
python实现LDA主题建模
本文详细介绍了如何使用Python实现LDA主题建模。LDA是一种用于主题建模的概率图模型,其基本思想是:每个文档是由一组主题混合而成的,每个主题又由一组词汇构成,而LDA试图找到最佳的主题和词汇组合,以解释给定的文本数据。
前言
本文详细介绍了如何使用Python实现LDA主题建模。LDA是一种用于主题建模的概率图模型,其基本思想是:每个文档是由一组主题混合而成的,每个主题又由一组词汇构成,而LDA试图找到最佳的主题和词汇组合,以解释给定的文本数据。
具体操作步骤
一、环境配置与数据准备
1.1 安装依赖库
首先,确保已经安装了所需的库:
pip install pandas matplotlib gensim scikit-learn jieba1.2 导入模块
接着,导入我们所需要用到的库及模块:
import os # 导入 os 模块,用于与操作系统进行交互
import pandas as pd # 导入 pandas 库,用于数据处理和分析
import matplotlib.pyplot as plt # 导入 matplotlib 库的 pyplot 模块,用于绘制图表
from gensim.corpora import Dictionary # 从 gensim 库的 corpora 模块中导入 Dictionary 类,用于创建词典
from gensim.models import LdaModel # 从 gensim 库的 models 模块中导入 LdaModel 类,用于实现潜在狄利克雷分配(LDA)模型
from gensim.models.coherencemodel import CoherenceModel # 从 gensim 库的 models 模块中导入 CoherenceModel 类,用于计算主题模型的一致性
import jieba # 导入 jieba 库,用于中文分词1.3 设置Matplotlib参数
设置Matplotlib参数,以便在绘制图像时能够正确显示中文字符,解决负号显示问题:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题1.4 加载停用词表
with open('cn_stopwords.txt', 'r', encoding='utf-8') as f:
stop_words = set(f.read().splitlines()) # 读取停用词文件并转换为集合二、数据加载与处理
2.1 文本预处理
由于存在一些纯数字的无效评论,因此会先将这类评论筛掉,然后再使用jieba进行中文分词,并通过停用词表进行去停用词操作,最后将单个字评论以及空评论数据过滤,因为这些数据并无意义,单个字无法表达含义。
def preprocess_text(text):
if not isinstance(text, str): # 检查输入是否为字符串
return [] # 如果不是字符串,返回空列表
words = list(jieba.cut(text)) # 使用jieba进行分词
filtered_words = [word for word in words if word not in stop_words and len(word) > 1] # 过滤掉停用词和长度小于等于1的单词
return filtered_words2.2 计算不同主题数量下的Coherence值
在应用LDA模型之前,我们需要确定合适的主题数量,这里我们选择一致性Coherence指标来进行衡量,一致性能够评估主题模型的语义质量,值越高,说明主题内部的词语在语义上越相关,反映出主题的可解释性越强。
