
拨开迷雾:人工智能核心领域与大模型的演进逻辑!新手放心进,保证通俗易懂!!
人工智能(AI)是计算机科学的重要分支,旨在模拟和扩展人类智能,涵盖规则设计、逻辑推理以及现代机器学习等技术。其核心子领域包括机器学习、深度学习和生成式人工智能等。机器学习通过数据驱动和算法导向赋能广泛应用,如推荐系统和自然语言处理;深度学习依托深层神经网络在非结构化数据处理中表现出色;生成式人工智能则通过生成对抗网络(GAN)和 Transformer 等技术,推动了文本、图像等多模态生成能力的
1. 人工智能的定义及其子领域
人工智能(Artificial Intelligence, AI)是计算机科学的一个重要分支,旨在模拟和扩展人类智能。AI 涉及多个学科,涵盖数学、计算机科学、认知科学等领域。根据研究内容和技术特点,人工智能主要分为以下几个子领域:
1.1 人工智能
人工智能是一个广义的概念,包含任何试图让机器表现出类似人类智能的技术。传统人工智能注重规则设计和逻辑推理,而现代人工智能通过机器学习实现数据驱动的智能化。
1.2 机器学习
机器学习(Machine Learning, ML)是人工智能的核心子领域之一,关注让计算机通过数据“学习”。核心特性包括:
- 数据驱动:利用大量数据进行模式发现和规律总结。
- 算法导向:常见算法包括监督学习、无监督学习和强化学习等。
- 广泛应用:机器学习技术被广泛应用于推荐系统、图像识别和自然语言处理等领域。
1.3 深度学习
深度学习(Deep Learning)是机器学习的一个子领域,依赖于深层神经网络(Deep Neural Networks, DNN)实现更复杂的任务。它的主要特点包括:
- 多层结构:通过多个神经网络层逐步提取高级特征。
- 强大的表达能力:能够处理图像、语音、文本等非结构化数据。
- 技术突破:近年来深度学习在计算机视觉、语音识别和生成式模型上取得显著成果。
1.4 生成式人工智能
生成式人工智能(Generative AI)是近年来兴起的一个重要分支,其特点在于能够创造新的内容,而非仅仅完成预测或分类任务。生成式 AI 技术依赖于诸如生成对抗网络(GANs)、变分自编码器(VAEs)以及近年来大火的 Transformer 架构。它的主要应用包括:
- 文本生成:如自动撰写文章、聊天机器人。
- 图像生成:如通过 DALL-E 等工具生成艺术作品。
- 多模态生成:实现跨文本、图像、音频的内容生成和理解.
2. 大模型
2.1. 什么是大模型
大模型是近年来人工智能领域的一项重要技术突破。它通过对海量数据进行训练,构建出具有庞大参数规模的机器学习模型,在多种任务中展现出强大的通用能力和跨领域适应性。
大模型的核心特征包括:
