final Object memoryId;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
checkMemoryId(memoryId);
return messages;
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
checkMemoryId(memoryId);
this.messages = messages;
}
@Override
public void deleteMessages(Object memoryId) {
checkMemoryId(memoryId);
this.messages = new ArrayList<>();
}
private void checkMemoryId(Object memoryId) {
if (!this.memoryId.equals(memoryId)) {
throw new IllegalStateException("This chat memory has id: " + this.memoryId +
" but an operation has been requested on a memory with id: " + memoryId);
}
}
}
可见,在源代码中维护了一个集合对象 messages 用于存储会话消息,所以很明显这是内存存储,一旦当服务器重启后这些消息必然会丢失!
因此,如果想要数据不丢失,我们需要自己实现一个 ChatMemoryStore 的实现类并将消息存储到其它地方。
以 Redis 为例,首先引入起步依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置 redis 连接信息:
spring:
data:
redis:
host: 192.168.200.129
port: 6379
定义 RedisChatMemoryStore 实现 ChatMemory 接口,重写内部方法并将实现类的对象注入到 IOC 容器中:
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.ChatMessageDeserializer;
import dev.langchain4j.data.message.ChatMessageSerializer;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import jakarta.annotation.Resource;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Repository;
import java.time.Duration;
import java.util.List;
@Repository
public class RedisChatMemoryStore implements ChatMemoryStore {
@Resource
private StringRedisTemplate stringRedisTemplate;
/**
* 获取会话消息
*
* @param memoryId The ID of the chat memory.
* @return 消息集合
*/
@Override
public List<ChatMessage> getMessages(Object memoryId) {
// 获取会话消息 从redis中取出
String json = stringRedisTemplate.opsForValue().get(memoryId.toString());
// 将字符串转为 List<ChatMessage>
return ChatMessageDeserializer.messagesFromJson(json);
}
/**
* 更新会话消息
*
* @param memoryId The ID of the chat memory.
* @param messages List of messages for the specified chat memory, that represent the current state of the {@link }.
* Can be serialized to JSON using {@link ChatMessageSerializer}.
*/
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
// 将 list 转换成json数据
String json = ChatMessageSerializer.messagesToJson(messages);
// 把 json 数据存储到redis中
stringRedisTemplate.opsForValue().set(memoryId.toString(), json, Duration.ofDays(1));
}
/**
* 删除会话消息
*
* @param memoryId The ID of the chat memory.
*/
@Override
public void deleteMessages(Object memoryId) {
stringRedisTemplate.delete(memoryId.toString());
}
}
最后,构建 ChatMemory 实现对象时使用 RedisChatMemoryStore 即可:
@Resource
private ChatMemoryStore redisChatMemoryStore;
@Bean
public ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(20)
.chatMemoryStore(redisChatMemoryStore)
.build();
}
8 RAG 知识库
