
基于动漫数据集的分析与预测:线性回归模型的应用
可视化分析展示了动漫类型、状态、工作室等方面的分布情况。建模分析利用线性回归模型预测动漫评分,评估模型性能并可视化预测结果。最后提供了使用保存模型进行新数据预测的功能。
摘要:可视化分析展示了动漫类型、状态、工作室等方面的分布情况。建模分析利用线性回归模型预测动漫评分,评估模型性能并可视化预测结果。最后提供了使用保存模型进行新数据预测的功能。
关键词:动漫数据集;线性回归;数据可视化;预测模型
图片转自kaggle:https://www.kaggle.com/datasets/tanishksharma9905/top-popular-anime
一、数据集
我用夸克网盘给你分享了「popular_anime.csv」,链接:https://pan.quark.cn/s/cef232474f26
kaggle源地址:https://www.kaggle.com/datasets/tanishksharma9905/top-popular-anime
id:唯一标识符(MyAnimeList ID)。
name:动画的英文标题(如果不可用,可能回退到原始标题或日语标题)。
genres:逗号分隔的流派列表。
type:动漫类型(例如电视、电影、OVA)。
episodes:集数。
status:播出状态(已完成、播出中、即将推出)。
aired_from:播出开始日期。
aired_to:播出结束日期(对于当前正在播放的动漫,此字段可能为null)。
duration_per_ep:每集时长。
score:用户评分(满分10分)。
scored_by:对其进行评分的用户数。
rank:在MyAnimeList上的排名。
rating:年龄分级(例如,PG-13、R)。
studios:参与制作的工作室。
producers:列出的生产商。
image:封面图片的URL。
trailer:预告片视频的URL。
synopsis:简短的情节摘要。
二、数据加载
2.1 加载函数实现
load_data函数用于从指定路径加载动漫数据集,优先尝试从Excel文件读取,若失败则尝试从CSV文件读取。
def load_data():
try:
df = pd.read_excel('E:/pycharm_workspace/数据集/popular_anime.csv')
except Exception as e:
print(f"Error reading as Excel: {e}")
try:
df = pd.read_csv('E:/pycharm_workspace/数据集/popular_anime.csv')
except Exception as e:
print(f"Error reading as CSV: {e}")
