
西瓜书的第三章(线性模型)
学习一些相关的概念。基础的形式,线性回归、均方误差、梯度下降等关键内容,涵盖对数几率回归、多分类学习及类别不平衡问题多分类学习(Multi-class Classification)是机器学习中的一种任务类型,旨在将输入的样本划分到多个不同的类别中。与二分类(只有两个类别,是猫或不是猫)不同,多分类面对的是具有三个或更多类别情况,例如在图像识别中区分不同种类的动物(猫、鸟、狗等)在分类任务中不同类
西瓜书的第三章(线性模型)
文章目录
- 西瓜书的第三章(线性模型)
- 前言
- 一、基本的形式
-
- 1.函数形式
- 2.向量形式
- 二、线性回归——Linear regression
-
- 1.概念
-
- 1)回归与分类
- 2)线性与非线性的概念
- 2.线性关系的基本假设:
- 3.怎么判读拟合的效果好不好?
-
- 1)预测值:
- 2) 误差项:
- 1.1. == 最小二乘法( Least Squate ,LS)---步骤,公式推导 ==
- 1)公式(推导)
- 2)补充
- 3)优点
- 4)缺点
- 1.2. ==梯度下降法(GD)---步骤,公式推导 ==
- 1)偏导与梯度
- 2)凹凸函数的不同
- 3)学习率问题
-
- 学习率公式
- 4)方式
- 4.==线性回归的相关系数与决定系数(拟合度)==
-
- 1)相关系数:
- 2)决定系数:
- 5.扩展到多元线性回归
- 三、对数几率回归(又名逻辑回归)
-
- 1.目的
- 2. 相关概念(几率、对数几率)
- 3.逻辑回归流程(手写)
- 四、代码演示(简单的逻辑回归模型)
-
- 定义传播函数
-
- 1. 前向传播
- 2.计算成本
- 3.反向传播
- 4.预测函数
- 5.更新参数
- 拓展
- 五、线性判别
-
- 线性判别分析
-
- 1.原理
- 六、多分类学习
-
- 定义
- 常见的解决策略
-
- 一对多策略(One-vs-Rest,简称 OvR):
-
- 原理:
-
- 优点
- 缺点
- 一对一策略(One-vs-One,简称 OvO):
-
-
- 原理
-
- 多对多策略(Many-vs-Many,简称 MvM):
-
-
- 原理
- 优点
- 缺点
-
- 七、类别不平衡问题
-
-
- 定义
- 产生的影响
- 解决类别不平衡问题的常用方法
-
前言
学习一些相关的概念。基础的形式,线性回归、均方误差、梯度下降等关键内容,涵盖对数几率回归、多分类学习及类别不平衡问题
一、基本的形式
1.函数形式
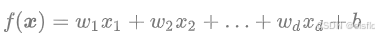
