
【分割论文集】LSBNet: Lightweight Symmetrically Balanced Network for Real-Time Semantic Segmentation
为了解决现有语义分割模型在移动设备上计算开销过大与实时推理速度之间的平衡问题,提出了一种用于实时语义分割的轻量化对称平衡网络(Lightweight Symmetrically Balanced Network,LSBNet)。
摘要
为了解决现有语义分割模型在移动设备上计算开销过大与实时推理速度之间的平衡问题,提出了一种用于实时语义分割的轻量化对称平衡网络(Lightweight Symmetrically Balanced Network,LSBNet)。LSBNet通过三个关键模块实现其目标:细节增强模块(Detail Reinforcement Module,DRM)、信息互补模块(Information Complementarity Module,ICM)以及有效的聚合金字塔池化模块(Effective Aggregation Pyramid Pooling Module,EAPPM)。DRM旨在补偿特征提取过程中丢失的空间细节信息,以提高分割精度。ICM解决了语义特征与细节特征融合过程中的不平衡问题,并通过通道注意力和空间注意力机制增强语义特征中的细节信息。此外,EAPPM用于聚合全局多尺度上下文信息。实验结果表明,LSBNet在Cityscapes和Camvid数据集上分别达到了73.4%和73.7%的平均交并比(mIoU),表现出色。值得一提的是,LSBNet仅包含870万参数,在保持高分割精度的同时大幅减少了参数数量,与大多数现有的先进模型相比,展现了其在轻量化模型设计方面的优越性。
引言
在计算机视觉领域,语义分割是一个非常重要且具有挑战性的研究课题,其目标是为输入图像的每个像素准确分配一个类别标签。在现实生活中,语义分割被广泛应用于自动驾驶[1, 2]和医学图像处理[3]等领域。然而,在自动驾驶和医学诊断等资源有限、计算能力较低的移动设备上,也需要实现实时推理。因此,如何在准确性和速度之间取得平衡,并设计出高效且实时的网络,是实时语义分割的基本任务。
