
LoRA 图像生成全流程实战:从数据准备到模型上线,一文通透!
LoRA(Low-Rank Adaptation)是一种高效的模型微调技术,通过分解权重矩阵减少训练参数,降低计算需求。核心流程包括:1)准备15-50张高质量素材图片并统一裁切分辨率;2)使用DeepBooru或wd14-tagger插件进行图像打标签,优化时保留通用特征、删除需绑定的细节标签;3)本地或云端训练后,通过XYZ Plot脚本测试不同权重效果。典型应用包括角色建模、风格迁移、品牌定
📌 本文为《LoRA 应用实录》系列第 2 篇,在第一篇里讲解了LoRA在 NLP 与 CV 场景的高效微调方法全解析,你可以查看:
- 总览篇:《LoRA 实战指南:NLP 与 CV 场景的高效微调方法全解析》👉 点此阅读
- NLP篇:《国产生态实战:基于 LLaMA-Factory + DeepSeek + LoRA + FastAPI 快速微调并部署专属大模型》👉 点此阅读
文章目录
一、LoRA介绍
LoRA(Low-Rank Adaptation)一种模型微调技术,将权重矩阵分解为低秩序形式(指把一个大而稠密的权重更新矩阵,近似成两个小矩阵相乘,只更新少量参数),减少需要训练的参考数量,降低显存和计算需求,适用于角色建模、风格迁移等场景。
二、LoRA 的核心训练流程
1. 训练数据集准备
素材图片要求
-
数量:不少于15张高质量图片,建议 20~50 张;
-
内容清晰、特征突出、构图简洁;
-
人物照建议以多角度脸部特写为主,辅以全身图(多姿势、多服装);
-
避免重复或相似图;
-
可使用 SD 的 Extras 功能 提升图像清晰度;
-
统一裁切分辨率为 64 的倍数,推荐:
- 显存较低:
512x512 - 显存较高:
768x768 - 工具推荐:Birme 批量裁切工具
- 显存较低:
2. 图像打标签(Tagging)
用于训练的图像需进行打标签,标注图像中包含的内容。常见方法如下:
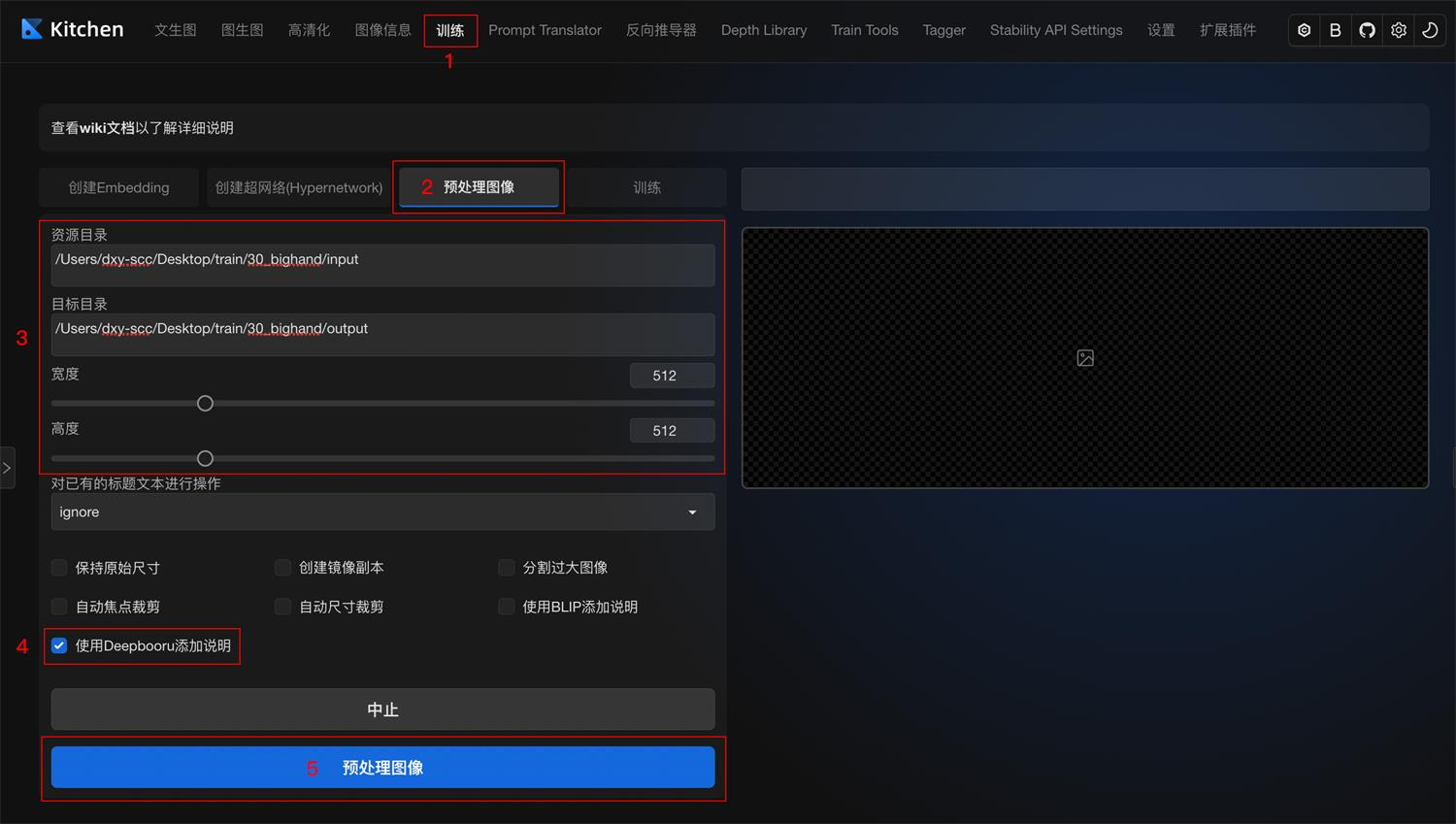
方法一:WebUI 图像预处理功能(使用 DeepBooru)
- 进入 SD WebUI 的训练模块
- 填写素材文件夹路径
- 勾选生成标签(DeepBooru)
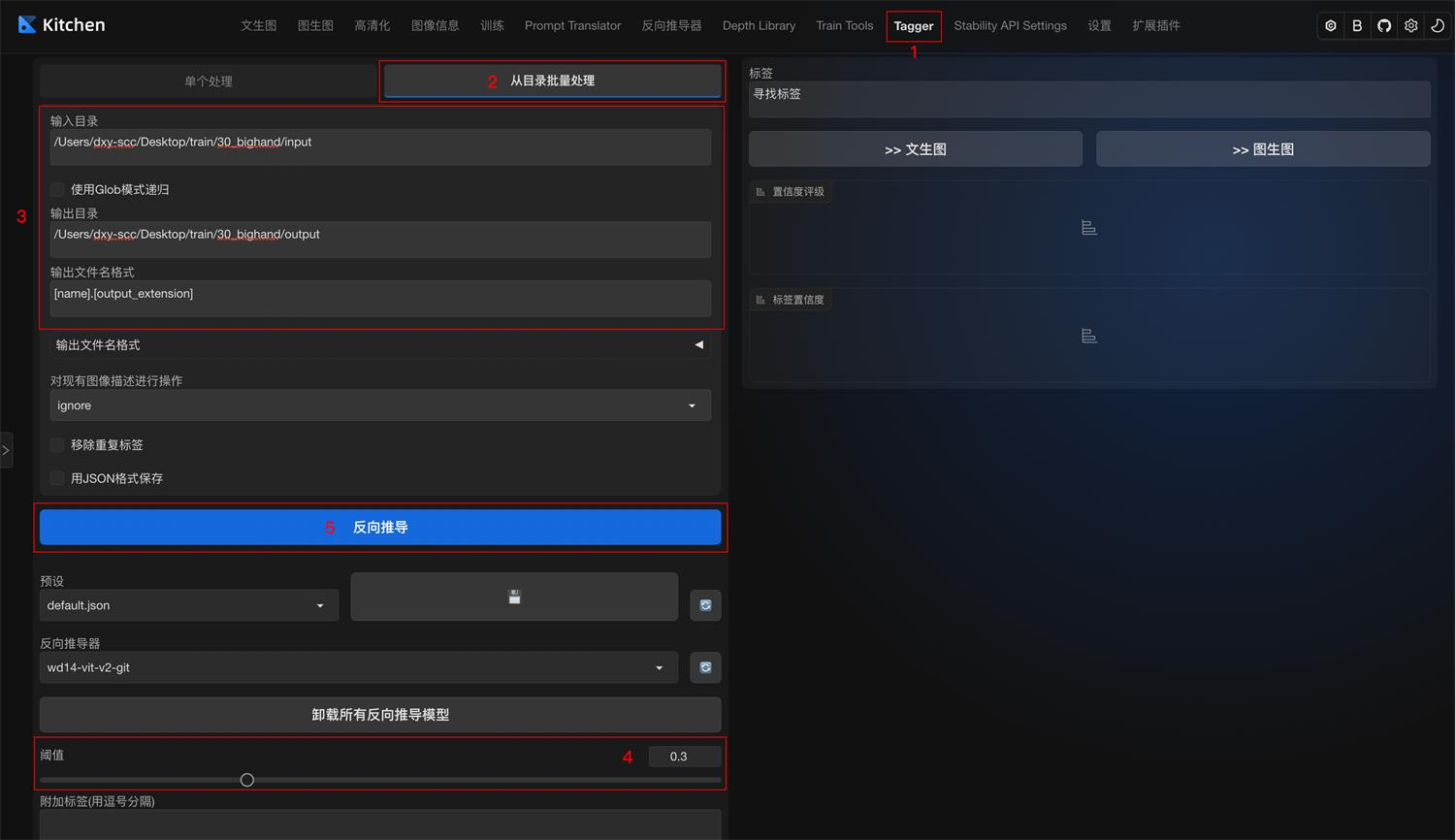
方法二:使用 wd14-tagger 插件
-
设置步骤:
- 输入图像目录与标签输出目录;
- 设置阈值:
0.3(生成尽可能多的标签); - 批量开始处理。
3. 标签优化策略
生成标签文件后,可进行如下优化处理:
方法一:保留全部标签
- 不进行任何修改,用于快速构建风格类模型或初期阶段测试模型表现;
- 优势:
不需人工干预,节省时间;
保持标签完整性,训练更稳定;
模型不容易陷入过拟合。 - 劣势:
标签数量多,推理时 prompt 需要输入更多;
标签泛化性强,精准还原性可能不足;
训练轮数需设置更高,耗时更久
方法二:手动筛选 + 删除冗余标签
-
删除主题特征,以便模型学习这些特征(绑定 LoRA);
-
删除示例(需绑定 LoRA 的特征):
- 特殊人物特征:
fox ears,fox tail,purple hair,anthro - 特定服饰:
purple dress等
- 特殊人物特征:
-
保留示例(可替换提示词):
- 通用人物特征:
long hair,teeth - 动作姿势:
crossed arms,jumping,dancing - 表情特征:
smile,open mouth - 镜头角度:
looking at viewer,full body,close up - 背景风格:
simple background,white background
- 通用人物特征:
推荐工具:
- BooruDatasetTagManager:批量标签管理与清洗工具
三、LoRA 模型训练与测试
1. 训练环境配置
本地训练
-
推荐显卡:RTX 30 系列及以上
-
工具推荐:
-
秋叶大佬一键包(适合初学者)
-
或使用 SD WebUI 训练插件
- 插件地址:sd-webui-train-tools
-
云端训练平台推荐
| 平台 | 定位 | 适合人群 |
|---|---|---|
| 揽睿星舟 | 云端GPU一键训练绘图平台 | LoRA 训练新手、AI绘画爱好者 |
| AutoDL算力云 | 自由灵活的训练环境 | AI 开发者、科研人员、熟悉部署流程的用户 |
2. 测试训练好的 LoRA
在 WebUI 中测试 LoRA 效果:
-
在提示词中调用 LoRA:
1girl, pink hair, <lora:foxgirl_lora:0.7> -
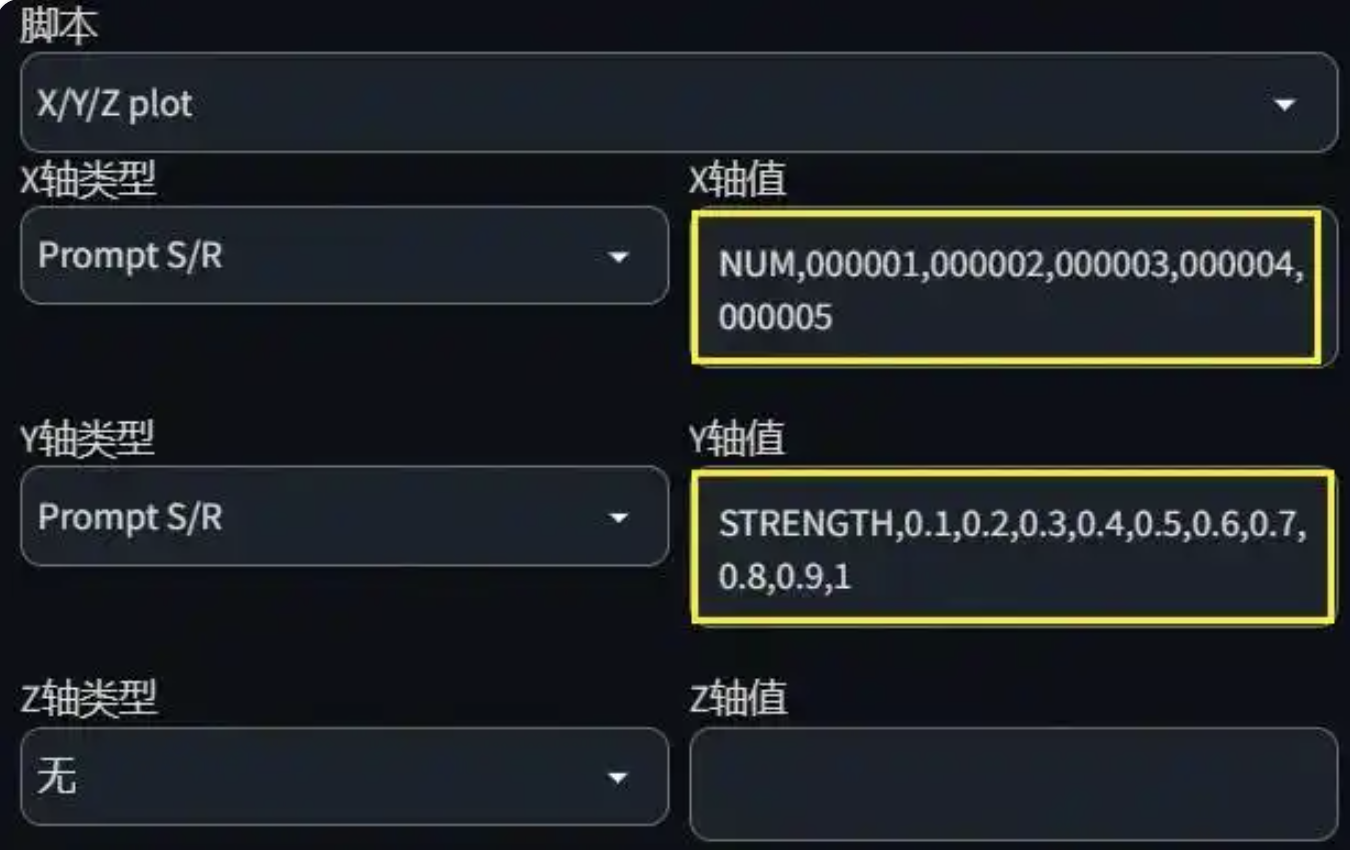
使用 XYZ Plot 脚本进行效果对比:
配置方法
-
脚本位置:WebUI 底部 → 脚本选择 “XYZ plot”
-
设置:
- X轴类型:Prompt S/R
- Y轴类型:Prompt S/R
-
X轴值(模型版本):
NUM,000001,000002,000003,000004,000005 -
Y轴值(权重强度):
STRENGTH,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1 -
