
【大模型】【推荐系统】基于分层树搜索的大语言模型用户终身行为建模
推荐系统(Recommendation Systems, RS)已在电子商务、影视推荐及音乐发现等领域实现广泛部署,显著优化了用户体验。用户行为建模作为核心环节,其关键在于解码行为序列中蕴含的细粒度偏好信号。传统模型(如DIN、DIEN)主要依赖用户行为的离散标识符特征语义理解缺失:无法有效捕捉用户与项目的语义关联,在数据密集型场景中形成认知鸿沟;行为完整性忽视:仅利用局部历史行为片段,导致偏好建
文章目录
A 论文出处
- 论文题目:Hierarchical Tree Search-based User Lifelong Behavior Modeling on Large Language Model
- 发表情况:2025-SIGIR
B 背景
B.1 背景介绍
推荐系统(Recommendation Systems, RS)已在电子商务、影视推荐及音乐发现等领域实现广泛部署,显著优化了用户体验。用户行为建模作为核心环节,其关键在于解码行为序列中蕴含的细粒度偏好信号。传统模型(如DIN、DIEN)主要依赖用户行为的离散标识符特征(ID features),存在双重局限:
- 语义理解缺失:无法有效捕捉用户与项目的语义关联,在数据密集型场景中形成认知鸿沟;
- 行为完整性忽视:仅利用局部历史行为片段,导致偏好建模碎片化。
因此未能根本解决全局行为序列建模问题,制约对用户动态兴趣演化的精准刻画。
B.2 问题提出
大语言模型(LLMs)凭借其广泛的世界知识与深度推理能力,为推荐系统的用户行为建模提供了新范式。然而其应用面临双重挑战:
- 长序列建模缺陷:受限于上下文窗口长度,LLMs难以有效处理长用户行为序列的文本语义;即使序列长度未达上限,其固有的位置偏差也会导致对序列首尾的过度关注,引发关键信息的提取缺失;
- 动态兴趣建模不足:LLMs将历史行为视为静态输入,缺乏对兴趣漂移的时间感知能力,无法捕捉用户偏好的演化规律。而精准建模兴趣动态恰是推荐系统的核心,当前LLM的静态表征机制亟待突破。
B.3 创新点
论文提出了基于层次树搜索的用户终身行为建模框架(HiT-LBM),该框架整合了分块用户行为提取(CUBE)和层次树搜索兴趣(HTS)两个模块,以捕捉用户的多样化兴趣及其演变过程。
B.4 传统推荐与基于LLM的推荐
-
传统推荐模型