def compute_coherence_values(dictionary, corpus, texts, limit=20, start=1, step=1):
coherence_values = [] # 初始化Coherence值列表
for num_topics in range(start, limit + 1, step): # 遍历不同的主题数量
model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=num_topics, random_state=42, passes=10) # 训练LDA模型
coherencemodel = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v') # 计算Coherence模型
coherence_values.append(coherencemodel.get_coherence()) # 获取并存储Coherence值
return coherence_values2.3 绘制主题数量与Coherence得分的关系图
使用计算得到的Coherence值以及对应的主题数,绘制它们之间的关系图,从而找到最佳主题数。
def plot_graph(coherence_values, title, output_folder):
x = range(1, len(coherence_values) + 1) # X轴表示主题数量
plt.figure() # 创建一个新的图形
plt.plot(x, coherence_values, marker='o') # 绘制Coherence值曲线
plt.xlabel("Num Topics") # 设置X轴标签
plt.ylabel("Coherence Score") # 设置Y轴标签
plt.title(title) # 设置图形标题
output_path = os.path.join(output_folder, f'{title.replace(" ", "_")}.png') # 构建输出文件路径
plt.savefig(output_path) # 保存图形
plt.close() # 关闭图形
print(f'Saved coherence plot for {title} to {output_path}') # 打印保存信息图像如下所示,横坐标为主题数,纵坐标为对应的Coherence得分。在图像中,寻找最高拐点,该拐点对应的主题数量即为最佳主题数量。原因是在这个主题数量下,一致性值达到较高水平,若继续增加主题数量,对一致性的提升效果开始减弱。选择这样的主题数量,既能保持模型性能,又能避免模型过于复杂,同时主题具有较好的可解释性。
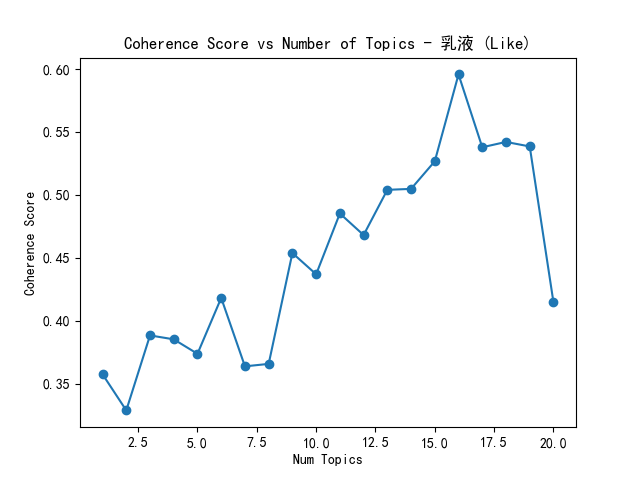
2.4 数据处理及生成Coherence图
在该函数中,首先对评论数据进行基本的去重和去缺失值操作,接着调用preprocess_text()进行分词、去停用词、去短词等进一步的数据处理操作,然后再使用tolist()函数提取预处理后的评论转换为 Python 列表;使用Dictionary()函数创建一个词典,将每个唯一的词映射到一个整数 ID;使用doc2bow()函数将每个文档转换为稀疏向量表示,其中每个元素是一个元组 (word_id, count),表示词的 ID 及其在文档中的出现次数,从而构建LDA模型所需的语料库。接着计算不同主题数量下的Coherence值,并绘制主题数量与Coherence得分的关系图,帮助确定最佳主题数。(这里先对整体评论进行上述操作,然后再分别对不同类别商品评论进行上述操作)
def process_data(df, sentiment, output_folder):