就比如
当d=1;w=[w1]
当d=2;w=[w1,w2]
2.向量形式
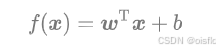
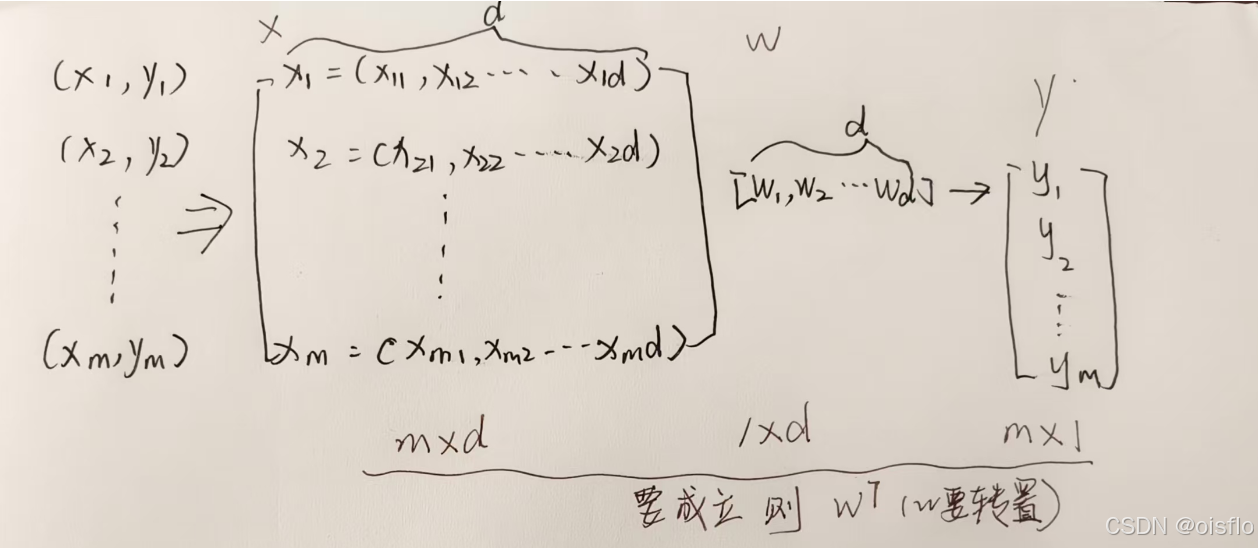 已经解释了w为什么要转置哦~
已经解释了w为什么要转置哦~
代码的实现如下
Z = np.dot(w.T, X) + b
二、线性回归——Linear regression
1.概念
是变量之间的关系——>自变量/因变量
线性:然而通常情况下,变量间是近似的线性关系
1)回归与分类
分类 的结果是离散,例如二分类,结果是1,0
回归 的结果是连续的,就像y=kx+b的函数图,没有间断
因变量和自变量之间是线性关系,就可以使用线性回归来建模
2)线性与非线性的概念
简单一点,就是线性是一元的,是一条直线eg.x,而非线性的是多元的eg.x∗∗2,x∗∗3eg.x**2,x**3eg.x∗∗2,x∗∗3
2.线性关系的基本假设:
- 自变量与因变量间存在线性关系;
- 数据点之间独立;
- 自变量之间无共线性,相互独立;
- 残差独立,等方差,且符合正态分布
3.怎么判读拟合的效果好不好?
1)预测值:
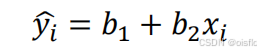
2) 误差项:
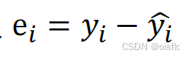
1.1. == 最小二乘法( Least Squate ,LS)—步骤,公式推导 ==
是线性回归中常用的性能度量,最小化均方误差是模型求解的关键(就是要得到的结果与我们想要的结果,无限接近,减少误差,求最小)
1)公式(推导)
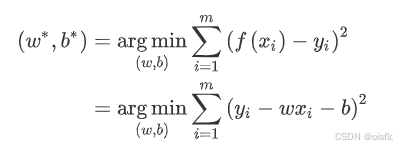
- 1.求偏导
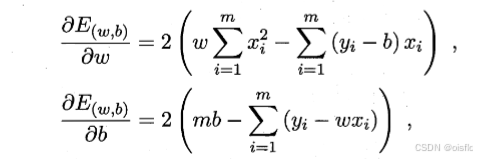
- 2.最优的w,b(记忆)
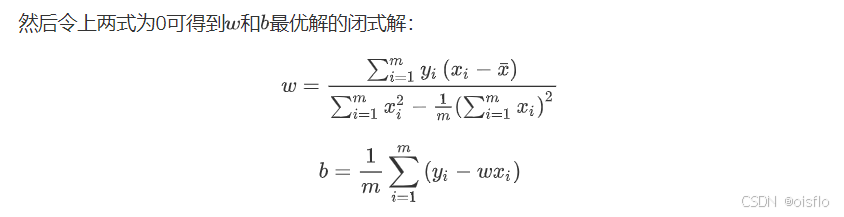
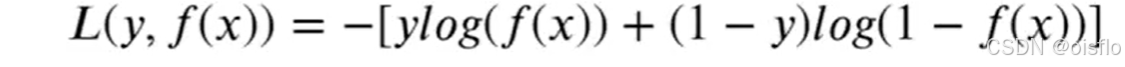
2)补充
类似的,可利用最小二乘法来对w和b进行估计.为便于讨论,我们把w和b吸收入向量形式ω=(w;b),相应的,把数据集D表示为一个m×(d+1)大小的矩阵X,其中每行对应于一个示例,该行前d个元素对应于示例的d个属性值,最后一个元素恒置为1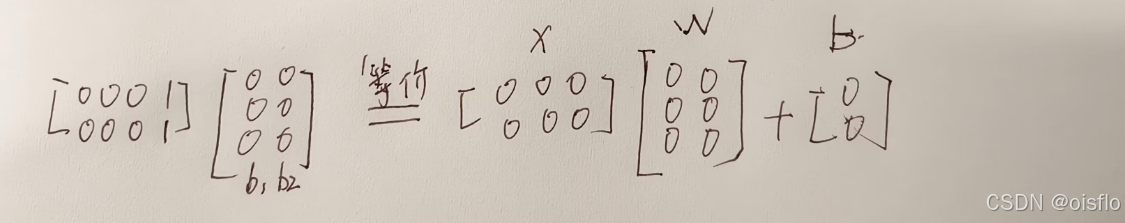
3)优点
• 损失函数是严格的凸函数,有唯一解
• 求解过程简单且容易计算
4)缺点