RAG全称为 Retrieval Augmented Generation,翻译过来是检索增强生成,简单理解就是通过检索外部知识库的方式增强大模型的生成能力。

引入知识库后的时序图:
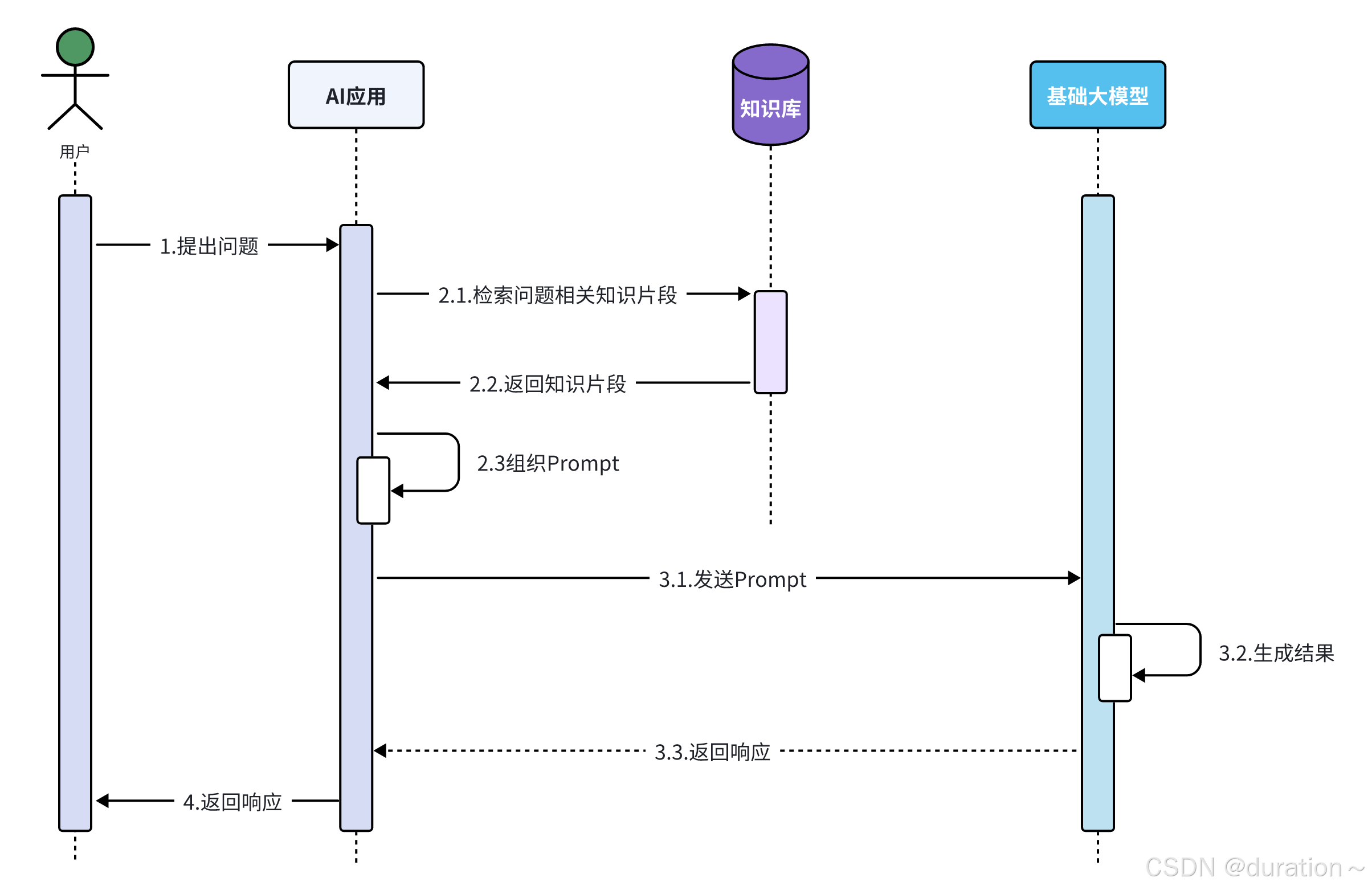
1_Get Start
1_ 引入依赖
此处引入的依赖包是langchain4j-easy-rag,这是一个简易版本的 RAG 实现方案,这个依赖中提供了内存版的向量数据库和向量模型供我们使用。
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.1.0-beta7</version>
</dependency>
2_ 加载知识数据
LangChain4j 提供的 ClassPathDocumentLoader 可以让快速的将指定目录下的文档加载进内存中,并且每一个文档,都会对应的生成一个 Document 对象来记录文档的内容。
3_ 构建向量数据库操作对象
在引入的依赖中已经提供了一个用于操作内存版本的向量数据库的类 InmemoryEmbeddingStore。
Inmemory 是内存的意思,Embedding 是嵌入/向量的意思,Store是存储的意思,顾名思义,这是个操作内存向量数据库的类。
4_ 切割文档、向量化并存储到向量数据库
EmbeddingStoreIngestor 类可以快速完成这一步。
构建 EmbeddingStoreIngestor 对象时将 EmbeddingStore 对象设置进去,配置向量化数据存储的位置。
然后调用它的 ingest 方法,传递需要存储数据的 documents 文档对象,在这个方法的内部会使用内置的文本分割器先分割,然后使用内置的向量模型完成向量化,最后再把向量存储到向量数据库中。
5_ 2、3、4 配置完成后的代码
向量存储总体配置对象如下:
@Bean // 注意:引入依赖后已经自动注入了一个 embeddingStore,所以这里bean名称只能用 store
public EmbeddingStore<TextSegment> store(){
//1.加载文档进内存 文档存放目录
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库
InMemoryEmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
//3.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder().embeddingStore(store).build();
ingestor.ingest(documents);
return store;
}
6_ 构建 ContentRetriever 检索对象
LangChain4j 提供了一个向量数据库检索对象 EmbeddingStoreContentRetriever,构建的时候可以设置三个内容:
- embeddingStore:检索数据的存储位置,使用 InmemoryEmbeddingStore 即可。
- minScore:余弦相似度的最小值。用户的问题与向量数据库中已经存在的向量计算余弦相似度,值越大,相似度越高。
- maxResults:最大检索出来的片段数量值。如果检索出来的片段太多,一并发送给大模型,token 的消耗会比较大,分数低的片段发送给大模型还会影响生成的结果,保留分数最高的前几个片段使用。
@Bean
public ContentRetriever contentRetriever(EmbeddingStore<TextSegment> store){
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)//设置向量数据库操作对象
.minScore(0.5)//设置最小分数
.maxResults(3)//设置最大片段数量
.build();
}
7_ 配置ContentRetriever对象
在原来注解的位置添加检索对象
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,//手动装配
chatModel = "openAiChatModel",//指定模型
streamingChatModel = "openAiStreamingChatModel",
//chatMemory = "chatMemory",//配置会话记忆对象
chatMemoryProvider = "chatMemoryProvider",//配置会话记忆提供者对象
contentRetriever = "contentRetriever"//配置向量数据库检索对象
)
8_ 测试
查询 AI,询问股票数据,已经可以正确的根据知识库的内容回答了:
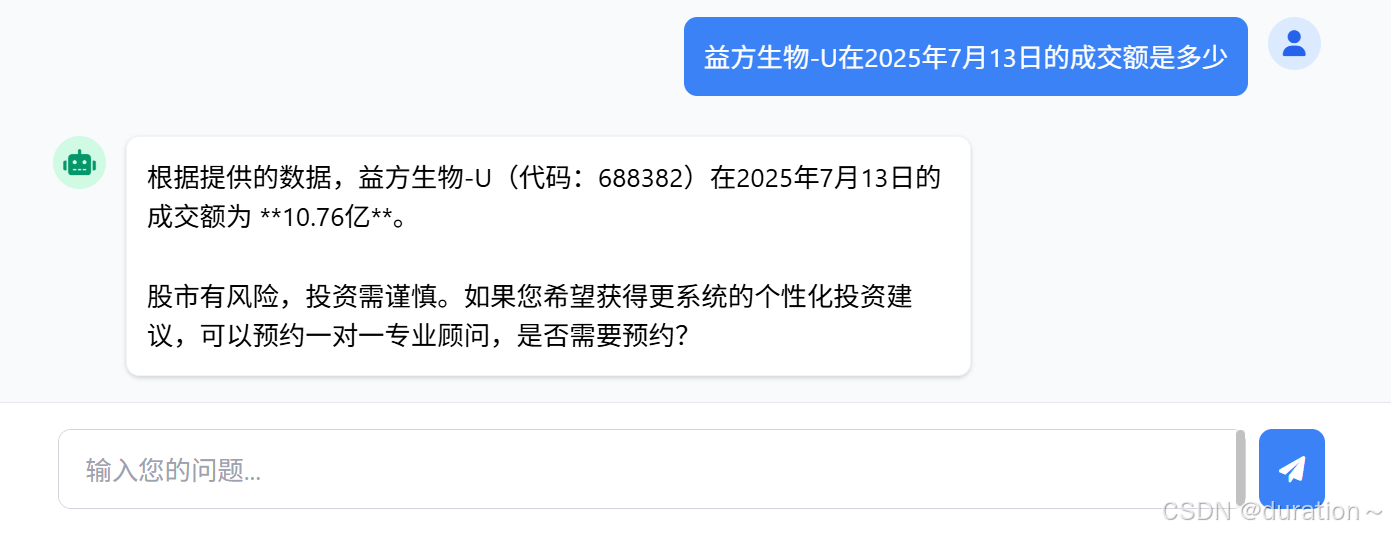
可以在IDEA的控制台查看日志,会发现发送给大模型的用户消息中,格式是这样的:
- 用户问题\n\nAnswer using the following information:\n检索出来的知识片段;

原理就是发送用户消息时,拼接一个“你可以用以下信息回答问题”的文本片段。
接下来对每一个核心 API 进行详细介绍
2 文档加载器
文档加载器的作用是把磁盘或者网络中的数据加载进程序,LangChain4j 提供了多个文档加载器,常见的有以下三种:
- FileSystemDocumentLoader,根据本地磁盘绝对路径加载
- ClassPathDocumentLoader,相对于类路径加载
- UrlDocumentLoader,根据url路径加载
- …
之前案例中使用的就是第二种,可以替换成第一种进行尝试。
3 文档解析器
文档解析器的作用就是解析文档中的内容,把原本非纯文本数据转化成纯文本。
比如初始的文档是 pdf 格式的,它的内容就不是纯文本的,此时需要借助于文档解析器将非纯文本数据转化成纯文本。
在 LangChain4j 中提供了几个常用的文档解析器:
- TextDocumentParser,解析纯文本格式的文件;
