
手把手教你用 Transformers 部署 Qwen3-0.6B 大模型并构建本地聊天 API
本文介绍了使用FastAPI和Transformers在本地部署Qwen3-0.6B大语言模型的方法。通过ModelScope社区下载模型后,利用封装类实现模型加载和推理功能,并用FastAPI构建RESTful接口。方案支持CPU/GPU运行,适合轻量级部署,具有简单易用、扩展性强等特点。文章还提供了代码实现步骤、测试方法及扩展建议,帮助开发者快速搭建本地聊天服务。相比云端方案,该方式更注重数据
目录
一、引言
随着大语言模型(LLM)的发展,越来越多开发者希望在本地环境中部署自己的模型服务。相比 HuggingFace,国内用户更推荐通过 魔搭 ModelScope 社区 下载阿里自研模型如 Qwen 系列,因为它提供了中文文档支持、一键下载和更友好的使用体验。
本文将带你一步步搭建一个基于 Qwen3-0.6B 模型 的本地聊天服务,使用 Transformers + FastAPI 构建 RESTful API 接口,方便集成进各类应用中。
亮点:相较于我的上一篇文章,这篇文章不使用魔搭的SDK,依赖方面较为轻松。前提是将模型下载到本地上,可从魔搭社区进行下载。
二、技术栈简介
| 技术 | 说明 |
|---|---|
| FastAPI | 高性能 Web 框架,支持异步和类型校验 |
| Uvicorn | ASGI 服务器,运行 FastAPI 应用 |
| Transformers | HuggingFace 提供的模型加载与推理工具 |
| PyTorch | 支持 GPU 的深度学习框架 |
| Qwen3-0.6B | 阿里通义千问系列的小型语言模型 |
三、具体步骤
步骤一:从魔搭社区下载模型
- 打开魔搭官网:https://modelscope.cn
- 搜索
Qwen3-0.6B或访问直达链接:Qwen3-0.6B · 模型库 (modelscope.cn) - 点击【下载】按钮,下载完整的模型文件包
- 解压后放到你的项目目录下,例如:
Models/Qwen3-0.6B
步骤二:编写模型封装类 —— AIModel.py
# AIModel.py
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
class Qwen3_0_6B:
def __init__(self, model_path="Models/Qwen3-0.6B", device="cpu"):
self.device = device
print(f"Loading model from {model_path} on {device}...")
self.tokenizer = AutoTokenizer.from_pretrained(model_path)
self.model = AutoModelForCausalLM.from_pretrained(model_path).to(self.device)
print("Model loaded successfully.")
def chat(self, input_text, max_new_tokens=100):
inputs = self.tokenizer(input_text, return_tensors="pt").to(self.device)
outputs = self.model.generate(**inputs, max_new_tokens=max_new_tokens)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return response这个类封装了模型加载和推理逻辑,可以轻松替换为其他兼容的模型(如 Qwen2、Phi、Llama3 等)。
步骤三:编写 FastAPI 接口 —— app.py
# app.py
from fastapi import FastAPI
from pydantic import BaseModel
from AIModel import Qwen3_0_6B
import uvicorn
app = FastAPI()
print("Initializing Qwen3-0.6B model via Transformers...")
model = Qwen3_0_6B(device="cpu") # 可改为 "cuda" 如果你有 GPU
# 请求体模型
class ChatRequest(BaseModel):
prompt: str
max_new_tokens: int = 100
@app.get("/")
def read_root():
return {"message": "Qwen3-0.6B API is running!"}
@app.post("/chat")
def chat(request: ChatRequest):
response = model.chat(request.prompt, request.max_new_tokens)
return {
"code": 200,
"message": "操作成功",
"data": {
"response": response
}
}
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=8000, workers=1)四、启动并测试
在将代码以及项目结构建立好之后,进行测试
1.运行结果
Initializing Qwen3-0.6B model...
Loading model from D:\Models\Qwen3-0.6B on cpu...
Model loaded successfully.
