
构建高效智能体(Building Effective Agents)
文章《构建高效智能体(Building Effective Agents)》中,Anthropic公司分享了他们在过去一年中与多个行业团队合作开发大型语言模型(Large Language Model, LLM)智能体的经验。文章的核心观点令人深思:最成功的智能体实现并非依赖于复杂的框架或专门的库,而是通过简单、可组合的模式构建而成。
在2024年12月20日发布的这篇文章《构建高效智能体(Building Effective Agents)》中,Anthropic公司分享了他们在过去一年中与多个行业团队合作开发大型语言模型(Large Language Model, LLM)智能体的经验。文章的核心观点令人深思:最成功的智能体实现并非依赖于复杂的框架或专门的库,而是通过简单、可组合的模式构建而成。
这一观点颠覆了许多开发者对人工智能开发的传统认知。通常,人们倾向于认为,越复杂的技术越能带来更好的效果。然而,作者通过实际案例表明,简洁性和模块化设计才是构建高效智能体的关键。这不仅降低了开发门槛,还提高了系统的可维护性和扩展性。
文章还提供了针对开发者的实用建议,强调了从客户需求出发、注重实际应用场景的重要性。这种以用户为中心的设计理念,正是当前人工智能领域亟需的。通过分享自身的实践经验,作者为读者提供了一条清晰的技术路径,帮助他们在开发智能体时避免常见的陷阱。
总体而言,这篇文章不仅具有理论深度,还充满了实践智慧。无论是对于初学者还是资深开发者,都能从中获得启发。它提醒我们,在追求技术创新的同时,不应忽视简单和实用的价值。这种平衡,正是构建高效智能体(Effective Agents)的核心所在。
完整Cookbook及原文章参考:https://github.com/anthropics/anthropic-cookbook/tree/main/patterns/agents
什么是智能体(Agents)?
智能体(Agent)可以从多个角度进行定义。一些客户将智能体定义为完全自主的系统,这些系统能够在较长时间内独立运行,并使用各种工具来完成复杂任务。另一些客户则用这一术语来描述遵循预定义工作流程的规范性实现。Anthropic 将所有这些变体归类为智能体系统(agentic systems),但在架构上对工作流程(workflows)和智能体(agents)进行了重要区分:
- 工作流程(Workflows):这类系统中,大语言模型(LLMs)和工具通过预定义的代码路径进行编排。
- 智能体(Agents):这类系统中,大语言模型(LLMs)动态地指导自身的流程和工具使用,保持对任务完成方式的控制。
接下来,我们将详细探讨这两种类型的智能体系统。