- 结果对数据中的 == “离群点”(outlier) ==非常敏感
解决方法:提前检测离群点并去除
• 损失函数对于超过和低于真实值的预测是等价的
• 但有些真实情况下二者带来的影响是不同的
1.2. ==梯度下降法(GD)—步骤,公式推导 ==
梯度下降法
• 初始化 𝑏1, 𝑏2 • 重复:
• 𝑏1 = 𝑏1 − 𝛼
• 𝑏2 = 𝑏2 − 𝛼
1)偏导与梯度
梯度就是函数曲面的陡度,偏导数是某个具体方向上的陡度.。梯度就等于所有方向上偏导数的向量和。
2)凹凸函数的不同
凸性定理:如果函数的二阶导数大于0,则是凸函数;如果小于0,则是凹函数;等于0,是平函数。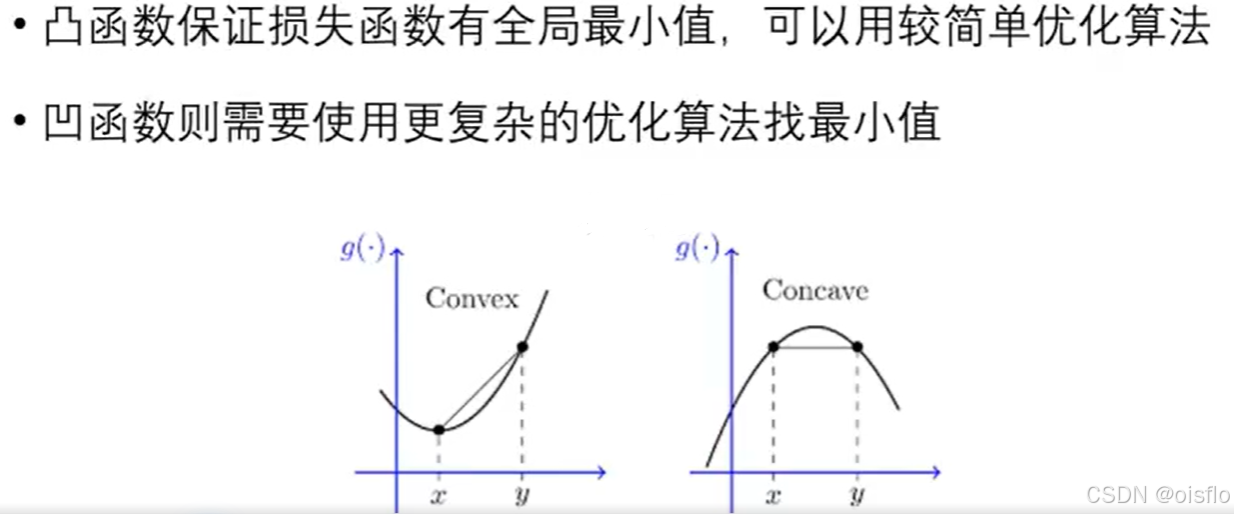
3)学习率问题
学习率公式
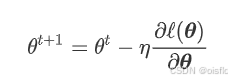
学习率太小,收敛慢
学习率太大,达不到最低点
# 使用梯度下降更新参数
w = w - learning_rate * dw
# 根据梯度下降算法,按照学习率和计算得到的权重梯度来更新权重 w,
#朝着成本最小化的方向调整
b = b - learning_rate * db
# 同理,根据偏差的梯度和学习率更新偏差 b
最开始学习率是我们自己设的,代码在不断的运行迭代(学习率),使学习率最优,可以更快,更加准确到达最低点
4)方式
1.网格搜索(设置迭代的数量)
#num_iterations -- 梯度下降的迭代次数,默认值为2000,即模型参数更新的轮数。
def model(X_train, Y_train, X_test, Y_test, num_iterations=2000,learning_rate=0.1, print_cost=False):
2.梯度限制(大量迭代,不设数量)
4.线性回归的相关系数与决定系数(拟合度)
1)相关系数:
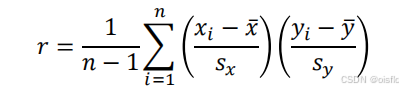
2)决定系数:
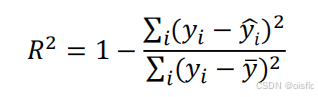
相关系数与决定系数:相关 ≠ 因果
5.扩展到多元线性回归
三、对数几率回归(又名逻辑回归)
1.目的
通过引入一个非线性的激活函数(即对数几率函数,也就是常说的 sigmoid 函数)将线性回归的结果映射到概率值(0 到 1 之间),从而实现分类目的。
2. 相关概念(几率、对数几率)
简单复述一下我对书上的理解:首先,我们有一个线性方程
但是我们的问题是想让这个函数有一个能力:将预测值落在0~1之间。现在是一个线性函数,范围是负无穷到正无穷。这是后有一个非线性函数(看下面画了圈的函数)与它进行巧妙的结合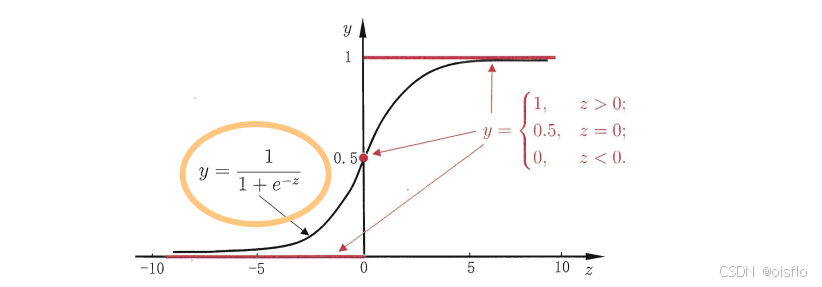