return None
return df
三、数据探索分析
3.1 数据预览与基本统计
explore_data函数首先对数据进行预览,展示数据集的前几行。然后进行数据预处理,将genres和studios列中的字符串按逗号拆分并去除两端空格。最后输出数据集的基本统计信息。
def explore_data(df):
# 数据预览
print("\n数据预览:")
print(df.head())
# 数据预处理
genres_list = df['genres'].dropna().str.split(',').explode().str.strip()#取出列,并分割,单成行,去空格
studios_list = df['studios'].dropna().str.split(',').explode().str.strip()
# 基本统计
print("\n基本统计信息:")
print(df.describe())
return genres_list, studios_list
四、可视化分析
4.1 动漫类型与状态分布
plot_distributions函数通过seaborn库绘制多个可视化图表。首先绘制动漫类型分布的条形图,展示不同类型动漫的数量。接着绘制动漫状态分布的条形图,直观呈现不同状态动漫的占比。
# 动漫类型分布
type_counts = df['type'].value_counts()
plt.figure(figsize=(10, 6))
sns.barplot(x=type_counts.index, y=type_counts.values, palette="viridis")
plt.title('动漫类型分布')
plt.xlabel('Type')
plt.ylabel('Count')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# 动漫状态分布
status_counts = df['status'].value_counts()
plt.figure(figsize=(10, 6))
status_barplot = sns.barplot(x=status_counts.index, y=status_counts.values, palette="mako")
status_barplot.set_title('动漫状态分布')
status_barplot.set_xlabel('Status')
status_barplot.set_ylabel('Count')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
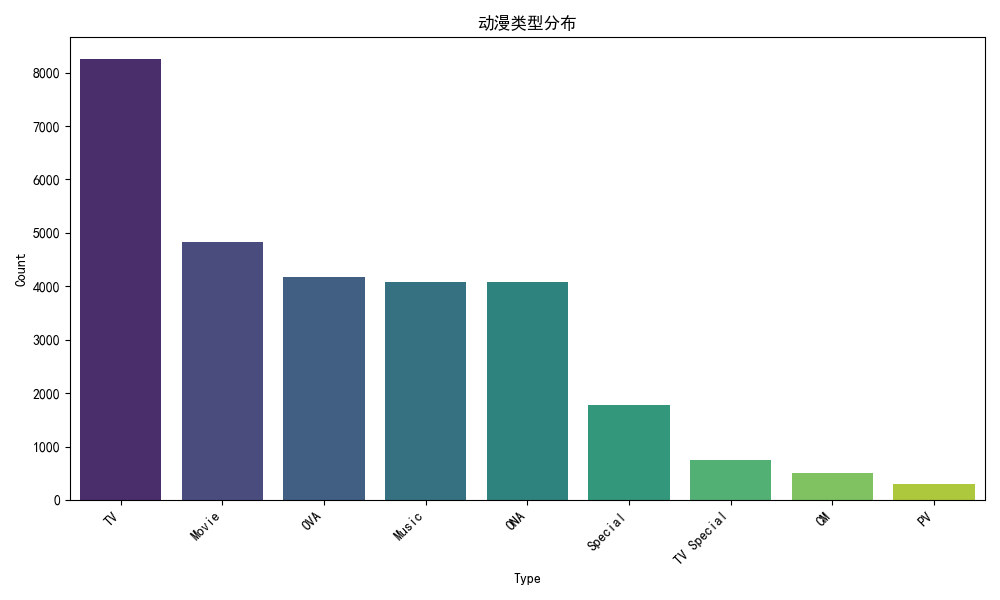