在本工作中,我们提出了一种名为LSBNet(Lightweight Symmetrically Balanced Network)的新型轻量化对称平衡实时分割网络,如图1所示。LSBNet采用编码器-解码器结构,并包含三个新颖的模块:细节增强模块(Detail Reinforcement Module,DRM)、信息互补模块(Information Complementarity Module,ICM)以及有效的聚合金字塔池化模块(Effective Aggregation Pyramid Pooling Module,EAPPM)。所提出的模型旨在解决在资源有限的移动设备(如自动驾驶)中存在分割精度和推理速度不平衡的问题。定义轻量化模型的一些常见指标包括参数数量、计算复杂度和推理速度等。轻量化模型的参数数量通常约为10M,计算复杂度通常约为20 GFLOPs,推理速度通常高于50 FPS。所提出的模型仅有8.7M参数,计算复杂度为15.94 GFLOPs,在Cityscapes数据集上推理速度为79 FPS,符合轻量化模型的定义标准。
语义分割模型中的编码器通过连续下采样提取图像不同层次的特征,而解码器则与编码器中不同层次的特征进行连续融合,然后上采样特征以恢复到原始图像的大小。对于编码器,我们使用RepVIT[6]作为骨干网络来提取不同层次的特征,RepVIT是一种在计算机视觉领域表现出色的纯卷积神经网络模型。然而,在特征提取过程中,一些重要的细粒度信息不可避免地会丢失。为此,我们设计了一个轻量化的细节增强模块(DRM),作为在解码器中与语义信息融合之前的预处理步骤。对于解码器,高级语义信息和低级细节信息的融合可以使模型获得更丰富、更全面的语义信息,从而提高模型对图像内容的理解和分割精度。然而,现有方法不仅未能有效平衡这种关系,还存在计算成本高的问题。为此,我们开发了一个利用注意力机制高效丰富特征表示的信息互补模块(ICM)。上下文聚合也是提高分割精度的有效方法,但以往的方法耗时较长。基于DDRNet[7]中DAPPM的结构,我们提出了一种新的有效的聚合金字塔池化模块(EAPPM),以建模全局信息作为编码器和解码器之间的桥梁。
方法
2.1 LSBNet结构
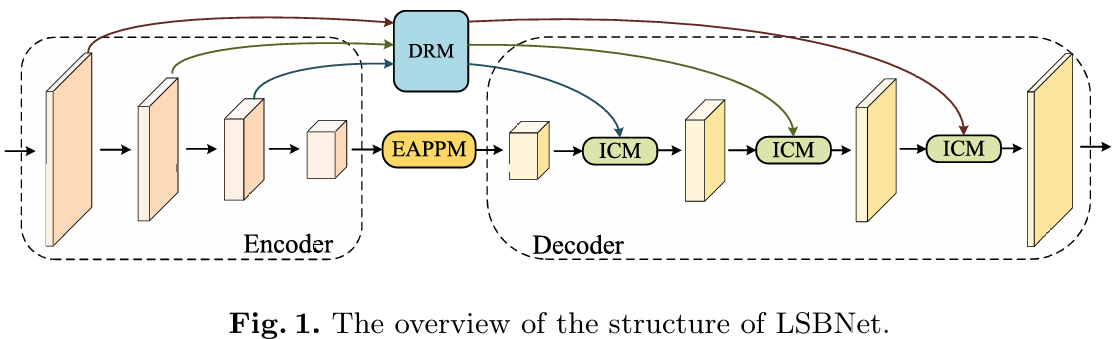
