
从图像中提取结构化车辆数据
我们的流水线链由四个组件组成:图像加载组件、提示生成组件、MLLM 调用组件以及用于将 LLM 的输出解析为结构化格式的解析器组件。想象一下,在一个检查点,有一个摄像头监控车辆,你的任务是记录复杂的车辆细节——类型、车牌号、品牌、型号和颜色。这项任务极具挑战性——传统的计算机视觉方法难以处理各种模式,而监督式深度学习则需要集成多个专门的模型、大量的标记数据和繁琐的训练。在本教程中,我们将构建一个车
介绍
想象一下,在一个检查点,有一个摄像头监控车辆,你的任务是记录复杂的车辆细节——类型、车牌号、品牌、型号和颜色。这项任务极具挑战性——传统的计算机视觉方法难以处理各种模式,而监督式深度学习则需要集成多个专门的模型、大量的标记数据和繁琐的训练。预训练多模态线性学习模型(MLLM) 领域的最新进展提供了快速灵活的解决方案,但要使其适应结构化输出则需要进行一些调整。
在本教程中,我们将构建一个车辆文档系统,从车辆图像中提取关键细节。这些细节将以结构化格式提取,以便后续后续使用。我们将使用OpenAI的 GPT-4 提取数据,使用Pydantic构建输出结构,并使用LangChain编排流程。最终,您将拥有一个实用的流程,用于将原始图像转换为结构化、可操作的数据。
本教程面向计算机视觉从业者、数据科学家以及有兴趣使用 LLM 执行视觉任务的开发者。完整代码包含在易于使用的 Colab 笔记本中,方便您逐步学习。
技术堆栈
- GPT-4 视觉模型: GPT-4 是由 OpenAI 开发的多模态模型,能够理解文本和图像 [1]。该模型基于海量多模态数据进行训练,能够以零样本(zero-shot)的方式泛化至各种任务,通常无需微调。虽然 GPT-4 的具体架构和大小尚未公开,但其性能在业内处于领先地位。您可以通过 OpenAI API 以付费代币的方式获取 GPT-4。在本教程中,我们将使用 GPT-4 来验证其出色的零样本性能,但您也可以根据自身需求,轻松地将其与其他模型进行替换。
- LangChain:我们将使用 LangChain 来构建管道。LangChain 是一个强大的框架,可以简化复杂的工作流程,确保代码的一致性,并方便在 LLM 模型之间切换 [2]。在我们的案例中,LangChain 将帮助我们链接加载图像、生成提示、调用 GPT 模型以及将输出解析为结构化数据的各个步骤。
- Pydantic: Pydantic 是一个强大的 Python 数据验证库 [3]。我们将使用 Pydantic 定义 GPT-4 模型预期输出的结构。这将帮助我们确保输出的一致性和易用性。
数据集概述
为了模拟车辆检查站的数据,我们将使用来自 Kaggle 数据集“车牌号”[4] 的车辆图像样本。此数据集遵循Apache 2.0 许可证。您可以查看以下图片:
 来自“车牌号”Kaggle 数据集的车辆图像
来自“车牌号”Kaggle 数据集的车辆图像
让我们编码吧!
