
Weakly-Supervised Audio-Visual Video Parsing with Prototype-based Pseudo-Labeling
本文提出了一种基于原型的伪标签方法,用于解决弱监督音视频视频解析(AVVP)问题。该问题旨在通过视频级别的事件标签,在视频中定位和分类可听、可见或两者兼具的事件。现有方法通常采用多实例学习(MIL)技术,但容易误分类。本文方法首先通过聚类训练数据中的关键片段,构建多个“原型”特征,然后基于这些原型与训练片段的特征相似性,为所有训练片段分配伪标签,并在弱监督和强监督下重新训练模型。通过使用伪标签进行

标题:弱监督音视频视频解析与基于原型的伪标签
原文链接:https://openaccess.thecvf.com/content/CVPR2024/papers/Rachavarapu_Weakly-Supervised_Audio-Visual_Video_Parsing_with_Prototype-based_Pseudo-Labeling_CVPR_2024_paper.pdf
发表:CVPR-2024
摘要
本文探讨了弱监督音视频视频解析(AVVP)问题,目标是在视频中标记事件为可听、可见或两者兼具,并在时间上定位和分类这些事件。由于在训练时只能访问视频级别的事件标签,而在测试时需要预测片段(帧)级别的事件标签,因此该问题具有挑战性。现有方法通常采用多实例学习(MIL)技术,这些方法往往只关注最具区分性的片段,导致频繁的误分类。我们的方法首先通过聚类训练数据中为每个事件类识别的关键片段,构建多个“原型”特征。然后,基于这些原型与所有训练片段的特征相似性,为所有训练片段分配伪标签,并在弱监督和强监督下重新训练模型。我们通过使用伪标签进行对比学习来结构化特征空间。实验表明,我们的方法在弱监督AVVP任务上优于现有方法。我们还展示了使用弱监督和迭代重新估计的伪标签进行学习可以解释为期望最大化(EM)算法,为我们的训练过程提供了进一步的见解。
1. 引言
本文探讨了弱监督音视频视频解析(AVVP)问题,目标是在给定视频级别(弱)事件标签的情况下,对视频中的事件进行分类并在时间和模态上定位它们。这种公式具有吸引力,因为它避免了昂贵且繁琐的细粒度标注。此外,其他弱监督视频时间预测任务可以作为AVVP的特殊情况。例如,音视频事件定位(AVEL)考虑同时可听和可见的事件,而时间动作定位(TAL)仅考虑可见事件。AVVP具有挑战性,因为事件可能仅出现在音频流、视频流或两者同时出现。音视频数据无处不在,事件在外观和持续时间上具有高度可变性。
图1展示了在弱监督下使用多实例学习(MIL)训练的模型[48]与我们的方法的预测示例。为清晰起见,我们仅展示视觉事件。MIL模型在开始时正确检测到了 “吉他” 事件,但随后出现了一些错误(红色虚线框)。此外,尽管最后三帧相似,但该模型对它们的标记并不一致。我们的方法始终能实现良好的定位。“GT” 表示真实情况。
现有的弱监督AVVP方法使用多实例学习(MIL)技术,在训练时优化视频级别标签,在评估时进行帧级别预测。MIL方法的一个缺点是模型可能只学习关注最具区分性(“显著”)的实例(即视频中的音频/视频帧),并且仍然能够成功最小化训练损失。这意味着这些模型可能无法可靠地检测事件的完整时间范围。图1展示了一个MIL模型在AVVP任务中未能准确定位事件的示例。此外,该模型对视觉上相似的帧进行了不一致的标记。MIL模型中误分类的另一个原因是它们通常包含一个帧级别分类器,每个事件类只有一个权重向量。然而,这可能不足以捕捉事件在时间、模态和示例中的类内变化。
我们提出以下思路来解决这些问题。首先,鉴于MIL模型可以找到触发视频级别标签的区分性帧,我们可以识别这些帧并将它们的预测标签传播到训练数据中的其他帧,从而在训练数据上创建帧级别的伪标签。其次,我们可以使用这些特征为每个事件类构建多个原型,确保更鲁棒的表征来传播伪标签。一旦为训练数据完成此操作,我们可以使用伪标签的强监督和视频级别标签的弱监督重新训练模型。图1展示了我们的方法比MIL模型产生更准确预测的示例。由于我们的方法依赖于特征相似性,我们通过使用伪标签进行对比学习进一步强化特征空间的结构。
我们在每个epoch后重新估计训练数据上的伪标签,并在下一个epoch中使用它们进行训练。我们展示了这种训练过程可以通过期望最大化(EM)视角来解释,其中未知的帧级别标签作为潜在变量。这种解释提供了收敛保证和进一步的见解。我们的方法在弱监督AVVP任务上实现了最先进的性能,并且在相关的弱监督时间动作定位(TAL)任务上也表现良好。我们的贡献总结如下:
- 我们提出了一种基于原型的伪标签方法,用于弱监督AVVP,利用特征空间中的相似性。
- 我们展示了如何使用伪标签进行对比学习,以帮助语义结构化特征空间。
- 我们提出了我们训练过程的期望最大化视角。
- 我们在弱监督AVVP任务上展示了最先进的结果,并在弱监督TAL任务的多个指标上表现出色。
2. 相关工作
音视频视频解析(AVVP)。Tian等人将AVVP表述为多模态多实例学习(MMIL)问题,并提出了一种具有学习池化函数的混合注意力网络(HAN)来捕捉单模态和跨模态上下文。大多数后续工作使用了HAN架构并结合其他技术以提高性能。Lamba等人利用跨模态信息通过对抗性和自监督损失学习更好的表征。Wu等人通过交换视频对之间的音频/视频流来估计模态级别标签,然后在更强的监督下重新训练。Lin等人使用跨视频和跨模态信号(如跨模态的事件共现)作为额外的监督来源。Mo等人利用多模态分组学习判别子空间。Gao等人从单模态和跨模态信息中提取事件的“存在”和“不存在”证据。Fu等人关注模态之间的学习率不平衡,Zhou等人利用CLIP获取片段标签,而我们的工作利用模型内特征相似性进行伪标签。PoiBin将事件的正帧数量建模为潜在变量以改进定位。与之前的方法不同,我们估计片段级别的伪标签并在全监督下重新训练。