LSBNet采用了如图1所示的对称编码器-解码器结构。编码器使用高效的骨干网络来捕捉不同层次的特征。解码器通过信息互补模块(ICM)融合高级语义信息和低级细节信息。值得一提的是,我们在编码器和解码器之间嵌入了细节增强模块(DRM)和有效聚合金字塔池化模块(EAPPM),以增强特征表示的质量。
首先,对于输入图像,我们选择RepVIT-M1.1作为骨干网络来提取不同层次的特征,因为它在性能和延迟之间取得了出色的平衡。RepVIT有4个阶段,第一阶段的步长为4,其余阶段的步长为2,最终输出的特征大小是输入图像的1/32。
其次,对于编码器的前三个阶段,我们采用DRM来增强细节信息,以补偿特征提取过程中丢失的细节信息。该模块专注于增强细节信息的表示,从而提高模型对图像中细节信息的感知能力。对于编码器的最后一个阶段,我们使用EAPPM来建模全局依赖关系并提取多尺度全局上下文信息的特征,这有助于模型更好地理解图像中的语义信息。
最后,LSBNet使用解码器逐步融合多级特征并输出最终的结果图像。具体来说,解码器由三个ICM和一个分割头组成。每个ICM接收两个输入特征,一个由编码器生成的低级特征和一个由EAPPM或更深层次融合模块生成的高级特征。为了提高分割性能,ICM中使用了通道注意力和空间注意力。最后一个ICM生成的特征图大小是原始图像的1/4。在分割头中,我们首先使用卷积操作将通道数更改为类别数,然后使用上采样操作将特征图的大小扩展到原始图像的大小。我们使用交叉熵损失来优化模型,以使生成的分割结果尽可能接近真实标签。
2.2 Detail Reinforcement Module
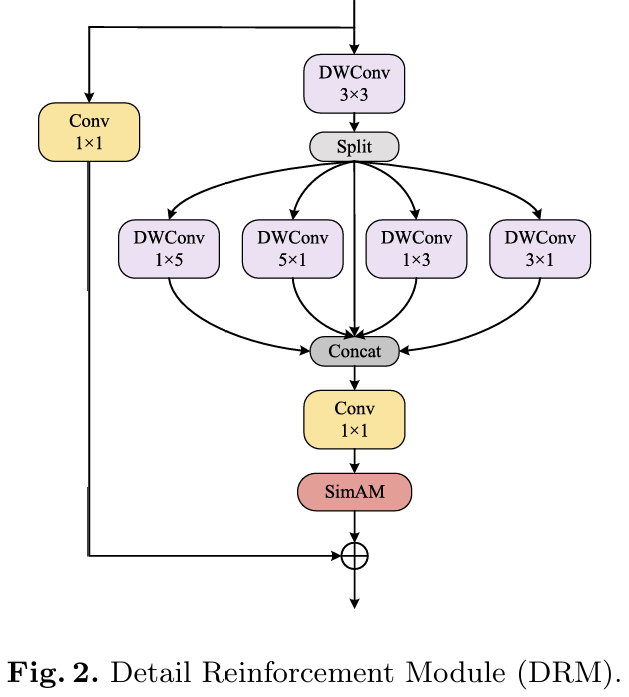
在特征提取过程中保留详细信息是一个挑战。为了解决这个问题,我们提出了一种创新的轻量级细节增强模块(Detail Reinforcement Module, DRM),如图2所示。DRM使用深度可分离卷积代替传统卷积,减少了参数和计算成本,同时高效地提取特征。此外,我们引入了SimAM [12],这是一种无需额外参数的注意力机制。它通过计算每个位置的均值和方差来评估局部重要性,然后进行全局归一化,并使用Sigmoid函数生成注意力权重,这些权重最终用于加权输入特征。这增强了网络捕捉细粒度信息的能力,而无需额外参数,确保了轻量级设计。
