
02 大模型学习——Ollama
Ollama 是一个开源的大型语言模型服务工具,它旨在简化在本地运行大型语言模型的过程,降低使用大型语言模型的门槛。让用户能轻松下载、运行和管理各种开源的大型语言模型,例如Llama3、Mistral、Qwen2 等。Ollama 支持的模型完全开源免费,任何人都可以自由使用、修改和分发,它的优势在于简单易用、模型丰富以及资源占用低。Ollama 兼容 Windows、Linux 和 MacOS
一、什么是Ollama?
Ollama 是一个开源的大型语言模型服务工具,它旨在简化在本地运行大型语言模型的过程,降低使用大型语言模型的门槛。让用户能轻松下载、运行和管理各种开源的大型语言模型,例如Llama3、Mistral、Qwen2 等。
Ollama 支持的模型完全开源免费,任何人都可以自由使用、修改和分发,它的优势在于简单易用、模型丰富以及资源占用低 。
Ollama 兼容 Windows、Linux 和 MacOS 操作系统。使用 Ollama,您仅需一行命令即可启动模型。
Ollama中文网:https://ollama.fan/getting-started
二、window中安装Ollama
1.Windows 10 或更新版本,家庭版或专业版
2.如果您有 NVIDIA 显卡,需要 NVIDIA 452.39 或更新版本的驱动程序
ollama下载地址:Download Ollama on macOS
官方支持的模型,可以在 library 上面找到。
例:以qwen为例,根据自己电脑显存性能, 选择适宜的版本。复制官网运行代码,终端运行,若未下载会自动下载
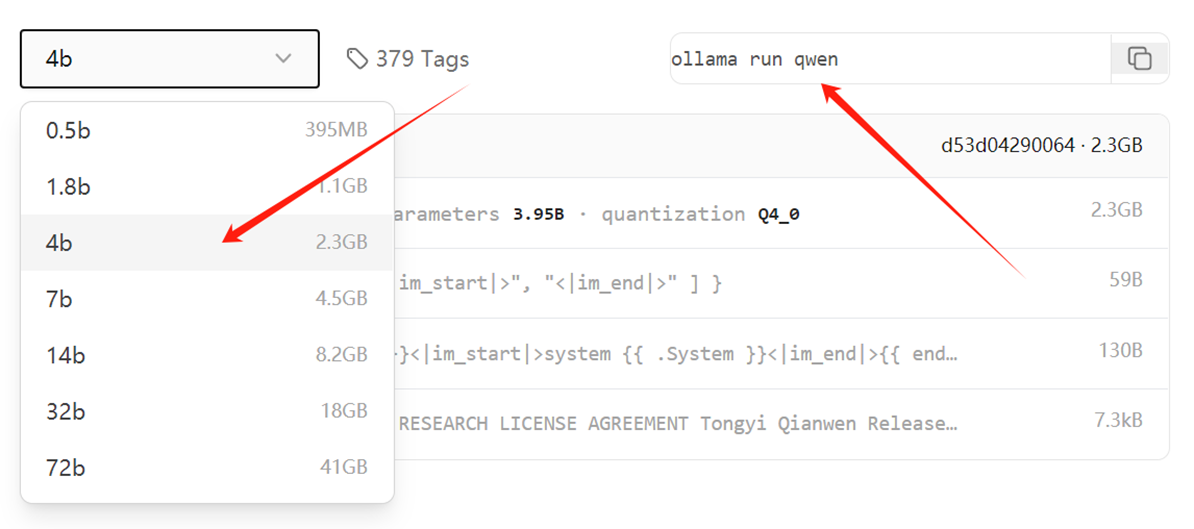
1、模型默认保存地址:
macOS: ~/.ollama/models
Linux: /usr/share/ollama/.ollama/models #作为系统服务启动时
Linux: /home/<username>/.ollama/models #当前用户启动时
Windows: C:\Users\<username>\.ollama\models
2、修改下载模型的默认存放目录
可参考博客:Ollama自定义安装路径,Ollama自定义模型下载目录-CSDN博客
1.windows用户
只设置当前用户:setx OLLAMA_MODELS "D:\ollama_model"
为所有用户设置:setx OLLAMA_MODELS "D:\ollama_model" /M
重启终端(setx命令在Windows中设置环境变量时,这个变量的更改只会在新打开的命令提示符窗口或终端会话中生效。)重启ollama服务
3、终端输入ollama list 查看本地已下载模型
三、使用python中调用ollama服务
安装包
pip install ollama -i Simple Index
启动ollama服务
ollama serve
python调用大模型
import ollama
response = ollama.chat(
model= "qwen2:0.5b",
# HumanMessage,SystemMessage,AIMessage
messages=[{
"role":"user",
"content":"我要去重庆旅游,请给我一些出行建议。"
}]
)
print(response["message"]["content"])四、大模型架构
1、MOE(Mixture of Experts)架构
混合专家模型,稀疏激活和动态路由机制,核心思想是将模型分解为多个较小的“专家”模型,并根据输入数据的特点动态地选择和组合这些专家模型来做出预测。
优势:
- 计算效率高:只需要激活部分专家模型,MOE架构可以显著减少计算资源的需求。
- 可扩展性强:可以很容易地通过增加专家模型的数量来扩展模型的规模。
- 灵活性高:可以根据任务需求调整专家模型的类型和数量。
GPT-4、DeepSeek-V3、腾讯混元 Large、Gemini
2、Dense架构
每一层的所有神经元都与其前一层和后一层的所有神经元相连接。这种架构也被称为“全连接层”或“密集层”(Dense Layer),稠密架构。信息在网络中可以自由流动,每个神经元都可以访问到整个输入空间的信息。这种设计使得Dense架构在处理复杂函数和模式识别任务时非常有效。
GPT系列(OpenAI)、BERT(Google)、RoBERTa(Facebook AI)

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)