在深入实际实施之前,我们需要做好一些准备:
- 生成 OpenAI API 密钥— OpenAI API 是一项付费服务。要使用该 API,您需要注册一个 OpenAI 帐户并生成一个与付费计划关联的 API 密钥。
- 配置您的 OpenAI — 在 Colab 中,您可以将 API 密钥安全地存储为环境变量(Secret),该变量位于左侧边栏 (🔑)。创建一个名为 的 Secret
OPENAI_API_KEY,将您的 API 密钥粘贴到value字段中,然后启用“笔记本访问”。 - 安装并导入所需的库。
管道架构
在此实现中,我们将使用 LangChain 的chain抽象将流水线中的一系列步骤连接在一起。我们的流水线链由四个组件组成:图像加载组件、提示生成组件、MLLM 调用组件以及用于将 LLM 的输出解析为结构化格式的解析器组件。链中每个步骤的输入和输出通常以字典的形式组织,其中键代表参数名称,值代表实际数据。让我们看看它是如何工作的。
图片加载组件
该链的第一步是加载图像并将其转换为 base64 编码,因为 GPT-4 要求图像采用基于文本(base64)的格式。
def image_encoding ( inputs ):
"""加载图像并将其转换为 base64 编码"""
with open (inputs[ "image_path" ], "rb" ) as image_file:
image_base64 = base64.b64encode(image_file.read()).decode( "utf-8" )
return { "image" : image_base64}
参数inputs是包含图片路径的字典,输出是包含based64编码图片的字典。
使用 Pydantic 定义输出结构
Vehicle我们首先使用继承自 Pydantic 的 的类来指定所需的输出结构BaseModel。每个字段(例如 、Type、Licence、Make、Model)Color都使用 定义Field,这使我们能够:
- 指定输出数据类型(例如
str,,,,等)int。list - 提供法学硕士 (LLM) 领域的描述。
- 包括指导法学硕士 (LLM) 的示例。
每个中的(省略号...)Field表示该字段是必填的,不能省略。
该类的外观如下:
类 车辆(BaseModel):
类型:str = Field(
...,
examples = [ “Car”,“Truck”,“Motorcycle”,'Bus' ],
description = “返回车辆的类型。”,
)
许可证:str = Field(
...,
description = “返回车辆的车牌号。”,
)
制造商:str = Field(
...,
examples = [ “Toyota”,“Honda”,“Ford”,“Suzuki” ],
description = “返回车辆的制造商。”,
)
型号:str = Field(
...,
examples = [ “Corolla”,“Civic”,“F-150” ],
description = “返回车辆的型号。”,
)
颜色:str = Field(
...,
example = [ “Red”,“Blue”,“Black”,“White” ],
description = “返回车辆的颜色。”,
)
解析器组件
为了确保 LLM 输出符合预期格式,我们使用类JsonOutputParser进行初始化Vehicle。该解析器会验证输出是否符合我们定义的结构,包括字段、类型和约束。如果输出不符合预期格式,解析器将引发验证错误。
该parser.get_format_instructions()方法根据类中的架构生成一串指令Vehicle。这些指令将成为提示的一部分,并将指导模型如何构建其输出以便进行解析。您可以instructions 在 Colab 笔记本中查看变量内容。
解析器 = JsonOutputParser(pydantic_object = Vehicle)
指令 = 解析器.get_format_instructions()
提示生成组件
我们流程中的下一个组件是构建提示。提示由系统提示和人工提示组成:
- 系统提示:在中定义
SystemMessage,我们用它来建立AI的角色。 - 人性化提示:定义在
HumanMessage并由3部分组成:1)任务描述2)我们从解析器中提取的格式指令,以及3)base64格式的图像,以及图像质量detail参数。
该detail参数控制模型如何处理图像并生成其文本理解 [5]。它有三个选项:low,high或auto:
low:该模型处理低分辨率(512 x 512 像素)的图像版本,并使用 85 个令牌的预算来表示该图像。这使得 API 能够更快地返回响应并消耗更少的输入令牌。high:该模型首先分析低分辨率图像(85 个标记),然后使用每 512 x 512px 图块 170 个标记创建详细裁剪。auto:默认设置,其中low或high设置由图像大小自动选择。