- 参数量巨大:通常达到数十亿到数千亿级别,模型规模远超传统人工智能模型。
- 多领域数据训练:训练数据范围涵盖多领域(如文本、图像、音频等)以及多模态(如视觉与语言的结合)。
- 通用性与可迁移性:支持跨领域任务,减少了为每个任务单独构建模型的成本。
通过这些特性,大模型已成为推动人工智能向通用智能(AGI)发展的重要工具。
2.2. 大模型和人工智能的关系
大模型与人工智能密切相关,是人工智能技术发展的重要里程碑。二者的关系可以从以下几个方面来理解:
2.2.1. 大模型是人工智能的具体技术实现
人工智能(AI)是一个涵盖多种技术和应用的广泛概念,而大模型是实现 AI 的一种具体技术路径。大模型依赖于深度学习技术,通过大规模神经网络结构处理复杂的智能任务。
2.2.2. 大模型推动人工智能迈向通用化
传统人工智能通常针对特定场景进行优化,例如语音识别或图像分类。大模型通过大规模训练与跨领域适配能力,逐步向通用人工智能(AGI)的目标迈进。例如,OpenAI 的 GPT 系列和 Google 的 PaLM 模型展现了在文本生成、问答、多模态任务等领域的强大能力。
2.2.3. 大模型提升了人工智能的实际应用水平
由于大模型具备强大的推理能力和数据理解能力,其应用范围从原本的单一任务扩展到多模态内容生成、知识推理等复杂场景。例如:
- 自然语言处理:实现更高质量的文本生成、机器翻译、智能问答等功能。
- 计算机视觉:用于图像生成、目标检测和视频内容分析等任务。
- 多模态结合:如文本到图像生成的应用(DALL-E、Stable Diffusion 等)。
2.2.4. 大模型驱动人工智能基础设施的升级
大模型的训练和运行需要大量的计算资源和更高效的算法支持,因此也推动了 AI 硬件(如 GPU、TPU)的迭代和分布式训练技术的发展。这种良性循环促进了人工智能整体技术生态的进步。
2.3. 大模型的演变
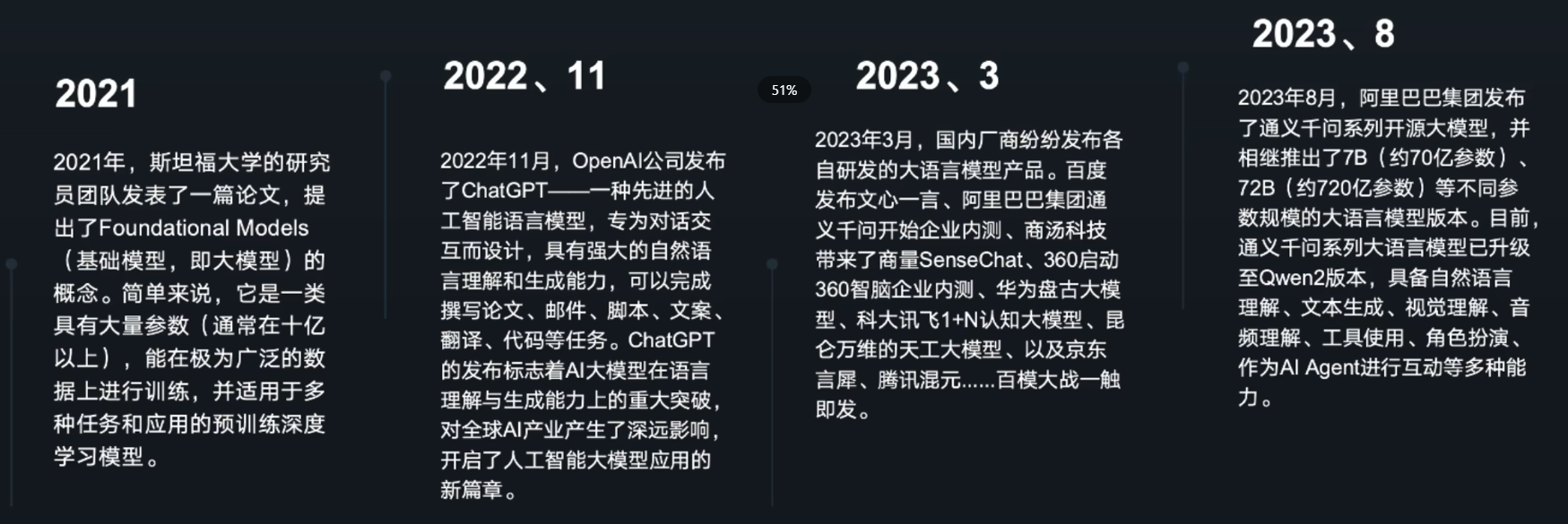
3. 大模型的使用和训练
3.1 大模型的使用
大模型的使用以**提示词(Prompt)**为核心。通过设计合适的提示词,可以引导模型完成多种任务,包括问答、内容生成、翻译、代码编写等。以下是大模型使用中的关键要素:
- 提示词优化:提示词的设计直接影响模型输出质量。精准的指令可以提高生成内容的相关性和准确性。
- 上下文管理:输入信息的上下文决定了模型对任务的理解程度,提供足够且清晰的上下文有助于提高性能。
- API 调用:许多大模型通过 API 提供服务(如 OpenAI 的 GPT 系列),用户通过接口传递任务请求并接收结果。
- 工具集成:大模型常被集成到业务应用中,如智能客服、内容推荐和数据分析系统。
示例:
输入提示词:“用中文解释人工智能的基本概念。”