a. 特征交互建模致力于通过隐空间向量内积、显式特征交叉及注意力加权等机制解析特征间非线性关联,例如因子分解机(FM)、深度交叉网络(DCN)及DeepFM等混合架构。此类模型虽能有效捕捉用户-物品特征间的协同效应,但其依赖离散标识符(ID)的建模范式导致语义理解能力薄弱。
b. 用户行为序列建模聚焦于从时序行为(如点击流)中提取动态兴趣模式,主流方法采用门控循环单元(GRU)与注意力机制(如DIEN的序列建模层、DIN的局部激活模块)编码历史行为ID序列。尽管此类方法可捕获短期兴趣演化,其离散标识符割裂行为语义的连续性,并且传统的循环神经网络难以建模超长序列(>1000项)中的长期依赖,导致对兴趣漂移现象的表征较弱。
-
基于LLM的推荐
a. 大语言模型驱动的新型推荐框架呈现双路径演化:其一是LLM即推荐器(LLM-as-Rec)范式,通过零样本推理、少样本上下文学习或参数微调使LLM直接生成推荐结果;其二是LLM增强推荐(LLM-enhanced-Rec)范式,利用LLM的语义生成能力抽取文本特征、解释行为序列或注入领域知识以优化传统推荐模型。两类范式虽突破语义理解瓶颈,仍受限于长上下文处理能力及动态兴趣建模机制缺失。
C 模型结构
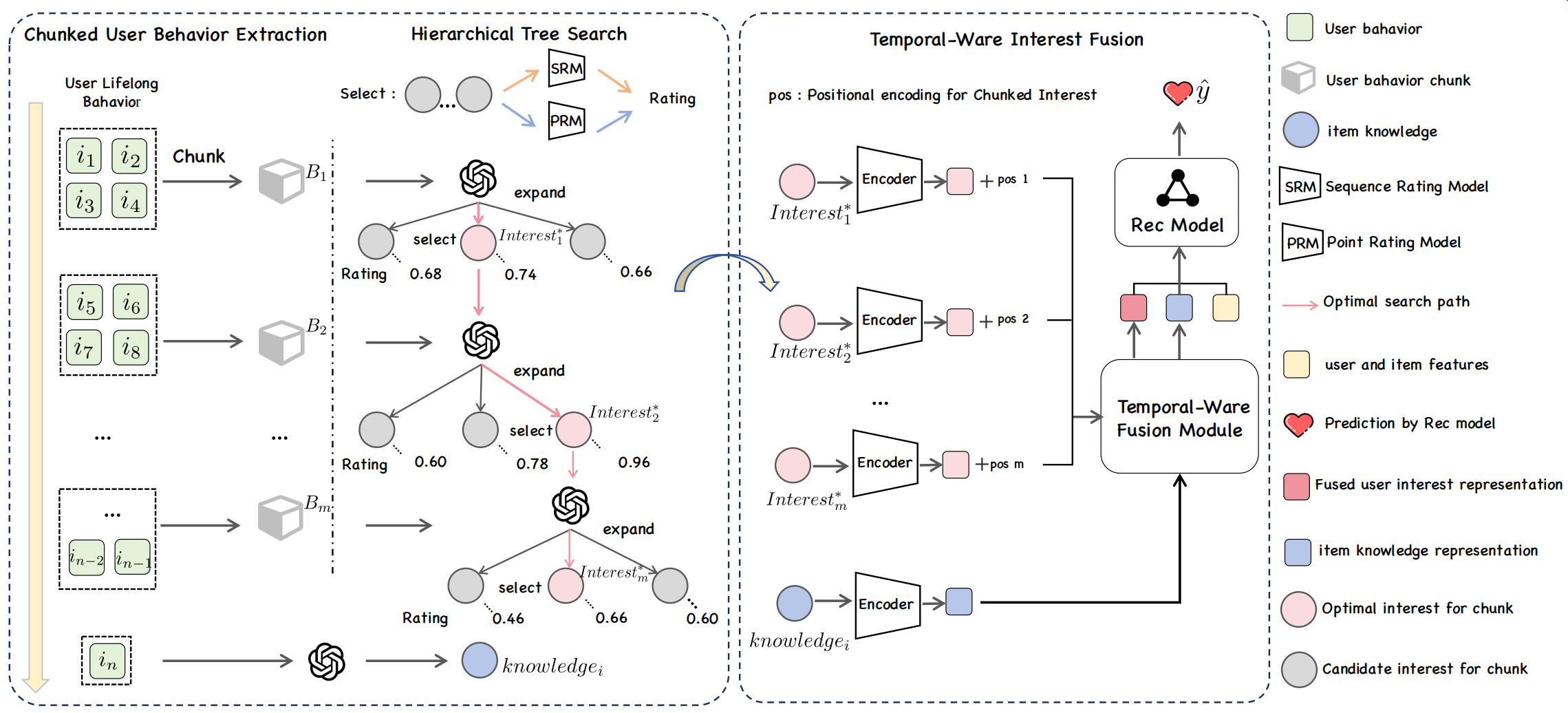
C.1 分块用户行为提取(CUBE)
为建模用户兴趣的动态演变过程,本文提出一种级联式学习框架。该框架首先依据大语言模型(LLM)的上下文窗口约束,将用户终身历史行为划分为长度适配的连续行为片段。继而通过结构化的指令模板,系统性地激发LLM的知识推理能力,实现对用户兴趣特征及其时序演化规律的深度解析。
在特征生成阶段,采用跨片段级联机制。当前片段的兴趣建模不仅基于片段内的交互行为,同时融合前序片段提取的显性兴趣表征。这种设计通过显式构建片段间的语义关联,有效捕捉兴趣漂移与继承特性,解决了长周期行为建模中的信息碎片化问题。
C.2 层次树搜索兴趣(HTS)
设计了两维度的过程评分模型——序列评分模型(SRM)和点评分模型(PRM),分别量化评估兴趣表征的时序连续性及语义有效性。基于这些评分,采用层次树搜索算法动态确定各行为片段的最优兴趣表征,具体实现如下:
-
过程评分模型:
a. 模型架构:序列评分模型(SRM)和点评分模型(PRM),用于评估LLM生成的兴趣的连续性和有效性。