伪标签。伪标签是指使用训练模型的预测为未标记数据估计标签。这种方法已被用于改进多个弱监督任务的性能,包括目标检测和图像分类。一些工作使用伪标签来改进时间动作定位(TAL)任务的性能,从模型输出或注意力权重生成标签。Luo等人将TAL任务表述为期望最大化,使用伪标签近似E和M步骤。与这些方法不同,我们提出了一种基于特征相似性的伪标签策略,由模型预测和视频的弱标签引导。
基于原型的分类。原型学习与最近邻(非参数)分类器激发了各种机器学习技术。最近,将这种方法整合到深度学习方法中的兴趣增加,例如零样本、少样本、无监督和监督学习。原型学习也被广泛用于图像分割。最近,基于原型的方法也被用于半监督图像和文本分类。一些工作将基于原型的方法与多实例学习结合使用。例如,Rymarczyk等人将大型医学图像处理为补丁包,Huang等人使用图卷积网络为TAL任务学习原型。这些工作采用嵌入级别的MIL方法,每个类一个原型,而我们采用实例级别的MIL并为每个事件类构建多个原型。
3. 背景
3.1 问题定义
在音视频视频解析(AVVP)问题中,我们的目标是在无约束视频中识别可听或可见的事件,并在时间上定位它们。具体来说,给定一个由 T T T个非重叠时间片段组成的视频 x x x,每个片段 x t = ( x t a , x t v ) x_t = (x^a_t, x^v_t) xt=(xta,xtv)包含音频( A A A)和视频( V V V)流,我们的目标是将每个片段分类为 C C C个可能的事件(例如,唱歌、车辆移动等)。在测试时,我们需要为每个音频和视频片段预测片段级别的事件标签 y t = ( y t a , y t v ) y_t = (\mathbf{y}_t^a, \mathbf{y}_t^v) yt=(yta,ytv),其中 y t a , y t v ∈ { 0 , 1 } C \mathbf{y}_t^a, \mathbf{y}_t^v \in \{0,1\}^C yta,ytv∈{0,1}C分别是片段级别的音频和视频事件标签。
弱监督。在弱监督AVVP中,对于每个视频 x x x,我们只能访问相应的视频级别事件标签向量 w = ( w 1 , … , w C ) ∈ { 0 , 1 } C \mathbf{w} = (w_1, \ldots, w_C) \in \{0,1\}^C w=(w1,…,wC)∈{0,1}C,其中 w c = 1 w_c = 1 wc=1表示视频中任何片段包含第 c c c个事件, w c = 0 w_c = 0 wc=0表示不包含。这种弱视频级别标签仅指示事件是否在视频中发生。在评估时,我们仍然需要预测片段级别标签 { ( y t a , y t v ) } t = 1 T \{(\mathbf{y}_t^a, \mathbf{y}_t^v)\}_{t=1}^T {(yta,ytv)}t=1T。注意,多个事件可以同时在视频中发生,即 ∑ c w c ≥ 1 \sum_c w_c \geq 1 ∑cwc≥1,每个片段可能包含多个事件。
3.2 MIL框架
我们采用实例级别的MIL方法,如之前的工作所做:首先,每个实例(即音频/视频片段)被分配一个分类分数(即一个 C C C维向量)。然后,通过池化操作聚合这些分数,并使用聚合结果计算损失。在我们的情况下,这看起来像:
[ { f t a } t = 1 T , { f t v } t = 1 T ] = f θ ( x ) \left[\{\mathbf{f}_t^a\}_{t=1}^T, \{\mathbf{f}_t^v\}_{t=1}^T\right] = f_\theta(x) [{fta}t=1T,{ftv}t=1T]=fθ(x)
p t m = g ϕ ( f t m ) ∈ [ 0 , 1 ] C , ∀ t ∈ [ 1 , T ] , m ∈ { a , v } \mathbf{p}_t^m = g_\phi(\mathbf{f}_t^m) \in [0,1]^C, \quad \forall t \in [1,T], m \in \{a,v\} ptm=gϕ(ftm)∈[0,1]C,∀t∈[1,T],m∈{a,v}
w ^ = σ θ , x ( { p t a } t = 1 T , { p t v } t = 1 T ) ∈ [ 0 , 1 ] C \mathbf{\hat{w}} = \sigma_{\theta,x} \left(\{\mathbf{p}_t^a\}_{t=1}^T, \{\mathbf{p}_t^v\}_{t=1}^T\right) \in [0,1]^C w^=σθ,x({pta}t=1T,{ptv}t=1T)∈[0,1]C
其中 f θ f_\theta fθ是特征提取器(编码器), g ϕ g_\phi gϕ是特征分类器, σ θ , x \sigma_{\theta,x} σθ,x是MIL池化操作符。预测的视频级别概率向量 w ^ \mathbf{\hat{w}} w^是从片段级别分类分数 { p t m } \{\mathbf{p}_t^m\} {ptm}计算得出的,而片段级别分类分数是从片段特征 { f t m } \{\mathbf{f}_t^m\} {ftm}计算得出的。我们采用混合注意力网络(HAN)架构来实现 f θ f_\theta fθ、 g ϕ g_\phi gϕ和 σ \sigma σ。这里, f θ f_\theta fθ由具有跨模态注意力的基于Transformer的编码器组成, g ϕ g_\phi gϕ是具有Sigmoid激活的线性分类器。 σ \sigma σ使用基于注意力的平均池化。我们在补充材料中提供了实现细节。