何时使用(以及何时不使用)智能体
在构建基于大语言模型(LLMs)的应用程序时,我们建议尽可能寻找最简单的解决方案,只有在需要时才增加复杂性。这可能意味着根本不需要构建智能体系统。智能体系统通常以延迟和成本为代价换取更好的任务性能,因此您需要权衡这种取舍是否合理。
当确实需要更高的复杂性时,工作流程(workflows)为定义明确的任务提供了可预测性和一致性,而智能体(agents)则是在需要灵活性和模型驱动的决策时更好的选择。然而,对于许多应用场景来说,通过检索和上下文示例优化单个大语言模型(LLM)调用通常已经足够。
何时以及如何使用框架
有许多框架可以简化智能体系统的实现,包括:
- LangGraph(来自LangChain);
- Amazon Bedrock 的AI Agent框架;
- Rivet,一个拖放式图形用户界面(GUI)大语言模型(LLM)工作流程构建工具;以及
- Vellum,另一个用于构建和测试复杂工作流程的GUI工具。
这些框架通过简化标准的底层任务(如调用大语言模型、定义和解析工具、以及链式调用)使入门变得容易。然而,它们通常会引入额外的抽象层,可能会掩盖底层的提示(prompts)和响应,从而增加调试难度。此外,它们可能会诱使开发者在简单设置足够的情况下增加不必要的复杂性。
我们建议开发者首先直接使用大语言模型(LLM)API:许多模式只需几行代码即可实现。如果您确实需要使用框架,请确保您理解底层的代码。对底层机制的错误假设是客户常见错误的来源。
构建模块、工作流与智能体(Building blocks, workflows, and agents)
在本节中,我们将探讨在生产环境中常见的智能体系统(agentic systems)模式。我们将从基础构建模块——增强型大语言模型(augmented LLM)开始,逐步增加复杂性,从简单的组合工作流(compositional workflows)到自主智能体(autonomous agents)。
构建模块:增强型大语言模型(Building block: The augmented LLM)
智能体系统的基本构建模块是一个通过增强功能(如检索、工具和记忆)优化的大语言模型(LLM)。我们当前的模型能够主动利用这些能力——生成自己的搜索查询、选择合适的工具,并决定保留哪些信息。
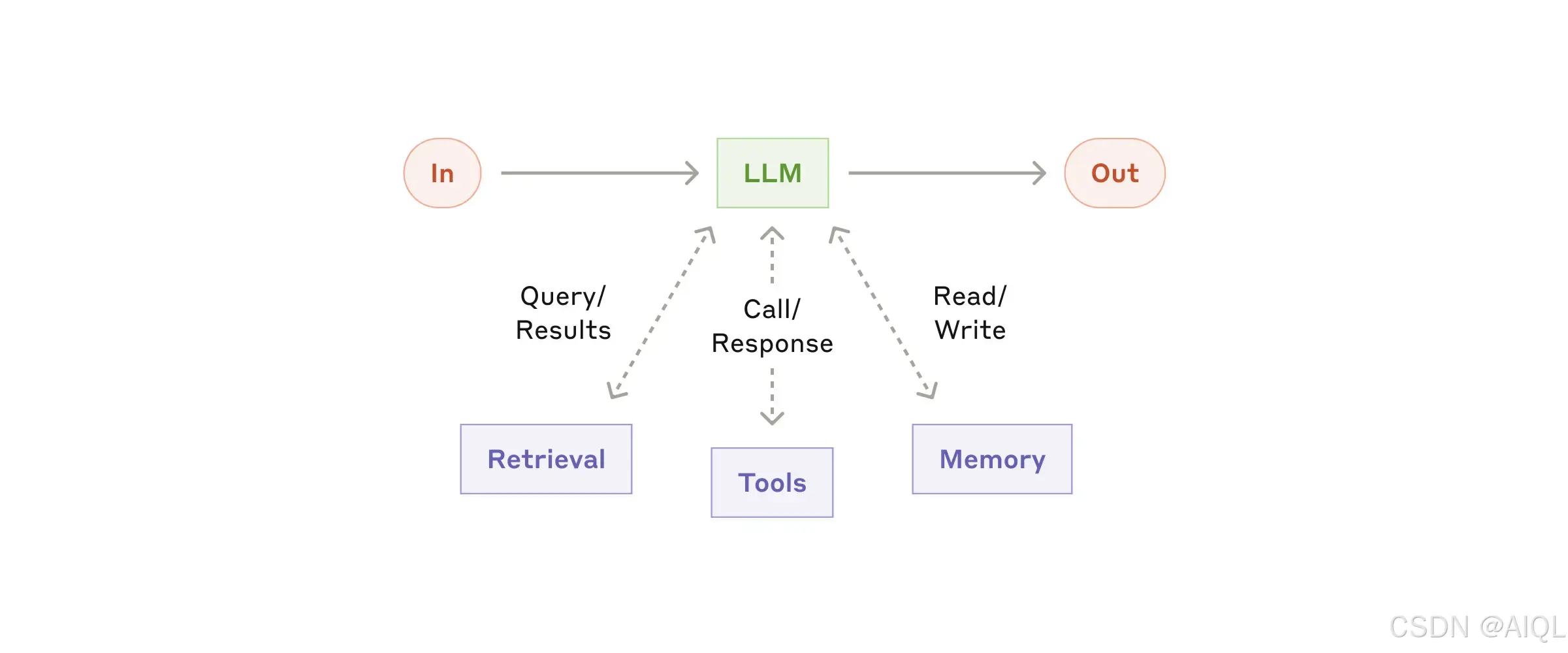
我们建议在实现过程中重点关注两个关键方面:
- 根据您的具体用例定制这些功能;
- 确保它们为大语言模型(LLM)提供易于使用且文档完善的接口。
虽然实现这些增强功能的方法有很多,但其中一种方式是通过Anthropic最近发布的模型上下文协议(Model Context Protocol)。该协议允许开发者通过简单的客户端实现与不断增长的第三方工具生态系统集成。