‘TV’ - 电视动画
‘TV Special’ - 电视特别篇
‘Movie’ - 剧场版/电影
‘OVA’ - 原创动画录像带 (Original Video Animation)
‘Music’ - 音乐动画
‘ONA’ - 网络动画 (Original Net Animation)
‘Special’ - 特别篇
‘PV’ - 宣传视频 (Promotional Video)
‘CM’ - 商业广告 (Commercial Message)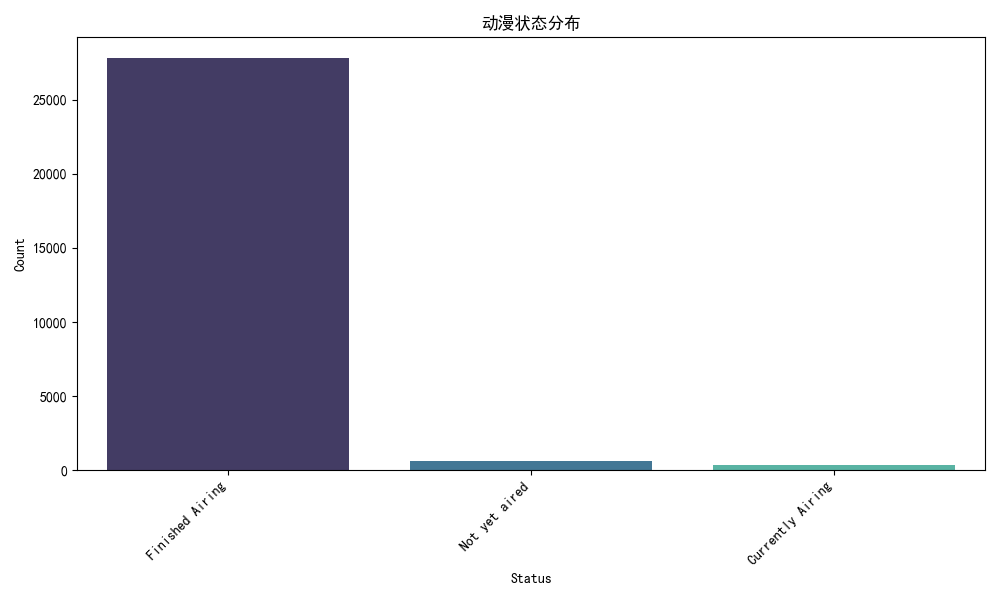
‘Finished Airing’ - 已完结
‘Currently Airing’ - 正在播出
‘Not yet aired’ - 尚未播出
4.2 受欢迎动漫类型与工作室分布
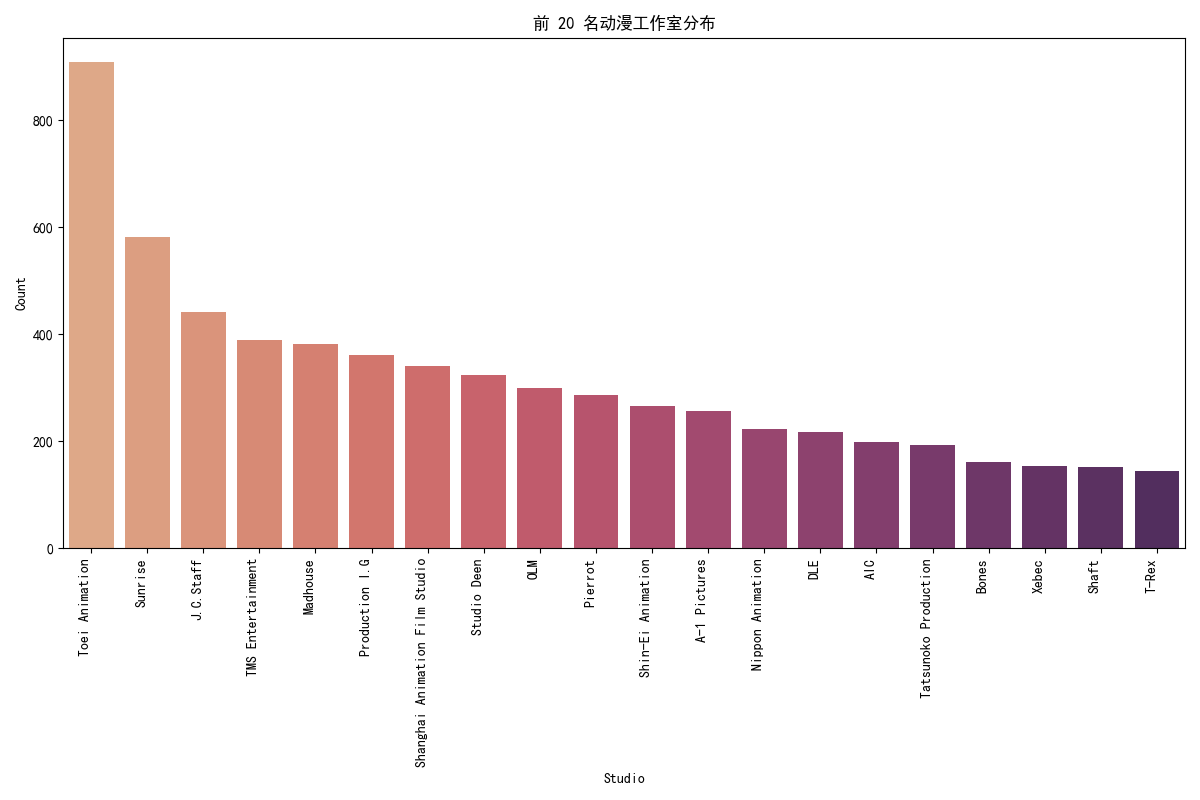
分析最受欢迎的动漫类型,对按score降序排序后的前100部动漫的genres进行拆分和统计,绘制前10种最常见类型的条形图。同时,绘制前20名动漫工作室和前20名动漫类型分布的条形图,展示相关分布情况。
# 分析最受欢迎的动漫类型
top_100_anime = df.sort_values('score', ascending=False).head(100)
top_genres_in_top100 = top_100_anime['genres'].str.split(', ').explode().value_counts().head(10)
plt.figure(figsize=(12, 6))
sns.barplot(x=top_genres_in_top100.index, y=top_genres_in_top100.values,
hue=top_genres_in_top100.index, palette="viridis", legend=False)
plt.title('Top 100高评分动漫中最常见的10种类型')
plt.xlabel('动漫类型')
plt.ylabel('出现次数')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# 动漫工作室分布 (top 20 studios by frequency)
plt.figure(figsize=(12, 8))
studios_barplot = sns.barplot(x=studios_list.value_counts().head(20).index,
y=studios_list.value_counts().head(20).values,
palette="flare")