在这项工作中,我们对编码器不同阶段的特征进行了一系列精心设计的操作,以最大化保留详细信息,并在保持轻量级目标的同时提取丰富的特征。首先,我们应用了一个3×3的深度可分离卷积,旨在通过高效的卷积操作进行初步特征提取。接下来,我们进行通道分割,并分别对特征图进行1×5、5×1、1×3和3×1的深度可分离卷积操作。这种通道分割策略显著减少了参数数量。不同大小的卷积核可以捕获更多的多尺度详细特征,从而提高了特征表示的丰富性。在特征融合中,我们使用连接(concatenation)方法融合这些多尺度特征,以获得更全面和多样化的信息。然后,应用逐点卷积(pointwise convolution)将多尺度特征结合起来,以获得新的、更丰富的空间特征。然后,我们引入了SimAM无参数注意力机制,它计算并加权特征图中每个像素与其邻域之间的相似性,从而使网络能够更多地关注重要的特征信息,提高模型的表示能力。最后,为了避免在计算过程中可能丢失的数据导致梯度消失或梯度爆炸,我们使用残差连接将输入和输出连接起来。这种设计不仅有助于信息的流动,而且有助于模型训练的稳定性。总之,我们的方法在提取特征时充分考虑了详细信息的保留和丰富性,并在设计中充分考虑了计算复杂性。
2.3 Information Complementarity Module
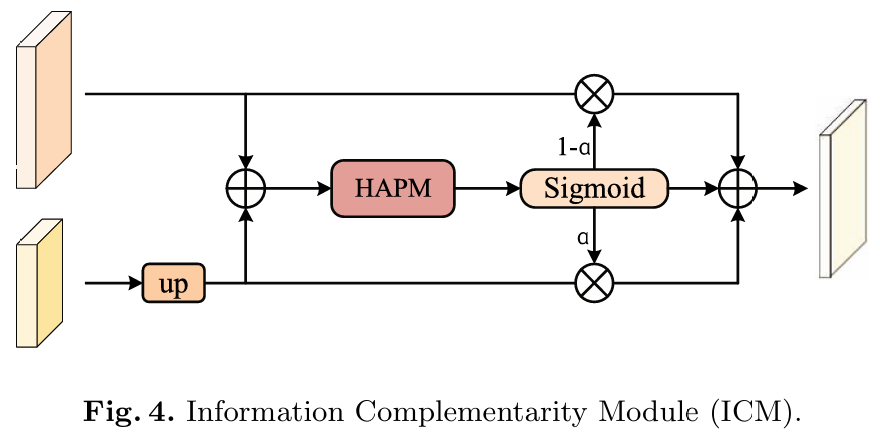
在许多语义分割任务中,例如 UNet [4] 和 DDRNet [7],跳跃连接用于融合特征以增强模型的表达能力。然而,在编码器-解码器结构中,编码器特征包含丰富的低级细节,而解码器特征包含丰富的高级语义信息。直接融合这些特征可能会导致细节特征被模糊的语义信息掩盖,从而导致分割效果不佳。为了解决这一问题,我们设计了一个信息互补模块(Information Complementarity Module, ICM),它使用混合注意力机制来平衡细节信息和语义信息,如图4所示。
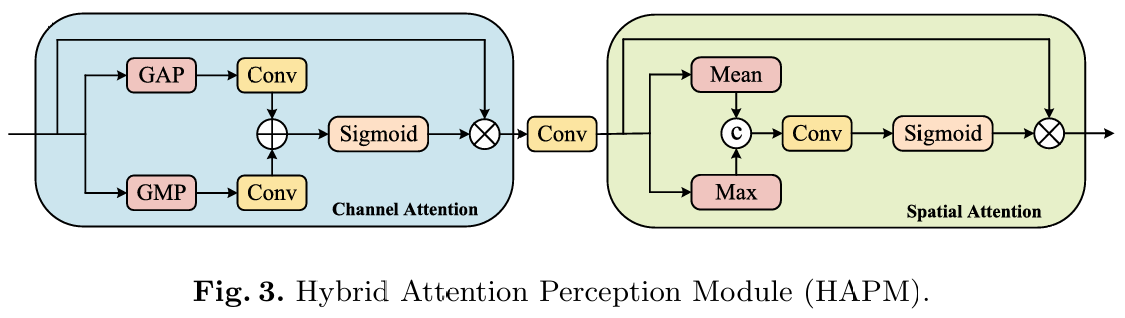
首先,我们将解码器和编码器的特征通过逐像素相加的方式进行融合,以获得包含语义信息和细节信息的特征图。然而,由于特征之间的不平衡,语义信息会对结果产生较大影响,这使得网络难以准确重建细节信息。为此,我们设计了一个混合注意力感知模块(Hybrid Attention Perception Module, HAPM),如图3所示,以帮助实现细节信息和语义信息之间的平衡。