该模型通过最小化加权交叉熵损失进行端到端训练:
L MIL = CE ( w ^ , w ) \mathcal{L}_{\text{MIL}} = \text{CE}(\mathbf{\hat{w}}, \mathbf{w}) LMIL=CE(w^,w)
其中权重与数据集中事件分布成反比。在测试时,我们从公式(2)中获取片段级别预测。
4. 基于原型的伪标签
虽然实例级别的MIL能够找到触发视频级别标签的关键片段,但它们通常错过了视频中事件的完整时间范围。然而,如果我们能够为训练视频中的每个标签识别这些区分性片段,我们可以使用它们来构建一组代表每个类的原型特征。片段与事件类原型特征的高度相似性意味着该片段可能包含该事件。我们使用这个想法为训练视频中的所有片段生成伪标签,然后在强监督下重新训练模型。图2展示了我们方法的概述。我们在算法1中提供了伪代码。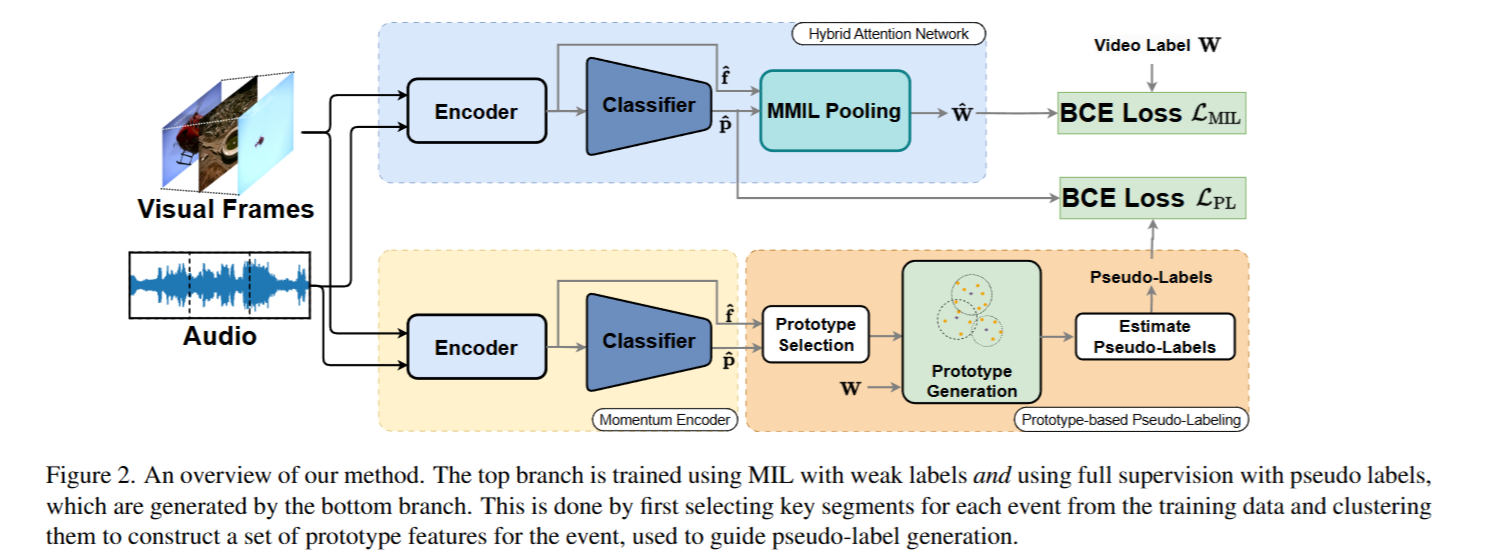
图2. 我们方法的概述。顶部分支使用弱标签通过多实例学习(MIL)进行训练,并使用由底部分支生成的伪标签进行完全监督训练。具体做法是,首先从训练数据中为每个事件选择关键片段,然后对这些片段进行聚类,以构建该事件的一组原型特征,这些原型特征用于指导伪标签的生成。
4.1 构建原型特征
片段级别的线性分类器 g ϕ g_\phi gϕ(公式(2))本身可以被视为基于原型的分类器,其中每个类的原型是 ϕ \phi ϕ中相应的权重向量。然而,这要求事件在训练数据中的跨模态和示例中具有相似的表征。我们通过以下两个步骤为每个类构建多个原型。
片段选择。对于每个训练视频 x x x,我们为目标事件 c c c(如果 w c = 1 w_c = 1 wc=1)找到正片段 P x ( c ) \mathcal{P}_x(c) Px(c),这些片段是模型高度自信包含该事件的片段。即:
P x ( c ) = { { x t m ∈ x ∣ p t m ( c ) ≥ γ p ∗ ( c ) } 如果 w c = 1 ϕ 如果 w c = 0 , \mathcal{P}_x(c) = \begin{cases} \{x_t^m \in x | \mathbf{p}_t^m(c) \geq \gamma p^*(c)\} & \text{如果 } w_c = 1 \\ \phi & \text{如果 } w_c = 0, \end{cases} Px(c)={{xtm∈x∣ptm(c)≥γp∗(c)}ϕ如果 wc=1如果 wc=0,
其中 γ ∈ ( 0 , 1 ] \gamma \in (0,1] γ∈(0,1]是一个超参数, p ∗ ( c ) = max t , m p t m ( c ) p^*(c) = \max_{t,m} \mathbf{p}_t^m(c) p∗(c)=maxt,mptm(c)是给定视频中事件 c c c在时间和模态上的最大预测概率。显然,当 w c = 1 w_c = 1 wc=1时, P x ( c ) \mathcal{P}_x(c) Px(c)将包含至少一个来自视频 x x x的音频/视频片段。我们假设这些片段高度可能包含事件 c c c(因此可能是真正的正例)。我们还为目标事件 c c c找到负片段 N x ( c ) \mathcal{N}_x(c) Nx(c),这些片段是模型高度自信不包含该事件的片段(当 w c = 1 w_c = 1 wc=1时,可能是真正的负例),或者当 w c = 0 w_c = 0 wc=0时,模型高度自信包含该事件的片段(明确的正例):
N x ( c ) = { { x t m ∈ x ∣ p t m ( c ) ≤ β p ∗ ( c ) } 如果 w c = 1 { x t m ∈ x ∣ p t m ( c ) = p ∗ ( c ) ≥ 0.5 } 如果 w c = 0 , \mathcal{N}_x(c) = \begin{cases} \{x_t^m \in x | \mathbf{p}_t^m(c) \leq \beta p^*(c)\} & \text{如果 } w_c = 1 \\ \{x_t^m \in x | \mathbf{p}_t^m(c) = p^*(c) \geq 0.5\} & \text{如果 } w_c = 0, \end{cases} Nx(c)={{xtm∈x∣ptm(c)≤βp∗(c)}{xtm∈x∣ptm(c)=p∗(c)≥0.5}如果 wc=1如果 wc=0,
其中 β ∈ ( 0 , 1 ) \beta \in (0,1) β∈(0,1)是一个超参数,设置为一个较小的值以检索不包含事件 c c c的片段(如果有的话)。注意,即使 w c = 1 w_c = 1 wc=1, N x ( c ) \mathcal{N}_x(c) Nx(c)也可能不包含任何片段,即可能为空集。
最后,我们将所有训练数据 D \mathcal{D} D中的正例和负例集合聚合起来,得到原型片段:
P ( c ) = ⋃ x ∈ D P x ( c ) , N ( c ) = ⋃ x ∈ D N x ( c ) . \mathcal{P}(c) = \bigcup_{x \in \mathcal{D}} \mathcal{P}_x(c), \quad \mathcal{N}(c) = \bigcup_{x \in \mathcal{D}} \mathcal{N}_x(c). P(c)=⋃x∈DPx(c),N(c)=⋃x∈DNx(c).