提示词中加入:
<lora:NUM:STRENGTH>
WebUI 将生成模型效果的 XY 对比图,便于分析最优模型版本与权重。

四、LoRA 模型调用方式
-
将 LoRA 文件(
.safetensors或.pt)放入目录:/models/Lora/ -
在 Prompt 中使用:
<lora:模型名:权重值> -
示例调用:
1girl, pink hair, <lora:foxgirl_lora:0.7> -
触发词:
- 某些旧版本 LoRA 需提供 Trigger Word;
- 现在多数泛化训练良好的 LoRA 不再依赖。
五、LoRA 五大典型应用场景
| 应用方向 | 说明 |
|---|---|
| 角色复现 / OC建模 | 训练你自己的虚拟人物(OC)形象,让AI识别外貌、穿着、风格 |
| 绘画风格迁移 | 例如模仿某位画家的风格,如手冢治虫、京阿尼等 |
| 特定服饰/物品 | 如“日式巫女服”、“透明雨伞”、“墨镜”等特定道具 |
| 品牌定制内容 | 企业、IP形象专属风格生成与传播 |
| 动态图像生成/虚拟直播 | 结合LoRA与实时动作捕捉,可制作AI虚拟主播等 |
推荐资料与工具链接
- Stable Diffusion WebUI:AUTOMATIC1111
- LoRA 训练插件:sd-webui-train-tools
- 标签器插件:wd14-tagger
- LoRA 标签清洗工具:BooruDatasetTagManager
- 图像批量裁切:Birme 网页工具
- 云训练平台:AutoDL、揽睿星舟

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)