
TextCNN论文解读--A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks f
最近CNN模型在句子分类任务中表现的很不错,但是要配置好了才行,包括 模型的结构和超参数。因为一层的CNN模型比较简单,我们拿它来进行研究模型的设计。
最近CNN模型在句子分类任务中表现的很不错,但是要配置好了才行,包括 模型的结构和超参数。因为一层的CNN模型比较简单,我们拿它来进行研究模型的设计。
一、引言
CNN模型 要实现 strong的结果,不需要很复杂的结构,比如Kim,一层CNN就实现了 stat-of-the-art 的效果。不幸的是,需要指定exact 的模型配置,这些参数配置包括:输入向量表征、卷积核大小、特征maps的数量、激活函数、池化策略、正则化(dropout / L2).
因为参数估计 巨大,所有tune 所有的参数是不可能的。先进的参数search 方法也有诸多限制和未落地,我们只能仿照前人,从经验上对参数进行identify,最后报道了在这些配置上的精准率和AUC 的平均值和范围。
二、知识背景
我们的目的是解决:实践中,一个人面临这好几个模型结构和各种各样的超参数。
2.1 CNN 结构
词向量维度d,句子长度为s:
(1)因为text数据内在是一个序列结构,所以我们使用的卷积核宽度为d。卷积核的高度h,我们可以简单多取几组值。
(2)因为特征map 是一个 句长和卷积核尺寸 的函数(含有激活函数了),会随着h的不同而变化,所以一个池化层被用来得到固定长度的向量。
最后,每个卷积核的输出们被concatenated一个固定长度的特征向量,它接着通过一个softmax层产生分类结果。
(3)在softmax层,one可以添加 dropout 或 L2 等正则化手段。
可被评估的参数包括:卷积核、激活函数的bias、softmax
三、数据
这些数据是 imbalanced 的,因此 训练前,我们下采样了 负样本 。为此,我们还使用了AUC,而不是精确率。
四、Baseline模型
为了作为对比,我们首先report 了svm的表现:
(1)平均词向量 + RBF-kernel SVM :
(2)uni-gram、bi-gram、词向量 + 线性核SVM:
我们采用了10折交叉验证,看到 融合词向量确实 可以提高 result。
4.1 baseline 配置
10折交叉验证、100份重复CV实验、每一份配置我们重复10次、non-static词向量
4.2 输入词向量的效果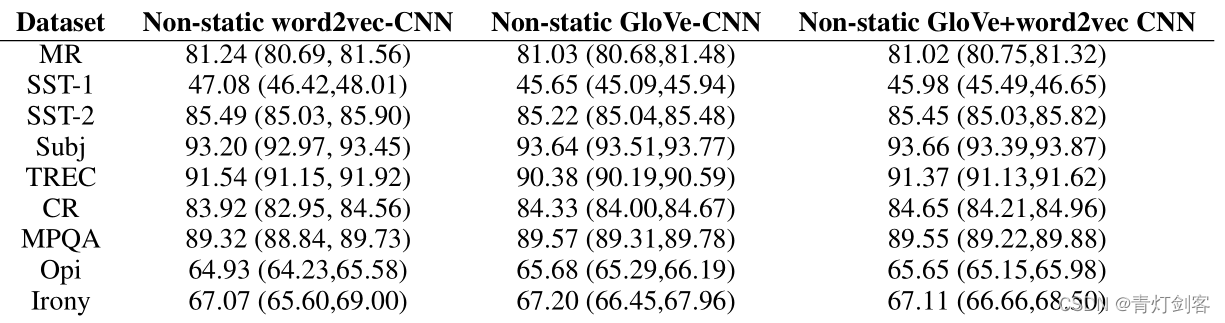
word2vec 和glove 各有所长,面对新任务时应该多尝试;
简单的将word2vec和glove 合并起来的方式,并不起什么作用;
one-hot vectors 对比embedding,表现的很差,可能是由于太稀疏和句子太简单而不能学到足够信息。
总结:embedding 最棒
4.3 卷积核尺寸大小的效果
先找到 单尺寸核 效果最好的,然后围绕这个卷积核尺寸 选择 大小相近的核大小构成的组合尺寸,包括 多种核尺寸、重复一个尺寸。
4.4 feature maps 数量的影响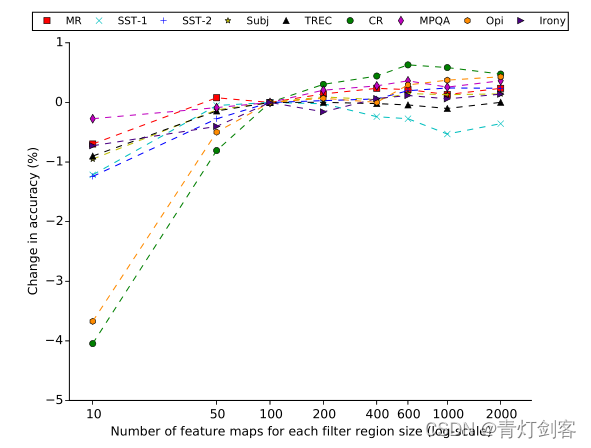
数据不同,每套卷积核尺寸的最佳 maps数量也不同。但是图中显示,当maps数据超过600的时候,收益很小且费时费力。
4.5 激活函数的影响
对比准备:线性激活函数 Iden;non-static 的CNN。激活函数的认识见激活函数介绍1、激活函数介绍2
结果显示:8/9的数据中,表现最好的时 iden、ReLU和tanh中的一个。
结果分析:ReLU表现好,大概是因为它的zero centering property (com-
pared to Sigmoid);ReLU是因为 它有一段 非饱和区间(和sigmoid相比),收敛快(导数是个常数);有意思的是Iden也能起到不错的作用,说明在某些数据中,线性转换有能力抓住 词向量和标签直接的相互关系,但当隐藏层有多个时,iden就不行了。
总结:应该选用 ReLU和tanh,或者Iden。
4.6 池化策略的影响
研究对象:池化策略、池化区域尺寸
发现:1-max 池化层效果最好,比k-max效果好;平均池化,效果很菜,而且耗时严重。
原因分析:上下文的位置不重要,某些n-gram相对来说更有可预测性。
4.7 正则化效果
我们在倒数第二层添加 dropout和L2正则。
实验表示:L2几乎没提高表现,dropout也是如此。
原因分析:我们的CNN只有一层,参数太少。
建议:设置 dropout为【0.0,0.5】,L2参数大一些。当featrues maps比较多时,提升 dropout 是有帮助的。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)