结合的结果是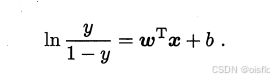
因为答案的只有两种1和0(按照二分类),如果y是正例,则1-y为反例。
接下来是介绍“对数几率(logit)"。因为 y/1-y 叫几率 ,所以前面加了 对数(ln) 叫"对数几率" (抱歉,我是这样浅显的认为的)。
3.逻辑回归流程(手写)
前向传播->计算成本(loss函数)->反向传播(更新w,b参数,学习率)->前向传播(循环)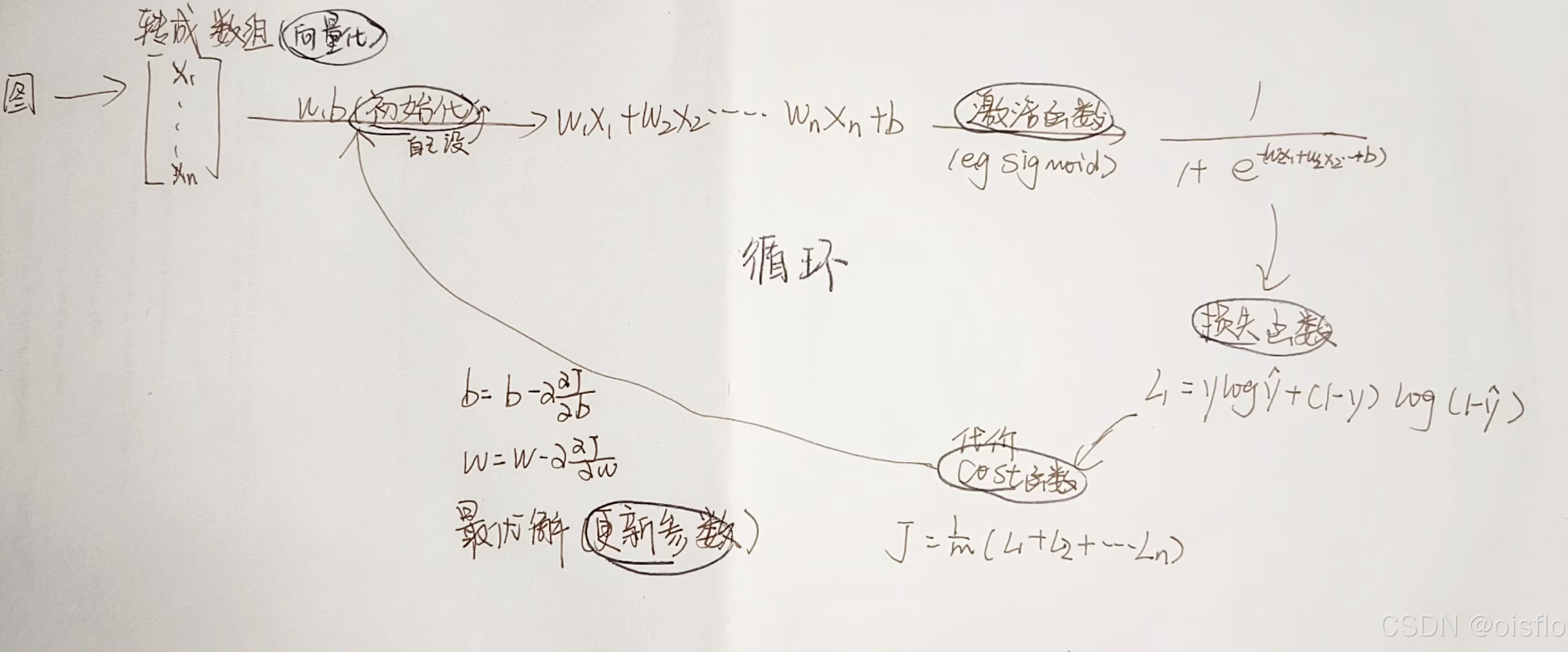
四、代码演示(简单的逻辑回归模型)
从最基础的前向传播、反向传播计算,到通过梯度下降法训练模型以及对模型进行预测和评估准确率等功能,通过自定义的数据模拟了训练和测试的过程(主要是想把前面的概念运用起来,不喜欢可以跳过,后面有简单分析)
定义传播函数
1. 前向传播
Z = np.dot(w.T, X) + b
# 计算线性组合加上偏差,得到中间变量 Z,这里 w.T 是将权重矩阵转置后与输入数据 X 做点积运算,形状为 (1, 样本数量)
A = 1 / (1 + np.exp(-Z))
# 通过 sigmoid 函数将 Z 转换为概率值(0到1之间),得到激活值 A,A 表示模型预测样本为正类(比如类别为1)的概率,形状同样为 (1, 样本数量)
2.计算成本
cost = -np.sum(Y * np.log(A) + (1 - Y) * np.log(1 - A)) / m
# 根据逻辑回归的成本函数(交叉熵损失函数)计算成本,对每个样本的损失求和后取平均,反映模型预测与真实标签的差异
3.反向传播
dw = np.dot(X, (A - Y).T) / m
# 计算权重 w 的梯度,根据链式法则推导得出,通过输入数据 X 与预测值和真实值的差值 (A - Y) 的转置做点积,再除以样本数量进行平均
db = np.sum(A - Y) / m
# 计算偏差 b 的梯度,直接对预测值和真实值的差值 (A - Y) 求和后除以样本数量
grads = {"dw": dw, "db": db} # 将权重和偏差的梯度封装到字典中
return grads, cost
4.预测函数
for i in range(m):
if A[0, i] <= 0.5:
Y_prediction[0, i] = 0
# 如果预测概率小于等于0.5,则将对应的预测类别设为0
else:
Y_prediction[0, i] = 1