MCP(Model Context Protocol)www.zhihu.com/column/c_1849077942736527360
在本文的后续部分,我们将假设每次大语言模型(LLM)调用都能访问这些增强功能。
1. 工作流程:提示链(Prompt Chaining)
提示链(Prompt Chaining)是一种将任务分解为一系列步骤的方法,其中每个大语言模型(LLM)调用都处理前一个步骤的输出。你可以在任何中间步骤中添加程序化检查(如下图所示中的“gate”),以确保整个流程仍在正确的轨道上。
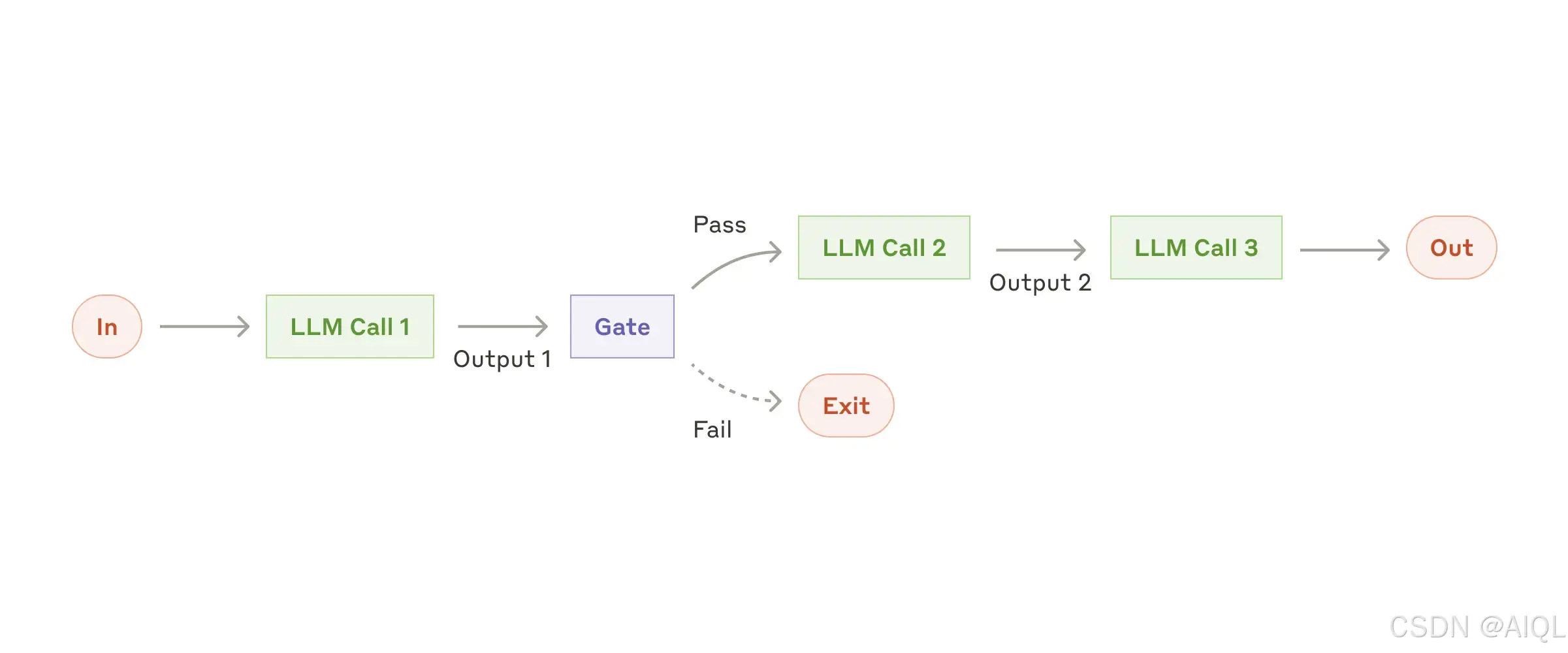
何时使用此工作流程:
此工作流程非常适合那些可以轻松且清晰地将任务分解为固定子任务的情况。其主要目标是通过让每个LLM调用处理更简单的任务,以牺牲一定的延迟(latency)来换取更高的准确性(accuracy)。
提示链(Prompt Chaining)适用的示例:
- 生成营销文案(Marketing Copy),然后将其翻译成另一种语言。
- 编写文档大纲(Outline),检查大纲是否符合特定标准,然后根据大纲撰写文档。
通过这种方式,提示链(Prompt Chaining)能够有效地将复杂任务分解为可管理的步骤,从而提高整体输出的质量和准确性。
2. 工作流程:路由(Routing)
路由(Routing)是一种对输入进行分类并将其引导至专门的后续任务的工作流程。这种方法实现了关注点分离(Separation of Concerns),并允许构建更专业化的提示(Specialized Prompts)。如果没有这种工作流程,针对某一种输入的优化可能会损害其他输入的性能。
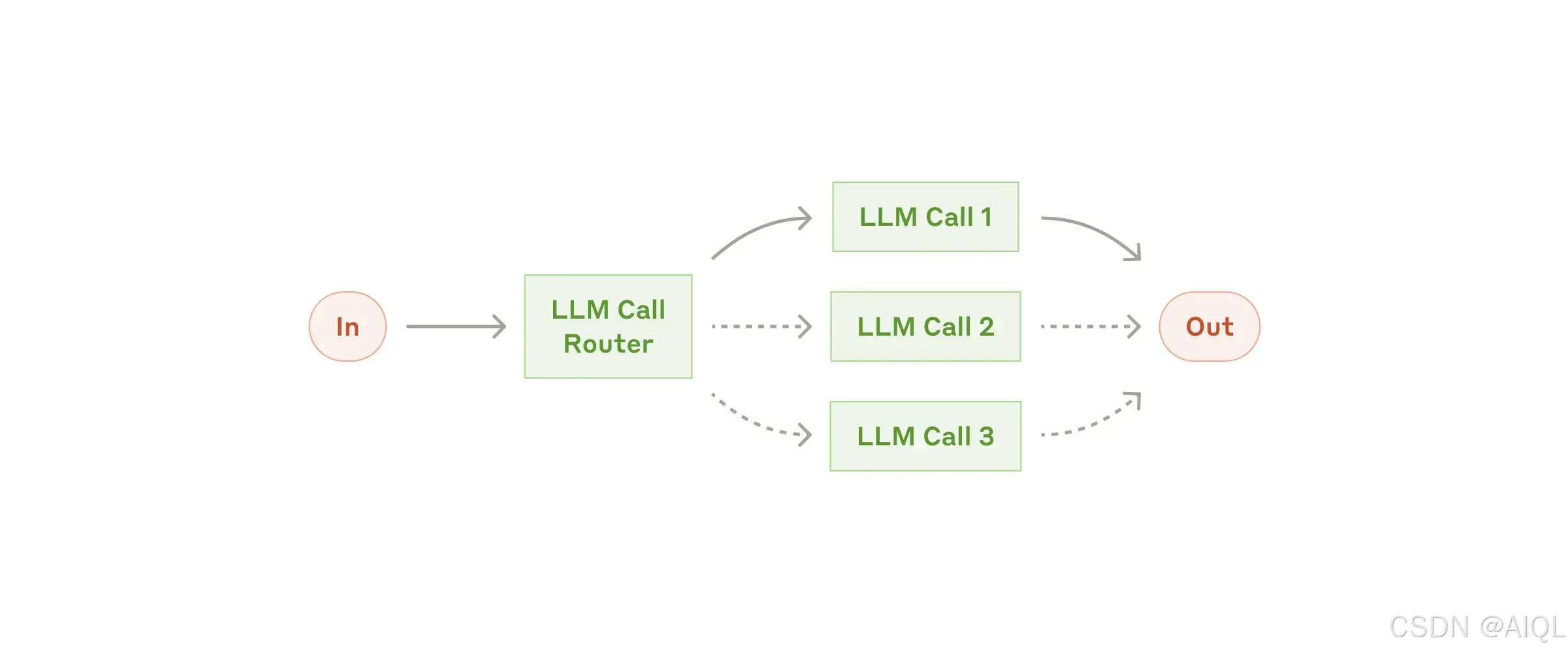
何时使用此工作流程:
路由(Routing)非常适合处理复杂任务,尤其是当任务可以明确分为不同类别且这些类别更适合单独处理时。此外,分类(Classification)需要能够被准确执行,无论是通过大语言模型(LLM)还是更传统的分类模型/算法(Classification Model/Algorithm)。
路由(Routing)适用的示例:
- 将不同类型的客户服务查询(如一般问题、退款请求、技术支持)引导至不同的下游流程、提示(Prompts)和工具中。
- 将简单/常见的问题路由到较小的模型(如Claude 3.5 Haiku),而将困难/不常见的问题路由到更强大的模型(如Claude 3.5 Sonnet),以优化成本(Cost)和速度(Speed)。