studios_barplot.set_title('前 20 名动漫工作室分布')
studios_barplot.set_xlabel('Studio')
studios_barplot.set_ylabel('Count')
plt.xticks(rotation=90, ha='right')
plt.tight_layout()
plt.show()
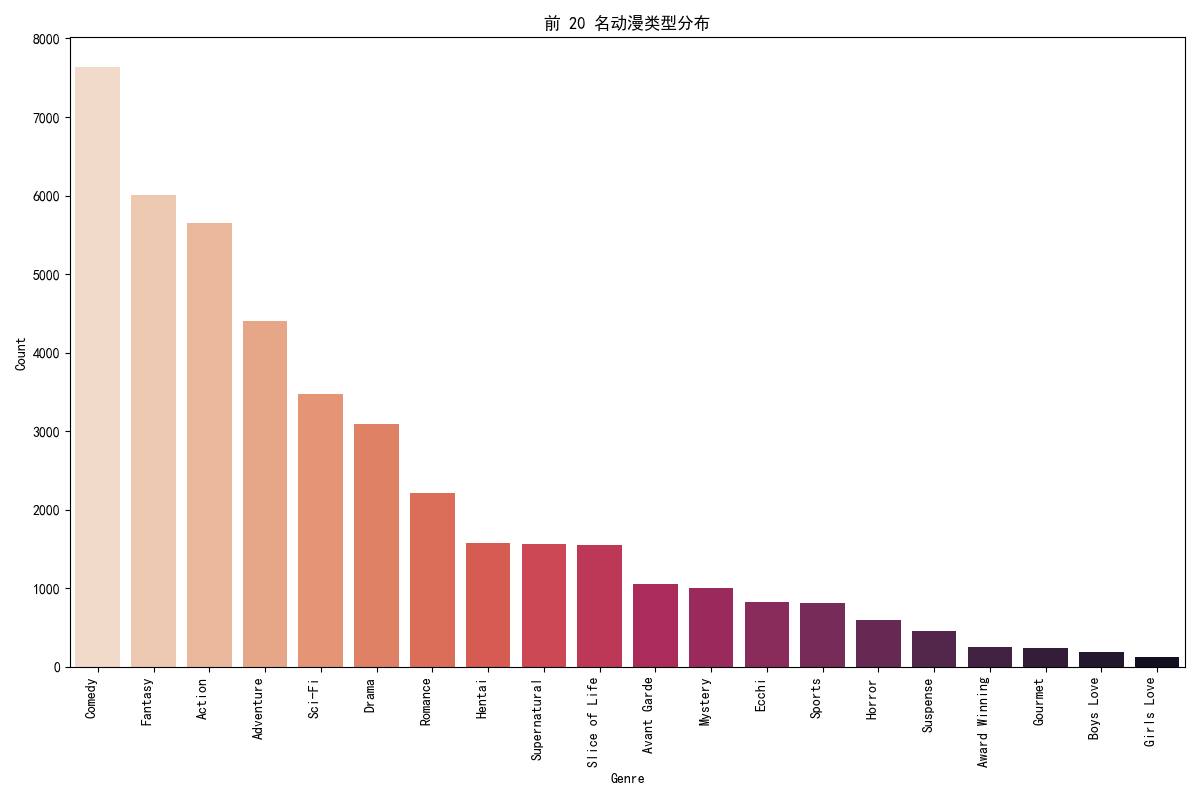
# 动漫类型分布 (top 20 genres by frequency)
plt.figure(figsize=(12, 8))
genres_barplot = sns.barplot(x=genres_list.value_counts().head(20).index,
y=genres_list.value_counts().head(20).values,
palette="rocket_r")
genres_barplot.set_title('前 20 名动漫类型分布')
genres_barplot.set_xlabel('Genre')
genres_barplot.set_ylabel('Count')
plt.xticks(rotation=90, ha='right')
plt.tight_layout()
plt.show()
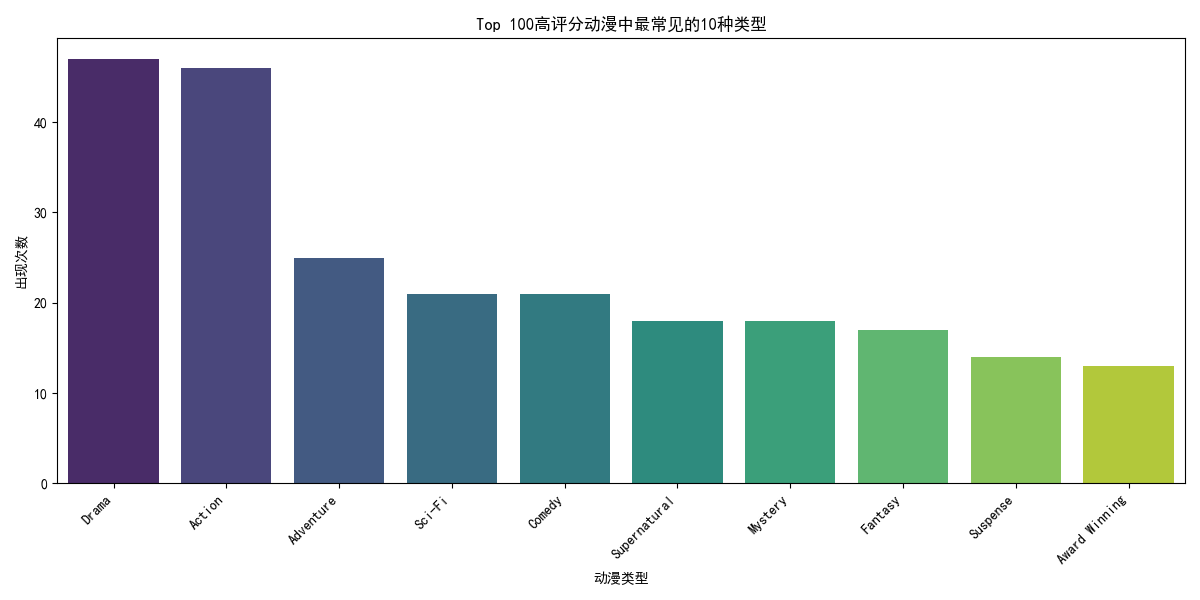
- Adventure - 冒险
- Drama - 剧情
- Fantasy - 奇幻
- Action - 动作
- Sci-Fi - 科幻(全称Science Fiction)
- Suspense - 悬疑
- Comedy - 喜剧
- Supernatural - 超自然
- Romance - 爱情
- Award Winning - 获奖作品
- Mystery - 神秘/推理
- Sports - 运动
- Slice of Life - 日常
- Ecchi - 擦边
- Gourmet - 美食
- Horror - 恐怖
- Avant Garde - 先锋派/实验性
- Boys Love - 耽美
- Hentai - 变态
- Girls Love - 百合
五、建模分析
5.1 数据准备与预处理
regression_analysis函数首先定义数值特征和类别特征,创建ColumnTransformer作为预处理器,对数值特征直接传递,对类别特征进行独热编码。接着对数据进行清洗,去除包含缺失值的行,将特征和目标变量分别赋值给X和y。
numeric_features = ['episodes','scored_by', 'rank']
categorical_features = ['studios']