原型生成。我们现在通过假设每个事件类有多个原型(特征向量)来生成多个原型,以更好地捕捉跨模态和训练示例的类内变化,并创建更鲁棒的表征。
首先,我们使用公式(1)提取 P ( c ) \mathcal{P}(c) P(c)和 N ( c ) \mathcal{N}(c) N(c)中所有片段的特征,并将生成的特征集称为 F P ( c ) \mathcal{F}_{\mathcal{P}}(c) FP(c)和 F N ( c ) \mathcal{F}_{\mathcal{N}}(c) FN(c)。这里,我们使用动量编码器 f θ ~ f_{\tilde{\theta}} fθ~而不是 f θ f_\theta fθ,它具有相同的架构,但其权重设置为 θ \theta θ在训练步骤中的指数移动平均(EMA): θ ← ( 1 − η ) θ ^ + η θ \theta \leftarrow (1-\eta)\hat{\theta} + \eta\theta θ←(1−η)θ^+ηθ,其中 η ∈ ( 0 , 1 ) \eta \in (0,1) η∈(0,1)。动量编码器更稳定,对弱监督的噪声不太敏感,从而略微提高了性能。
接下来,我们分别对 F P ( c ) \mathcal{F}_{\mathcal{P}}(c) FP(c)和 F N ( c ) \mathcal{F}_{\mathcal{N}}(c) FN(c)进行 k k k-均值聚类,得到两组聚类中心。我们将这些中心称为原型:
C P ( c ) = { f i + } i = 1 k p , C N ( c ) = { f j − } j = 1 k n . \mathcal{C}_{\mathcal{P}}(c) = \{\mathbf{f}_i^+\}_{i=1}^{k_p}, \quad \mathcal{C}_{\mathcal{N}}(c) = \{\mathbf{f}_j^-\}_{j=1}^{k_n}. CP(c)={fi+}i=1kp,CN(c)={fj−}j=1kn.
通过聚类寻找原型施加了自然的瓶颈,有助于丢弃片段中的无关信息。我们对每个事件类重复此过程。
4.2 估计伪标签
我们通过考虑每个片段与每个类的原型的特征相似性,为训练视频中的每个片段分配伪标签。我们假设,如果一个音频/视频片段包含事件 c c c,它在特征空间中平均上会更接近 P ( c ) \mathcal{P}(c) P(c)而不是 N ( c ) \mathcal{N}(c) N(c)。为此,我们探索了两种方法:(i)硬标签,它为类 c c c的原型集中平均最接近的集分配标签(0,1):
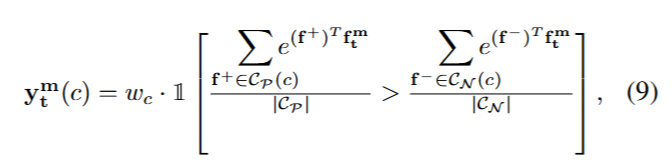

和(ii)软标签,它分配一个概率分数:
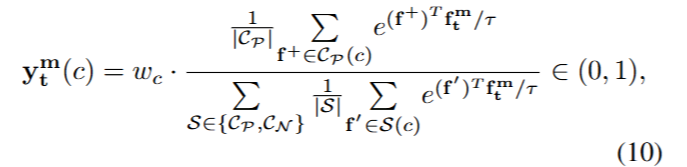

其中 τ > 0 \tau > 0 τ>0是一个温度超参数。
在训练我们的模型时,我们在每个epoch后为每个训练视频生成伪标签 { y t m } \{\mathbf{y}^{\text{m}}_{\text{t}}\} {ytm},并使用它们通过二元交叉熵损失完全监督片段级别概率 { p t m } \{\mathbf{p}^{\text{m}}_{\text{t}}\} {ptm}:
L PL = CE ( p t m , y t m ) , \mathcal{L}_{\text{PL}} = \text{CE}(\mathbf{p}^{\text{m}}_{\text{t}}, \mathbf{y}^{\text{m}}_{\text{t}}), LPL=CE(ptm,ytm),
在片段和训练示例上取平均。
4.3 使用伪标签进行对比学习