通过路由(Routing),可以更高效地处理多样化任务,同时确保每种输入都能得到最合适的处理方式,从而提升整体性能和资源利用率。
3. 工作流程:并行化(Parallelization)
大语言模型(LLMs)有时可以同时处理任务,并通过程序化方式聚合它们的输出。这种工作流程,即并行化(Parallelization),主要体现在两种关键形式中:
- 分段(Sectioning):将任务分解为独立的子任务并并行运行。
- 投票(Voting):多次运行同一任务以获得多样化的输出。
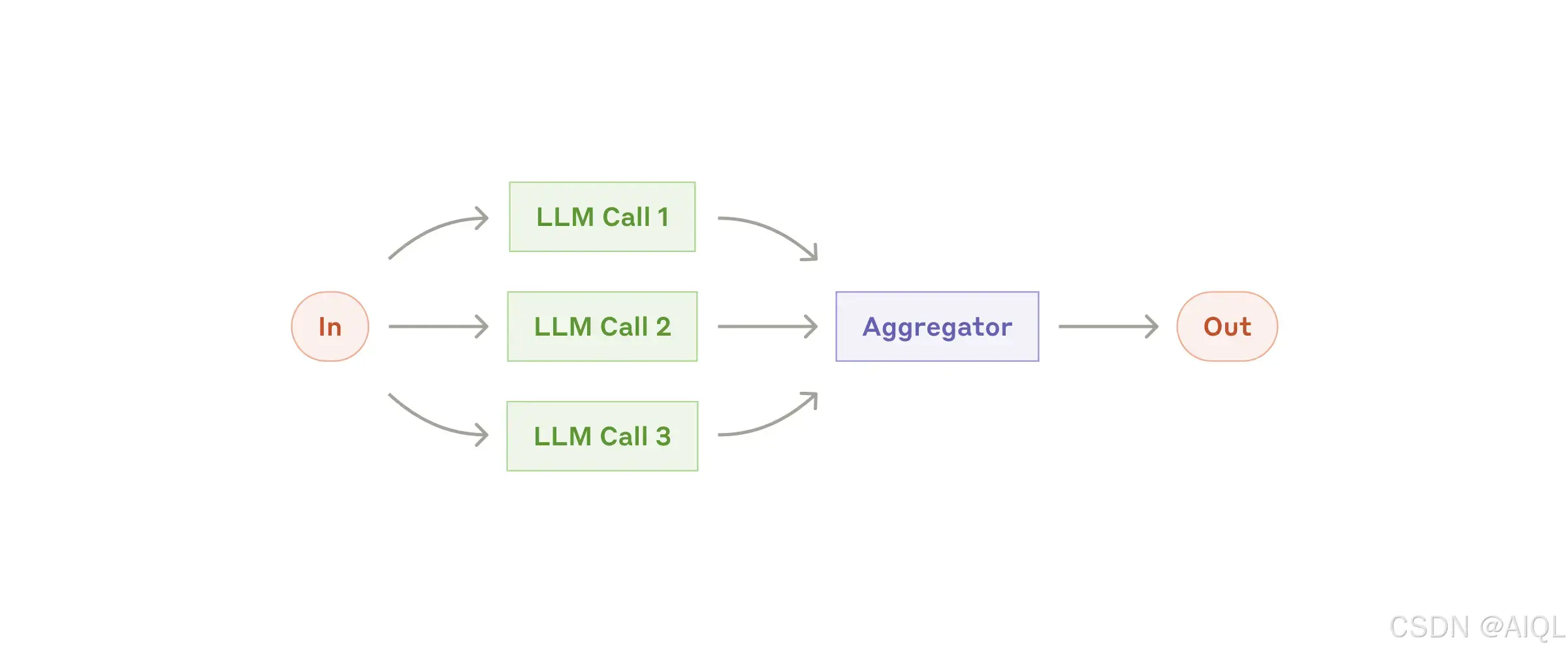
何时使用此工作流程:
并行化(Parallelization)在以下情况下非常有效:
- 当分解后的子任务可以并行执行以提高速度时;
- 当需要多种视角或多次尝试以获得更高置信度的结果时。
对于涉及多方面考虑的复杂任务,通常每个方面由单独的大语言模型(LLM)调用处理会表现更好,因为这样可以集中注意力于每个具体方面。
并行化(Parallelization)适用的示例:
分段(Sectioning):
- 实施防护措施(Guardrails),其中一个模型实例处理用户查询,而另一个模型实例筛查不适当的内容或请求。这种方式通常比让同一个大语言模型(LLM)调用同时处理防护措施和核心响应效果更好。
- 自动化评估(Automating Evals)以评估大语言模型(LLM)性能,其中每个大语言模型(LLM)调用评估模型在给定提示(Prompt)下的不同方面表现。
投票(Voting):
- 审查一段代码是否存在漏洞,其中多个不同的提示(Prompts)对代码进行审查并在发现问题时标记。
- 评估某段内容是否不适当,多个提示(Prompts)评估不同方面或要求不同的投票阈值(Vote Thresholds)以平衡误报(False Positives)和漏报(False Negatives)。
通过并行化(Parallelization),可以显著提升任务处理效率和结果的可靠性,尤其是在需要多角度或多层次分析的场景中。
4. 工作流程:协调器-工作者(Orchestrator-Workers)
在协调器-工作者(Orchestrator-Workers)工作流程中,一个中央大语言模型(LLM)动态地分解任务,将其分配给工作者大语言模型(Worker LLMs),并综合它们的结果。
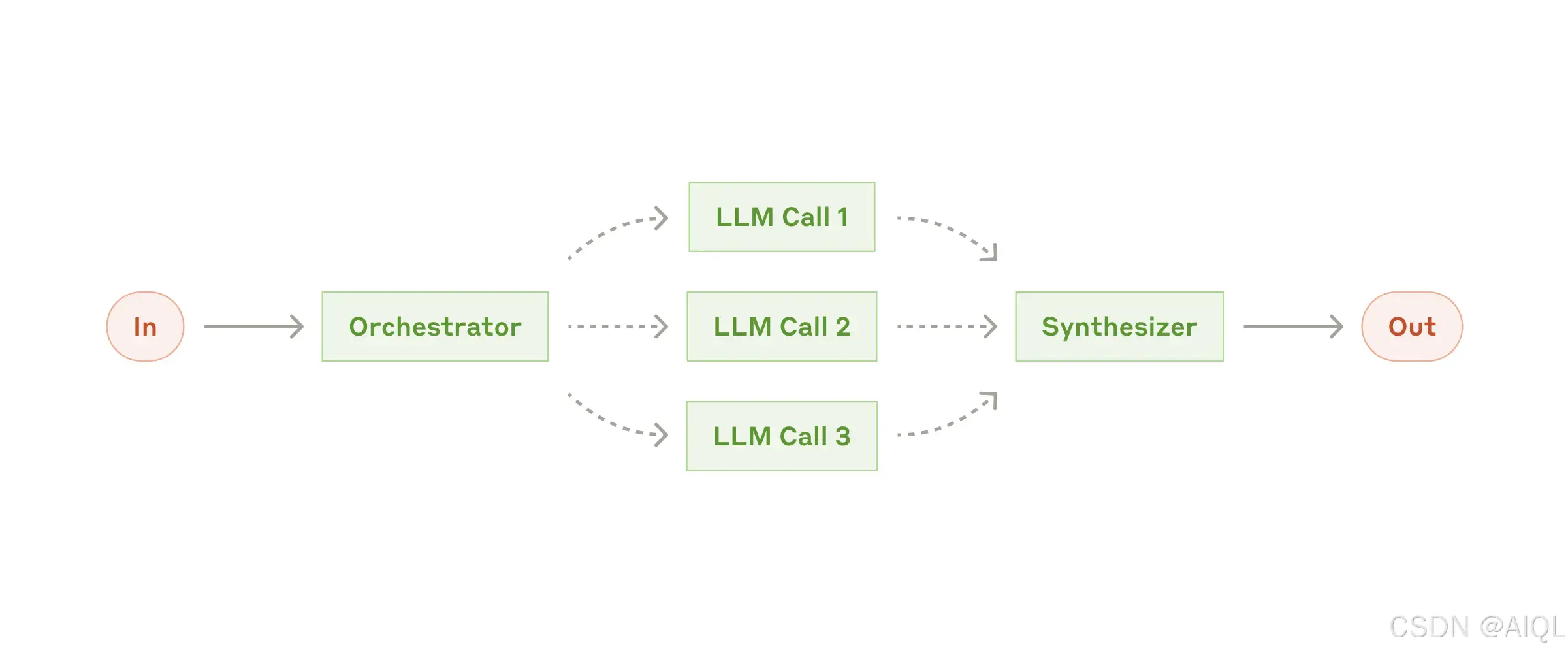
何时使用此工作流程:
这种工作流程非常适合复杂任务,尤其是在无法预先确定所需子任务的情况下(例如,在编码任务中,需要更改的文件数量以及每个文件中的更改性质可能取决于具体任务)。尽管在拓扑结构上与并行化(Parallelization)相似,但其关键区别在于灵活性——子任务并非预先定义,而是由协调器(Orchestrator)根据具体输入动态决定。