b. 评估机制:构建监督训练集驱动LLM预测后续行为片段中的目标项目,采用AUC指标量化兴趣表征的预测效能。
c. 动态阈值:如果当前兴趣的AUC值高于前𝐾个兴趣,则判定其具备兴趣延续性与信息增益,反之标注为负样本。
-
层次树搜索:
a. 数据结构:将用户行为抽象为动态兴趣树,每个节点代表对应行为片段的兴趣。
b. 候选生成:从根节点开始,通过LLM的Best-of-N模式生成多个候选兴趣节点,并使用SRM和PRM对这些节点进行评分。
c. 最优路径:通过加权方式计算每个候选节点的最终评分,并选择评分最高的节点作为下一轮扩展的父节点,直到覆盖全部的行为片段。
d. 表征提取:通过路径回溯提取叶节点至根节点的最优兴趣链,作为最终的用户兴趣表示。
C.3 时间感知兴趣融合(TIF)
将LLM生成的文本知识转换为紧凑的向量表征,通过时序感知融合增强推荐系统性能。最终生成的终身兴趣表示具备模型无关性,可无缝嵌入任意推荐架构。核心流程如下:
-
兴趣编码器:将LLM生成的兴趣文本编码为密集向量表示。
-
时间感知融合:利用层次树搜索过程中得到的最终评分对兴趣向量进行加权,并引入位置编码以保留用户行为的顺序性,同时通过掩码自注意力层整合不同片段的兴趣表示,确保每个位置的表示只能感知到其之前的兴趣表示。
-
兴趣集成:将通过融合得到的用户兴趣表征和知识嵌入到传统的推荐模型中。
D 实验设计
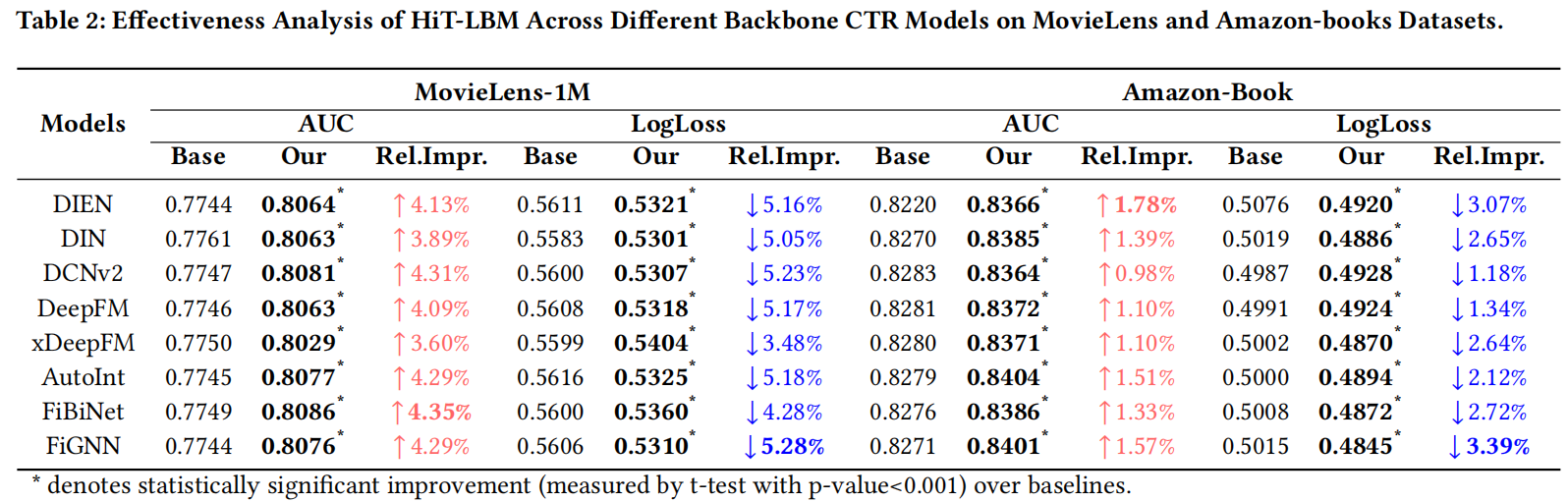
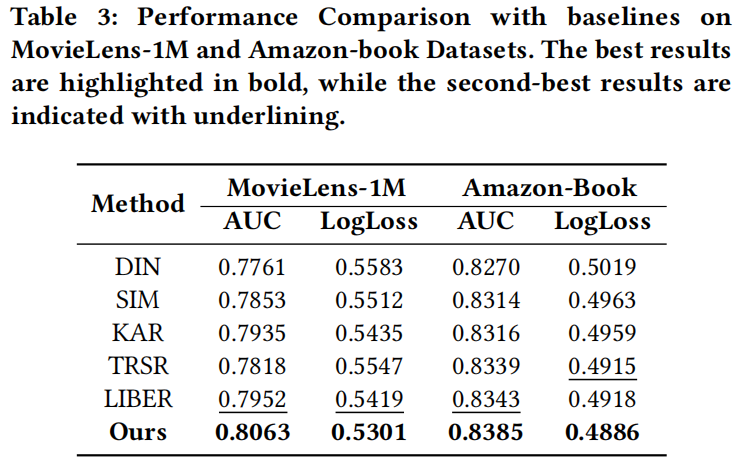
HiT-LBM与其他用户行为建模基线模型的比较结果表明:
- LLM在用户行为建模方面优于传统的基于ID的推荐模型。
- HiT-LBM能够充分利用LLM的强大文本理解能力,提升推荐性能。
- HiT-LBM显著优于其他基于LLM的基线方法,在AUC和LogLoss指标上均表现出色。
E 个人总结
- 创新提出层次树搜索机制,解决长周期行为建模中的兴趣漂移问题,同时通过双评分模型设计(SRM/PRM)量化评估兴趣连续性与有效性,增强可解释性,最后,时序感知融合框架实现LLM知识与推荐系统的无损嫁接,提升长期偏好捕捉能力。
- 依赖LLM生成候选兴趣可能存在幻觉风险,同时树的搜索依赖也会导致出现局部最优解。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)