# 如果预测概率大于0.5,则将对应的预测类别设为1
return Y_prediction
5.更新参数
# 使用梯度下降更新参数
w = w - learning_rate * dw
# 根据梯度下降算法,按照学习率和计算得到的权重梯度来更新权重 w,朝着成本最小化的方向调整
b = b - learning_rate * db
# 同理,根据偏差的梯度和学习率更新偏差 b
拓展
以下是常见的激活函数介绍:
-
Softmax 函数:
-
公式
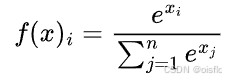
-
特点:Softmax 函数将一组数值转换为概率分布,即所有输出的和为(1),且每个输出都在((0, 1))之间。
-
优点:适用于多分类问题的输出层,可以将网络的输出转换为概率值,便于对不同类别的可能性进行比较和预测。
-
缺点:在零点不可微;负输入的梯度为零,对于该区域的激活,权重在反向传播期间不会更新,可能会产生永不激活的“死亡神经元”。
-
-
Tanh 函数(双曲正切函数):
-
公式:
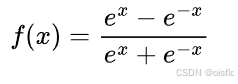
-
特点:输出值范围在(-1)到(1)之间,形状也是类似“S”形,但相对于 Sigmoid 函数,它是关于原点对称的,即以(0)为中心。
-
缺点:和 Sigmoid 函数一样,在输入较大或较小时,梯度接近(0),存在梯度消失问题,不太适合深度神经网络。
-
-
ReLU 函数
- 公式
-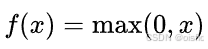
- 特点:当(x)大于(0)时,输出就是(x)本身;当(x)小于等于(0)时,输出为(0)。图像呈现出在(x)轴负半轴为(0),正半轴是一条斜率为(1)的直线的样子。
- 优点:
- 有效解决了梯度消失问题,在(x>0)的区间,其导数恒为(1),使网络能够更快地进行训练,适合用于深层神经网络。
- 计算简单高效,没有复杂的指数运算,计算速度快。
- 缺点:
- 神经元在训练时比较容易“死亡”。如果神经元参数值在一次不恰当的更新后小于(0),那么这个神经元自身参数的梯度永远都会是(0),在以后的训练过程中永远不能被激活。
- 输出是非零中心化的,可能会给后一层的神经网络引入偏置偏移,影响梯度下降的效率。
- 公式
-
Leaky ReLU 函数:
- 公式
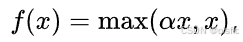
- 特点:Leaky ReLU 是 ReLU 的一个变体,在输入为负时给予一个小的非零斜率,避免了 ReLU 中神经元“死亡”的问题。
