
fofa自动化爬虫脚本更新+详解
fofa自动化爬虫脚本更新+详解起因最近要用到fofa爬虫,为什么要用爬虫不用api,问就是穷,想起来之前写过一个相关的脚本:Fofa-python-脚本,是很久以前写的了,之前写的时候有点问题,昨天重新修改了一下,记录一下整个过程关于fofa在其他大佬博客上摘抄的FOFA简介及使用教程FOFA 是白帽汇推出的一款网络空间搜索引擎,它通过进行网络空间测绘,能够帮助研究人员或者企业迅速进行网络资产匹
起因
最近要用到fofa爬虫,为什么要用爬虫不用api,问就是穷,想起来之前写过一个相关的脚本:Fofa-python-脚本,是很久以前写的了,之前写的时候有点问题,昨天重新修改了一下,记录一下整个过程
关于fofa
在其他大佬博客上摘抄的FOFA简介及使用教程
FOFA 是白帽汇推出的一款网络空间搜索引擎,它通过进行网络空间测绘,能够帮助研究人员或者企业迅速进行网络资产匹配,例如进行漏洞影响范围分析、应用分布统计、应用流行度等。
FOFA 搜索引擎检索到的内容主要是服务器,数据库,某个网站管理后台,路由器,交换机,公共ip的打印机,网络摄像头,门禁系统,Web服务 ……
FOFA 这类搜索引擎又有另一个名字:网络空间测绘系统。—— 它们就像是现实生活中的卫星地图那样,一点点勾勒出公共网络空间的样子,每一个网站、每一台公共环境下的服务器……当一个高危漏洞爆发,FOFA系统便能向卫星定位地址一样,通过特征迅速找到全网的脆弱设备。
网站:https://fofa.so/ FOFA不仅提供了在线搜索还提供了FOFA Pro客户端版本
简单来说就是跟国外的shodan,国内的ZoomEye一样是网络空间测绘工具
流程
登陆 -> 输入关键字 -> 爬取 -> 保存
登陆
登陆流程比较复杂,为了简单暴力直接使用cookie,每次使用时需要在 config.py 文件中修改 cookie值
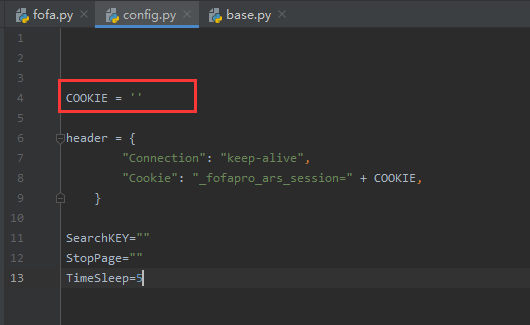
此外config.py里面还存储了一些全局的配置信息
输入关键字

在页面输入我们需要查找的关键字,例如 aaa
跳转网页为:https://fofa.so/result?q=aaa&qbase64=YWFh&file=&file=
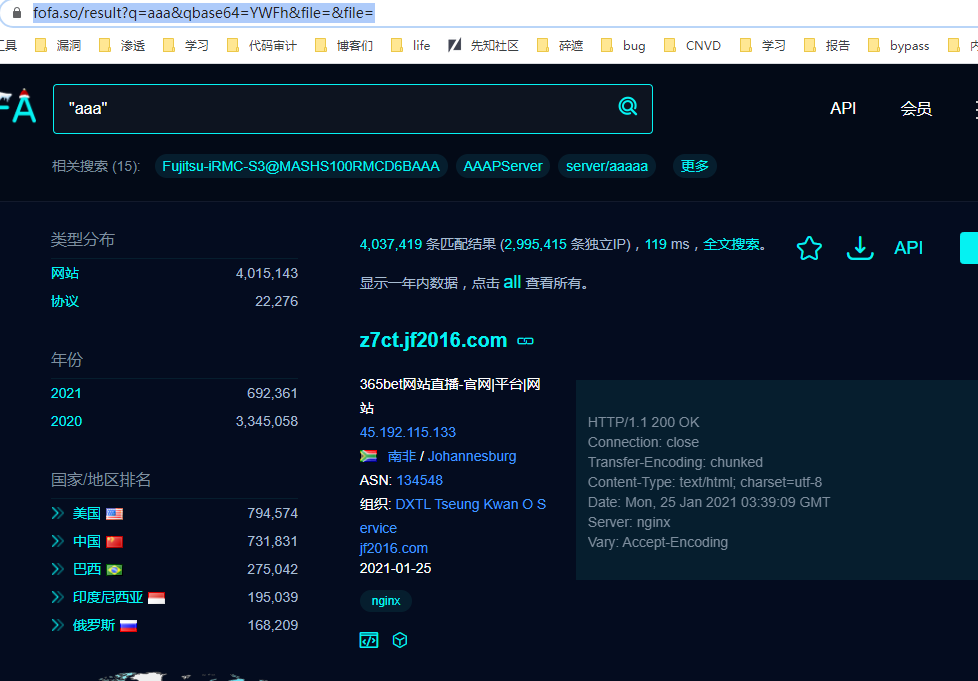
可以看出来qbase64是关键字base64的编码,经过测试只需要这两个关键字即可进行搜索
https://fofa.so/result?page=&qbase64=
page为页码,qbase64为关键字的base64编码
关键字转base64编码关键代码如下
使用quote对URL进行编码,防止出现错误
爬取
使用正则表达式显示该关键字在fofa中一共有多少页
先让用户确定爬取的开始和结束页码
使用xpath提取页面url
保存
保存在 hello_world.txt文件中
完成
END
全部代码放在 github上:https://github.com/Cl0udG0d/Fofa-script
EOF

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)