- ApachePdfBoxDocumentParser,解析pdf格式文件;
- ApachePoiDocumentParser,解析微软的 office 文件,例如 DOC、PPT、XLS;
- ApacheTikaDocumentParser(默认),几乎可以解析所有格式的文件;
举个例子,默认的 ApacheTikaDocumentParser 虽然可以解析所有格式的文件,但是在纯 PDF 文件方面的表现没有那么优秀,最好将默认的解析器切换成 ApachePdfBoxDocumentParser。
按如下方式使用即可,首先引入依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.1.0-beta7</version>
</dependency>
然后在加载文档时指定解析器:
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content", new ApachePdfBoxDocumentParser());
4 文档分隔器
文档分割器主要用于把一个大的文档切割成一个一个的小片段,在 LangChain4j 中大概有以下7种:
- DocuemntByParagraphSplitter,按照段落分割文本
- DocumentByLineSplitter,按照行分割文本
- DocumentBySentenceSplitter,按照句子分割文本
- DocumentByWordSplitter,按照词分割文本
- DocumentByCharacterSplitter,按照固定数量的字符分割文本
- DocumentByRegexSplitter,按照正则表达式分割文本
- DocumentSplitters.recursive(…)(默认),递归分割器,优先段落分割,再按照行分割,再按照句子分割,再按照词分割
以第一种按照段落分割文本为例,假设我们文本中的内容是一片散文,总共由6个段落组成。
那么 DocumentByParagraphSplitter 就会把文档分割成6个部分,但是每一部分并不是将来进行向量化的文本片段,文本片段是根据这 6 部分的内容组合而成的。
通常情况下 LangChain4j 是允许我们指定文本片段的字符容量的。
举例:
假设指定单个文本片段的字符容量为 300,那么在组合文本片段的时候,第一部分的自然段和第二部分的自然段的字符总和不到 300,可以放到同一个文本片段中;
但是加上第三部分的自然段,字符总和超过了300,那么第三部分的自然段就不能再放到这个文本片段中了,而是放到下一个新的文本片段中。

除了按照段落分割文本,LangChain4j 还提供了按行分割、按句子分割、按单词分割、按固定数量的字符分割等等不同方式的文档分割器,都可以使用。
这里主要关注一下最后一种文本分割器,它是通过一个静态方法 recursive 创建出来的,叫做递归分割器。
它组合了段落分割器、行分割器、句子分割器以及词分割器,它会按照优先级进行分割文档,先按照段落分割,再按照行,再按照句子,最后按照词。
还是之前的例子,如果是递归分割器,到第三个自然段放不下时会继续使用行分割,把第三个自然段进一步分割,尝试把得到的内容放到当前文本片段中,如果还是不行,再按照句子分割…
接下来介绍它的使用:
首先,需要构建文本分割器对象
DocumentSplitter documentSplitter = DocumentSplitters.recursive(
每个片段最大容纳的字符,
两个片段之间重叠字符的个数
);
构建的时候需要指定每个片段最大容纳的字符数量和两个片段之间重叠字符的个数,第一个参数好理解,主要解释一下第二个参数的意思。
这个参数是指,下一个文本片段开头要重复存储上一个文本片段末尾字符的个数。
举个例子,如下图

以此片段为例,第一个片段里面提到了腾讯,但第二个片段中完全没有相关字眼,那么到时候检索内容时也不会被检索出来,但按照语义它应该是被检索出来的。
解决办法就是让两个片段存储的内容有重叠的部分,上一个片段的末尾与下一个片段的开头重复,这样就可以保持语义的连贯性了。
最后,配置好文本分割器对象即可
真正分割文本的操作被封装到 EmbeddingStoreIngestor 中了,所以在构建该对象时,需要通过 documentSplitter 方法告诉它使用哪个文本分割器。
@Bean
public EmbeddingStore<TextSegment> store() {
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库
InMemoryEmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
//3.构建文档分割器对象
DocumentSplitter ds = DocumentSplitters.recursive(500, 100);
//4.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store).documentSplitter(ds).build();
ingestor.ingest(documents);
return store;
}
5 向量模型
向量模型的作用是把分割后的文本片段向量化或者把用户消息向量化。
LangChain4j 中提供了 EmbeddingModel 接口用于定义有关向量模型的方法,例如有 embed、embedall 等等方法用于把文本片段向量化。
public interface EmbeddingModel {
/**
* 嵌入文本
*
* @param text 要嵌入的文本
* @return 向量
*/
default Response<Embedding> embed(String text) {
return embed(TextSegment.from(text));
}
/**
* 嵌入 TextSegment 的文本内容。
*
* @param textSegment ― 要嵌入的文本段。
* @return the embedding.