features = numeric_features + categorical_features
preprocessor = ColumnTransformer(
transformers=[
('num', 'passthrough', numeric_features),
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)
])
clean_data = df[features + ['score']].dropna()
X = clean_data[features]
y = clean_data['score']
5.2 模型训练与评估
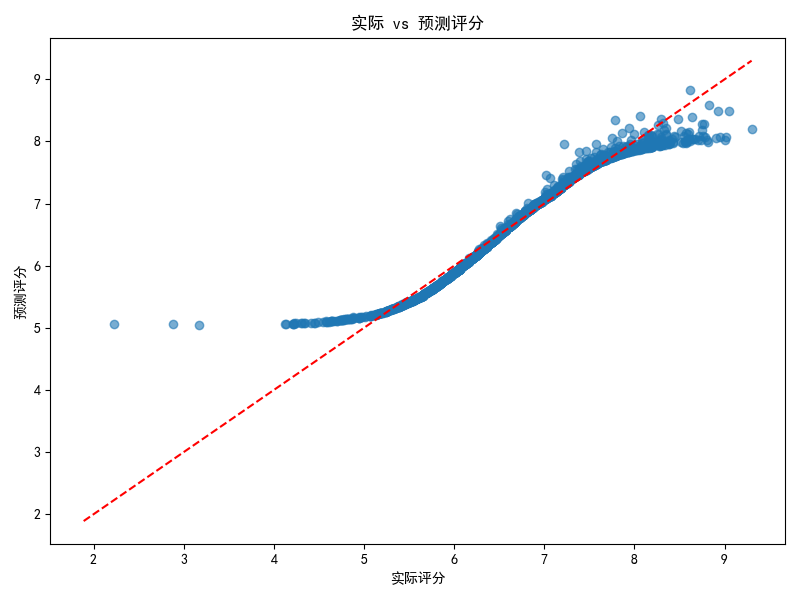
将数据按80%训练集和20%测试集的比例进行划分,对训练集和测试集数据进行预处理。使用线性回归模型进行训练,并对测试集进行预测。计算并输出模型的R2分数,同时绘制实际评分与预测评分的散点图,并添加对角线以便直观比较。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train_transformed = preprocessor.fit_transform(X_train)
X_test_transformed = preprocessor.transform(X_test)
model = LinearRegression()
model.fit(X_train_transformed, y_train)
y_pred = model.predict(X_test_transformed)
print(f'模型R2分数: {r2_score(y_test, y_pred):.4f}')
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, alpha=0.6)
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--')
plt.xlabel('实际评分')
plt.ylabel('预测评分')
plt.title('实际 vs 预测评分')
plt.tight_layout()
plt.show()
# 模型保存 (取消注释以启用)
# import joblib
# joblib.dump(preprocessor, 'anime_preprocessor.pkl')
# joblib.dump(model, 'anime_model.pkl')
六、主程序与模型应用
import joblib
import pandas as pd
# 加载保存的模型和预处理器
preprocessor = joblib.load('anime_preprocessor.pkl')