df.dropna(subset=['comment'], inplace=True) # 去除评论列中的缺失值
df.drop_duplicates(subset=['comment'], inplace=True) # 去除评论列中的重复项
df['comment_cleaned'] = df['comment'].apply(preprocess_text) # 对评论进行预处理
texts = df['comment_cleaned'].tolist() # 提取预处理后的评论
dictionary = Dictionary(texts) # 创建字典
corpus = [dictionary.doc2bow(text) for text in texts] # 创建语料库
# 计算Coherence值并绘图
coherence_values = compute_coherence_values(dictionary, corpus, texts)
plot_graph(coherence_values, f"Coherence Score vs Number of Topics - {sentiment}", output_folder)
# 对每个类别重复上述过程
categories = df['catagory'].unique() # 获取所有类别
for cat in categories:
cat_texts = df[df['catagory'] == cat]['comment_cleaned'].tolist() # 获取某一类别的评论
cat_dictionary = Dictionary(cat_texts) # 创建该类别的字典
cat_corpus = [cat_dictionary.doc2bow(text) for text in cat_texts] # 创建该类别的语料库
cat_coherence_values = compute_coherence_values(cat_dictionary, cat_corpus, cat_texts)
plot_graph(cat_coherence_values, f"Coherence Score vs Number of Topics - {cat} ({sentiment})", output_folder)
# 保存预处理后的数据到Excel文件
preprocessed_output_path = os.path.join(output_folder, f'preprocessed_{sentiment}.xlsx')
df.to_excel(preprocessed_output_path, index=False)
print(f'Saved preprocessed data for {sentiment} to {preprocessed_output_path}')预处理后的数据保存到coherence_plots文件夹中。
2.5 主程序
在主程序中,首先定义输入和输出路径,若输出目录不存在,则创建输出目录。接着分别读取需要进行主题建模的两类情感类别评论数据,然后分别调用数据处理及生成Coherence图的函数,进行后续操作。
if __name__ == "__main__":
# 文件路径和输出文件夹
file_path = "韩束sentiment.xlsx"
output_folder = 'coherence_plots'
os.makedirs(output_folder, exist_ok=True) # 创建输出文件夹(如果不存在)
# 读取Excel文件
like_df = pd.read_excel(file_path, sheet_name='特别喜欢')