输出结果:人工智能是一门旨在让机器模拟人类智能的学科,包括学习、推理、感知等能力。
3.2 大模型的训练
大模型的训练分为三个主要阶段:预训练、SFT(监督微调)和RLHF(基于人类反馈的强化学习)。
3.2.1 预训练是什么
预训练是大模型训练的基础阶段,主要目的是通过大规模无标注数据(如互联网文本、图像等)学习通用知识和模式。
特点:
- 无监督学习:不依赖特定任务标签,通过语言建模任务(如预测下一个单词)学习广泛的语言知识。
- 大规模数据:通常需要处理数百 GB 到 PB 级的数据,涵盖多种语言和领域。
- 参数初始化:为后续微调阶段提供良好的模型参数基础。
典型方法:
- 自回归模型(如 GPT):基于前向语言模型进行预训练。
- 自编码模型(如 BERT):通过遮蔽部分输入内容,预测被掩盖的信息。
3.2.2 SFT(监督微调)是什么
SFT(Supervised Fine-Tuning, 监督微调) 是在预训练模型的基础上,通过有标注的数据进一步调整模型,使其适应特定任务。
特点:
- 有监督学习:需要大量高质量的任务数据集(如问答对、翻译对等)。
- 任务针对性:优化模型参数,使其在目标任务上表现更优。
- 可扩展性:微调后的模型可迁移到其他类似任务上。
典型场景:
- 微调 GPT 模型用于特定领域的文本生成(如医疗报告、法律文档)。
- 微调 BERT 模型用于分类任务(如情感分析、垃圾邮件检测)。
3.2.3 RLHF(基于人类反馈的强化学习)是什么
RLHF(Reinforcement Learning with Human Feedback) 是大模型优化的一种先进方法,通过人类反馈指导模型的行为,使其更符合用户需求。
核心流程:
- 收集反馈:让人类标注员评估模型输出质量,并提供优劣对比。
- 训练奖励模型:基于人类反馈数据,构建一个预测输出质量的奖励模型。
- 强化学习优化:使用强化学习算法(如 Proximal Policy Optimization, PPO),根据奖励模型优化大模型,使其输出更符合用户偏好。
应用场景:
- 聊天机器人:让模型生成更人性化的对话内容。
- 内容过滤:通过反馈优化模型避免生成有害或不相关的信息。
3.2.4 大模型的完整训练流程
大模型的完整训练流程通常包括以下步骤:
- 预训练:利用大规模无标注数据学习通用知识,为模型提供初始能力。
- 监督微调(SFT):在特定任务数据集上进行微调,使模型适应具体任务需求。
- RLHF 优化:通过人类反馈进一步调整模型,增强其对人类偏好的理解和响应能力。
- 模型评估:通过多维度的指标(如准确性、鲁棒性和安全性)对模型性能进行综合评估。
- 部署与维护:将训练好的模型部署到实际应用中,并持续优化和更新。
