
python中使用xpath爬取豆瓣电影剧情简介遇到不同标签的处理方法
爬取豆瓣电影剧情简介遇到不同xpath路径的处理方法问题描述解决方法问题描述在爬取豆瓣top250电影详细信息的时候,会遇到个别电影信息下的xpath路径不一样。这里我举例为:top250电影的剧情简介下面是两个不同情况的例子:1.肖申克的救赎:这里的xpath下的路径为.//*[@id="link-report"]/span[1]/span/text()[1]2.霸王别姬:这里的xpath下的路
问题描述
在爬取豆瓣top250电影详细信息的时候,会遇到个别电影信息下的xpath标签不一样。
这里我举例为:top250电影的剧情简介
下面是两个不同情况的例子:
1.肖申克的救赎: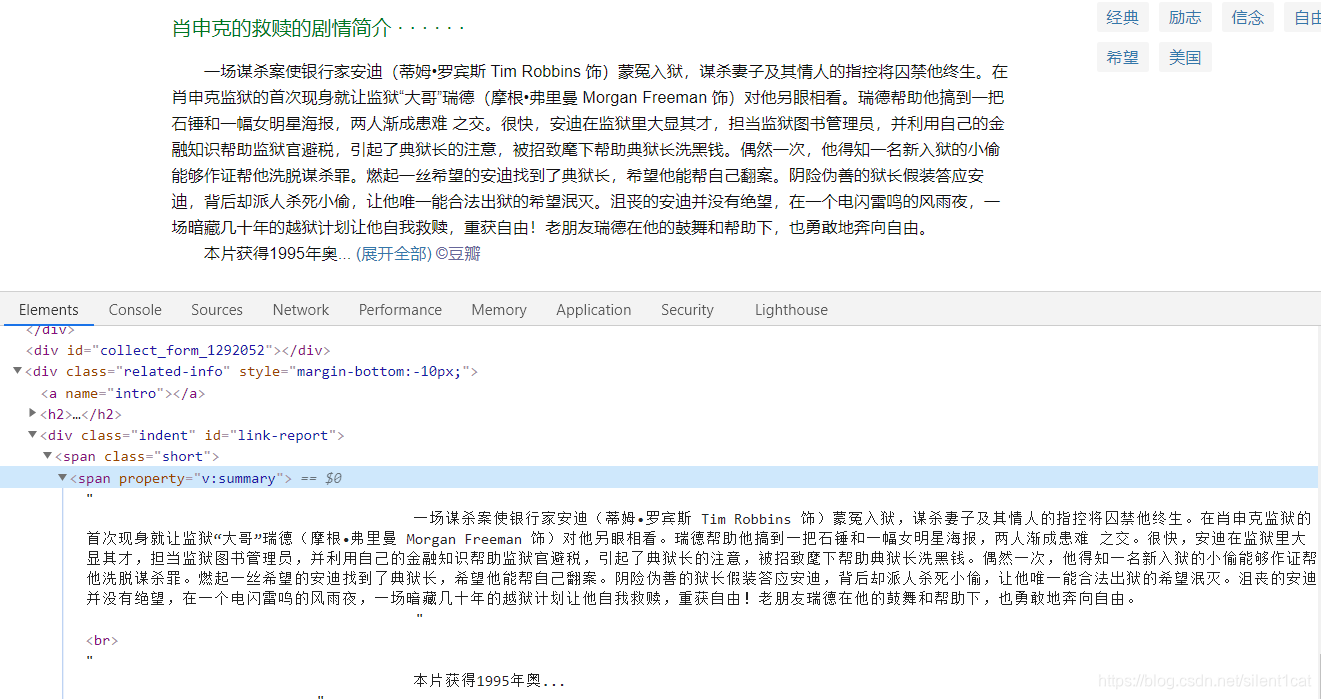
这里的xpath下的标签为.//*[@id="link-report"]/span[1]/span/text()[1]
2.霸王别姬: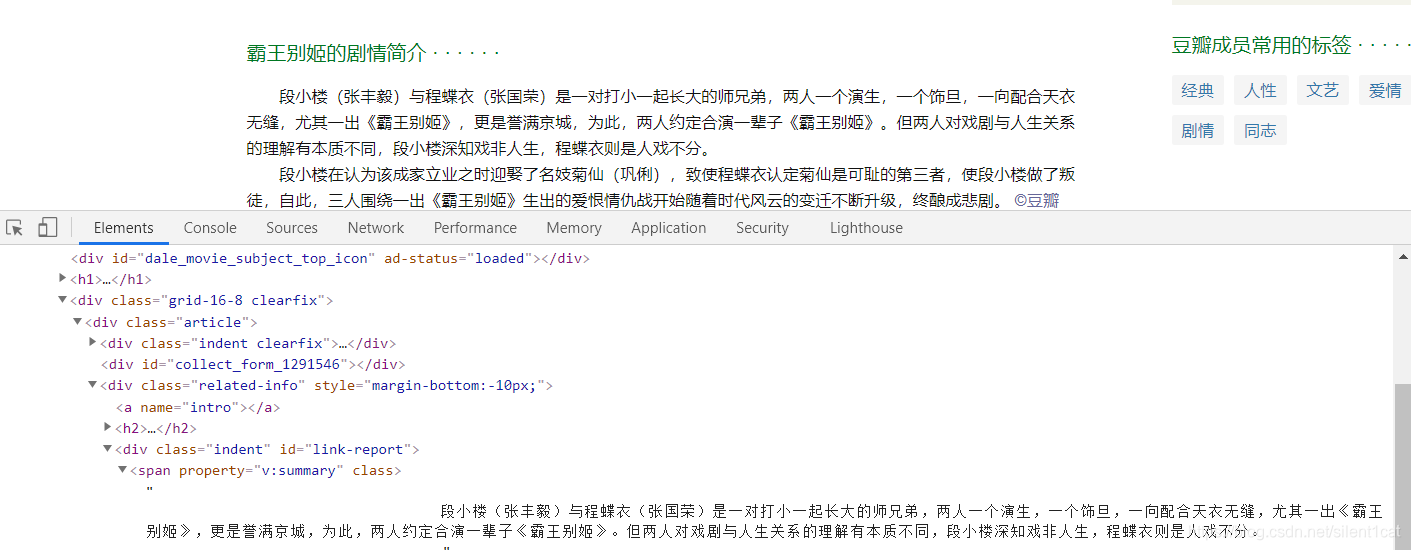
这里的xpath下的标签.//*[@id="link-report"]/span[1]/text()[1]
那么在循环爬取剧情简介的时候,就会有出现部分电影的简介无法爬取的情况。
解决方法
通过在抓包工具下查找可以发现和肖申克的救赎的简介具有相同的xpath标签的电影,简介都存在于另一个位置.//*[@id="link-report"]//span[@class=all hidden]/text()[1]。
那么我们可以通过一个判断Introduction = html.xpath('.//*[@id="link-report"]/span[2]/text()[1]')中的Introduction中的列表长度,如果为0,则执行Introduction = html.xpath('.//*[@id="link-report"]/span[1]/text()[1]')
具体代码
Introduction = html.xpath('.//*[@id="link-report"]/span[2]/text()[1]')
if len(Introduction) == 0:
Introduction = html.xpath('.//*[@id="link-report"]/span[1]/text()[1]')
这是本人第一篇csdn,如有写的不好的地方或者有更好的方法,欢迎评论留言。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)