协调器-工作者(Orchestrator-Workers)适用的示例:
- 编码产品,每次需要对多个文件进行复杂更改。
- 搜索任务,涉及从多个来源收集和分析信息以寻找可能的相关内容。
通过协调器-工作者(Orchestrator-Workers)工作流程,可以高效处理动态性强、复杂度高的任务,同时确保任务分解和结果合成的灵活性。
5. 工作流程:评估器-优化器(Evaluator-Optimizer)
在评估器-优化器(Evaluator-Optimizer)工作流程中,一个大语言模型(LLM)调用生成响应,而另一个大语言模型(LLM)在循环中提供评估和反馈。
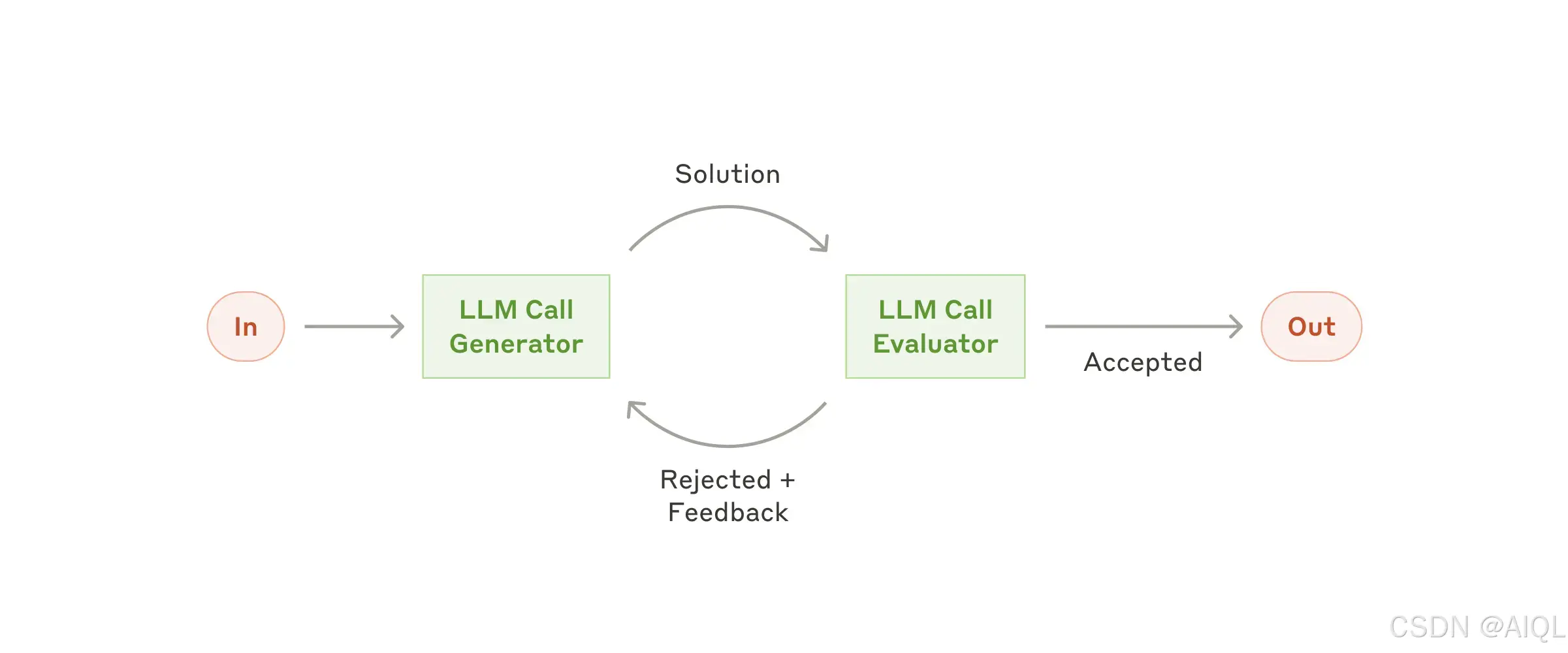
何时使用此工作流程:
这种工作流程在以下情况下特别有效:
- 当有明确的评估标准(Evaluation Criteria)时;
- 当迭代优化(Iterative Refinement)能够提供可衡量的价值时。
适合使用此工作流程的两个标志是:
- 当人类明确表达反馈时,大语言模型(LLM)的响应能够显著改进;
- 大语言模型(LLM)能够提供类似的反馈。
这与人类作家在撰写一篇精炼文档时可能经历的迭代写作过程(Iterative Writing Process)类似。
评估器-优化器(Evaluator-Optimizer)适用的示例:
- 文学翻译(Literary Translation),其中可能存在一些细微差别,翻译大语言模型(Translator LLM)可能最初无法捕捉,但评估大语言模型(Evaluator LLM)可以提供有用的批评和改进建议。
- 复杂搜索任务,需要多轮搜索和分析以收集全面信息,其中评估器(Evaluator)决定是否需要进行进一步的搜索。
通过评估器-优化器(Evaluator-Optimizer)工作流程,可以显著提升任务输出的质量,尤其是在需要精细调整和多轮优化的场景中。
6. 代理(Agents)
随着大语言模型(LLMs)在关键能力上的成熟——理解复杂输入(Understanding Complex Inputs)、进行推理和规划(Reasoning and Planning)、可靠地使用工具(Using Tools Reliably)以及从错误中恢复(Recovering from Errors)——代理(Agents)正在生产中逐渐崭露头角。代理(Agents)通常从人类用户的命令或交互式讨论开始工作。一旦任务明确,代理(Agents)会独立规划和操作,并可能返回向人类用户请求更多信息或判断。在执行过程中,代理(Agents)必须在每一步从环境中获取“真实数据”(Ground Truth)(例如工具调用结果或代码执行结果)以评估其进展。代理(Agents)可以在检查点(Checkpoints)或遇到阻碍时暂停以获取人类反馈。任务通常在完成后终止,但也常见设置停止条件(Stopping Conditions)(例如最大迭代次数)以保持控制。