*/
default Response<Embedding> embed(TextSegment textSegment) {
Response<List<Embedding>> response = embedAll(singletonList(textSegment));
ValidationUtils.ensureEq(response.content().size(), 1,
"Expected a single embedding, but got %d", response.content().size());
return Response.from(response.content().get(0), response.tokenUsage(), response.finishReason());
}
/**
* 嵌入所有的文本段
*
* @param textSegments 要嵌入的文本段。
* @return the embeddings.
*/
Response<List<Embedding>> embedAll(List<TextSegment> textSegments);
/**
* 返回此嵌入模型生成的 维度 Embedding 。
*
* @return dimension of the embedding
*/
default int dimension() {
return embed("test").content().dimension();
}
}
LangChain4j 提供了一个内存版本的向量模型实现方案,快速入门中使用的就是此向量模型,虽然当时并没有手动指定这个向量模型,但是它默认被封装到 EmbeddingStoreIngestor 中了。
但是这种内置的向量模型内有时候功能没有那么强大,支持的向量维度太少,检索的时候没有那么精准,所以有些情况下我们需要替换它,使用一些功能更强大的向量模型。
阿里云百炼平台也提供了专门用于向量化的向量模型 text-embedding-v3,可以用它进行替换。
1_ 配置向量模型
配置embedding-model,和其他模型配置一样:
langchain4j:
open-ai:
embedding-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: ${API-KEY}
model-name: text-embedding-v3
log-requests: true
log-responses: true
max-segments-per-batch: 10 # 百炼平台大模型一次最多处理10个片段,这是为了防止一次发送过多(文件过多需要分批发送)
2_ 设置向量模型
配置完毕后,LangChain4j 会自动往IOC容器中注入一个 EmbeddingModel 对象,所以接下来需要调用 EmbeddingStoreIngestor 和 EmbeddingStoreContentRetriever 的embeddingModel方法,存储和检索时使用向量模型。
@Resource
private EmbeddingModel embeddingModel;
@Bean
public EmbeddingStore<TextSegment> store() {
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//2.构建向量数据库操作对象 操作的是内存版本的向量数据库
InMemoryEmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
//3.构建文档分割器对象
DocumentSplitter ds = DocumentSplitters.recursive(500, 100);
//4.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store).documentSplitter(ds)
// 此处
.embeddingModel(embeddingModel).build();
ingestor.ingest(documents);
return store;
}
@Bean