HAPM通过通道注意力和空间注意力过滤冗余信息,进一步增强融合特征的特性。通道注意力使用全局平均池化和全局最大池化来提取每个通道中最显著的特征,从而增加对关键通道的关注。而空间注意力则沿着通道计算均值和最大值,增加对关键区域的关注。这两种注意力机制的结合有助于确保融合后的特征在细节信息和语义信息之间更好地平衡。接下来,通过Sigmoid激活函数获得权重图。权重图中的权重分数α越大,像素属于同一类别的可能性就越高。α逐元素乘以解码器中的特征,以获得更准确的语义预测;1-α逐元素乘以编码器中的特征,以获得更准确的像素定位。最后,将两者相加,以实现语义信息和细节信息之间的平衡,并获得更准确的分割结果。ICM可以表示如下:
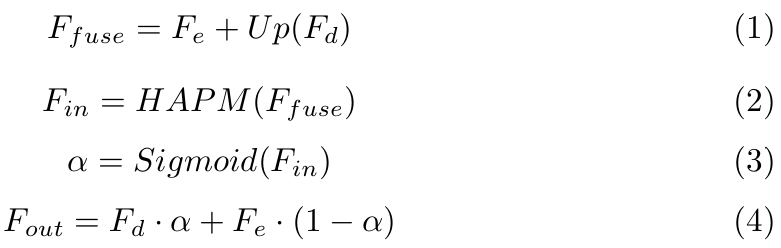
其中,\( F_e \) 是编码器提供的低级细节信息,\( F_d \) 是解码器提供的高级语义信息,Up表示上采样操作,Sigmoid表示激活函数。
2.4 Effective Aggregation Pyramid Pooling Module
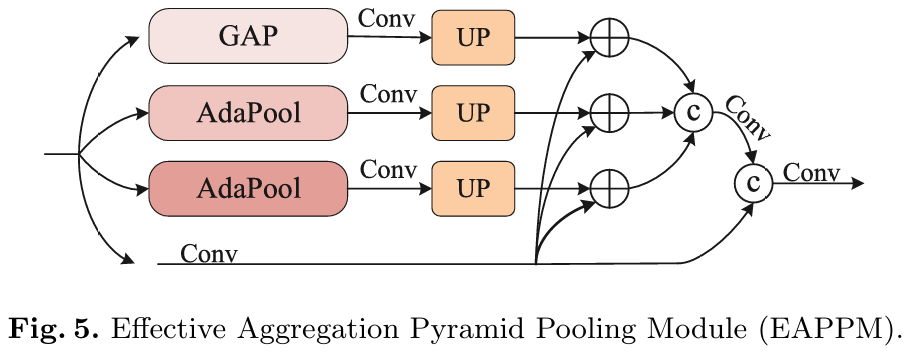
金字塔池化模块(Pyramid Pooling Module, PPM)通过在多个尺度上对特征图进行操作来捕捉全局信息,以获取广泛的上下文语义信息。深度聚合金字塔池化模块(Deep Aggregation Pyramid Pooling Module, DAPPM)通过在不同深度聚合池化层来增强PPM,但其众多的级联连接显著增加了计算成本,这与轻量级实时模型的目标相冲突。因此,我们设计了一个新的有效聚合金字塔池化模块(Effective Aggregate Pyramid Pooling Module, EAPPM),如图5所示,用于在特征提取后从局部到全局捕捉广泛的情境信息,提高分割精度的同时减少计算成本。
具体来说,EAPPM通过三个具有不同池化核大小的池化分支和一个1×1卷积分支来提取多尺度特征信息。并行的池化分支将特征图池化为1×1、2×2、4×4三种大小,然后它们分别在1×1卷积和上采样后直接加到卷积分支的结果上。我们使用连接(concatenation)和3×3卷积操作来融合三个池化分支的结果。接下来,我们使用连接和1×1卷积操作来融合四个分支的特征信息,并相应地调整特征图的通道数。值得注意的是,EAPPM的参数数量非常少,仅为0.67M,同时提高了分割精度,这与轻量级语义分割模型设计的标准非常一致。