4. 大模型的特点与分类
4.1 大模型的特点
大模型在人工智能领域展现出诸多独特的特点,这使其在广泛的应用场景中具有显著的优势:
-
参数规模庞大
大模型通常拥有数十亿到数千亿级别的参数,赋予其强大的学习能力和表达能力。例如,GPT-4 具有数万亿级参数,能够处理复杂的语言任务。 -
多模态融合
支持多种模态(文本、图像、音频等)的融合与处理,能够实现跨模态生成与理解。例如,生成文本描述的图像或根据图片生成文字。 -
通用性与可迁移性
通过大规模预训练,大模型在广泛领域中表现出通用性,可通过少量微调迁移到具体任务。 -
强大的上下文理解能力
能够捕捉输入中的语义上下文,生成连贯且高质量的内容,尤其在自然语言处理任务中表现突出。 -
持续学习与优化能力
随着数据规模和计算资源的提升,大模型可不断更新和优化,逐步接近人类智能的通用水平。
4.2 大模型的分类
根据大模型的设计目标与应用领域,可以将其分为以下几类:
4.2.1 大语言模型(LLM, Large Language Model)
定义:大语言模型是专注于自然语言处理任务的深度学习模型,能够理解、生成和处理语言数据。
特点:
- 主要通过自回归或自编码结构(如 Transformer)实现语言的高效建模。
- 支持多语言处理,广泛应用于文本生成、机器翻译、问答等任务。
- 示例模型:GPT 系列、BERT、T5、PaLM。
应用场景:
- 自动化写作:撰写文章、创作小说或总结文档。
- 智能问答:提供实时信息查询和对话服务。
- 机器翻译:高质量地翻译多种语言。
4.2.2 多模态模型
定义:多模态模型是能够同时处理多种类型数据(如文本、图像、音频)的人工智能模型。
特点:
- 通过多模态融合技术,实现跨模态的内容生成和理解。
- 结合不同模态的数据提升任务表现,例如结合视觉和语言的信息生成图像描述。
- 示例模型:CLIP(对比学习图文模型)、DALL-E(文本到图像生成模型)、Flamingo(跨模态问答模型)。
应用场景:
- 文本到图像生成:根据输入文字生成对应的高质量图像。
- 多模态搜索:支持通过图片查找相关的文本或通过文字检索图像。
- 智能内容创作:实现跨模态内容协同生成(如视频自动配音与字幕生成)。
5. 大模型的工作流程
大模型的工作流程包括从输入文本的分词化到最终的文本生成,分为多个关键步骤。
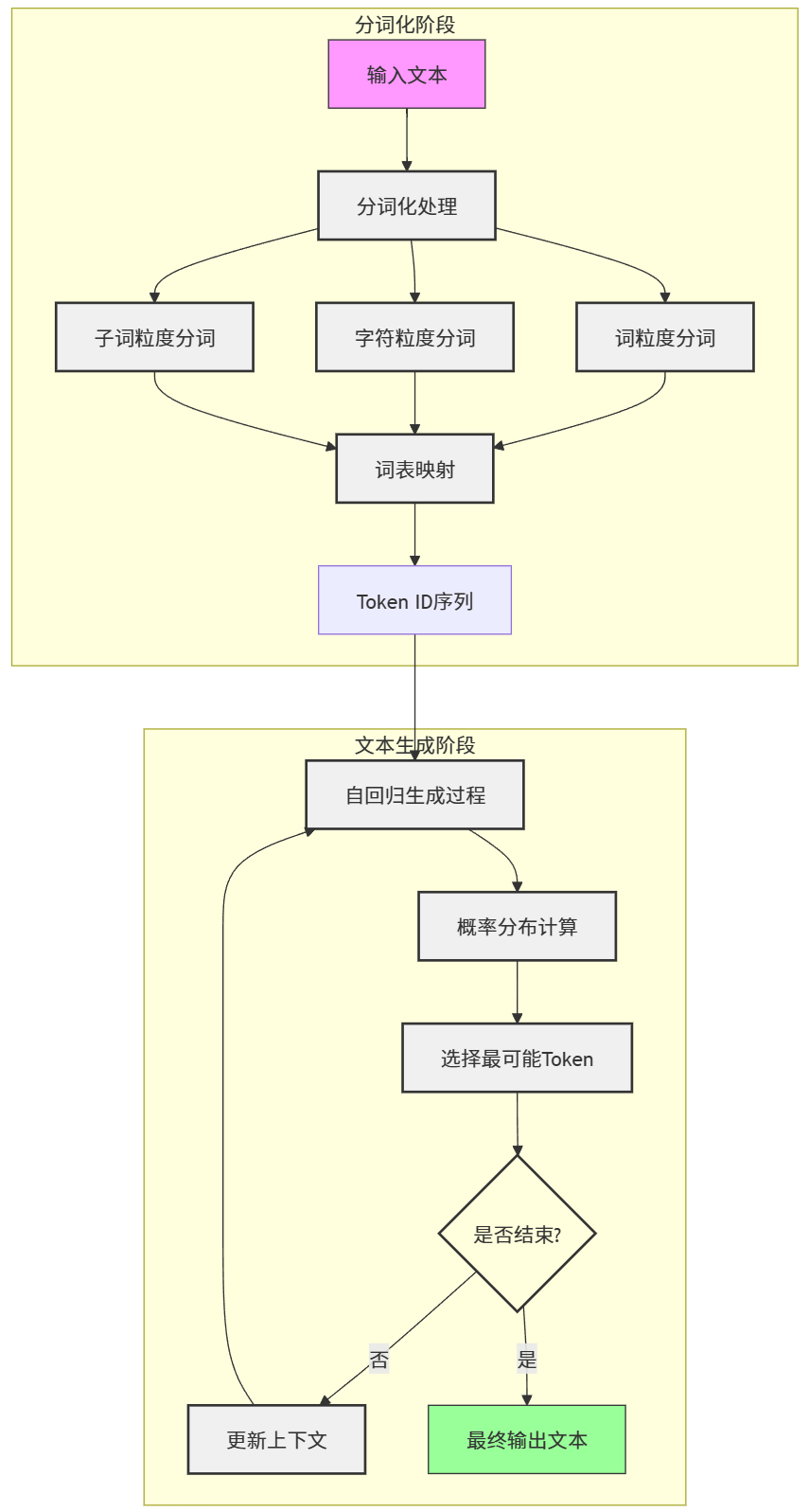
5.1 分词化与词表映射
分词化(Tokenization)是自然语言处理(NLP)中的核心步骤,旨在将段落或句子分解为更小的、计算机易于处理的单元(Token)。以下是具体内容:
分词化的过程
以英文句子为例:
输入句子:I want to study ACA.