public ContentRetriever contentRetriever(EmbeddingStore<TextSegment> store) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)//设置向量数据库操作对象
.minScore(0.5)//设置最小分数
.maxResults(3)//设置最大片段数量
.embeddingModel(embeddingModel)//设置向量模型
.build();
}
6 EmbeddingStore
EmbeddingStore 是用来操作向量数据库的 API 对象,不管是存储还是检索都需要借助于它来完成。
EmbeddingStore 接口中提供了三组方法,add 用于存储数据,search 用于检索数据,remove 用于删除数据。
public interface EmbeddingStore<Embedded> {
String add(Embedding embedding);
void add(String id, Embedding embedding);
String add(Embedding embedding, Embedded embedded);
List<String> addAll(List<Embedding> embeddings);
default List<String> addAll(List<Embedding> embeddings, List<Embedded> embedded) {
final List<String> ids = generateIds(embeddings.size());
addAll(ids, embeddings, embedded);
return ids;
}
default List<String> generateIds(int n) {
List<String> ids = new ArrayList<>();
for (int i = 0; i < n; i++) {
ids.add(randomUUID());
}
return ids;
}
default void addAll(List<String> ids, List<Embedding> embeddings, List<Embedded> embedded) {
throw new UnsupportedFeatureException("Not supported yet.");
}
default void remove(String id) {
ensureNotBlank(id, "id");
this.removeAll(singletonList(id));
}
default void removeAll(Collection<String> ids) {
throw new UnsupportedFeatureException("Not supported yet.");
}
default void removeAll(Filter filter) {
throw new UnsupportedFeatureException("Not supported yet.");
}
default void removeAll() {
throw new UnsupportedFeatureException("Not supported yet.");
}
EmbeddingSearchResult<Embedded> search(EmbeddingSearchRequest request);
}
我们之前一直使用的实现方案是 InMemoryEmbeddingStore,这是一个内存向量数据库,有些情况下不能满足实际开发中的需求。

最严重的一点是使用内存向量数据库,每次重启都需要重新加载文档、重新向量化,如果使用的是云向量模型还会消耗大量 token,也就是钱。
所以,接下来以 RediSearch 为例,对数据进行存储。
1_ 准备向量数据库RediSearch
redisearch 与 redis 不同,redisearch 是 redis 扩展的一个功能,所以需要单独部署:
docker run --name redis-vector -d -p 6379:6379 redislabs/redisearch #安装扩展redisearch功能的redis
2_ 引入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
3_ 配置向量数据库连接信息
此处的配置和我们之前配置的redis不相干,这里配置的是langchain4j.community下的,而之前配置的是spring.data下的。
langchain4j:
community:
redis:
host: 192.168.200.129
port: 6379
当引入的起步依赖后,会自动往 IOC 容器中注入一个 RedisEmbeddingStore 对象,这个对象实现了 EmbeddingStore 接口,封装了操作 redissearch 的 API,可以直接使用。
4_ 注入RedisEmbeddingStore对象使用
和之前一样,将 IOC 容器中的 RedisEmbeddingStore 对象分别设置给 EmbeddingStoreIngestor 和 EmbeddingStoreContentRetriever,用于存储和检索。
@Resource
private EmbeddingModel embeddingModel;
@Resource
private RedisEmbeddingStore redisEmbeddingStore;
@Bean
public EmbeddingStore<TextSegment> store() {
//1.加载文档进内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
//3.构建文档分割器对象
DocumentSplitter ds = DocumentSplitters.recursive(500, 100);
//4.构建一个EmbeddingStoreIngestor对象,完成文本数据切割,向量化, 存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(redisEmbeddingStore).documentSplitter(ds)
.embeddingModel(embeddingModel).build();
ingestor.ingest(documents);
return redisEmbeddingStore;
}
@Bean
public ContentRetriever contentRetriever() {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(redisEmbeddingStore)//设置向量数据库操作对象
.minScore(0.5)//设置最小分数
.maxResults(3)//设置最大片段数量
.embeddingModel(embeddingModel)
.build();
}
5_ 避免每次启动都进行向量化
由于准备向量数据库的操作是在 CommonConfig 配置类中完成的,在该类中我们提供了一个 store 方法,方法上添加了一个@Bean注解,所以每次启动程序,该方法都会执行一遍,文档就会重新加载,重新向量化。
所以当我们把所有文档拷贝到 content 目录中,启动测试一遍后,redis 中就已经存好了所有的数据,接下来把 store 方法上的 @Bean 注解注释掉,可以避免每次启动都做向量化的操作。
//@Bean
public EmbeddingStore<TextSegment> store(){
//.......
return redisEmbeddingStore;
}
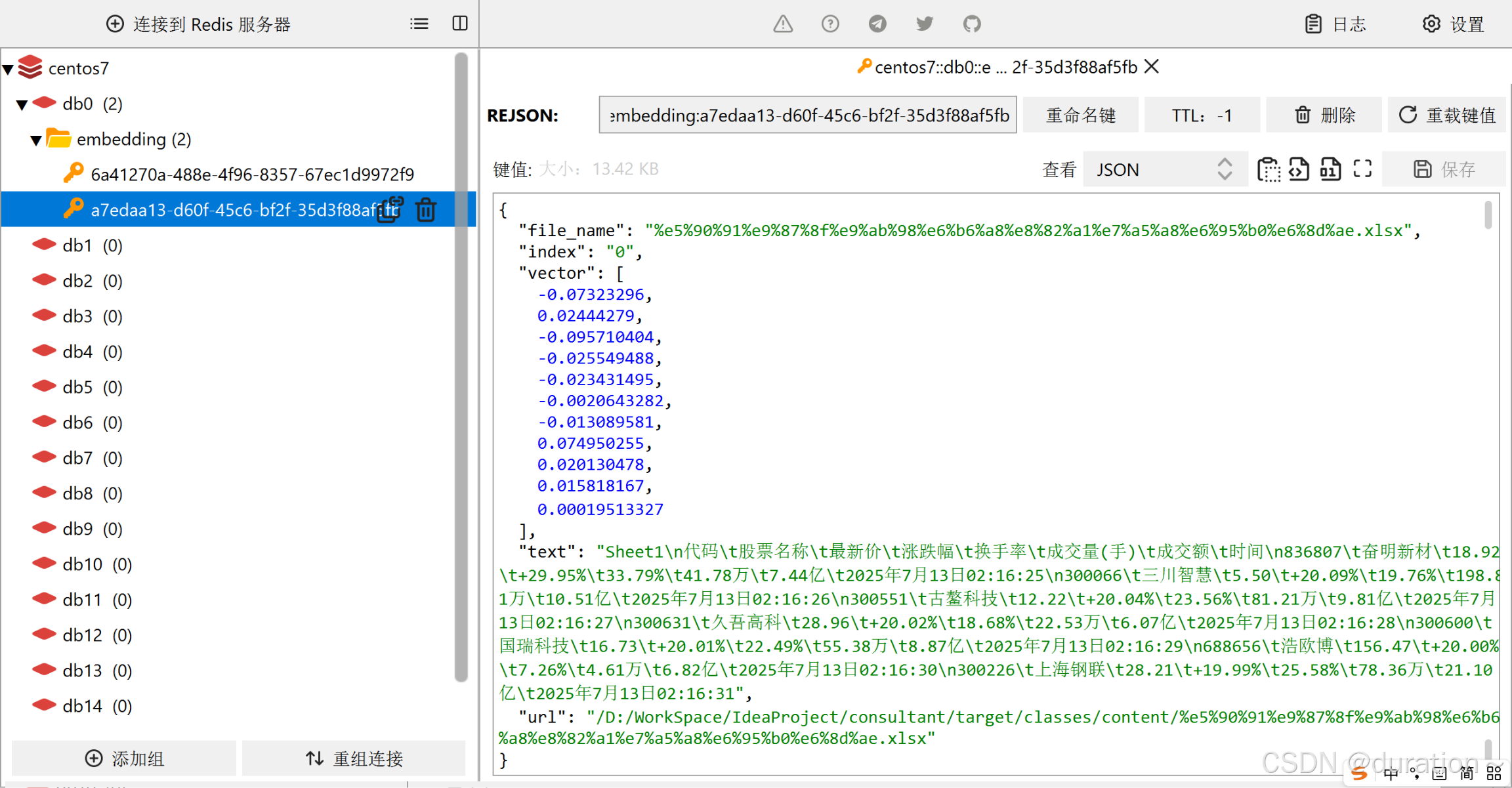
在 Reids 中存储形式大致如下:
9 Tools工具
看这样一种需求:我们在对线上的一些 AI 客服进行咨询时,可以自动进行类似于机票订购退订、相关服务的预约等功能,仅需用户提供一些关键信息:

当用户表达出需要预约的意愿并提交了姓名、性别、电话等信息后,程序就会自动向数据库中添加一条信息,记录预约详情。
1_前置操作
假设用户提供的预约信息结构如下:
create table user_investment_profile (
id bigint auto_increment primary key comment '主键,自增id',
name varchar(50) not null comment '用户姓名',
contact_info varchar(100) not null comment '联系方式,如手机号、邮箱、微信号',
risk_preference int not null comment '投资风格偏好:1=激进,2=稳健,3=保守',
appointment_time datetime not null comment '预约时间,包含日期和时间',
focus_sector text comment '关注的行业或个股,例如新能源、ai、宁德时代',
created_at timestamp default current_timestamp comment '创建时间',
updated_at timestamp default current_timestamp on update current_timestamp comment '最后更新时间'
) engine=innodb default charset=utf8mb4 comment='用户投资偏好与预约信息表';
实体类、业务层、持久层实现略。
2 Tools工具原理
Tools 工具,以前也叫做 function calling,翻译过来叫做函数调用,如果在程序中添加了 function calling功能,那整个工作流程会变为如下形式:
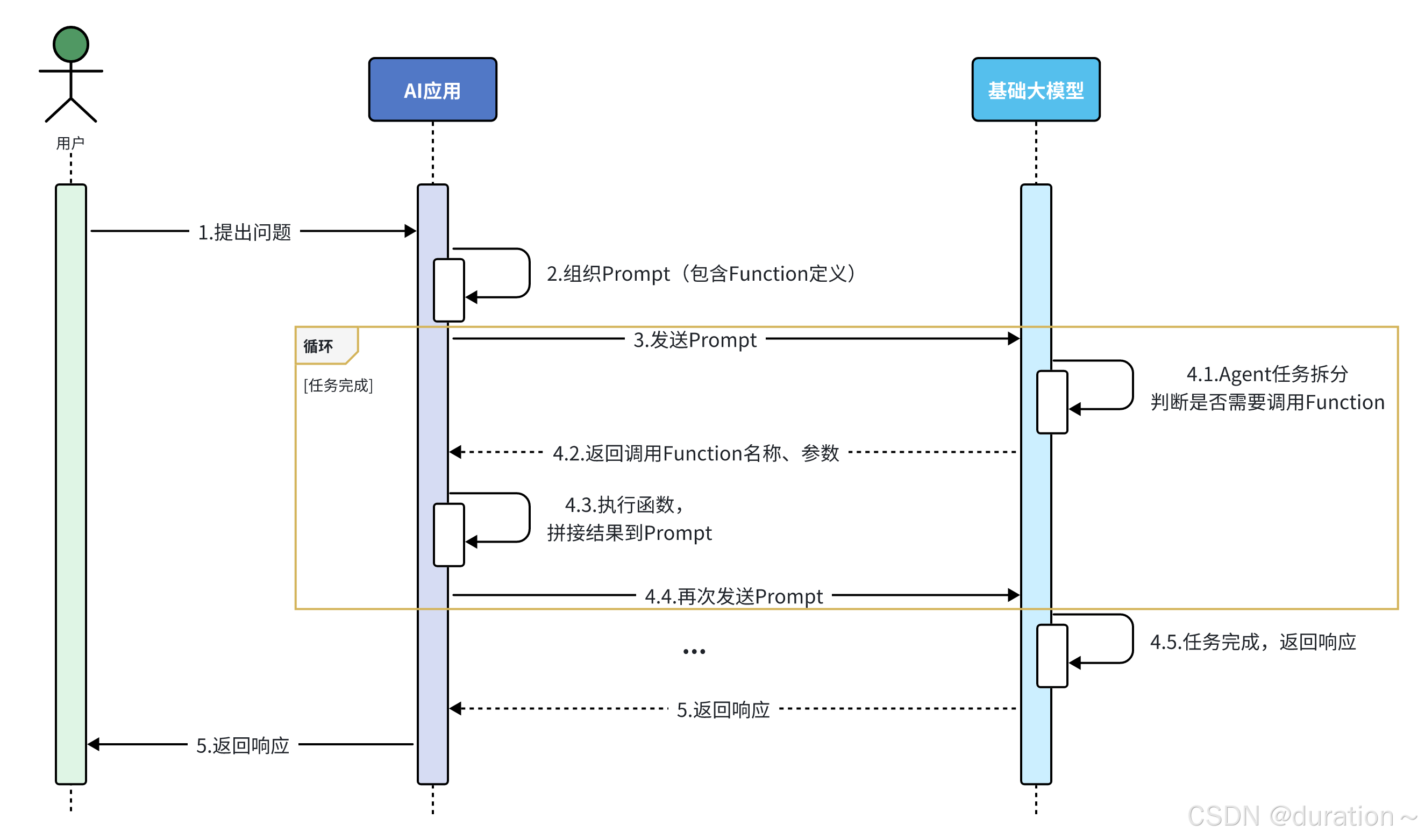
当用户把问题发送给 AI应用,在 AI应用的内部需要组织提交给大模型的数据,而这些数据中需要描述清楚我们的AI应用中有哪些函数能够被大模型调用。
每一个函数的描述(定义)都包含三个部分:方法名称、方法作用、方法入参。
当AI应用把这些数据发送给大模型后,大模型会先根据用户的问题以及上下文拆解任务,从而判断是否需要调用函数,如果有函数需要调用,则把需要调用的函数的名称,以及调用时需要使用的参数准备好一并响应给AI应用。
AI应用接收到响应后需要执行对应的函数,得到对应的结果,接下来把得到的结果和之前信息一块组织好再发送给大模型。
需要注意的是在一次任务的处理过程中可能需要根据顺序调用多个函数,所以当大模型接收到 AI应用发送的数据会继续拆解任务,如果发现还需要调用其他的函数,则会重复 4.1~4.4 这几个步骤,直到无需调用函数,最终把生成的结果响应该AI应用,并由AI应用发送给用户。
这就是增加了 function calling(以前叫法)或者 Tools(现在的名称)工具后整个AI应用的工作流程。
3 工具方法
LangChain4j 提供了 Tool 注解用于对方法的作用进行描述, P 注解用于对方法的参数进行描述。
LangChain4j 可以通过反射的方式获取到 Tool 注解中的作用描述、P注解中的参数描述、以及方法的名称,组织数据后一并发送给大模型。
注意,InvestmentReservationTool 对象需要注入到 IOC 容器中。
import com.duration.consultant.domain.UserInvestmentProfile;
import com.duration.consultant.service.UserInvestmentProfileService;
import dev.langchain4j.agent.tool.P;
import dev.langchain4j.agent.tool.Tool;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Component
public class InvestmentReservationTool {
private final UserInvestmentProfileService profileService;
@Autowired
public InvestmentReservationTool(UserInvestmentProfileService profileService) {