实验
3.1 数据集
我们在两个流行的公开数据集——Cityscapes和CamVid上对我们的模型进行了评估。
Cityscapes是一个包含50个大型城市街道场景的数据集,涵盖了19个类别的密集像素注释。该数据集总共包含5000张高质量精细标注的图像,其中包括2975张训练图像、500张验证图像和1525张测试图像。这个数据集中图像的分辨率是1024×2048。
CamVid是另一个道路场景解析数据集,它包含了从视频序列中提取的701张标注图像,总共有11个类别的密集像素注释。其中,367张用于训练,101张用于验证,233张用于测试。这个数据集中图像的分辨率是720×960。
3.2 实施细节
我们的研究使用预训练的 RepVIT-M1.1 模型作为我们的骨干网络。我们的模型在 Cityscapes 和 CamVid 数据集上进行了 400 个训练周期。实验环境是单个 RTX3080 GPU,使用 PyTorch 1.13.1。训练期间的批量大小设置为 4。我们采用随机梯度下降(Stochastic Gradient Descent, SGD)作为优化方法,其中动量参数为 0.9,权重衰减为 1e-4。我们将初始学习率设置为 7e-3,并采用余弦退火(Cosine annealing)学习率调度策略。
在数据增强方面,我们对图像进行了一系列处理,包括随机缩放、扭曲、添加灰度条等,同时以一定概率应用随机翻转、高斯噪声干扰和旋转。为了减少计算量,对于 Cityscapes 数据集,我们将图像分辨率裁剪为 512×1024。
我们使用平均交并比(mean Intersection over Union, mIoU)、每秒帧数(Frames Per Second, FPS)和参数数量(Params)作为分割性能的评估指标。
3.3 消融实验
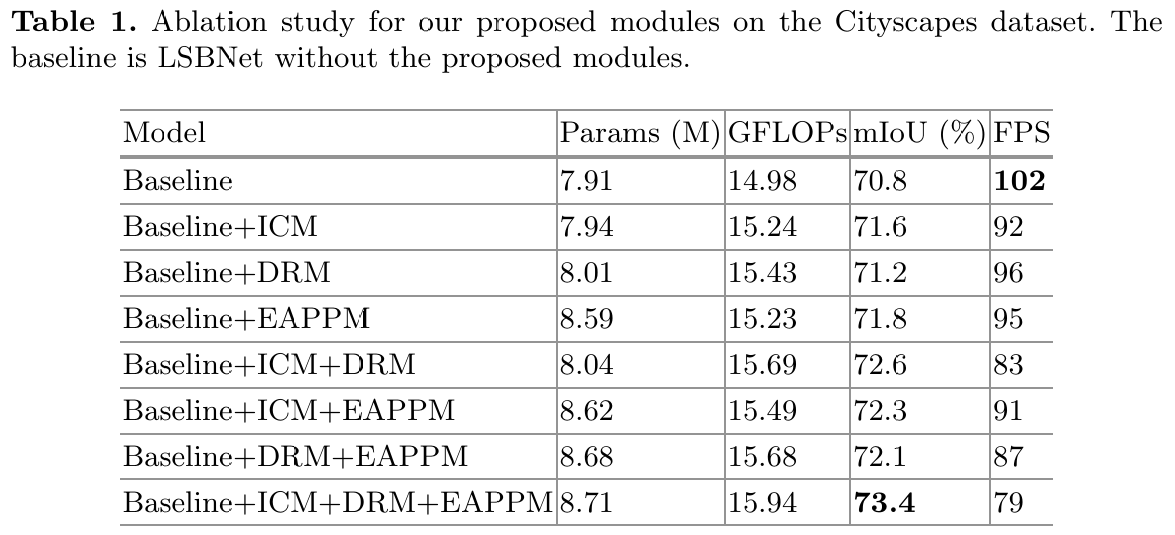
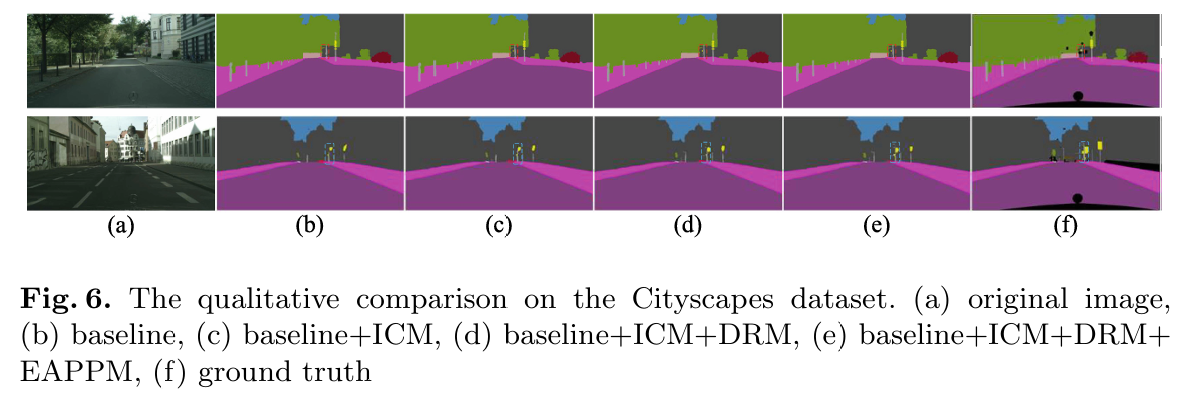