鉴于我们的方法利用了片段之间基于其所包含事件的特征相似性,我们使用基于伪标签的对比学习来帮助在语义上构建特征空间。由于多个事件可能同时发生,对于每个视听片段,我们将相似片段定义为那些被估计有某些共同事件的片段,将不相似片段定义为那些被估计没有共同事件的片段。形式上,给定一批训练示例,令 B = { f t m → y t m } B = \{\mathbf{f}^{\text{m}}_{\text{t}} \rightarrow \mathbf{y}^{\text{m}}_{\text{t}}\} B={ftm→ytm}是从特征到所有片段和所有视频中分配的伪标签的字典。对于每个特征 f ∈ B \mathbf{f} \in B f∈B,相似特征集为 S ( f ) = { g ∈ B ∣ B ( g ) ∩ B ( f ) ≠ ϕ } \mathcal{S}(\mathbf{f}) = \{\mathbf{g} \in B | B(\mathbf{g}) \cap B(\mathbf{f}) \neq \phi\} S(f)={g∈B∣B(g)∩B(f)=ϕ},不相似集为 D ( f ) = { g ∈ B ∣ B ( g ) ∩ B ( f ) = ϕ } \mathcal{D}(\mathbf{f}) = \{\mathbf{g} \in B | B(\mathbf{g}) \cap B(\mathbf{f}) = \phi\} D(f)={g∈B∣B(g)∩B(f)=ϕ}。为了将具有共同预测事件的片段拉近特征空间,我们使用对比损失:
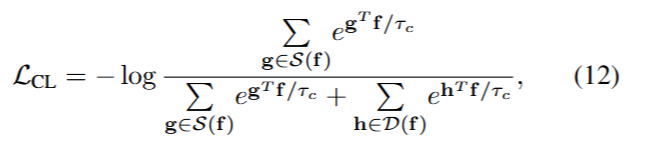

4.4 训练与推理
我们使用以下损失函数以端到端的方式训练模型:
L = L MIL + λ PL L PL + λ CL L CL , \mathcal{L} = \mathcal{L}_{\text{MIL}} + \lambda_{\text{PL}} \mathcal{L}_{\text{PL}} + \lambda_{\text{CL}} \mathcal{L}_{\text{CL}}, L=LMIL+λPLLPL+λCLLCL,
其中 λ PL , λ CL > 0 \lambda_{\text{PL}}, \lambda_{\text{CL}} > 0 λPL,λCL>0是超参数。在训练过程中,我们每个epoch为所有训练样本生成一次伪标签,使用当前最佳模型。在推理时,我们使用非参数的原型伪标签(公式(10))预测片段级别的概率,并结合公式(3)中的视频级别预测。
5. 实验
5.1 实验设置
LLP数据集。我们在《Look, Listen and Parse》(LLP)数据集上进行实验,该数据集包含11849个YouTube视频,每个视频时长为10秒,标注为25个事件类别。这些视频内容广泛,包括日常活动、音乐表演和车辆声音等。我们使用10000个带有弱(视频级别)标签的视频进行训练,剩余的1849个完全标注的视频用于验证和测试。LLP数据集提供了训练/验证/测试的划分。
评估指标。根据之前的工作,我们使用音频、视觉和音视频事件的F1分数作为评估指标。这些指标在片段级别和事件级别上计算。我们还包含了“Type@AV”和“Event@AV”的聚合指标,同样在片段和事件级别上计算。详见Tian等人的论文对这些指标的详细解释。
实现细节。我们使用在ImageNet上预训练的ResNet-152和Kinetics-400上预训练的R(2+1)D-18作为视觉特征提取器,生成每个片段的512维视觉特征。我们使用在AudioSet上预训练的VGGish生成每个片段的128维音频特征。我们使用Adam优化器,批量大小为16,学习率 α = 3 e − 4 \alpha = 3e-4 α=3e−4,训练50个epoch。动量编码器的 η = 0.999 \eta = 0.999 η=0.999,公式(13)中的 λ PL = λ CL = 0.1 \lambda_{\text{PL}} = \lambda_{\text{CL}} = 0.1 λPL=λCL=0.1,公式(5)中的 γ = 1 \gamma = 1 γ=1,公式(6)中的 β = 0.2 \beta = 0.2 β=0.2,公式(10)中的 τ = 0.1 \tau = 0.1 τ=0.1,公式(12)中的 τ c = 0.2 \tau_c = 0.2 τc=0.2。公式(8)中的 k p = k n = 10 k_p = k_n = 10 kp=kn=10。超参数值基于验证性能。
5.2 与现有方法的比较
为了公平比较,所有方法都使用相同的预训练特征提取器和训练/验证/测试划分。
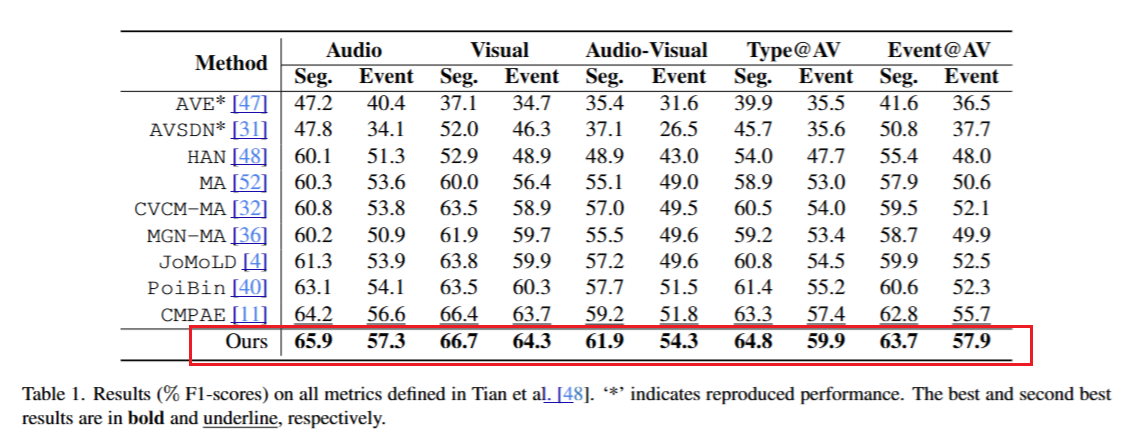