- 优点:保留了 ReLU 的优点,如计算速度快、缓解梯度消失等,同时在一定程度上减轻了“死神经元”问题,提高了网络的稳定性和训练效果。
- 缺点 a的值需要手动设定,并且在实际应用中尚未完全证明它总是比 ReLU 更好。
-
ELU 函数(Exponential Linear Units)
- 公式
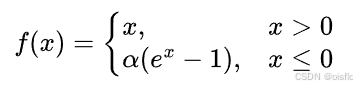
- 公式
五、线性判别
线性判别分析
1.原理
LDA给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别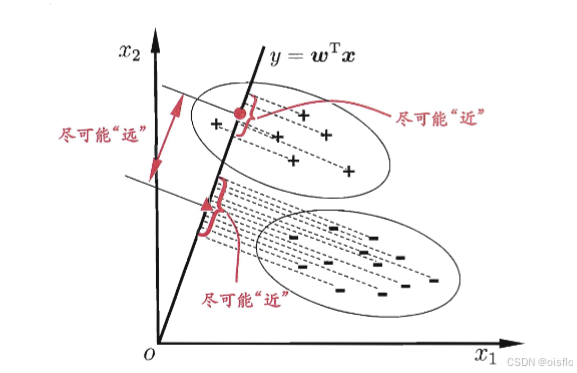
- 同类样例的投影点尽可能接近:让同类的协方差尽可能小

- 异类样例的投影点尽可能远离:让异类的中心之间的距离尽可能大
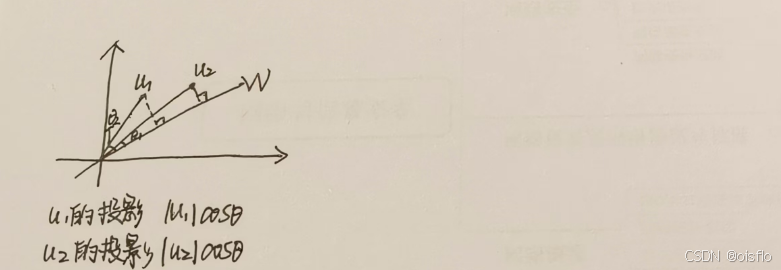

- 结合(要分子大,分母小)
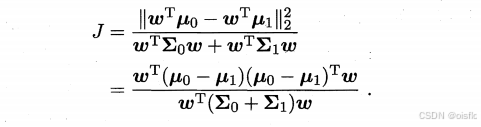
六、多分类学习
定义
多分类学习(Multi-class Classification)是机器学习中的一种任务类型,旨在将输入的样本划分到多个不同的类别中。与二分类(只有两个类别,是猫或不是猫)不同,多分类面对的是具有三个或更多类别情况,例如在图像识别中区分不同种类的动物(猫、鸟、狗等)
常见的解决策略
一对多策略(One-vs-Rest,简称 OvR):
原理:
对于有 个类别的多分类问题,把它转化为 个二分类问题。具体做法是,每次将其中一个类别作为正类,其余的 个类别都作为反类,这样就构建出了 个二分类器。
优点
简单直观,容易理解和实现,可直接利用现有的二分类算法(如逻辑回归等)来构建多分类模型。
缺点
在训练时需要训练多个二分类器,可能导致训练时间较长;而且每个二分类器只关注一个类别的区分,忽略了类别之间的关联性,有可能会出现类别不平衡等问题影响分类效果。
一对一策略(One-vs-One,简称 OvO):
原理
构建三个二分类器,分别是猫和狗、猫和兔子、狗和兔子这两两之间的分类器。在预测时,一个新样本通过所有的这些二分类器进行分类
多对多策略(Many-vs-Many,简称 MvM):
原理
它是一种更为灵活的策略,先将所有类别划分成多个不同的子集,然后在这些子集之间构建二分类器,子集的划分方式有多种,可以基于一些先验知识或者特定的算法来进行
优点
可以根据数据特点灵活地进行类别子集划分,有可能更好地利用类别之间的内在联系,提高分类效率和准确性
缺点