我们在 Cityscapes 数据集上进行了消融实验,以验证我们提出的模块对语义分割性能的有效性。这些实验采用了相同的实验设置。我们选择没有加入任何我们提出模块的 LSBNet 作为基线。表 1 展示了消融实验的定量结果。通过将不同的单一模块添加到基线中,揭示了每个模块的独立贡献,其中 EAPPM 对分割结果的影响最佳,且计算复杂度最低,而 ICM 的参数数量最少。通过将两种不同模块的组合添加到基线中,探索了模块之间的相互作用,其中 DRM 和 ICM 的组合表现最佳。图 6 提供了定性比较,可以看出在逐步引入 ICM、DRM 和 EAPPM 后,预测图像与真实标注的一致性越来越高。然而,由于复杂背景的干扰,一些非常小的目标没有被准确分割。总之,通过上述消融实验的设计与分析,我们可以系统地了解每个模块及其组合对语义分割模型性能的影响,从而为模型设计提供了坚实的理论依据和实验验证。
3.4 实验结果
1)Cityscapes 数据集的实验结果
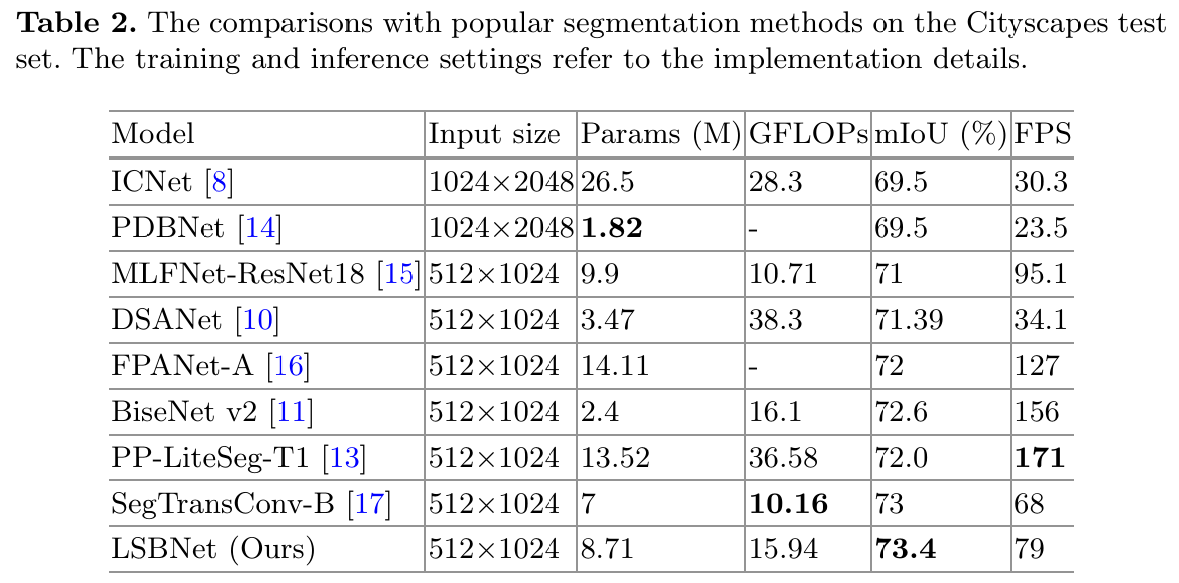
为了验证 LSBNet 的有效性,我们在 Cityscapes 测试集上将其与其他先进的轻量级实时分割方法进行了比较。表 2 展示了各种分割方法的结果。实验结果表明,我们的方法实现了令人印象深刻的分割精度,达到了 73.4% 的 mIoU(平均交并比),并且推理速度为 79 FPS,优于大多数其他方法。
值得注意的是,我们并没有通过增加参数数量来实现如此高的精度。实际上,我们的模型的参数数量甚至比某些方法还要少。与 MLFNet-ResNet18 相比,LSBNet 的参数数量更少,尽管 FPS 略低,但分割精度比 mIoU 高出 2.4%。尽管 BiseNet v2 的参数数量要少得多,但其 GFLOPs(十亿浮点运算次数)高于 LSBNet,这也证明了双分支结构的计算效率不如编码器-解码器结构。与 SegTransConv-B 相比,LSBNet 的参数数量略高,但 FPS 显著高出 11,分割精度也高出 0.4%。虽然 LSBNet 的速度不如 PP-LiteSeg 快,但它的参数数量更少,计算复杂度也低于 PP-LiteSeg。此外,LSBNet 的分割精度比 PP-LiteSeg 高出 1.4%。
这些实验表明,LSBNet 在确保高分割精度的同时保持了较高的推理速度,并在精度和速度之间取得了良好的平衡。
2) CamVid 数据集的实验结果