model = joblib.load('anime_model.pkl')
def predict_score(new_data):
"""
使用保存的模型预测新数据
:param new_data: 包含episodes, scored_by, rank, studios的DataFrame或字典
:return: 预测得分
"""
if isinstance(new_data, dict):
new_data = pd.DataFrame([new_data])
# 预处理新数据
transformed_data = preprocessor.transform(new_data)
# 预测
return model.predict(transformed_data)
if __name__ == "__main__":
# 准备新数据 (格式要与训练数据一致)
test_data = {
'episodes': 12,
'scored_by': 50000,
'rank': 100,
'studios': 'Madhouse'
}
predicted_score = predict_score(test_data)
print(f"预测得分: {predicted_score[0]:.2f}")

如果启用了这段代码,anime_preprocessor.pkl和anime_model.pkl会保存在代码文件的同级目录下面。
七、完整代码
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# 设置字体为SimHei以支持中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#1.加载数据集
try:
#尝试读取为Excel文件
df = pd.read_excel('E:/pycharm_workspace/数据集/popular_anime.csv')
except Exception as e:
#如果失败,打印错误信息
print(f"Error reading as Excel: {e}")
try:
#尝试读取为CSV文件
df = pd.read_csv('E:/pycharm_workspace/数据集/popular_anime.csv')
except Exception as e:
# 失败后打印错误信息
print(f"Error reading as CSV: {e}")
df = None
# 如果成功读取,打印前几行数据
if df is not None:
preview = df.head()
else:
preview = "Unable to read the file."
