
Claude系列和Doubao Seed 1.6,为什么是“最能干活”的大模型?
不难发现,在评估维度评测的五大任务场景中,有一个场景的评分显现出较大的两级分化,那就是交互操作能力,透过热力图与雷达图可以清楚看到,该能力甚至直接影响了最后的评分排比,交互操作类任务仅Claude系列和Doubao Seed 1.6经受住了挑战,而这三个模型分别位列综合评分前三。结合Auto-GPT 与 Agent 架构中对“操作环境”的描述以及AiPy、Autogen等框架中的衡量指标来看,交互
最近,AiPy官方发布了《大模型适配度测评第二期报告》。本次报告中我们能够看到,Claude Opus 4这匹新晋黑马强势突围,位居榜首;Claude Sonnet 4紧随其后,评分领先;国产大模型Doubao Seed 1.6表现依旧亮眼。
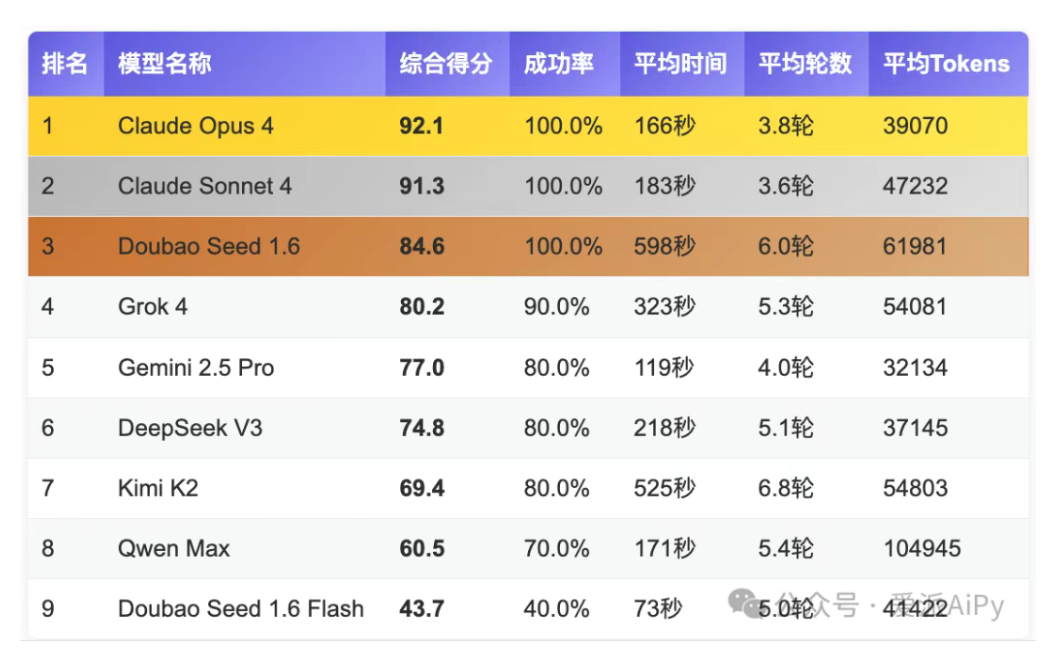
本次综合评分的评估在过往测评维度上新增“执行轮数”与“Token消耗成本”两个维度,并应用于系统分析、可视化分析、数据处理、交互操作和信息获取五大核心应用场景。
不难发现,在评估维度评测的五大任务场景中,有一个场景的评分显现出较大的两级分化,那就是交互操作能力,透过热力图与雷达图可以清楚看到,该能力甚至直接影响了最后的评分排比,交互操作类任务仅Claude系列和Doubao Seed 1.6经受住了挑战,而这三个模型分别位列综合评分前三。
这是否意味着,衡量一个AI的价值天花板,正在发生变化?
01
什么是智能体的交互操作能力?
结合Auto-GPT 与 Agent 架构中对“操作环境”的描述以及AiPy、Autogen等框架中的衡量指标来看,交互操作能力指的是:AI 在理解用户意图后,能否代替用户完整并实际地执行一系列操作。如执行从打开文件、编写代码、到调用软件或终端完成任务并返回结果的全过程。
比如用户给出指令“把一份 Excel 表格里的“销售数据”汇总,并生成一个可视化图表”。
没有交互操作能力的智能体会回答:

它只是告诉你该怎么做,不能帮你真正做。
而有交互操作能力的本地智能体会回答:

它会自动打开文件、读取数据、生成图表、输出结论,全流程代劳,无需用户点击操作或切换软件。
这个能力,本质是让 AI 从语言助手变成行动者,它能像一个真实的虚拟助理那样,替你动手干活,而不仅是出主意。
02
Claude & 豆包,为什么能“抗事儿”?
Claude 背后的优势,是 Anthropic 对 Agent 架构的持续投入,包括Auto100等基准测试、自动行动规划等。这使其能够实现工具并行调用与MCP协议集成。
一方面,它支持同时调用多个API工具,如数据库查询+网络搜索+文件处理;另一方面它通过标准化协议连接外部工具,如GitHub、Slack、Canva,实现“一键接入”工作流,无需手动配置集成。
而DoubaoSeed 1.6则兼具了原生多模态思考和图形界面操作的能力。其能够支撑底层融合文本、图像、音频等多模态信息的联合推理。例如,上传商品图片后,语音提问“找出所有红色鞋子并对比评价”,模型可同步解析视觉内容并检索知识库生成报告。
此外,它能够基于视觉定位技术精准识别UI元素,实现跨应用自动化。如从Excel读取数据→登录CRM系统录入→生成邮件报告,全程无需人工干预。
以上可能说明了一个趋势:交互操作能力,正在成为大模型实现突破的关键入口。
03
打造“能动手”的AI产品,要具备什么?
仅有强模型是不够的。可以观察到,像 Claude 和豆包这样的“动手型”智能体,背后还有一个共同点:
它们拥有稳定、开放、细粒度的能力调度机制。
在中国,目前一些基于本地部署能力 + 自定义工作流 + 多模态输入 + 插件生态的产品,开始形成这样的趋势。
比如实施测评的本地智能体AiPy ,就可以完成自动化文档分析、图谱生成、文件调用等任务,已展现出“行动者”的声势。
可以想见,智能体时代,拼的不再是谁“说得好”,而是谁“干得快、干得对”。
这次测评给我们提了一个醒:
未来AI能不能落地,或许核心更偏向于“操作力”而不是“想象力”。
而接下来的关键,或许是谁能真正让这些“能动手”的能力,普及到每个用户的桌面上。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)