分词结果:['I', 'want', 'to', 'study', 'ACA', '.']
通过分词化,句子被分解成独立的单元(Token),使计算机能够理解各个部分在上下文中的意义。
分词化的粒度
-
词粒度(Word-Level Tokenization)
- 将句子按照单词划分成 Token。
- 适用语言:大多数西方语言,如英语、法语等。
- 示例:
['I', 'want', 'to', 'study', 'ACA', '.']
-
字符粒度(Character-Level Tokenization)
- 将句子按单个字符划分成 Token。
- 适用语言:中文等无明显分词标记的语言。
- 示例:
['我', '想', '学', '习']
-
子词粒度(Subword-Level Tokenization)
- 将词分解为更小的单元,如词根、词缀或常见组合。
- 优势:高效处理新词(如专有名词、网络用语),即便单词本身未出现在词表中,其组成的子词很可能已被训练过。
- 示例:
['stu', 'dy', 'ing']
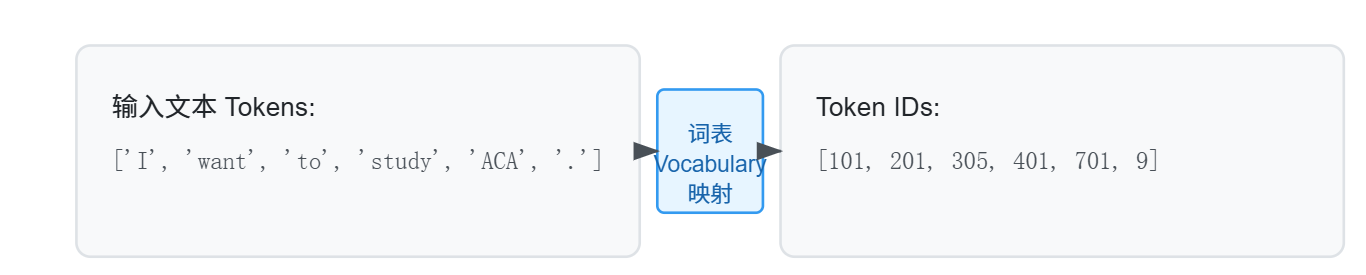
词表映射
- 每个 Token 通过预设的词表(Vocabulary)映射为一个唯一的 Token ID(“身份证”)。
- 示例:
['I', 'want', 'to', 'study', 'ACA', '.']→[101, 201, 305, 401, 701, 9] - 最终,句子被表示为一个由 Token ID 组成的列表,便于后续处理。
5.2 文本生成过程
文本生成是大语言模型的核心能力,其本质是根据给定的输入预测下一个最有可能的 Token。这一过程通常采用自回归方法。
自回归文本生成
-
输入提示词(Prompt)
用户通过一段提示文本向大模型输入任务需求,例如:- 输入:
What is artificial intelligence?
- 输入:
-
逐步预测 Token
大模型根据已知的 Token,逐步预测下一个最有可能的 Token:- 第一步:
What→ 根据上下文预测is - 第二步:
What is→ 预测artificial - 第三步:
What is artificial→ 预测intelligence
- 第一步:
-
更新输入序列
每次预测的 Token 都会加入输入序列,形成新的上下文,供模型继续预测。 -
终止条件
- 模型预测出特殊 Token(如
<EOS>,表示句子结束)。 - 达到预设输出长度限制。
- 模型预测出特殊 Token(如

示例:完整生成过程
假设输入提示词为:AI is
- 初始输入:
AI is - 预测序列:
AI is a powerful tool for - 最终输出:
AI is a powerful tool for solving complex problems.
特点与优化
-
概率最大原则
每次预测时,模型会基于概率分布选择最有可能的 Token。例如,给定输入AI is:- 可能输出:
helpful (50%)、amazing (30%)、a (20%) - 模型选择
helpful。
- 可能输出:
-
生成控制
- 长度控制:限制生成的最大 Token 数。
- 多样性控制:通过调整温度参数,控制生成内容的多样性和创新性。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 30
30 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)