子集划分的好坏对分类结果影响较大,如果划分不合理,可能导致分类效果不佳;而且其实现相对复杂,需要对数据有更深入的理解和合适的划分方法
七、类别不平衡问题
定义
在分类任务中不同类别在样本数量上存在较大差异的现象。
例如,在一个判断是否患有某种罕见病的医疗数据集中,健康人群的样本数量可能有10000个,而患有该病的患者样本仅有100个
产生的影响
- 对模型训练的影响:
- 学习偏向:大多数机器学习算法在训练时倾向于让整体的分类准确率尽量高,这样就容易忽略少数类别的特征,导致对少数类别的分类能力很差。例如在上述医疗例子中,模型可能直接把所有样本都预测为健康人群,这样整体准确率看似很高(能达到约99%),但实际上对于真正需要关注的患病类别却完全无法准确识别,失去了实际应用价值。
- 模型评估偏差:常用的评估指标如准确率(Accuracy)在类别不平衡时会产生误导。继续以医疗例子来说,即使模型完全不考虑患病类别,只预测为健康人群,也能获得很高的准确率
解决类别不平衡问题的常用方法
-
数据层面的方法:
- 过采样(Oversampling):
- 原理:增加少数类别的样本数量,使其与多数类别样本数量相当或接近,从而平衡不同类别间的样本分布
- 优点:可以直接改变数据分布,让模型在训练时能更均衡地学习不同类别的特征,相对简单直接地缓解类别不平衡问题
- 缺点:随机过采样可能导致过拟合,可能生成不合理的样本,且增加了数据量会加大计算成本和训练时间
- 欠采样(Undersampling):
- 原理:减少多数类别的样本数量,使其与少数类别达到相对平衡
- 优点:能快速降低数据规模,减少训练时间和计算资源消耗,并且在一定程度上可以缓解类别不平衡对模型的影响,让模型不会过度偏向多数类别
- 缺点:可能会丢失多数类别中的一些有用信息,因为是直接舍弃了部分样本,如果舍弃不当可能导致模型学习到的多数类别特征不全面,影响模型的泛化能力和整体性能
- 过采样(Oversampling):
-
算法层面的方法:
- 调整分类阈值:对于像逻辑回归等能输出类别概率的分类算法,可以根据训练集上不同类别样本的先验概率情况,手动调整分类阈值
- 使用代价敏感学习(Cost-sensitive Learning):
- 原理:为不同类别样本在模型训练过程中设置不同的误分类代价
- 优点:不需要改变原始数据的分布,直接从算法训练的角度来解决类别不平衡问题,能根据实际情况灵活地分配不同类别样本的重要性,提高对少数类别的分类性能
- 缺点:代价的设定往往需要对具体业务场景有深入了解,并且要通过多次实验来合理确定不同类别的代价参数

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)