print("Data Preview:")
print(preview)
# 2. 数据预处理
# 准备特征矩阵 X 和目标向量 y
genres_list = df['genres'].dropna().str.split(',').explode().str.strip()#取出列,并分割,单成行,去空格
type_counts = df['type'].value_counts()# 统计每个类型的数量
status_counts = df['status'].value_counts()
duration_counts = df['duration_per_ep'].value_counts()
studios_list = df['studios'].dropna().str.split(',').explode().str.strip()
# 1. 动漫类型分布
plt.figure(figsize=(10, 6))
type_barplot = sns.barplot(x=type_counts.index, y=type_counts.values, palette="viridis")
type_barplot.set_title('动漫类型分布')
type_barplot.set_xlabel('Type')
type_barplot.set_ylabel('Count')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# 2. 动漫状态分布
plt.figure(figsize=(10, 6))
status_barplot = sns.barplot(x=status_counts.index, y=status_counts.values, palette="mako") # 选择一个颜色映射表,如mako
status_barplot.set_title('动漫状态分布')
status_barplot.set_xlabel('Status')
status_barplot.set_ylabel('Count')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# 3. 分析最受欢迎的动漫类型
# 按score降序排序并取前100
top_100_anime = df.sort_values('score', ascending=False).head(100)
# 拆分genres并统计
top_genres_in_top100 = top_100_anime['genres'].str.split(', ').explode().value_counts().head(10)
# 可视化
plt.figure(figsize=(12, 6))
sns.barplot(x=top_genres_in_top100.index, y=top_genres_in_top100.values,
hue=top_genres_in_top100.index, palette="viridis", legend=False)
plt.title('Top 100高评分动漫中最常见的10种类型')
plt.xlabel('动漫类型')
plt.ylabel('出现次数')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
# 4. 动漫工作室分布 (top 20 studios by frequency)
plt.figure(figsize=(12, 8))
studios_barplot = sns.barplot(x=studios_list.value_counts().head(20).index,
y=studios_list.value_counts().head(20).values,
palette="flare")
studios_barplot.set_title('前 20 名动漫工作室分布')
studios_barplot.set_xlabel('Studio')
studios_barplot.set_ylabel('Count')
plt.xticks(rotation=90, ha='right')
plt.tight_layout()
plt.show()
# 5. 动漫类型分布 (top 20 genres by frequency)
plt.figure(figsize=(12, 8))
genres_barplot = sns.barplot(x=genres_list.value_counts().head(20).index,
y=genres_list.value_counts().head(20).values,
palette="rocket_r")
genres_barplot.set_title('前 20 名动漫类型分布')
genres_barplot.set_xlabel('Genre')
genres_barplot.set_ylabel('Count')
plt.xticks(rotation=90, ha='right')
plt.tight_layout()
plt.show()
# 6. 回归分析
print("\nRegression Analysis:")
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# 6.1 准备数据
numeric_features = ['episodes', 'scored_by', 'rank']
categorical_features = ['studios']
features = numeric_features + categorical_features
# 6.2 创建预处理器
preprocessor = ColumnTransformer(
transformers=[
('num', 'passthrough', numeric_features),
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)
])
# 6.3 数据清洗
clean_data = df[features + ['score']].dropna()
X = clean_data[features]
y = clean_data['score']
# 6.4 模型训练与评估
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
X_train_transformed = preprocessor.fit_transform(X_train)
X_test_transformed = preprocessor.transform(X_test)
model = LinearRegression()
model.fit(X_train_transformed, y_train)
y_pred = model.predict(X_test_transformed)
# 6.5 输出结果
print(f'模型R2分数: {r2_score(y_test, y_pred):.4f}')
# 6.6 可视化预测结果
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, alpha=0.6)
plt.plot([y.min(), y.max()], [y.min(), y.max()], 'r--')
plt.xlabel('实际评分')
plt.ylabel('预测评分')
plt.title('实际 vs 预测评分')
plt.tight_layout()
plt.show()
# import joblib
#
# # 保存预处理器和模型
# joblib.dump(preprocessor, 'anime_preprocessor.pkl')
# joblib.dump(model, 'anime_model.pkl')
# print("模型和预处理器已保存为 anime_model.pkl 和 anime_preprocessor.pkl")

GitCode 天启AI是一款由 GitCode 团队打造的智能助手,基于先进的LLM(大语言模型)与多智能体 Agent 技术构建,致力于为用户提供高效、智能、多模态的创作与开发支持。它不仅支持自然语言对话,还具备处理文件、生成 PPT、撰写分析报告、开发 Web 应用等多项能力,真正做到“一句话,让 Al帮你完成复杂任务”。
更多推荐



 36
36 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)