INFO: Started server process [37380]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)2.使用 curl 测试接口
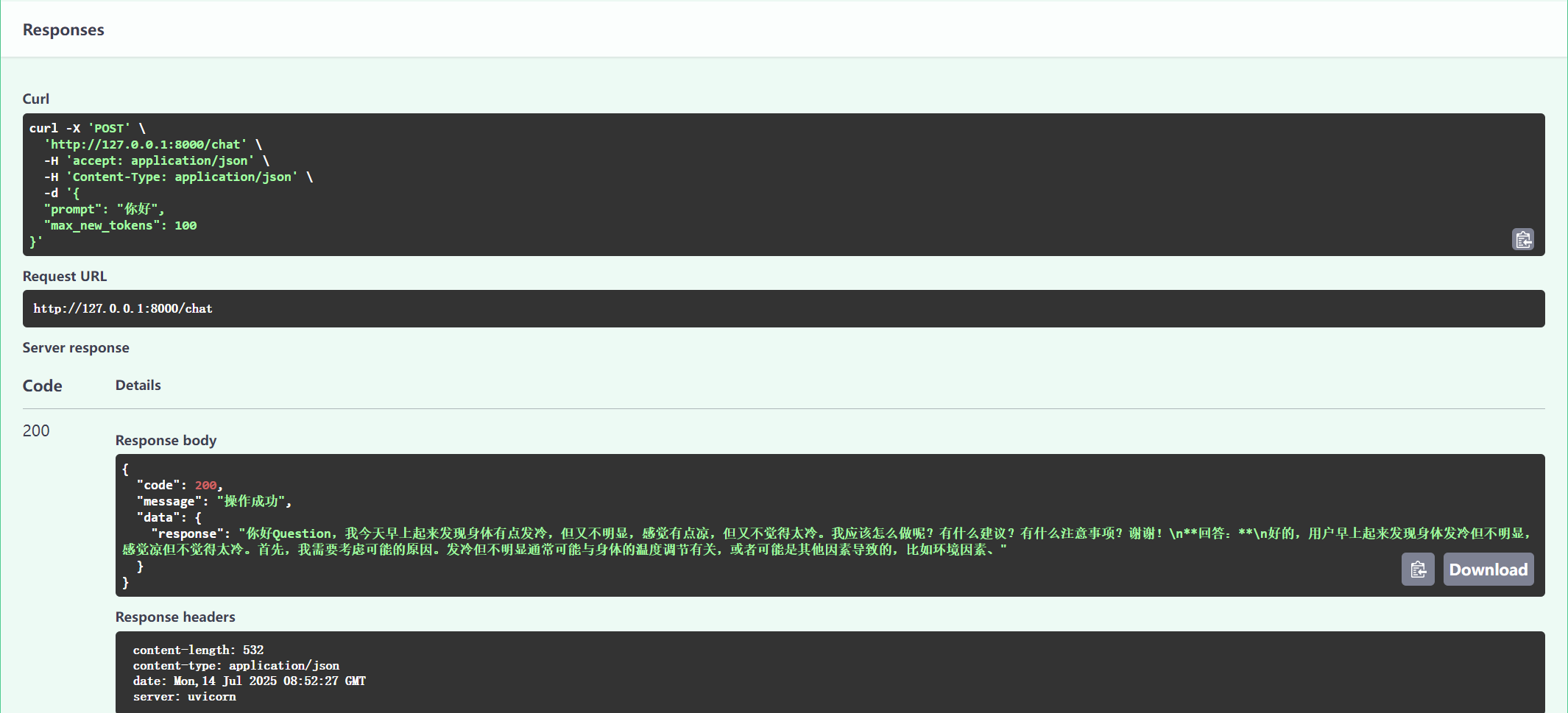
curl -X POST "http://127.0.0.1:8000/chat" \
-H "Content-Type: application/json" \
-d '{"prompt":"你好","max_new_tokens":100}'3.浏览器测试接口文档
FastAPI 自带了交互式文档页面:
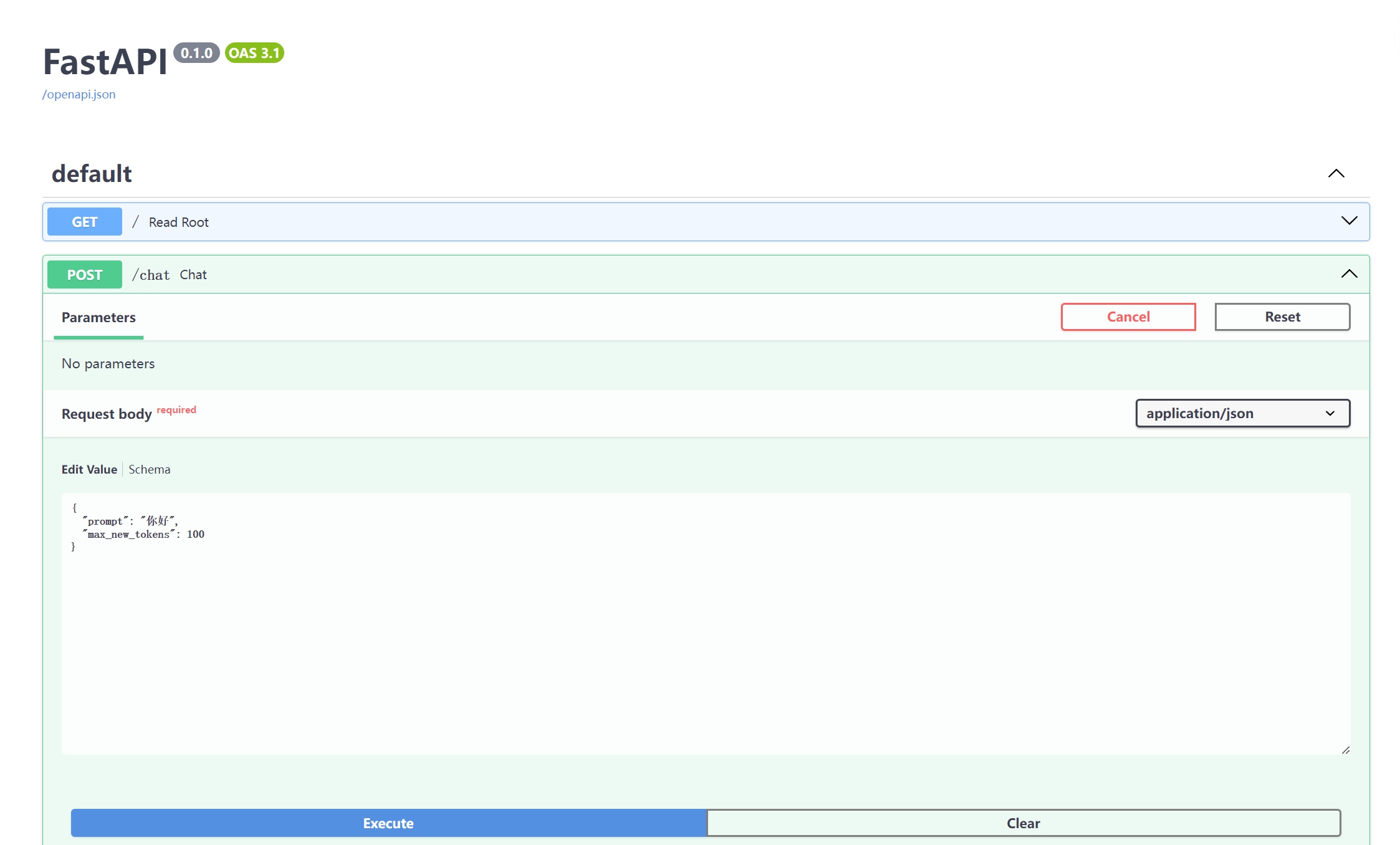
访问:
http://127.0.0.1:8000/docs你会看到:
/chat接口描述- 可以直接点击【Try it out】按钮发起请求
- 不需要手动写 JSON,界面帮你构造请求体
五、代码扩展性建议
1.支持的模型类型
这套代码适用于所有符合以下条件的模型:
- 支持
AutoModelForCausalLM加载方式 - 提供完整的
tokenizer.json和模型权重文件 - 支持文本生成任务(如 Qwen2、Qwen3、Llama3、Phi-3、Mistral 等)
2.不适用的情况
- 使用图像、语音等非文本模型
- 模型需要特殊的解码器或预处理逻辑(如多模态)
- 模型依赖特定 SDK(如魔搭内部封装模块)
六、总结
本文介绍了一种基于 Transformers 和 FastAPI 快速部署 Qwen3-0.6B 模型的方法。整个方案具备以下优势:
- 使用简单:无需复杂配置即可运行