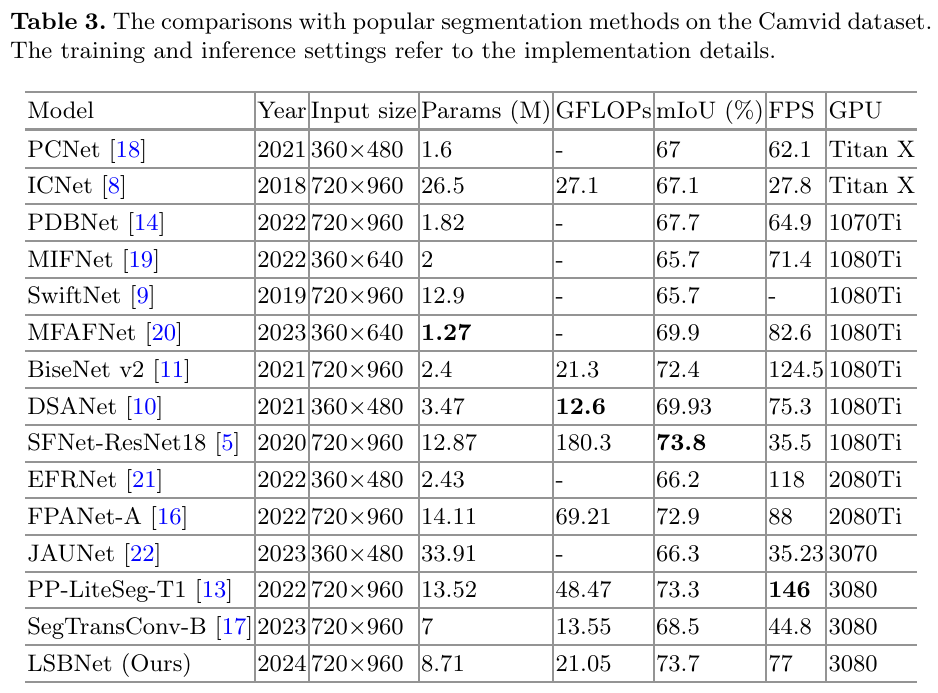
为了进一步验证 LSBNet 的性能,我们在 CamVid 数据集上进行了实验。表 3 展示了 LSBNet 以及一些先进的语义分割模型在该数据集上的结果,包括轻量级和非轻量级网络。尽管我们的模型的分割精度并非最高,但我们成功地在保持高精度的同时减少了参数数量和计算复杂度。
与 SFNet-ResNet18 相比,LSBNet 的 mIoU 仅低 0.1%,但参数数量更少,GFLOPs(计算量)约为其 1/9。在推理速度方面,LSBNet 超过了大多数模型,甚至比许多参数极少的模型还要快。LSBNet 的 FPS 仅落后于 MFAFNet、BiseNet v2、EFRNet 和 FPANet-A。然而,LSBNet 的 mIoU 比 MFAFNet 和 EFRNet 分别高出 3.8% 和 7.5%,且 LSBNet 的 GFLOPs 低于 BiseNet v2 和 FPANet-A。
与 PP-LiteSeg 相比,LSBNet 的参数数量和计算复杂度更低,分割精度更高,尽管推理速度略低于 PP-LiteSeg。
这些实验结果表明,LSBNet 具有出色的泛化能力和竞争力。
结论
在本研究中,我们提出了一种基于编码器-解码器结构的轻量级对称平衡网络,名为 LSBNet。该网络使用了三个关键模块:细节增强模块(Detail Reinforcement Module, DRM)、信息互补模块(Information Complementarity Module, ICM)和有效聚合金字塔池化模块(Efficient Aggregation Pyramid Pooling Module, EAPPM)。其中,DRM 在特征提取的多个阶段以较低成本进行细节特征增强;ICM 致力于补充高级语义信息中的低级细节信息;EAPPM 具备从局部到全局捕捉多尺度上下文信息的能力。实验结果表明,LSBNet 在两个具有挑战性的数据集 Cityscapes 和 CamVid 上均实现了令人满意的分割精度。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 32
32 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)