dislike_df = pd.read_excel(file_path, sheet_name='不喜欢')
# 处理“特别喜欢”和“不喜欢”数据
process_data(like_df, 'Like', output_folder)
process_data(dislike_df, 'Dislike', output_folder)三、提取主题及可视化
3.1 安装并导入依赖库
首先,确保已经安装了所需的库:
pip install pandas gensim pyLDAvis然后导入所需要的库及模块:
import pandas as pd # 导入pandas库用于数据处理
from gensim import corpora, models # 导入gensim库中的corpora和models模块用于主题建模
import pyLDAvis # 导入pyLDAvis库用于主题模型的可视化
import pyLDAvis.gensim_models as gensimvis # 导入pyLDAvis.gensim_models模块以支持gensim模型3.2 定义最佳主题数
根据前面绘制的主题数量与Coherence得分关系图得到的最佳主题数。
# 定义每个情感评论对应的最佳主题数量(整体)
topics_per_sentiment_overall = {
'特别喜欢': 15 # 对于“特别喜欢”情感,整体使用15个主题
}
# 定义每个情感评论在不同类别中的最佳主题数量
topics_per_sentiment_category = {
'特别喜欢': {'洁面': 17, '精华水': 12, '精华液': 10, '乳液': 16} # 对于“特别喜欢”情感,在不同类别中使用的主题数量
}3.3 读取Excel数据
在前面的操作中,预处理后的数据保存到了coherence_plots文件夹中,这里需要把路径替换为文件夹中的Excel路径。(本文只对特别喜欢类别的评论数据进行了主题提取)
# Excel文件路径
excel_file_path = r"D:\xxx\xxx\coherence_plots\preprocessed_Like.xlsx"
# 创建一个空的DataFrame列表用于后续合并
dfs_for_excel = []
# 读取Excel文件中的特定工作表
df = pd.read_excel(excel_file_path)3.4 comment_cleaned字段处理
comment_cleaned字段记录了分词等预处理后的评论数据,需要先转换成单词列表:
def split_to_tokens(text):
if isinstance(text, str): # 检查输入是否为字符串
# 去掉方括号和引号
text = text.strip('[]').replace("'", "") # 去除字符串两端的方括号和单引号
# 去掉逗号
text = text.replace(',', '') # 去除字符串中的逗号
return text.split() # 将字符串按空格分割成单词列表
else:
return [] # 如果输入不是字符串,返回空列表3.5 主题提取与可视化
对评论数据进行 LDA 主题建模分析。首先对整体评论数据进行主题建模,生成可视化的 HTML 文件;然后按商品类别细分数据,对每个类别分别构建 LDA 模型并生成可视化结果;最后将每个类别下的主题特征词及其权重保存到 DataFrame 中,收集到 dfs_for_excel 列表以便后续导出到 Excel 文件。具体包括Gensim 词典构建、词袋模型转换、LDA 模型训练、pyLDAvis 可视化这几个关键步骤。