代理(Agents)能够处理复杂的任务,但其实现通常较为直接。它们通常只是大语言模型(LLMs)在循环中基于环境反馈使用工具。因此,清晰且深思熟虑地设计工具集(Toolsets)及其文档至关重要。
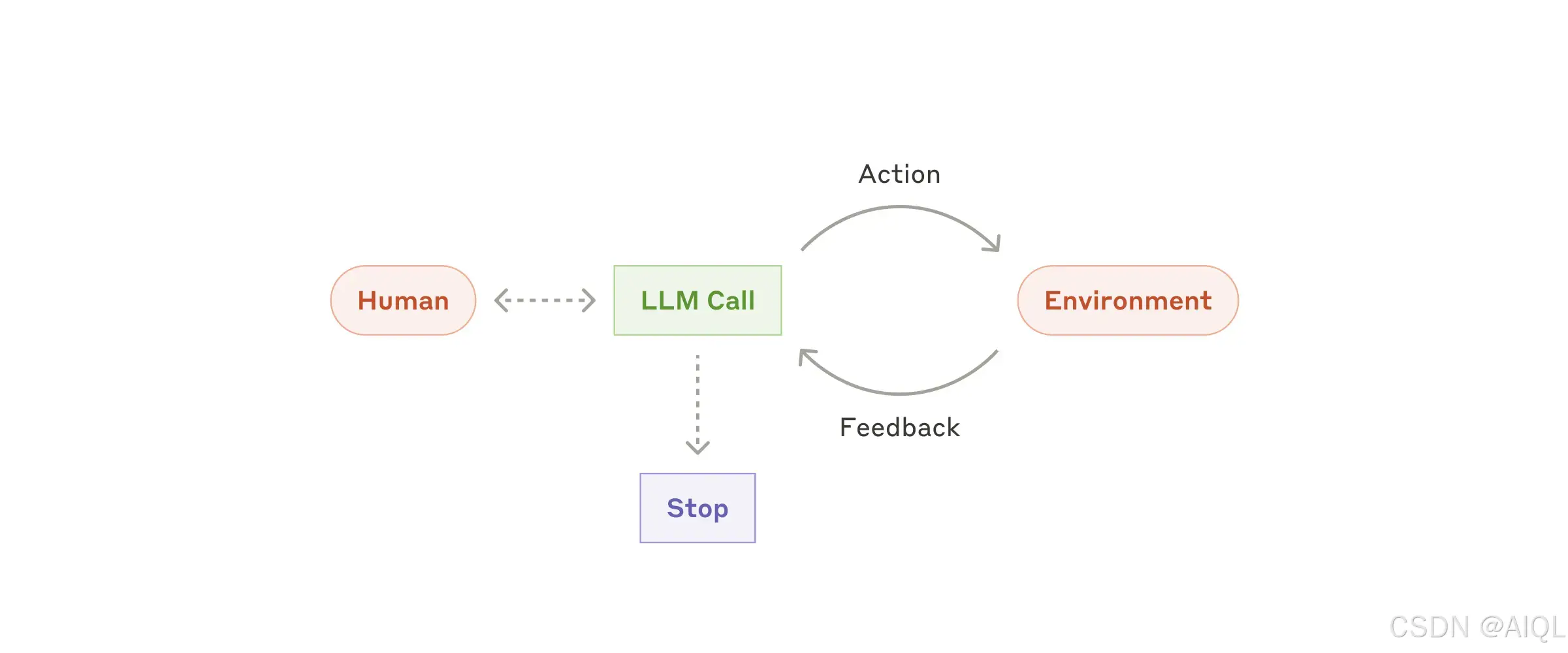
何时使用代理(Agents):
代理(Agents)适用于开放式问题(Open-Ended Problems),其中难以或无法预测所需的步骤数量,也无法硬编码固定路径。大语言模型(LLM)可能会运行多个回合,因此必须对其决策能力有一定程度的信任。代理(Agents)的自主性使其成为在受信任环境中扩展任务的理想选择。
代理(Agents)的自主性意味着更高的成本以及错误累积的可能性。我们建议在沙盒环境(Sandboxed Environments)中进行广泛测试,并设置适当的防护措施(Guardrails)。
代理(Agents)适用的示例:
- 客户支持(Customer Support)
客户支持(Customer Support)将熟悉的聊天机器人界面与通过工具集成增强的能力相结合。这种方法非常适合开放式代理(Open-Ended Agents),因为:
- 支持交互自然遵循对话流程,同时需要访问外部信息和操作;
- 可以集成工具以提取客户数据(Customer Data)、订单历史(Order History)和知识库文章(Knowledge Base Articles);
- 诸如发放退款(Issuing Refunds)或更新工单(Updating Tickets)等操作可以通过程序化方式处理;
- 成功可以通过用户定义的解决方案(User-Defined Resolutions)清晰衡量。
多家公司已经通过基于使用量的定价模型(Usage-Based Pricing Models)证明了这种方法的可行性,这些模型仅对成功解决的案例收费,显示出对其代理(Agents)有效性的信心。
2. 编码代理(Coding Agents)
软件开发领域展示了大语言模型(LLMs)功能的显著潜力,其能力从代码补全(Code Completion)发展到自主问题解决(Autonomous Problem-Solving)。代理(Agents)在这一领域特别有效,因为:
- 代码解决方案可以通过自动化测试(Automated Tests)验证;