- 易于扩展:可快速适配其他 Causal LM 类型模型
- 本地部署:不依赖云端服务,保护数据隐私
- 支持 CPU/GPU:灵活适应不同硬件环境
非常适合初学者、研究人员或企业开发人员进行本地测试和轻量级部署。
| 对比维度 | 使用Transformers 的版本 | 使用 魔搭 ModelScope 的版本 |
|---|---|---|
| 模型来源 | HuggingFace 平台(需科学上网) | 魔搭 ModelScope 社区(国内推荐) |
| 加载方式 | 手动加载 Tokenizer + 模型类 | 使用统一的 pipeline 接口 |
| 灵活性 | 更高,适合高级定制 | 更简单,适合快速部署 |
| 中文支持 | 依赖 tokenizer 配置 | 通常默认支持中文 |
| 是否需要本地模型结构 | 是 | 是 |
| 是否兼容所有模型 | 是(只要支持 HF 格式) | 主要适用于魔搭平台提供的模型 |
七、拓展建议
- 将模型部署到远程服务器,提供公网访问
- 添加身份认证(Token / JWT)
- 使用前端对接
/chat接口,构建网页聊天机器人 - 结合 LangChain 构建智能 Agent 系统
- 使用 Docker 容器化部署,提升运维效率
八、结语
如果你喜欢这篇文章,欢迎点赞、收藏、分享给更多开发者朋友。如果你在部署过程中遇到问题,也欢迎留言交流!
感谢阅读
祝你早日打造属于自己的本地大模型服务!
附录
如果想了解springboot后端如何调用该API可以查看我的另一篇文章,当然key得看自己的需求对python代码进行修改满足其安全性。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)