# 分别对每个情感的整体数据进行LDA主题分析
for sentiment in ['特别喜欢']: # 遍历情感类型
num_topics_overall = topics_per_sentiment_overall[sentiment] # 获取该情感的整体主题数量
# 填充可能存在的NaN值,并应用split_to_tokens函数
df.loc[:, 'comment_cleaned'] = df['comment_cleaned'].fillna('') # 将'comment_cleaned'列中的NaN值填充为空字符串
df.loc[:, 'tokens'] = df['comment_cleaned'].apply(split_to_tokens) # 应用split_to_tokens函数将评论转换为词列表
# 构建主题模型
dictionary = corpora.Dictionary(df['tokens']) # 创建Gensim字典对象
corpus = [dictionary.doc2bow(text) for text in df['tokens']] # 将文档转换为词袋表示
lda_model = models.LdaModel(corpus, num_topics=num_topics_overall, id2word=dictionary, passes=15) # 训练LDA模型
# 使用 pyLDAvis 可视化整体数据
vis_data = gensimvis.prepare(lda_model, corpus, dictionary) # 准备可视化数据
pyLDAvis.save_html(vis_data, f'{sentiment}_overall_visualization.html') # 保存可视化结果为HTML文件
# 根据类别细分数据并进行LDA主题分析
categories = df['catagory'].unique() # 获取所有唯一的类别
for category in categories: # 遍历每个类别
category_df = df[df['catagory'] == category].copy() # 过滤出当前类别的数据并复制
num_topics_category = topics_per_sentiment_category[sentiment].get(category, 1) # 获取该类别下的主题数量,默认为1
# 填充可能存在的NaN值,并应用split_to_tokens函数
category_df.loc[:, 'comment_cleaned'] = category_df['comment_cleaned'].fillna('') # 将'comment_cleaned'列中的NaN值填充为空字符串
category_df.loc[:, 'tokens'] = category_df['comment_cleaned'].apply(split_to_tokens) # 应用split_to_tokens函数将评论转换为词列表
# 构建主题模型
dictionary = corpora.Dictionary(category_df['tokens']) # 创建Gensim字典对象
corpus = [dictionary.doc2bow(text) for text in category_df['tokens']] # 将文档转换为词袋表示
lda_model = models.LdaModel(corpus, num_topics=num_topics_category, id2word=dictionary, passes=15) # 训练LDA模型