- 代理(Agents)可以使用测试结果作为反馈迭代解决方案;
- 问题空间(Problem Space)定义明确且结构化;
- 输出质量可以客观衡量。
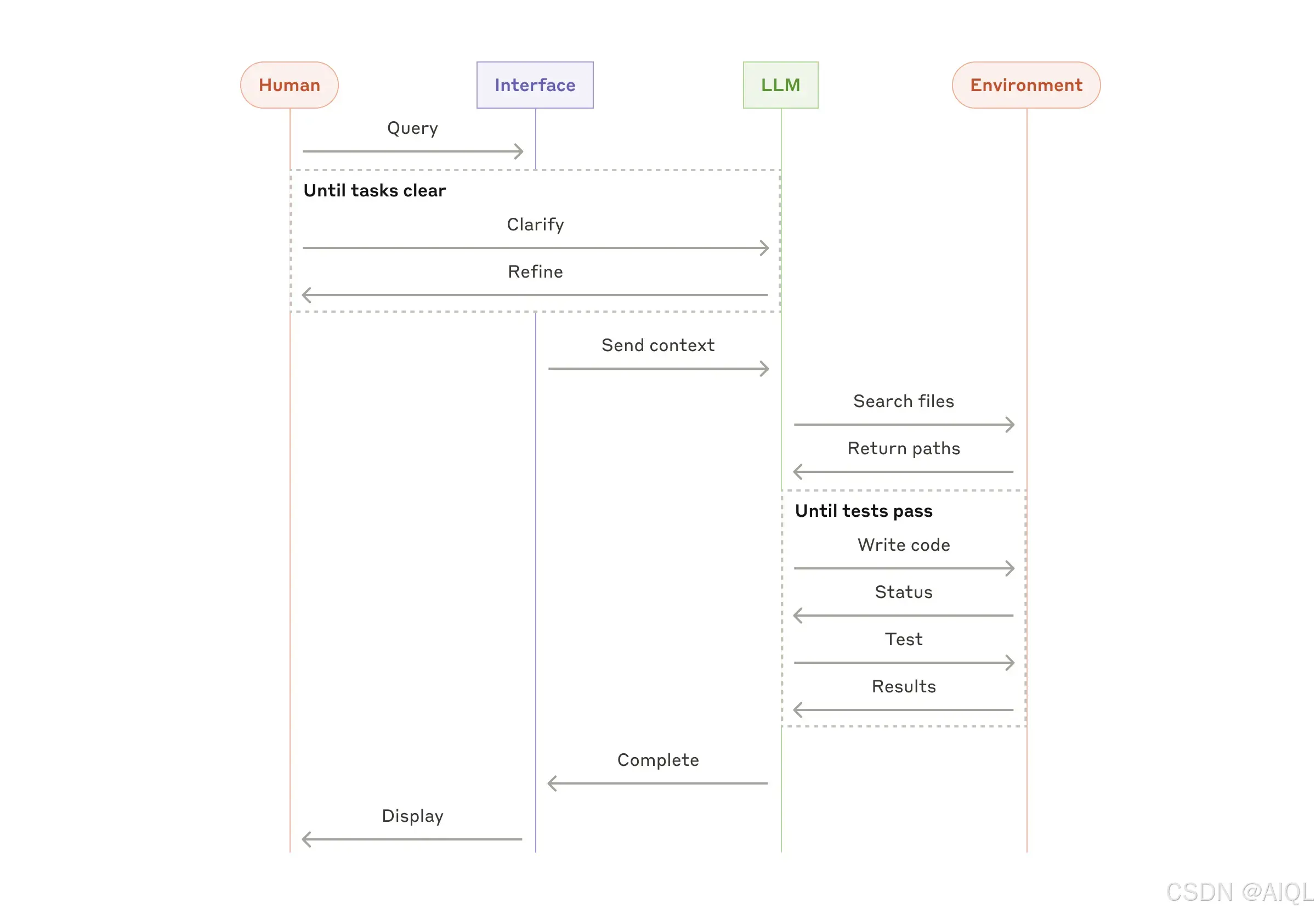
在Anthropic的项目实现中,代理(Agents)现在可以仅基于拉取请求描述(Pull Request Description)解决SWE-bench Verified基准测试中的真实GitHub问题。然而,尽管自动化测试有助于验证功能,人工审查(Human Review)对于确保解决方案符合更广泛的系统要求仍然至关重要。
通过客户支持(Customer Support)和编码代理(Coding Agents),代理系统(Agentic Systems)展示了其在处理复杂任务和提升效率方面的巨大潜力。
总结(Summary)
在大语言模型(LLMs)领域取得成功,并不是要构建最复杂的系统,而是要构建适合需求的系统。从简单的提示(Simple Prompts)开始,通过全面评估(Comprehensive Evaluation)进行优化,只有在简单解决方案不足时,才考虑添加多步代理系统(Multi-Step Agentic Systems)。
在实现代理(Agents)时,我们遵循以下三个核心原则:
- 保持设计的简洁性(Maintain Simplicity in Your Agent's Design):避免不必要的复杂性,确保系统易于理解和维护。
- 优先考虑透明度(Prioritize Transparency):明确展示代理的规划步骤(Planning Steps),使用户能够理解其决策过程。
- 精心设计代理-计算机接口(Agent-Computer Interface, ACI):通过详细的工具文档(Tool Documentation)和测试(Testing)确保接口的可靠性和易用性。
框架(Frameworks)可以帮助您快速入门,但在进入生产环境时,不要犹豫减少抽象层(Abstraction Layers)并使用基本组件(Basic Components)进行构建。通过遵循这些原则,您可以创建不仅功能强大,而且可靠、可维护并赢得用户信任的代理(Agents)。
通过灵活结合与定制这些模式(Combining and Customizing These Patterns),开发者能够构建出高效、透明且用户友好的代理系统(Agentic Systems),从而满足多样化的需求。
我的个人理解
通过对前文的分析和实际开发中的经验,我对工作流程选择和代理(Agents)的使用有以下几点理解:
1. 工作流程的选择