定量比较。我们在表1中比较了所有指标上的方法。我们看到,我们的方法在音频、音视频、Type@AV和Event@AV指标上均优于其他方法,特别是在音视频事件上平均提升了2.6个百分点。在所有指标上,我们的方法比之前最好的方法CMPAE平均提升了1.86个百分点。由于我们不需要额外的可学习参数来生成伪标签,这一改进是在与之前方法相当的参数数量下实现的。
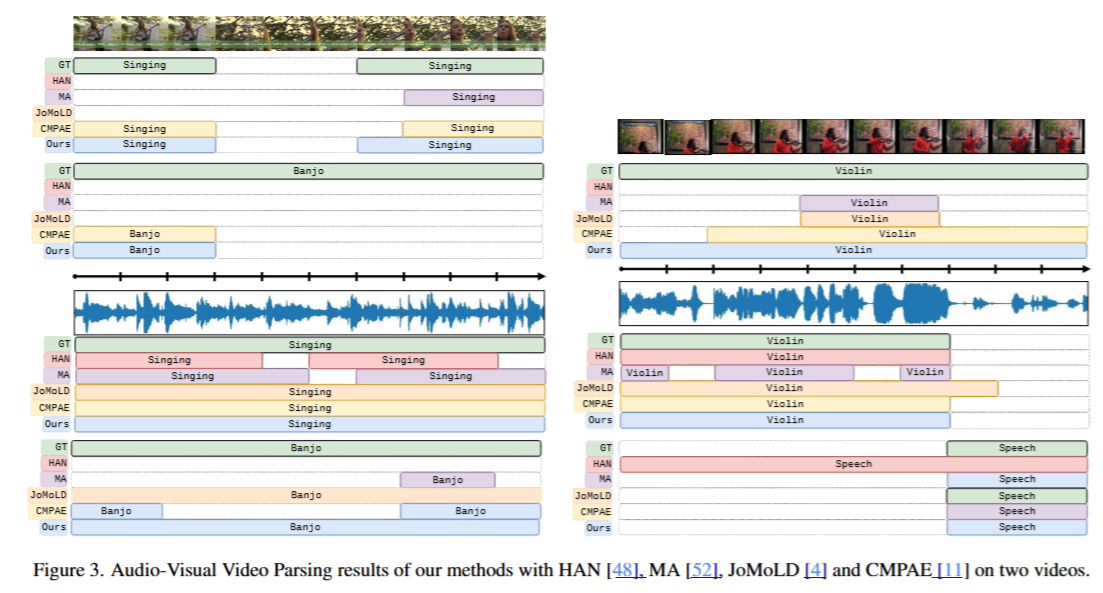
定性比较。我们在图3中定性比较了我们的方法与一些现有方法在两个示例上的表现。图3(左)包含“Singing”和“Banjo”两个事件,且这两个事件在两种模态中都存在。图3(右)展示了另一个场景,其中“Speech”事件仅出现在音频模态中,而“Violin”事件同时出现在两种模态中。显然,现有方法的常见失败模式是它们只能检测到事件的部分持续时间,而我们的方法更常见地检测到事件的完整持续时间。正如第1节所讨论的,这可能是由于多实例学习鼓励模型只挑选出包含事件的最具区分性的片段,而不是所有片段。
计算成本。在训练时,我们的方法每个epoch耗时67.4秒(前向+反向传播耗时17.1秒,基于原型的伪标签生成耗时50.3秒)。推理时,每个视频平均耗时5.9毫秒,与基线方法(2.9毫秒)相当。
5.3 分析
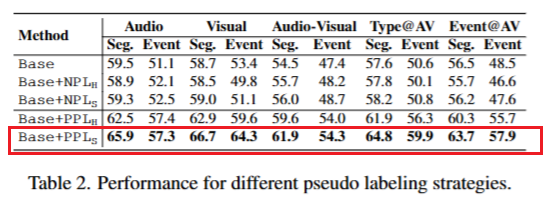
伪标签策略。我们在表2中报告了一项消融研究,以验证我们的特定伪标签方法。这里,Base是第3.2节中解释的基线MIL模型。Base+NPL指的是使用朴素伪标签训练的基线模型,即直接使用模型的片段级别预测作为伪标签进行重新训练。在这种情况下,H和S分别表示使用硬(二值化)和软(连续)伪标签。我们观察到,朴素伪标签并没有带来一致的改进,这可能是由于MIL模型对事件的非区分性片段产生了错误的预测,导致伪标签不可靠。Base+PPL指的是使用基于原型的伪标签训练的基线模型,如第4.2节所述。在这种情况下,H和S分别表示使用硬和软伪标签,如公式(9)和(10)所定义。我们的方法通过在整个训练视频中生成更可靠的伪标签,显著提高了性能。我们还看到,软标签比硬标签效果更好。由于片段级别的预测可能带有噪声,我们预计硬标签的错误对性能的影响会比软标签更大。
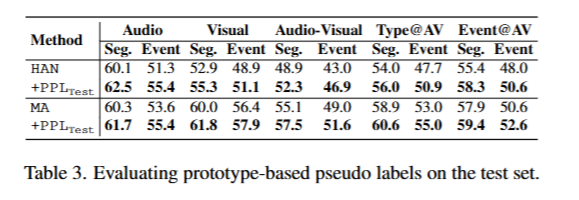
伪标签的可靠性。我们现在评估我们的方法生成的伪标签是否可靠用于重新训练。为此,我们使用预训练的基线模型HAN和MA,从训练数据中为每个事件生成原型,并简单地在测试集上预测基于原型的伪标签(公式(9))进行评估(即在测试时丢弃分类器)。我们将生成的分类器称为HAN+PPL Test _{\text{Test}} Test和MA+PPL Test _{\text{Test}} Test,并在表3中展示了结果。除了分类器外,我们没有对模型进行任何其他更改,我们看到所有指标都有显著提升,这表明我们的伪标签确实是真实标签的可靠估计。注意,表1中的结果是在每个epoch后重新计算训练数据上的伪标签,并使用不断改进的基线模型。
γ \gamma γ和 β \beta β的影响。公式(5)和(6)中的超参数 γ \gamma γ和 β \beta β大致控制将选择为正例和负例的片段比例,以分配伪标签。我们尝试了不同的值,并在图4中绘制了所有片段/事件级别指标的平均值。性能对控制正例的 γ \gamma γ敏感,而对 β \beta β的轻微变化具有容忍度。最佳性能出现在 γ = 1 \gamma = 1 γ=1和 β = 0.2 \beta = 0.2 β=0.2时。
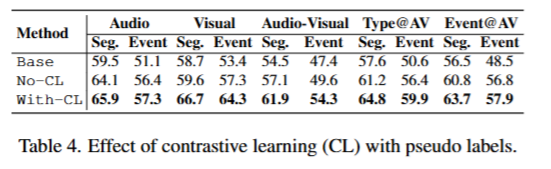
对比学习的影响。我们通过将公式(13)中的 λ CL \lambda_{\text{CL}} λCL设置为0,分析了使用伪标签进行对比学习(公式(12))的影响。结果如表4所示。虽然仅使用基于原型的伪标签进行训练(No-CL)显著改善了基线,但添加基于伪标签的对比损失(With-CL)进一步带来了大幅提升。
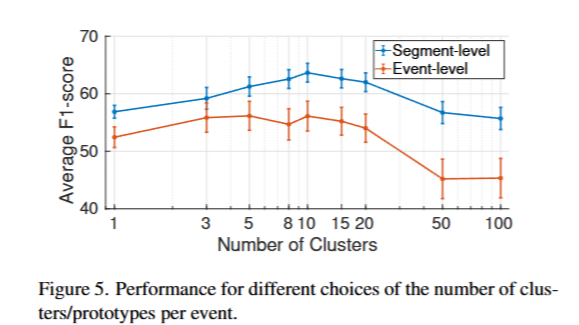