对于我们的设置,low分辨率已经足够,但其他应用程序可能会受益于high分辨率选项。
以下是提示创建步骤的实现:
@chain
def prompt ( inputs ):
"""创建提示"""
prompt = [
SystemMessage(content= """您是AI助手,其工作是检查图像并从图像中提供所需的信息。如果所需字段不清晰或检测不准确,则返回此字段的none。不要尝试猜测。""" ),
HumanMessage(
content=[
{ "type" : "text" , "text" : """检查主要车辆类型、品牌、型号、车牌号和颜色。""" },
{ "type" : "text" , "text" : instructions},
{ "type" : "image_url" , "image_url" : { "url" : f"data:image/jpeg;base64, {inputs[ 'image' ]} " , "detail" : "low" , }}]
)
]
return prompt
@chain 装饰器用于指示此函数是 LangChain 管道的一部分,其中此函数的结果可以传递给工作流中的步骤。
MLLM 组件
管道中的下一步是使用该MLLM_response函数调用 MLLM 从图像中生成信息。
首先,我们使用 初始化多模态 GTP-4 模型ChatOpenAI,其配置如下:
model指定 GPT-4 模型的确切版本。temperature设置为 0.0 以确保确定性的响应。max_token将输出的最大长度限制为 1024 个标记。
接下来,我们使用组装好的输入(包括图像和提示)调用 GPT-4 模型model.invoke。该模型处理输入并返回图像中的信息。
@chain
def MLLM_response ( inputs ):
"""调用 GPT 模型从图像中提取信息"""
model: ChatOpenAI = ChatOpenAI(
model= "gpt-4o-2024-08-06" ,
temperature= 0.0 ,
max_tokens= 1024 ,
)
output = model.invoke(inputs)
return output.content
构建 管道链
定义完所有组件后,我们将它们与|运算符连接起来,构建管道链。该运算符将一个步骤的输出与下一个步骤的输入按顺序连接起来,从而创建流畅的工作流程。
单幅图像推理
现在到了最有趣的部分!我们可以通过将包含图像路径的字典传递给该pipeline.invoke方法来从车辆图像中提取信息。具体操作如下:
输出 = 管道.invoke({ “image_path”:f “ {img_path} ” })
输出是包含车辆详细信息的字典:
 左图:输入图像。右图:输出字典。
左图:输入图像。右图:输出字典。
为了进一步与数据库或 API 响应集成,我们可以轻松地将输出字典转换为 JSON:
json_output = json.dumps(输出)
对一批图像进行推断
LangChain 允许您同时处理多张图片,从而简化了批量推理。为此,您需要传递一个包含图片路径的字典列表,并使用以下命令调用管道pipeline.batch:
# 准备一个包含图像路径的字典列表:
batch_input = [{ "image_path" : path} for path in image_paths]
# 执行批量推理:
output = pipeline.batch(batch_input)
生成的输出字典可以轻松转换为表格数据,例如 Pandas DataFrame:
df = pd.DataFrame(输出)
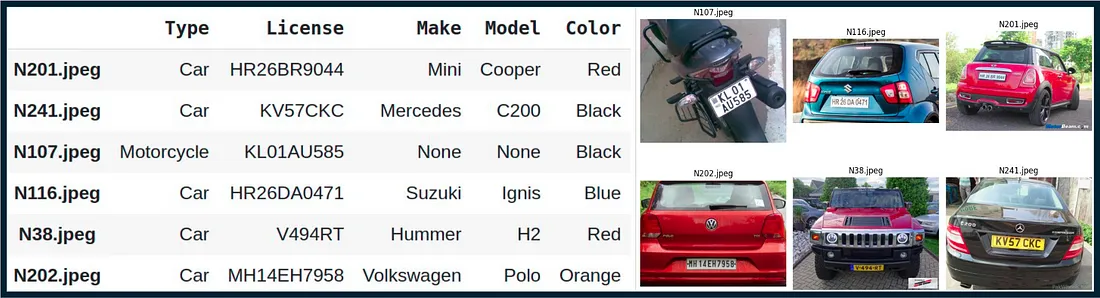
左图:以 DataFrame 形式输出的车辆数据。右图:输入图像。
我们看到,GPT-4 模型正确识别了车辆类型、车牌、品牌、型号和颜色,提供了准确且结构化的信息。对于细节不清晰的车辆(例如摩托车图像),它会按照提示返回“无”。
总结
在本教程中,我们学习了如何从图像中提取结构化数据,并利用这些数据构建车辆文档系统。同样的原理也可以应用于其他各种应用。我们使用了 GPT-4 模型,该模型在识别车辆细节方面表现出色。然而,我们基于 LangChain 的实现非常灵活,可以轻松与其他 MLLM 模型集成。虽然我们取得了良好的结果,但务必注意基于 LLM 的模型可能出现的潜在分配问题。
从业者在实施类似系统时,也应考虑潜在的隐私和安全风险。虽然 OpenAI API 平台中的数据默认不用于训练模型 [6],但处理敏感数据需要遵守适当的规定。
完整代码+资料包↓(或看我个人简介处)


GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 31
31 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)