# 使用 pyLDAvis 可视化分类数据
vis_data = gensimvis.prepare(lda_model, corpus, dictionary) # 准备可视化数据
pyLDAvis.save_html(vis_data, f'{category}_{sentiment}_visualization.html') # 保存可视化结果为HTML文件
# 创建一个新的DataFrame来保存主题模型的结果
topic_results = []
for i in range(num_topics_category): # 遍历每个主题
topic_details = lda_model.print_topic(i) # 获取主题的特征词及其权重
topic_results.append({'所属主题': f'topic {i}', '特征词及其权重': topic_details}) # 将结果添加到列表中
result_df = pd.DataFrame(topic_results) # 将结果列表转换为DataFrame
# 如果结果不为空,则添加到dfs_for_excel列表中
if not result_df.empty: # 检查DataFrame是否为空
sheet_name = f'{category}_{sentiment}' # 设置Sheet名称
result_df.index.name = sheet_name # 设置DataFrame索引名称
dfs_for_excel.append((sheet_name, result_df)) # 将结果添加到列表中LDA 主题模型的可视化结果如下所示,主要包含两部分核心内容:左侧是主题距离图,通过多维缩放展示主题间的语义距离,主题圆圈的位置越近,代表主题内容越相关,圆圈大小反映主题在整体数据中的占比,这里主题2、3、4内容较相关;右侧是主题词分布,展示当前选中主题(主题 6)的核心词汇,横轴表示词汇的相关度量,红色条(主题内词频)越长,说明该词对主题 6 的代表性越强,例如 “购买”“满意”“很多” 等词在主题 6 中高频出现,表明主题 6 主要围绕 “购买体验、满意评价” 方面。
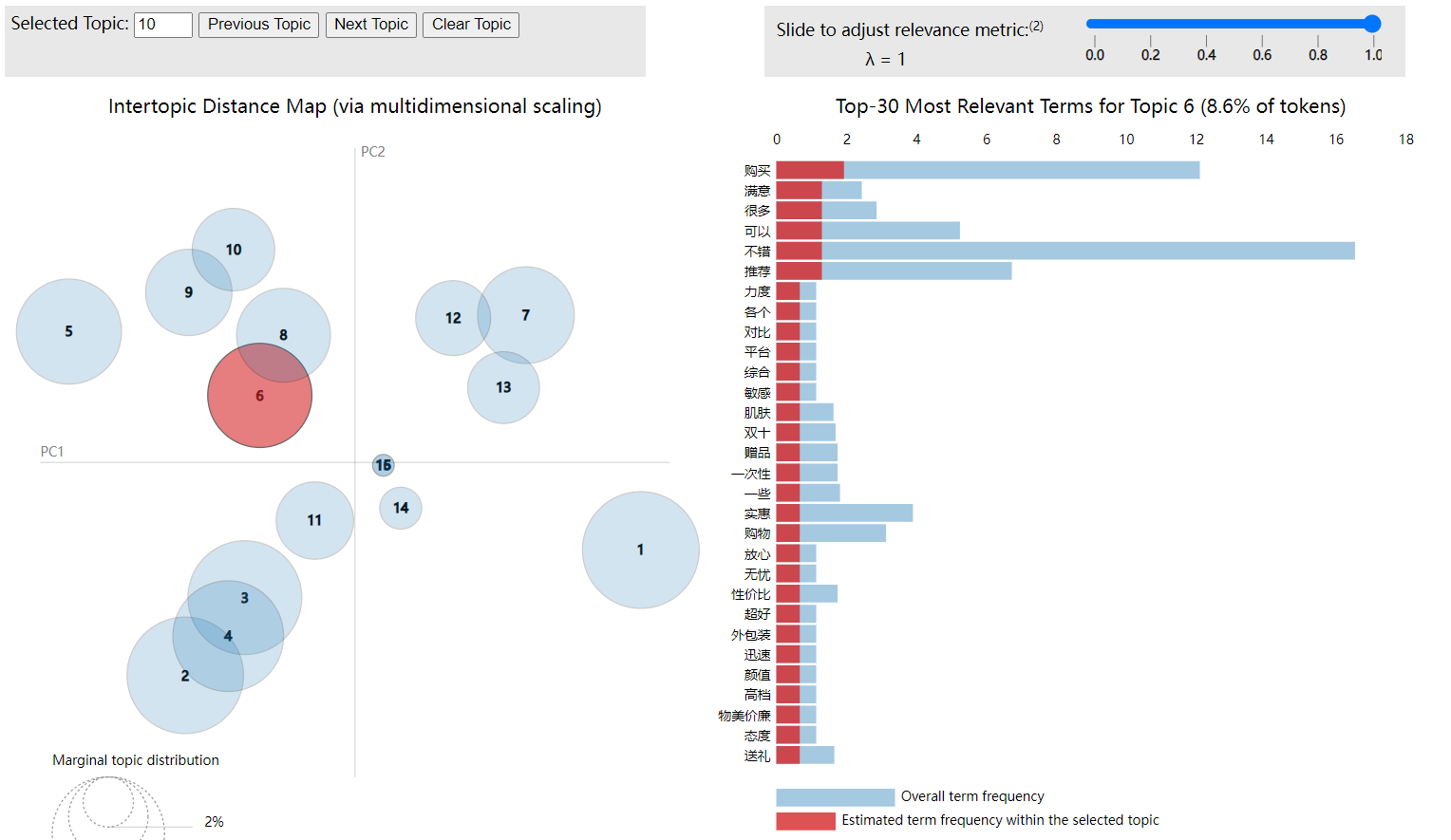
3.6 结果保存
将主题提取结果保存到新Excel:
# 将结果写入新的Excel文件
if dfs_for_excel: # 检查是否有结果需要写入
with pd.ExcelWriter('主题.xlsx', engine='openpyxl') as writer: # 创建Excel写入器
for sheet_name, df in dfs_for_excel: # 遍历每个结果
df.to_excel(writer, sheet_name=sheet_name, index=False) # 将DataFrame写入指定Sheet
else:
print("没有数据可写入Excel文件。") # 如果没有结果,打印提示信息所属主题列是不同的主题编号(如 topic 0、topic 1 ),每个编号代表一个通过 LDA 模型挖掘出的潜在主题;特征词及其权重是每个主题下列出与之关联的特征词及对应权重,权重体现词在该主题中的重要性,权重越高,词对主题的代表性越强。topic 13中 “物美价廉”“值得”“购买”权重较高,说明该主题与 “产品性价比及购买推荐” 相关。
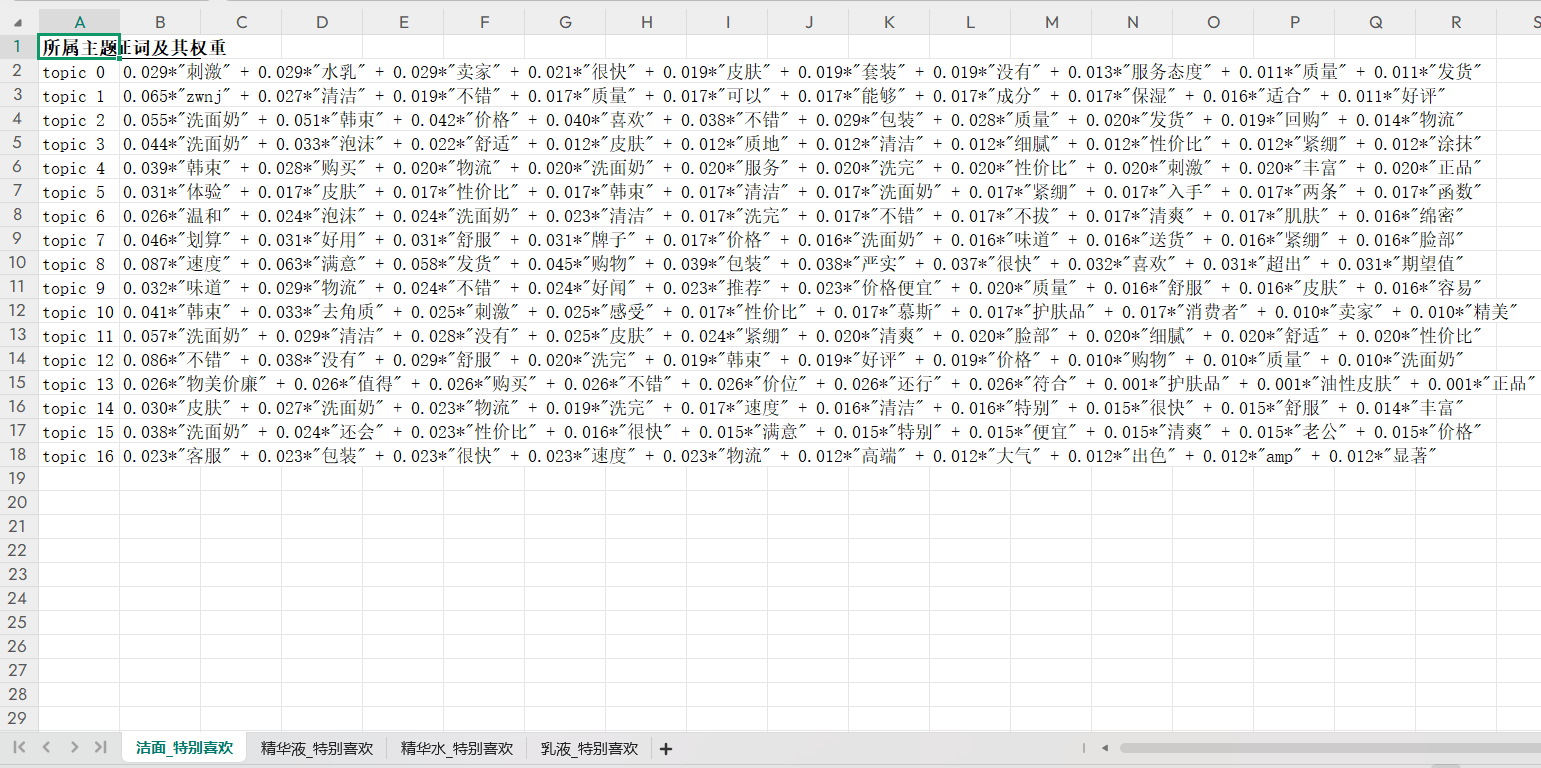
结语
如果大家觉得有帮助,请多多点赞收藏支持一下,谢谢大家。如果遇到什么问题,也非常欢迎大家私信。

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)