- 简单任务:对于可以明确分解为固定子任务的工作,提示链(Prompt Chaining)和并行化(Parallelization)是高效的选择。它们通过分步骤或多线程处理任务,能够显著提升准确性和速度。
- 复杂任务:对于无法预先确定子任务或需要动态调整的工作,协调器-工作者(Orchestrator-Workers)和评估器-优化器(Evaluator-Optimizer)更为适合。它们通过动态任务分解和迭代优化,能够处理更复杂的场景。
- 路由任务:当任务涉及多种类型且需要分类处理时,路由(Routing)可以将输入引导至最合适的处理路径,从而提高效率和准确性。
2. 代理(Agents)的使用
- 代理系统(Agentic Systems)的核心优势在于其自主性和灵活性,能够处理开放式问题(Open-Ended Problems)和复杂任务。然而,其能力高度依赖大语言模型(LLMs)的函数调用(Function Call)准确性。
- 我的个人实际开发测试中,即使是GPT-4在函数调用(Function Call)方面也存在一定局限性,可能导致错误累积或执行偏差。因此,在生产环境中,代理(Agents)的使用需要谨慎(其实就是一旦翻车,你根本没有挽救的余地,因为太依赖语言模型的能力了)。
3. 实际生产环境的优化策略
- 简化场景:在实际应用中,建议优先选择前几个简单且固定的工作流程(如提示链和并行化),以降低复杂性并提升执行效果。
- 逐步引入代理(Agents):在受控环境中逐步引入代理系统(Agentic Systems),并通过沙盒测试(Sandbox Testing)和防护措施(Guardrails)确保其可靠性。
- 工具设计优化:精心设计工具集(Toolsets)和代理-计算机接口(Agent-Computer Interface, ACI),确保其文档清晰且功能可靠,从而提升代理(Agents)的执行准确性。
4. 概要(全文看下来其实就说了这三件事)
- 选择合适的工具:并非所有任务都需要复杂的代理系统(Agentic Systems),简单的工作流程(如提示链和并行化)在大多数场景下已经足够高效。
- 平衡复杂性与效果:只有在简单解决方案无法满足需求时,才应考虑引入更复杂的代理(Agents)或多步工作流程。
- 持续迭代与测试:通过持续的性能评估(Performance Evaluation)和迭代优化(Iterative Refinement),逐步提升系统的可靠性和用户信任度。
通过以上策略,可以在实际生产环境中最大化大语言模型(LLMs)和代理系统(Agentic Systems)的价值,同时降低潜在风险。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)