聚类数量。我们取 k p = k n k_p = k_n kp=kn,并尝试 { 1 , 2 , . . . , 100 } \{1,2,...,100\} {1,2,...,100}中的值。我们在图5中绘制了所有片段/事件级别指标的平均值。最佳性能出现在每个类 k = 10 k = 10 k=10个聚类时。较少的聚类有助于捕捉事件的更一般特征,而不是实例特定的细节,但过少的聚类会因丢弃类内变化而损害性能。
5.4 不同任务的结果
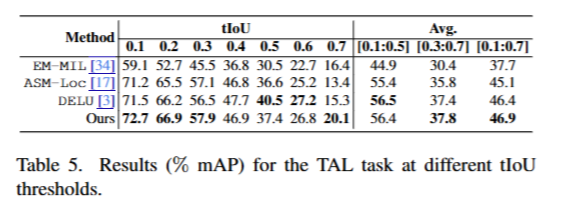
我们在THUMOS14数据集上进行了弱监督时间动作定位(TAL)任务的初步实验,以进一步验证我们的方法。TAL的目标是在视频中时间定位和分类视觉事件到已知类别。我们报告了不同时间交并比(tIoU)阈值下的平均精度(mAP),结果如表5所示。我们相对于当前最先进的方法DELU取得了更好或相当的性能,并且优于之前的方法。完整的比较请参见补充材料。
6. 作为期望最大化的解释
我们现在展示,迭代重新估计软伪标签并在弱监督和强监督下训练模型(公式(13))可以解释为期望最大化(EM)算法,为我们的训练过程提供了进一步的见解。为此,我们将每个视频的片段级别标签 y = { ( y t a , y t v ) } t = 1 T y = \{(\mathbf{y}^a_t, \mathbf{y}^v_t)\}_{t=1}^T y={(yta,ytv)}t=1T视为潜在变量,因为它们在弱监督训练时未被观察到。观察到的变量是视频片段 x = { ( x t a , x t v ) } t = 1 T x = \{(x^a_t, x^v_t)\}_{t=1}^T x={(xta,xtv)}t=1T和弱标签 w \mathbf{w} w。为清晰起见,假设单个事件类,即 w , y t m ∈ { 0 , 1 } \mathbf{w}, \mathbf{y}^m_t \in \{0,1\} w,ytm∈{0,1}。
我们的目标是最大化数据对数似然 L ( θ ) = ln p θ ( w ∣ x ) \mathcal{L}(\theta) = \ln p_\theta(\mathbf{w}|x) L(θ)=lnpθ(w∣x),其中 θ \theta θ是模型参数(为清晰起见,假设只有一个数据点 x x x)。我们不直接最大化这个似然,而是尝试最大化其变分下界 L VLB \mathcal{L}_{\text{VLB}} LVLB:
L VLB ( θ , ϕ ) = E Y ∼ q ϕ ( ⋅ ∣ w , x ) [ ln p θ ( w ∣ Y , x ) ] − D KL [ q ϕ ( ⋅ ∣ w , x ) ∣ ∣ p θ ( ⋅ ∣ x ) ] , \mathcal{L}_{\text{VLB}}(\theta, \phi) = \mathop{\mathbb{E}}_{Y \sim q_\phi(\cdot|\mathbf{w}, x)}[\ln p_\theta(\mathbf{w}|Y, x)] - \mathbf{D}_{\text{KL}}[q_\phi(\cdot|\mathbf{w}, x)||p_\theta(\cdot|x)], LVLB(θ,ϕ)=EY∼qϕ(⋅∣w,x)[lnpθ(w∣Y,x)]−DKL[qϕ(⋅∣w,x)∣∣pθ(⋅∣x)],
其中 q ϕ ( y ∣ w , x ) q_\phi(y|\mathbf{w}, x) qϕ(y∣w,x)是标签 y y y上的任意条件分布,参数为 ϕ \phi ϕ,旨在近似真实后验 p θ ( y ∣ x ) p_\theta(y|x) pθ(y∣x)。EM算法交替执行两个步骤,首先通过最大化 L VLB \mathcal{L}_{\text{VLB}} LVLB来近似后验(E步),然后通过最大化数据似然来改进模型参数(M步)。设 j ≥ 1 j \geq 1 j≥1表示迭代次数(注意,这里的 θ \theta θ和 ϕ \phi ϕ与第3.2节中的不同)。

E步。第 j j j次更新由下式给出:
q ϕ j ( y ∣ w , x ) = p θ j − 1 ( y ∣ w , x ) , ∀ y . q_{\phi_j}(y|\mathbf{w}, x) = p_{\theta_{j-1}}(y|\mathbf{w}, x), \quad \forall y. qϕj(y∣w,x)=pθj−1(y∣w,x),∀y.