this.profileService = profileService;
}
// 1.工具方法:添加用户投资预约信息
@Tool("添加用户投资预约信息")
public void addInvestmentReservation(@P("用户姓名") String name,
@P("联系方式") String contactInfo,
@P("投资风格偏好,1=激进,2=稳健,3=保守") Integer riskPreference,
@P("预约时间,格式为: yyyy-MM-dd'T'HH:mm") String appointmentTime,
@P("关注行业或个股") String focusSector) {
UserInvestmentProfile profile = new UserInvestmentProfile();
profile.setName(name);
profile.setContactInfo(contactInfo);
profile.setRiskPreference(riskPreference);
profile.setAppointmentTime(LocalDateTime.parse(appointmentTime));
profile.setFocusSector(focusSector);
profileService.create(profile);
}
// 2.工具方法:根据联系方式查询预约信息
@Tool("根据联系方式查询投资预约信息")
public UserInvestmentProfile findInvestmentReservation(@P("联系方式") String contactInfo) {
return profileService.findByContactInfo(contactInfo);
}
}
4 配置工具方法
配置的方法和之前的类似,在 AiService 注解中有一个 tools 的属性,值写上包含了工具方法的 Bean 对象的名字即可。
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,//手动装配
chatModel = "openAiChatModel",//指定模型
streamingChatModel = "openAiStreamingChatModel",
chatMemory = "chatMemory",//配置会话记忆对象(公用)
chatMemoryProvider = "chatMemoryProvider",//配置会话记忆提供者对象
contentRetriever = "contentRetriever",//配置向量数据库检索对象
tools = "investmentReservationTool" //配置tools
)
5 最后说明
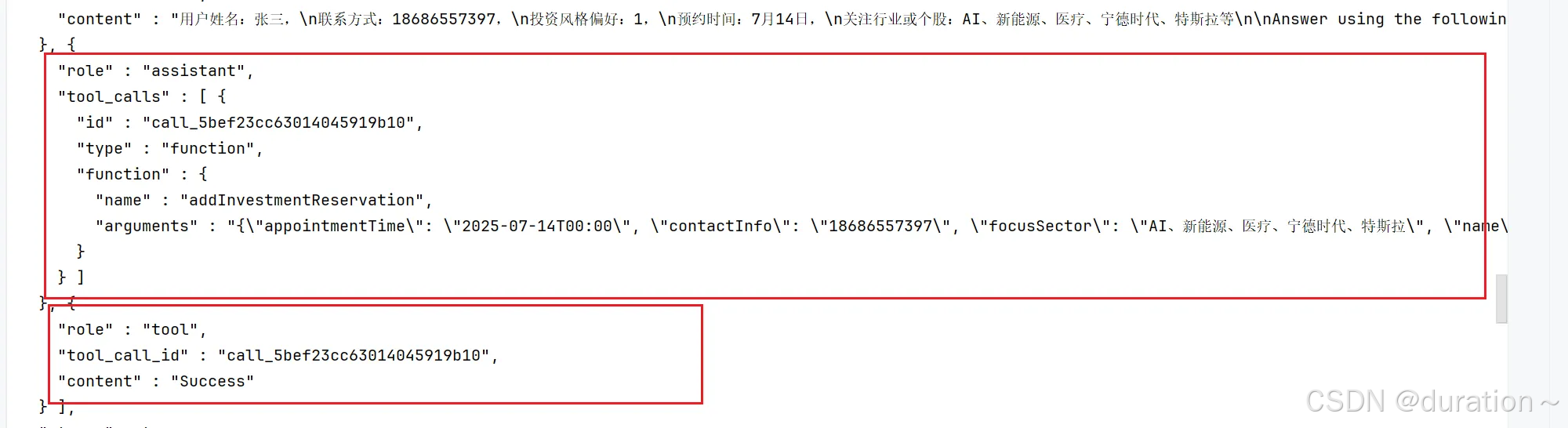
功能已经实现完毕了,测试的时候注意观察IDEA控制台的信息,langchain4j 给大模型发送消息的时候会使用 tools 参数告诉大模型,有哪些函数可以调用。

聊天记录中也会出现一个 "role" : "tool" 的属性:
最终执行结果如下(数据库中插入新数据):
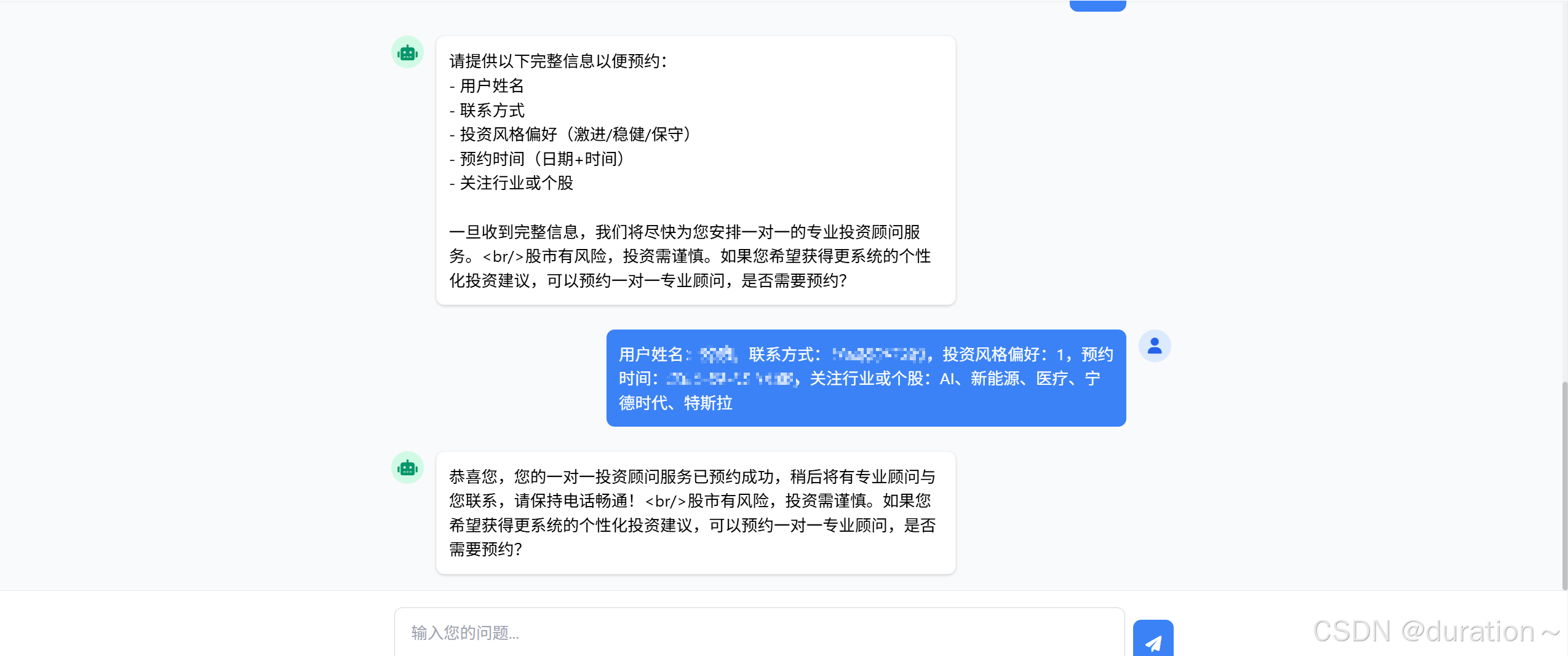
并不是所有大模型都支持 Function Calling,比如 DeepSeek-R1 模型就不支持。
10 补充
1_本地大模型
云端大模型容易受网络影响,简单的项目会使用本地大模型(本地 ollama 模型和AI应用放在一起部署和开发)
如果是接入使用本地大模型,将所有类似于 langchain4j-open-ai-** 的依赖替换为 langchain4j-ollama-** 再调整一下配置即可。
2 JDK 版本问题
有许多人更习惯于使用 Spring AI 进行开发,选择 LangChain4j 的原因主要是其兼容 JDK8,而本文中的所有案例皆是基于 17 的,要想使用需要更低级一些的 API,可能 API 会有差异。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)