假设给定视频及其弱标签,片段级别标签条件独立,我们可以将右侧表示为 p θ ( y ∣ w , x ) = ∏ t , m p θ ( y t m ∣ w , x ) p_\theta(y|\mathbf{w}, x) = \prod_{t,m} p_\theta(\mathbf{y}^m_t|\mathbf{w}, x) pθ(y∣w,x)=∏t,mpθ(ytm∣w,x),使用以下公式计算:
p θ ( y t m ∣ w , x ) : = { p θ ( y t m ∣ x ) 如果 w = 1 1 − y t m 如果 w = 0 , p_\theta(\mathbf{y}^m_t|\mathbf{w}, x) := \begin{cases} p_\theta(\mathbf{y}^m_t|x) & \text{如果 } \mathbf{w} = 1 \\ 1 - \mathbf{y}^m_t & \text{如果 } \mathbf{w} = 0, \end{cases} pθ(ytm∣w,x):={pθ(ytm∣x)1−ytm如果 w=1如果 w=0,
其中 p θ ( y t m ∣ x ) p_\theta(\mathbf{y}^m_t|x) pθ(ytm∣x)表示模型对视频 x x x中模态 m m m和片段 t t t的预测。因此, p θ ( y t m ∣ w , x ) p_\theta(\mathbf{y}^m_t|\mathbf{w}, x) pθ(ytm∣w,x)成为片段 x t m x^m_t xtm的软伪标签。
M步。第 j j j次更新通过最大化 L VLB ( θ , ϕ j ) \mathcal{L}_{\text{VLB}}(\theta, \phi_j) LVLB(θ,ϕj)找到 θ j \theta_j θj,由于公式(15),这等价于:
min θ − ∑ y p θ j − 1 ( y ∣ w , x ) ln p θ ( y ∣ x ) − ∑ y p θ j − 1 ( y ∣ w , x ) ln p θ ( w ∣ y , x ) , \min_\theta - \sum_y p_{\theta_{j-1}}(y|\mathbf{w}, x) \ln p_\theta(y|x) - \sum_y p_{\theta_{j-1}}(y|\mathbf{w}, x) \ln p_\theta(\mathbf{w}|y, x), minθ−∑ypθj−1(y∣w,x)lnpθ(y∣x)−∑ypθj−1(y∣w,x)lnpθ(w∣y,x),
其中 p θ ( y ∣ w , x ) p_\theta(y|\mathbf{w}, x) pθ(y∣w,x)和 p θ ( y ∣ x ) p_\theta(y|x) pθ(y∣x)如公式(16)计算。
公式(17)中的第一项可以展开为片段级别预测 p θ ( y t m ∣ x ) p_\theta(\mathbf{y}^m_t|x) pθ(ytm∣x)与伪标签目标 p θ j − 1 ( y t m ∣ w , x ) p_{\theta_{j-1}}(\mathbf{y}^m_t|\mathbf{w}, x) pθj−1(ytm∣w,x)之间的总交叉熵,因此等于 L PL \mathcal{L}_{\text{PL}} LPL(见公式(13))。为了理解公式(17)中的第二项,注意在我们的设置中, p θ ( w ∣ y , x ) = p θ ( w ∣ x ) p_\theta(\mathbf{w}|y, x) = p_\theta(\mathbf{w}|x) pθ(w∣y,x)=pθ(w∣x),因为我们使用MIL池化进行视频级别预测,而不访问片段级别标签( y y y)。第二项简化为 − ln p θ ( w ∣ x ) -\ln p_\theta(\mathbf{w}|x) −lnpθ(w∣x),即视频级别标签( w \mathbf{w} w)的负对数似然。这意味着第二项等于 L MIL \mathcal{L}_{\text{MIL}} LMIL(见公式(13))。即,M步等价于:
min θ − ∑ y p θ j − 1 ( y ∣ w , x ) ln p θ ( y ∣ x ) − ln p θ ( w ∣ x ) . \min_\theta - \sum_y p_{\theta_{j-1}}(y|\mathbf{w}, x) \ln p_\theta(y|x) - \ln p_\theta(\mathbf{w}|x). minθ−∑ypθj−1(y∣w,x)lnpθ(y∣x)−lnpθ(w∣x).
如果我们直接最大化数据对数似然 L ( θ ) \mathcal{L}(\theta) L(θ)(没有伪标签),这可能会收敛到一个仅挑选出每个视频中最具区分性片段的解,这可能足以减少视频级别损失 L MIL \mathcal{L}_{\text{MIL}} LMIL。正如我们在本文中所展示的,使用伪标签可以帮助缓解这一问题,但估计的伪标签的质量起着关键作用。例如,硬标签不如软标签,因为它不试图精确计算E步(公式(15))。虽然软标签确实试图精确计算E步,但更好的归纳偏差(如基于原型的标签和对比学习)可以帮助达到有利的解,正如第5.3节和表2中所报告的。我们还在补充材料中与现成的伪标签方法进行了比较,发现我们显著优于它,这表明并不是伪标签本身对AVVP有效——我们如何估计伪标签至关重要。
7. 结论
我们提出了一种基于原型的伪标签方法,用于弱监督AVVP,其性能优于现有方法。一些有趣的发现是:(i)朴素伪标签不能产生可靠的训练目标,(ii)使用伪标签进行对比学习是一种有效的策略,(iii)使用弱监督和重新估计的软伪标签进行训练是一种EM算法。
我们以一些局限性和未来工作的建议结束。首先,性能对超参数 β \beta β敏感,如图4所示。这可能是因为从MIL模型的预测中识别一个类的负例比识别正例更不准确。此外,事件的负例片段在内容上会有更大的变化。其次,具有较大类内变化的事件可能需要更多的原型来表示,而我们为了方便假设所有事件的最优原型数量相同。第三,虽然我们可以将我们的方法解释为EM算法,但EM可能只收敛到局部最优解。正如第6节所讨论的,未来的工作可以探索在伪标签步骤中引入归纳偏差,以偏向更好的解。最后,尚不清楚我们的方法可以推广到多少相关的视频/图像预测任务。虽然我们在第5.4节中提供了TAL的结果,但未来工作中更多关于将我们的方法适应相关任务的证据将是有用的。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)